はじめに
因果推論の実験に使えるデータセットをpythonでの読み込み方法とともにまとめた記事です。
想定している読者
- 主にRubin因果モデルに従った手法による因果推論を実装したい
- それぞれのデータセットの特徴を知りたい
- (pythonで)すぐに自分の環境でデータセットを読み込みたい
因果推論とデータセット
データセット紹介の前に、少しだけ表題の解説を行います。基礎的な部分なので、読み飛ばしていただいて大丈夫です。
因果推論の手法の評価実験では、通常のテーブルデータを用いることは少なく、多くの場合、因果推論専用のデータセットによって手法の評価を行います。その理由は簡潔に言うと、「通常のデータには正解データが無いから」であり、これは**「因果推論の根本問題」という問題と関連します。
因果推論の根本問題とは、ある介入を行った場合と行わなかった場合の両方の効果を同時には観測できないと言う問題です。例えば、薬の投与をした人からは、薬を投与した場合の効果しか観測されず、薬を投与しなかった場合の効果は観測されない、同様に、薬を投与しなかった人からは、薬を投与した場合の効果が観測されないという問題です。
この問題のため、通常は真の因果効果**をデータから算出することはできないという問題点があります。そのため、通常のデータに因果推論の手法を適用しても、手法の精度が良いか分からず、手法間の比較を行うことができません。
以上の問題点から、因果推論の手法の性能評価実験では、「因果効果が分かる形」のデータセットが用いられます。
ここからは、(一部例外がありますが、)因果推論の手法の性能評価実験に使えるデータセットについて紹介していきます。
1. IHDPデータセット
概要
- よく採用されているベンチマーク・データセット
- Infant Health and Development Programという、低出生体重児や未熟児を対象としたランダム化比較試験(RCT)を元に生成されたデータセット
- 変数
- 共変量:出生時の体重・頭囲、母親の年齢・教育・薬物・アルコールなどの25の変数
- 介入:「乳児が質の高い保育と専門家による家庭訪問を受けること」
- 効果:乳児の認知テストのスコア
-
NPCIパッケージを用いて効果をシミュレーションすることができる
- 介入あり、なしの効果を同時に入手できる
- シミュレーションには複数の設定がある
読み込み
ihdp.py
df = pd.DataFrame()
for i in range(1, 10):
data = pd.read_csv('https://raw.githubusercontent.com/AMLab-Amsterdam/CEVAE/master/datasets/IHDP/csv/ihdp_npci_' + str(i) + '.csv', header=None)
df = pd.concat([data, df])
cols = ["treatment", "y_factual", "y_cfactual", "mu0", "mu1"] + [i for i in range(25)]
df.columns = cols
df.index = range(len(df))
df
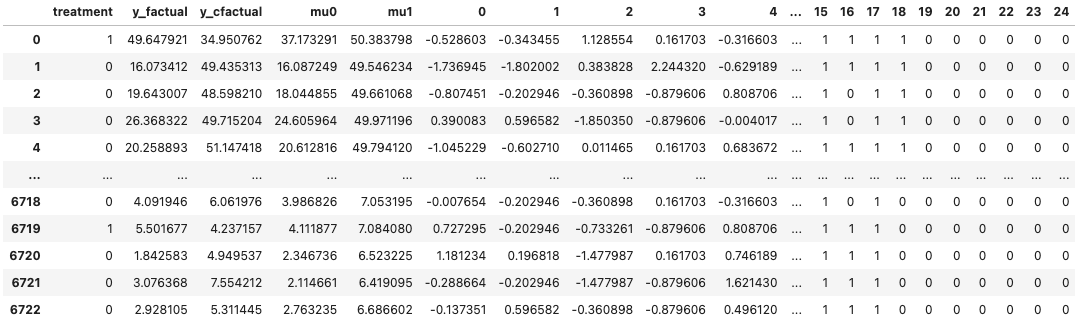
-
treatmentは介入の有無 -
y_factualは観測された効果、y_cfactualは観測されなかった効果 -
mu0は介入なしの場合の効果の期待値、mu1は介入ありの場合の効果の期待値
2. Jobsデータセット
概要
- Landoleの行った職業訓練の有無による収入への因果効果を確かめるための実験
- 変数
- 共変量:年齢、教育、民族、1974,75年の収入などの8つの変数
- 介入:職業訓練への参加の有無
- 効果:1978年の収入
- Landoleらの行ったRCT(ランダム化比較実験)のデータと、職業訓練を受けていない人のRCTでないデータがある
- 前者を用いることで、職業訓練の因果効果を知ることができる
- 後者を前者と結合することで不均衡なデータを作れる
読み込み
jobs.py
# RCTでないデータ
df_cps1 = pd.read_stata('https://users.nber.org/~rdehejia/data/cps_controls.dta')
# RCTデータ
df_nsw = pd.read_stata('https://users.nber.org/~rdehejia/data/nsw_dw.dta')
df = pd.concat([df_nsw[df_nsw[z_column] == 1], df_cps1], ignore_index=True)
df
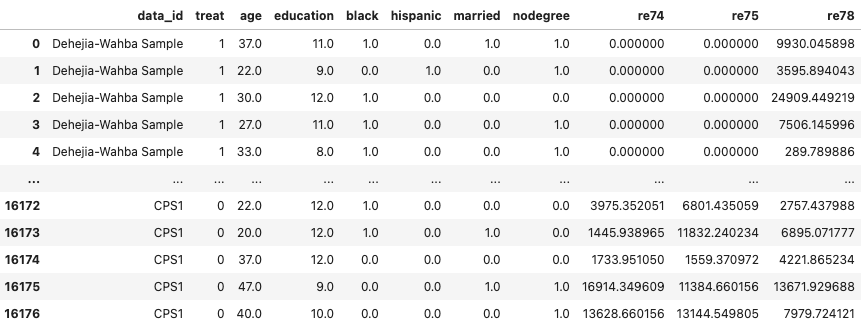
- 2行目の
cps_controlsの末尾に2, 3をつけることで、別のボリュームのデータを得られる-
cps_controls.dta:15992行 -
cps_controls2.dta:2369行 -
cps_controls3.dta:429行
-
- 詳細な説明はhttps://users.nber.org/~rdehejia/nswdata2.html 参照
3. TWINSデータセット
概要
- 1989年から1991年の間に米国で出生した双子のデータをもとに構築されたデータセット
- 変数
- 共変量:妊娠週数、妊娠中のケアの質、妊娠危険因子(貧血、アルコール使用、タバコ使用など)、居住地などの50の変数
- 介入:体重の重い方の双子
- 効果:1年後志望しているかどうか
- 介入を受けた場合(重い方の双子)の効果、受けなかった場合(軽い方の双子)の効果の両方が観測される
- このデータセットにおける因果効果は「双子の重い方と軽い方の死亡率の差」を示している
- 「介入をどちらかだけ割り当てる」という概念がないため、この割り当ては通常は自分で定義する
読み込み
twins.py
# 共変量のdf
df_x = pd.read_csv('https://raw.githubusercontent.com/AMLab-Amsterdam/CEVAE/master/datasets/TWINS/twin_pairs_X_3years_samesex.csv', index_col=0)
df_x.drop(['Unnamed: 0.1', 'infant_id_0', 'infant_id_1'], axis=1, inplace=True)
# 効果のdf
df_y = pd.read_csv('https://raw.githubusercontent.com/AMLab-Amsterdam/CEVAE/master/datasets/TWINS/twin_pairs_Y_3years_samesex.csv', index_col=0)
# 結合
df = pd.concat([df_y, df_x], axis=1)
# 割り当ての追加(自分で割り当てを定義する)
# 今回は、ランダム割り当て(本来は、共変量から割り当てを決定する関数を作成する必要あり)
df['treat'] = np.random.randint(0, 2, (len(df), 1))
df

- 欠損値の処理をする必要あり
-
mort_0が非介入の場合の死亡、mort_1が介入の場合の死亡 -
pd.read_csv('https://raw.githubusercontent.com/AMLab-Amsterdam/CEVAE/master/datasets/TWINS/twin_pairs_T_3years_samesex.csv', index_col=0)とすることで、体重に関する情報を得ることができる
岩波データサイエンス
概要
- 『岩波データサイエンスvol.3』で取り上げられているCM接触のアプリゲームプレイ因果効果についてのデータセット
- 変数
- 共変量:居住地、年齢、性別、職業などの31個の変数
- 介入:(アプリゲームの)cmを見たかどうか
- 効果:アプリゲームのプレイ時間
- 注意:このデータセットは、正解データがあるわけではないので、手法の評価を行うのは難しい
読み込み
iwanami.py
df = pd.read_csv('https://raw.githubusercontent.com/iwanami-datascience/vol3/master/kato%26hoshino/q_data_x.csv')
df
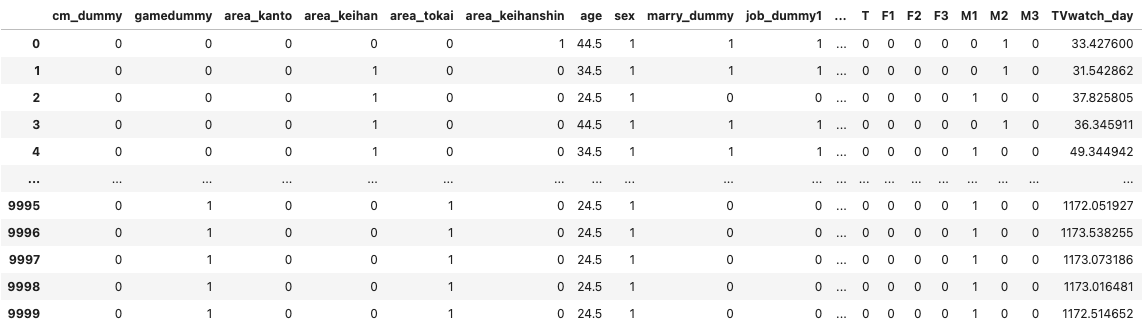
- 詳しい説明はサポートページ参照
(注)このデータセットは、両方の効果を観測できているわけではないので手法の評価に使えるわけではない
おわりに
本記事では、因果推論の実験に使えるデータセットをまとめました。
参考文献