はじめに
この記事はシスコの有志による Cisco Systems Japan Advent Calendar 2017 の 22 日目です。
IT 業界に限らず、「機械学習」や「AI」という言葉が様々な場面で語られることが多い昨今ですが、弊社製品でも機械学習を取り入れた製品が増えてきています。
例えば、ETA という Security ソリューションでは、暗号化されたトラフィックに対して機械学習を適用することで、暗号化通信を復号化せずに脅威判定を行うことができます(参考)。
今回は Connected Mobile eXperiences - CMX という弊社の位置情報ソリューションの API を用い、「機械学習が組み込まれていないソリューションに対して、機械学習を組み込むとどうなるか」という遊びをしてみました。
位置情報データの扱いと機械学習
世の中には、行動分析として用いられている手法が多々あります。
データの時系列性に着目したもの、「物事を選択する」という行動の離散的な性質に着目したものなど、着目する観点によってその手法は様々です。
特に、位置情報データと時系列データを組み合わせ、行動パターンを機械学習によって把握する手法は、多くの企業によって提案されており、開発が進んでいる分野の 1 つです。
今回は CMX から得られた位置情報データのみを用いて、シンプルに「行動範囲から人物の特定が可能か」を試してみました。
座標データを元にした、離散値の分類となるため、機械学習の手法としてはランダムフォレストを用いてみます。
位置情報データの取得
下記コードで CMX の API から位置情報データを取得します。
import requests
requests.packages.urllib3.disable_warnings()
from requests.auth import HTTPBasicAuth
import json
username = "XXXX"
password = "XXXX"
macaddress = "XXXX"
url = "https://CMX IPaddress//api/location/v1/historylite/clients/" + macaddress
request = requests.get(
url = url,
auth = HTTPBasicAuth(username,password),
verify = False,
params = params)
data = json.dumps(json.loads(request.content), indent=2)
得られるデータの形は下記のような JSON 形式です。
{
"Data": [{
"x": 127.360504,
"y": 46.771755,
"flr": "723413320329068590",
"chgOn": "1486857599696",
"s": "1",
"ssid": "test",
"ap": "XX:XX:XX:XX:XX:XX",
"un": "",
"ip": "XX.XX.XX.XX",
"lat": -999,
"long": -999
},
...
"Count": 3000,
"Ipv4address": "X.X.X.X",
"Date": "2017/12/22",
"Macaddress": "XX:XX:XX:XX:XX:XX"
}
データ
実際に足で稼いでデータを取得します。
その後、行動範囲を複数の座標データ、人物の特定を MAC アドレスによって行います。
今回取得したデータとしては、 MAC アドレスは全部で 3 種類で、各 MAC アドレスにつき 300 個の座標データです。
これらをランダムフォレストのトレーニングデータとし、最終的に人物の特定が可能かを行います。
ランダムフォレスト構築後は、新たに各 MAC アドレスにつき 100 個の座標データを用いて精度の検証をします。
また、前節で取得した座標データと MAC アドレスの情報を、本記事で用いる Python のランダムフォレスト関数に適合するよう、配列の形に整形します。
training_data = []
macaddress = []
for item in data["Data"]:
training_data.append([item["x"],item["y"]])
macaddress.append(data["Macaddress"])
トレーニングデータの分布は下図のようになりました。
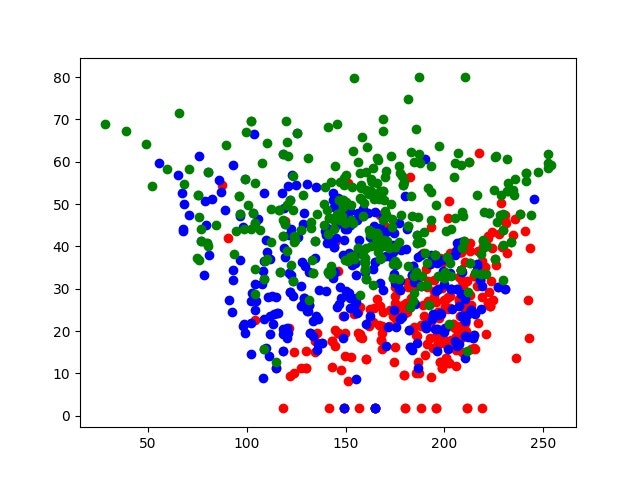
また、作成されたランダムフォレストがどれほど有用かを調査するため、同様の形でテストデータも作成します。
ランダムフォレストの実装
今回は Python での実装となるため、扱いやすくメジャーな scikit-learn を用いています。
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
model.fit(training_data, people)
このわずか 2 行で、ランダムフォレストが作られたことになります。
結果
>>> model.score(training_data, people)
0.90625
>>> model.score(test_data,test_people)
0.79666666666666668
数値で見る結果は、上記の通りです。
トレーニングデータとして使ったデータを、出来上がったランダムフォレストに当てはめた場合の値がmodel.score(training_data, people)です。こちらは当然良い結果であり、90% を超えています。
しかし、新たに取得したテストデータを当てはめた場合(model.score(test_data,test_people))は約 80% となり、「そこそこ」といった結果になりました。
つまり、同じ場所でのデータかつ新しいデータが与えられた場合には、約 80% の確率で誰であるかを特定できる、ということです。
最後に
本記事では、行動範囲のみを用いて、人物の特定を行いました。
ある程度の精度は得られましたが、やはり説明変数を行動範囲のみとすると難しいようです。しかし、CMX の API 自体は、時間などの他のデータも取得できます。時系列を考慮した動線を分析し、その後機械学習する、などより詳細な分析も可能だと考えられます。
さらに、今回は人物に関するデータ(個人属性のデータ)を MAC アドレスのみとしましたが、他アプリケーションのデータを用いて個人属性データを取得すれば、離散選択モデルのような行動分析も可能です。
というわけで、インプットデータの拡張や数理モデルの選択次第でまだまだ多くのアウトプットが得られそうです。
おまけ
今回は CMX を用いましたが、弊社の他ソリューションでも API が公開されているものは数多く存在します。
取得したデータを機械学習によって予測・分類すると、本記事よりももっと面白いことができそうです。
DevNet のページに API に関する情報が多く載せられていますので、ご興味のある方はぜひ閲覧ください。