はじめに
LLM - Gemini Proでの開発にて 、OSSの実験管理ツールMLflowでそれっぽく実験管理を行ってみました。
※後述の自作クラスでは、最小限のログのみ記録しています。
実現したいこと
(VertexAI)Gemini Pro と LangChain にて、レスポンス速度を重視したLLMのプロダクト開発を試行しています。その中の関心ごとの1つとして実験管理があり、実現したいこととしては以下のような内容があります。
- WandB などの(無料では)商用不可なサービスを使わず 実験管理を行いたい
- プロンプトのinput / output / エラーを、LangChainライブラリの内部で生成しているプロンプトも含めて可視化したい
- なるべく自動でログを取得したい(Chainの変更などの仕様変更)
- 複数メンバーで結果をリアルタイムで共有したい
大枠の指針
今回は、下記の指針で対応しました。
MLflowを使う
OSSの実験管理ツールMLflowは、autolog(自動でログをトラッキング/送信する機能)の他に イベント実装でログを送信することもできます。
ログはMLflow Tracking Server をlocalhostで立てて、スクリプト内でトラッキング〜そのエンドポイントへログを送信し、自前の環境で実験管理を完結させることが可能です。
MLflowはLangChainでのautologにも対応しているようなのですが、
現状はHuggingFaceHubとOpenAIのみの対応のようです。
https://github.com/mlflow/mlflow/blob/master/mlflow/langchain/utils.py#L52
"MLflow does not guarantee support for LLMs outside of HuggingFaceHub and OpenAI, ...
今回はMLFlowのArtifactsに、jsonでそれっぽくログを記録し、MLflow Tracking UIプロント履歴を可視化することをゴールとします。
LangChainのCallbacksを使う
前述のようにMLflow + LangChain +
LangChainCallbacksを使うことで、llmのモデルにプロンプトを渡す際、Chainの開始/終了時に自作ののコールバックを呼ばせることが可能なので、このコールバックメソッドにMLflowのトラッキングのイベント実装を行います。
継承するクラス
コールバックのためのクラスは下記の2クラスあり、
- BaseCallbackHandlerクラス
- BaseTracerクラス
差異は、
`BaseTracer` class extends the `BaseCallbackHandler` class and provides a more specific interface for tracing runs in the LangChain framework. It includes methods for starting and ending traces for runs, persisting runs, and handling various events that can occur during a run, such as errors, retries, and the generation of new tokens.
とのことです。(今回は後の拡張も加味してBaseTracerクラスを使います)
LangChainのcallbackに設定するクラス例
以下は、LangChainのcallbackとして使用するMyTracerクラスの例です。このクラスはLangChainの各種イベント(開始、終了、エラー)に対して特定のアクションを定義し、MLflowにログを送信するように設計されています。
下記クラスでは、(VertexAI)Gemini Proに対応しています。
# callback
from langchain.callbacks.tracers.base import BaseTracer
# mlflow設定
import mlflow
mlflow.set_tracking_uri("http://localhost:5000")
mlflow.set_experiment("signal_detect")
class MyTracer(BaseTracer):
"""
MyTracerクラスはBaseTracerを継承し、
のトレースとログ記録を行います。
"""
def __init__(self):
"""
初期化メソッド。ログを格納するdictを初期化します。
"""
self.mlflow_log = {
"inputs": [],
"outputs": [],
"errors": [],
}
super().__init__()
def _persist_run(self, run):
print("Persisting run")
def on_llm_start(self, serialized, prompts, **kwargs):
"""
LLMの開始時に呼ばれるメソッド。入力をログに追加します。
"""
self.mlflow_log["inputs"].append(prompts)
super().on_llm_start(serialized, prompts, **kwargs)
def on_llm_end(self, response, *args, **kwargs):
"""
LLMの終了時に呼ばれるメソッド。出力とエラーをログに追加します。
"""
output = str(vars(response)).replace("\\n", "\n")
self.mlflow_log["outputs"].append(output)
self.mlflow_log["errors"].append("")
return super().on_llm_end(response, *args, **kwargs)
def on_llm_error(self, error, *args, **kwargs):
"""
LLMのエラー発生時に呼ばれるメソッド。エラーをログに追加します。
"""
self.mlflow_log["outputs"].append("")
self.mlflow_log["errors"].append(str(vars(error)))
return super().on_llm_error(error, *args, **kwargs)
def on_agent_action(self, action, *args, **kwargs):
"""
エージェントのアクション発生時に呼ばれるメソッド。
"""
return super().on_agent_action(action, *args, **kwargs)
def on_agent_finish(self, finish, *args, **kwargs):
"""
エージェントの終了時に呼ばれるメソッド。
"""
return super().on_agent_finish(finish, *args, **kwargs)
def on_tool_start(self, serialized, input_str, *args, **kwargs):
"""
ツールの開始時に呼ばれるメソッド。
"""
return super().on_tool_start(serialized, input_str, *args, **kwargs)
def on_tool_end(self, output, *args, **kwargs):
"""
ツールの終了時に呼ばれるメソッド。
"""
return super().on_tool_end(output, *args, **kwargs)
def on_tool_error(self, error, *args, **kwargs):
"""
ツールのエラー発生時に呼ばれるメソッド。
"""
return super().on_tool_error(error, *args, **kwargs)
def on_chain_start(self, serialized, inputs, *args, **kwargs):
"""
チェーンの開始時に呼ばれるメソッド。
"""
return super().on_chain_start(serialized, inputs, *args, **kwargs)
def on_chain_end(self, outputs, *args, **kwargs):
"""
チェーンの終了時に呼ばれるメソッド。
"""
print("mlflow.log_table")
return super().on_chain_end(outputs, *args, **kwargs)
使い方
以下のスクリプトでは、LangChainのllmにMyTracerクラスのコールバックを設定し、プロンプトをトラッキングしてローカルのMLflowサーバにログを送信します。
( 下記では llm に コールバックを設定していますが、Agentなども含め包括的にログを取得されたい場合は、chain.runやinvokeのcallbackへの設定も可能です。)
# MyTracerクラスを使用してトレースを設定
tracer = MyTracer()
# VertexAIモデルを設定
chat = VertexAI(
model_name="gemini-pro",
max_output_tokens=1024,
temperature=0,
top_p=0.8,
top_k=10,
callbacks=[tracer]
)
# チャットのプロンプトを設定
prompt = "あなたは誰?"
# MLflowの記録を開始
mlflow.start_run()
# チャットプロンプトテンプレートを生成し、チャットを開始
chain = (ChatPromptTemplate.from_template(prompt) | chat)
chain.invoke({})
# 追加のチャットを実行
chat("今日の天気は?")
# トラッキングログをMLflowサーバに送信し、結果を(artifactとして)保存
mlflow.log_table(data=tracer.mlflow_log, artifact_file="data_sample.json")
# MLflowの記録を終了
mlflow.end_run()
実行手順
事前準備
MLflowをインストール
pip install mlflow
今回は複数メンバーで結果をリアルタイムで共有するため、Gogole Driveをマウントして 共有フォルダ と sqliteのDBファイルを事前に作成し、各メンバーのスクリプト実行のディレクトリにシンボリックリンクを貼っています。
ln -s (共有フォルダ)/mlflow.db .
ln -s (共有フォルダ)/mlartifacts .
手順
- 別ターミナル などで MLflowサーバを起動します。
mlflow server --host 0.0.0.0 --backend-store-uri "sqlite:///mlflow.db"
-
MyTracerクラスを利用して、前述実装例のようにcallbackの設定とログ送信を実装します。
-
2.を実装したLLMのスクリプトを実行します。
python mlflow.py
- MLflowサーバにアクセスして実験結果を確認します。
http://localhost:5000
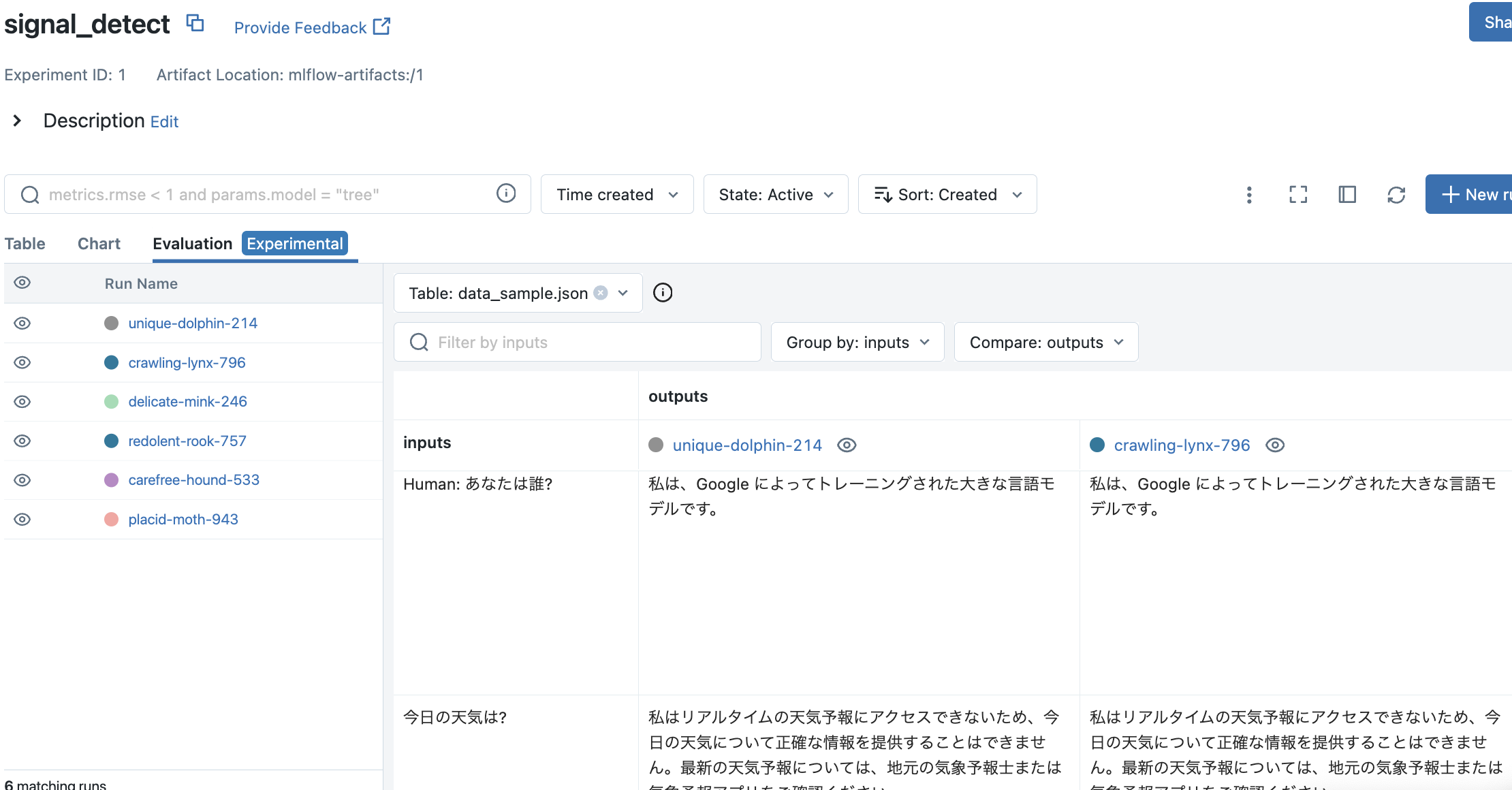
SSのように、Evaluationタブにプロンプト履歴が記録されました。
まとめ
GeminiなどはOpenAIと比較すると周辺エコシステムの対応が後追いなので、ひとまずは最低限の対応を行ってプロジェクトを進めていく対応が今後も求められそうです。
( LLM専用の実験管理ツールの対応にも今後期待...! )