はじめに
Convolutional Neural Network (CNN) を画像分類に使う時、最後の分類層を fully-connected layer の代わりに Support Vector Machine (SVM) に置き換えることがしばしばあります。これなんで?って上司に聞かれてうまく答えられなかったので R-CNN の原論文の appendix を読んで勉強してみました。
参考資料
-
Rich feature hierarchies for accurate object detection and semantic segmentation Tech report (v5)
- https://arxiv.org/abs/1311.2524
- 言わずと知れた R-CNN の原論文。You Only Look Once (YOLO) や Single Shot multibox Detector (SSD) の元祖ですね。この論文の R-CNN では分類層に SVM を用いているのですが、そう実装した理由が Appendix B で議論されています。
-
R-CNNの原理とここ数年の流れ (2017)
- https://www.slideshare.net/KazukiMotohashi2/rcnn
- 関係ないのですが、R-CNN の原理について解説したスライドを以前公開したので貼っておきます(宣伝)。Deep Learning 勉強し始めて1ヶ月の時に作ったスライドということもありツッコミどころ多々ありますが、むしろ突っ込んでいただけると勉強になりますのでお願いします。
Appendix B: Positive vs. negative examples and softmax
前提知識
R-CNN の概要
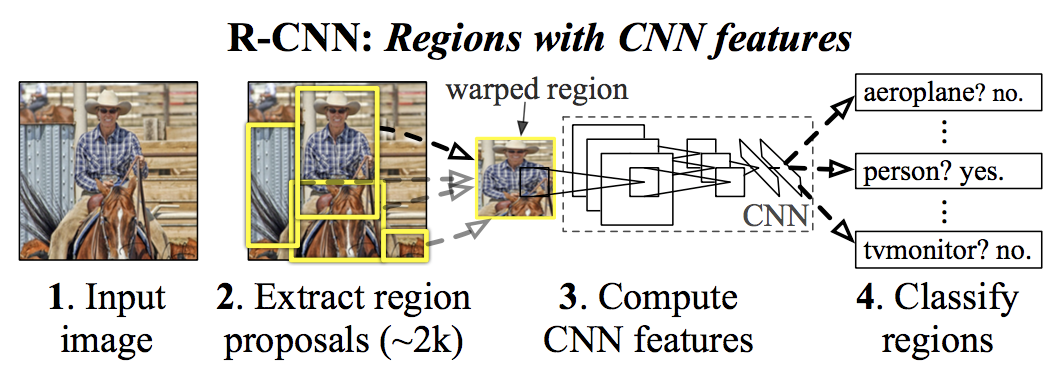
image quoted from https://arxiv.org/abs/1311.2524
- 入力画像に対して、
- 物体が写っている領域の候補を selective search で約2,000個抽出し、(CNN のインプットの大きさに合うようにそれぞれの領域中の画像をリサイズし、)
- それぞれの領域に対して CNN (AlexNet) で特徴量を計算し、
- それぞれの領域に何が写っているか SVM で分類する
R-CNN の訓練方法
- ILSVRC2012 dataset で特徴抽出用の CNN (AlexNet) を pre-training
- VOC 2007 や ILSVRC2013 dataset に対して、selective search で物体候補領域を抽出し、分類層1を fine-tuning
- 最後に CNN で得た特徴量を SVM に入力して SVM のトレーニングを行う(この行程がなんで必要か知りたい)
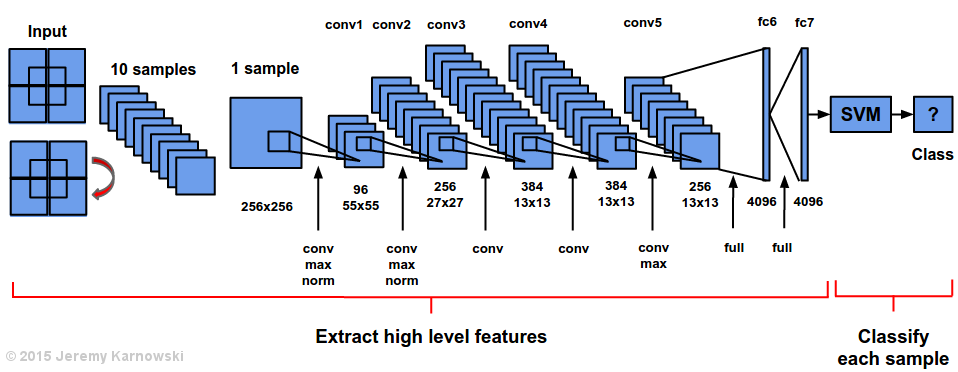
image quoted from https://jeremykarnowski.wordpress.com/2015/07/15/alexnet-visualization/
ひたすら訳します(一部意訳)
関係あるのは4段落め以降です。せっかく訳したので誰かのために省略せず残しておきます。
1段落目
Two design choices warrant further discussion. The first is: Why are positive and negative examples defined differently for fine-tuning the CNN versus training the object detection SVMs? To review the definitions briefly, for fine-tuning we map each object proposal to the ground-truth instance with which it has maximum IoU overlap (if any) and label it as a positive for the matched ground-truth class if the IoU is at least 0.5. All other proposals are labeled “background” (i.e., negative examples for all classes). For training SVMs, in contrast, we take only the ground-truth boxes as positive examples for their respective classes and label proposals with less than 0.3 IoU overlap with all instances of a class as a negative for that class. Proposals that fall into the grey zone (more than 0.3 IoU overlap, but are not ground truth) are ignored.
2つの設計上の選択肢が、さらなる議論を生む。まず、CNN の fine-tuning とオブジェクト検出 SVM の訓練に対して、それぞれ positive と negative のサンプルの定義を変えるのはなぜか?それぞれの定義を簡単に見直そう。fine-tuning を行う時は、オブジェクト候補領域それぞれを、IoU2 が最も大きい ground truth3 にマッピングし、IoU が 0.5 以上であればその候補領域を「マッチした ground-truth が属するクラスに対して positive」としてラベル付けする。他のすべての候補領域には「背景」 (すべてのクラスに対する negative サンプル) というラベルが付けられる。一方、SVM を訓練する場合、ground-truth box のみをそのクラスの positive サンプルとして扱い、IoU が 0.3 未満の矩形領域候補はそのクラスに対する negative として扱う。グレーゾーンにある矩形領域候補(IoU が 0.3 以上だが、ground truth でない)は無視する。
2段落目
Historically speaking, we arrived at these definitions because we started by training SVMs on features computed by the ImageNet pre-trained CNN, and so fine-tuning was not a consideration at that point in time. In that setup, we found that our particular label definition for training SVMs was optimal within the set of options we evaluated (which included the setting we now use for fine-tuning). When we started using fine-tuning, we initially used the same positive and negative example definition as we were using for SVM training. However, we found that results were much worse than those obtained using our current definition of positives and negatives.
経緯としては、ImageNet で事前訓練を行なった CNN によって計算された特徴量に対して SVM を訓練することから始めたためこれらの定義を用いるに至ったのであり、その時点では fine-tuning を行うことは想定していなかった。このセットアップでは、fine-tuning のために使用した定義を含む様々な定義のオプションを試したが、SVM をトレーニングするために用いた上記のラベル定義が最適であった。fine-tuning を使い始めた当初は、SVM トレーニングに使用したのと同じ positive と negative のサンプル定義を使用した。しかし、最終的に用いた positive と negative の定義により得られる結果よりもずっと悪い結果が得られた。
3段落目
Our hypothesis is that this difference in how positives and negatives are defined is not fundamentally important and arises from the fact that fine-tuning data is limited. Our current scheme introduces many “jittered” examples (those proposals with overlap between 0.5 and 1, but not ground truth), which expands the number of positive examples by approximately 30x. We conjecture that this large set is needed when fine-tuning the entire network to avoid overfitting. However, we also note that using these jittered examples is likely suboptimal because the network is not being fine-tuned for precise localization.
私たちの仮説では、positive と negative の定義の違いは本質的に重要ではなく、fine-tuning に用いる訓練データ数が限られているのが問題だと考えている。私たちの現在のスキームでは、多くの「ジッタ」のついたサンプル(IoU が 0.5と1の間にあるが ground truth でない領域候補)が導入されており、positive のサンプルの数は約30倍に拡大される。ネットワーク全体を fine-tuning する時 overfitting を避けるためにこの大きなセットが必要であると推測される。しかし、ネットワークが正確な localization のために fine-tune されていないため、これらのジッタ付きのサンプルを使用するのは最適でない可能性がある。
4段落目
This leads to the second issue: Why, after fine-tuning, train SVMs at all? It would be cleaner to simply apply the last layer of the fine-tuned network, which is a 21-way softmax regression classifier, as the object detector. We tried this and found that performance on VOC 2007 dropped from 54.2% to 50.9% mAP. This performance drop likely arises from a combination of several factors including that the definition of positive examples used in fine-tuning does not emphasize precise localization and the softmax classifier was trained on randomly sampled negative examples rather than on the subset of “hard negatives” used for SVM training.
これは2つ目の問題につながる。**なぜ、fine-tuning の後、SVM をトレーニングするのか?**物体検出器として、21クラス(20クラス+背景)の softmax 回帰分類器である fine-tuned ネットワークの最後のレイヤーを単純に適用すると、よりシンプルになる。これを試したところ、VOC 2007 dataset に対するパフォーマンスは 54.2% から 50.9% に低下してしまった。この性能低下には様々な要因が考えられる。一つには、fine-tuning に使用される positive サンプルの定義が正確な localization を重要視していないこと。また、softmax 分類器の訓練には、SVM の訓練に使用される "hard negative" のサブセットではなくランダムにサンプリングされた negative のサンプルを用いたためと考えられる。
5段落目
This result shows that it’s possible to obtain close to the same level of performance without training SVMs after fine-tuning. We conjecture that with some additional tweaks to fine-tuning the remaining performance gap may be closed. If true, this would simplify and speed up R-CNN training with no loss in detection performance.
この結果は、fine-tuning 後に SVM を訓練することなく、同等のレベルの性能を得ることが可能であることを示している。私たちは、残りのパフォーマンスギャップを微調整するためのいくつかの追加調整を行うと、ギャップがなくなると推測する。本当にそうであれば、検出性能を損なうことなく R-CNN トレーニングを単純化し、スピードアップできるだろう。
結論と勝手な考察
なんか「こうしたらうまくいった」以外の何者でもないように感じます。R-CNN の前身とも言える Selective Search の論文 (Selective Search for Object Recognition) では HOG 特徴量 + SVM を用いているので、R-CNN でも SVM を用いたのはその名残に寄るところが大きいですかね。softmax だけで十分だろうと予想はしたけれども、(振り返ってみると)複雑すぎるシステム・訓練手順にした結果、最適化しきれなかった、って感じでしょうか。
「いや、君は全くわかっとらん。」「うちではこういう理由で SVM 使ってるよ。」などといったツッコミ・情報など激しく歓迎です。
Deep Learning using Linear Support Vector Machines というまんまな論文では MNIST, CIFAR-10, ICML 2013 のデータセットに softmax の代わりに (L2-)SVM を用いたところ、パフォーマンスが向上したことを報告しています。
Stack Exchange の Why do Convolutional Neural Networks not use a Support Vector Machine to classify? では、「SVM にすると認識率が上がることもあるが、計算コストが割高なので普通は使わない」という意見もありました。
-
論文からは分類層が具体的にどの部分を指しているか読み解けませんでした。AlexNetのpool5以降のレイヤーのこと? ↩
-
Intersection over Union の略。推定した矩形領域とあらかじめラベル付けしておいた矩形領域 (Ground Truth) が重なっている面積の割合のこと。(IoU(A,B) := A∩B/A∪B) ↩
-
地上 (ground) の衛星写真画像に対して、 各領域がどういったカテゴリの土地なのかをラベル付けした正しい (truth) 情報。転じて、R-CNN 等では、写真に写っている物体とその位置を通常矩形領域で指定した annotation 情報のことを指す。 ↩