サーバーサイドエンジニアも知っておくべきフロントエンドの今
こちらのスライドですが、スライドのみだとライブラリやツールの紹介でわからない気がするのと、それに対する批判がイマイチなので、自分なりにわかりやすくしてみます。
スライド書いた人とは無関係なので、解釈が間違っているかもしれません。
前提の説明
フロントエンドの話をする前に、レガシーなWebとモダンなWebの前提知識が必要だと思います。
レガシーなWebページ
リクエストを送ると、HTMLとCSS、JavaScriptが返ってきます。

モダンなWebページ
リクエストを送ると、HTMLとCSS、JavaScriptが返ってくるだけでなく、JSONというデータも返ってきます。
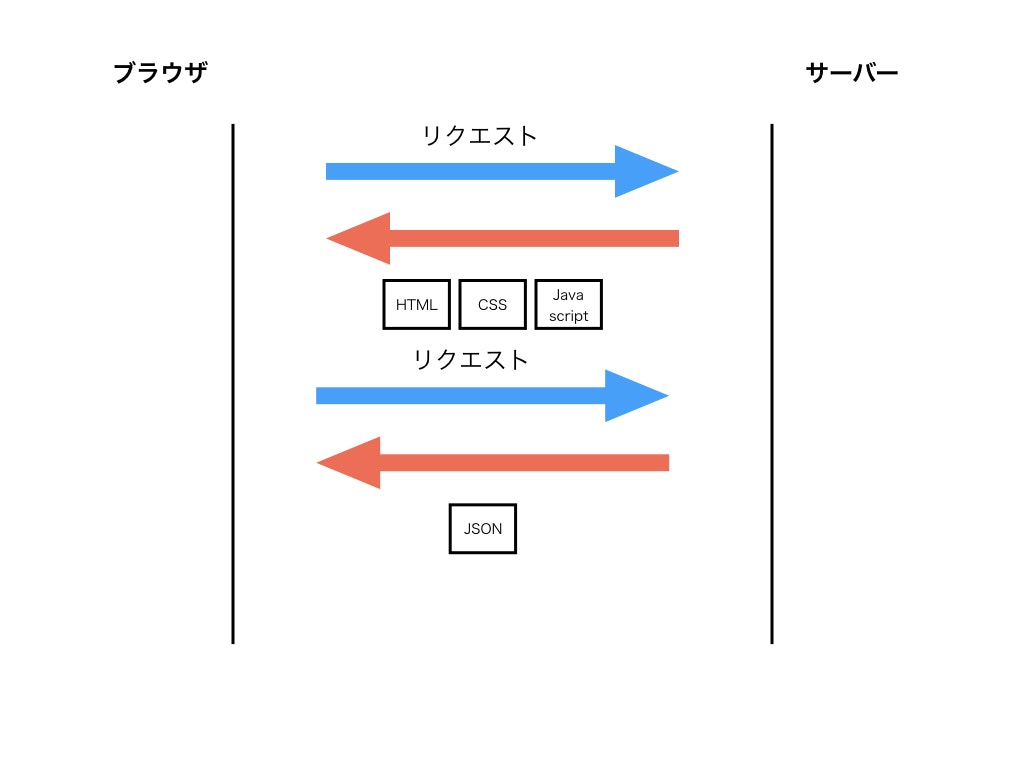
このJSONというデータ形式でやり取りすることになった影響により大きく変わりました。
非同期処理という概念が生まれ、それにより状態管理が必要になりました。
フロントエンドはこの状態管理と付き合うためにどうするかを考えるようになりました。
モダンなWebとサーバーサイドが意識すること
HTMLの分割
レガシーなWebページでは単一のHTML、CSS、Javascriptを使ってWebページを構成していました。
しかしこのような方式では以下のような弊害が発生しています。
- 巨大な状態管理を行う
- 巨大なデザイン管理を行う
このような問題を解決するために、JavascriptでHTMLを描画する仕組み≒仮想DOMをつかってHTMLを細かく分けることを行いました。
そして以下のような恩恵を受けることができました
- 状態を小さく切り分けて保守性を上げる
- デザインを小さく切り分けて保守性を上げる
その結果、サーバーから返すHTMLはメタタグなどの情報だけとなり、主要なコンテンツはJavascriptで書くケースが増えました。
リクエストをたくさん送る
レガシーなWebでは1リクエスト送るたびに、HTMLが返ってきました。
例えばメディアサイトの場合は記事、カテゴリ、コメントが描画されたHTMLが返ってきます。
しかし、モダンなWebでは要素ごとにリクエストを送ることがあります。
例えば、記事のデータ、カテゴリのデータ、コメントだけをリクエストしてJSONを受け取ります。
一つの画面で複数のリクエストを送るということが行われます。
このように複数のリクエストを送る事により、非同期処理という概念が誕生しました。
そしてその非同期処理によって以下のようなリクエスト処理が発生するようになります。
- 一度に複数のリクエストを送る
- Aというリクエストを送る、Aが完了してからBというリクエストを送る。(直列的なリクエスト)
- AとBというリクエストを同時に送り、その2つが完了してからCというリクエストを送る(並列的なリクエスト)
こういったように、処理が終了するのを待って、なにか別のことを行うという非同期処理を管理する必要が出てきました。
このようなリクエストを処理するために、axiosやRxJSといったライブラリを使うことがあります。
getArticle(): Observable<Article> {
return from(
// リクエスト処理
);
}
this.getArticle()
.subscribe(article => this.setState({ article: article }));
このような背景からサーバーサイドのエンジニアが知るべきことは以下のような感じです。
- リソースにアクセスするために 様々なAPIを用意する
- 単一のページでも、要件によっては一度に複数のリクエストが複雑に処理される
リクエストを処理する
リクエストを送るとJSONで帰ってきます。その後フロントエンドのコードでJSONからデータを抜き出し、描画します。
そのデータを処理を効率的に行うために、JSONのレスポンスをモデルに変換する手法が行われることがあります。
※ ネイティブアプリにおける、MoshiやGsonのような感じです。
以下のようなJSONのレスポンスがあるとします。
{
"data": {
"id": "1",
"type": "article",
"attributes": {
"id": 1,
"title": "テスト"
},
"relationships": {
"picture": {
"data": {
"id": "1",
"type": "picture"
}
}
}
},
"included": [
{
"id": "1",
"type": "picture",
"attributes": {
"id": 1,
"url": "sample.jpg",
}
}
]
}
それを以下のモデルにマッピングします。
export default class Article extends Model {
@json() public id: number;
@json() public title: string;
@json({ type: Picture }) public picture: Picture;
}
export default class Picture extends Model {
@json() public id: number;
@json() public url: string;
}
コンポーネントなどではこれらのモデルを使います。
type Props = {
article: Article;
};
type State = {};
export default class ArticleCard extends React.Component<Props, State> {
constructor(props) {
super(props);
}
render() {
const { article } = this.props;
return (
<div className={styles.card}>{article.title}</div>
);
}
}
このようにする理由としては
- パースの処理を共通化
- コンポーネントの処理の簡潔化
- モデルにメソッドをもたせることができる
- TypeScriptを導入することで、更に型安全な開発ができる
こういった背景があり、サーバーサイドのエンジニアは以下のようなことを考慮する必要があります。
- テーブル設計、正規化などはフロントエンドでのリクエストを送るタイミングや用途を考慮して設計する。
- データベースの構造が、JSONの形式に影響を与え、フロントエンドのモデルやロジックに影響を与えるため。
- オブジェクトにマッピングしやすいように、JSONに変換に対して責任を持つレイヤーを作成する
- Serializerクラスなどが当てはまります。
- フロントエンド側でモデル変換しやすいように、レスポンス定義を明確に決める。
- 各パラメータがNull(nil)を許容するかしないかを明確に決める
脱線しますが、Goでジェネリクス論争を見かけますが、このようなフロントエンドでの都合が要因もあるかもしれません。
エラーメッセージ
非同期処理が多くなると、フロントエンドでの状態も複雑になってきます。
主なところだと、リクエストの成功やエラーなどによって状態切り替えて処理を行います。
フロントエンドで発生するエラーとしては以下のようなものがあります。
- ネットワークに接続されていない
- JavaScriptのプログラムのバグやエラー
- リソースが見つからなかった
- 認証が通らなかった。
- ポストされたデータの値が不正である
- サーバー側のエラー
- サーバーが停止している
などがあります。
フロントエンドではこれらの様々なエラーメッセージによって状態を変えて適切にユーザーに通知する必要があります。
例えば、サーバーエラーの場合は再度リクエストを投げる、リソースがない場合は無いことをユーザーに通知するなどあります。
サーバーサイドのエンジニアは、様々なエラーを適切に返すということを行わなければならないです。
ページネーション

アプリやWebサービスで上記のように同じコンテンツが2回連続で並ぶ、という現象を見たことがあるかもしれません。
これはサーバーサイドがフロントエンドを意識して設計していないためです。
class Api::V1::ArticlesController < Api::ApplicationController
def index
articles = Article.page(params[:page]).per(3)
render json: Api::V1::ArticleSerializer.new(articles).serialized_json
end
end
上記のようなRailsのコードがあるとします。このコードはページに応じてコンテンツを3つ返します。
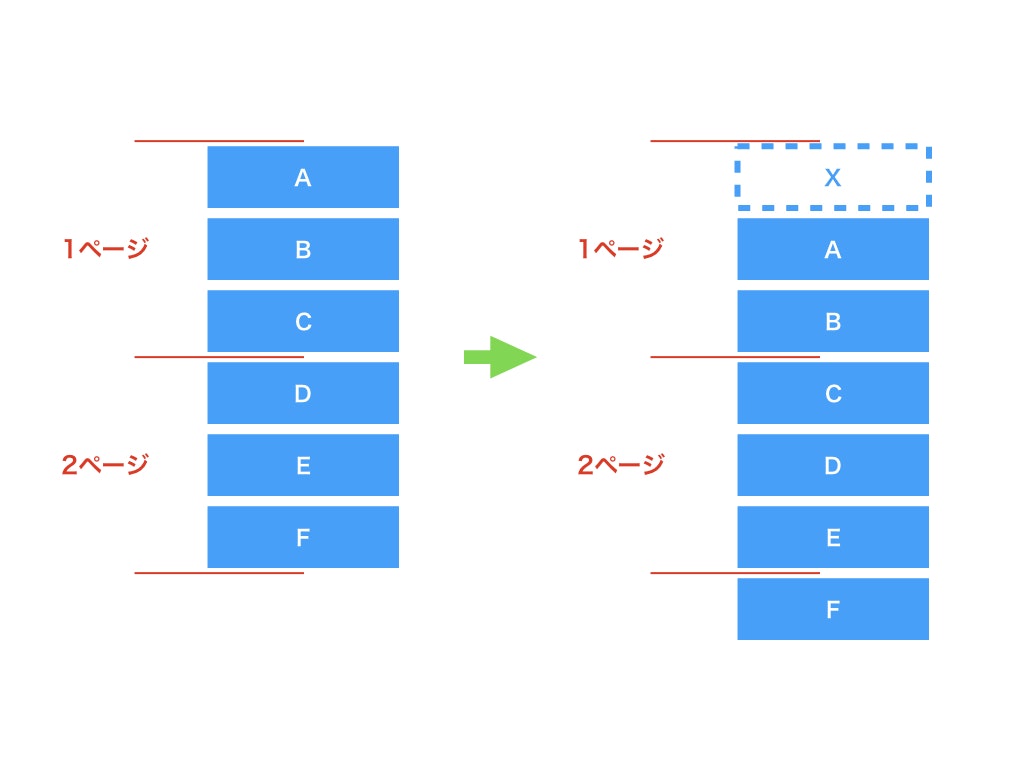
上記の画像のように、コンテンツがABCDEFとあるとします。
1ページ目はABC、2ページ目はDEFです。
あるユーザーがいたとして、一ページ目を読み込むと、ABCが読み込まれます。
その後2ページめを読む前に、Xが新規作成された場合、1ページ目と2ページ目のコンテンツの内容が変わります。
このときにユーザーが2ページめを読み込むとCDEが読み込まれてしまい、ユーザーに表示されるコンテンツはABCCDEとなっていまいます。
このような現象を防ぐためにサーバーサイドのエンジニアは以下のようなことを意識します。
- OFFSETとLIMITによる絶対位置的なページネーションではなく、コンテンツを指定した相対的なページネーションを実装する
- フロントエンドに差分を比較して表示する仕組みがある場合、それぞれのリソースにユニークなIDを付与してレスポンスに含めるようにする。
- 次のページや関連するコンテンツをJSON上で表現する仕組みを考える
- URLをレスポンスに含めるなど
これらを前提として有用なツール
これらの複雑な要件を実現するために多くのライブラリを使うということがスタンダートになりつつあります。
TypeScript
これらのモダンなWebの処理を型をつかって安全にかけます。
React / Vue など
仮想DOMのライブラリです。
状態管理も行うことができます。
Webpack
フロントエンドのライブラリを管理する仕組みです。
JavaにおけるMaven、Gradle、RubyにおけるBundlerのようなものです。
CDNWorker
Javascriptでレンダリングを行っているため、メタタグなどはJavascriptで描画できなかったが、それを解決できるかもしれないです。
Jestなど
複雑化したフロントエンドをテストするためのツールです。
終わりに
元スライドはツールやライブラリの紹介ばかりで、サーバーサイドのエンジニアがすべてを知るべきかといわれるとよくわからない感じでしたが、
それに対する批判も大昔のWebの知識を前提としているものがほとんどだったので、どっちが悪いとも言えなかったです。
そのため、解説記事みたいなのを書いてみました。