はじめに
MPIを使って並列処理をする際に必要な準備やコマンド、ホストファイルの書き方を勉強したので、ここにざっとメモっときます。
以下の説明ではCentOS7で実行する場合を想定しています。
(追記: 2/22)
ホストファイルの書き方の説明を一部修正しました。
(プロセス割り当ての設定の書き方が、MPICHとOpenMPIとで違っていました)
MPIとは
MPI (Message Passing Interface) は、並列コンピューティングを利用するための標準化された規格のことです。
並列処理には共有メモリ型と分散メモリ型の2通りの処理形態がありますが、MPIは分散メモリ型の並列処理を行います。
(共有メモリ型の並列処理を行うものにはOpenMPなどがあります)
MPIの主な実装としてはMPICH (エムピッチ) とOpenMPI (オープンエムピーアイ) などがありますが、基本的な使い方はほぼ同じなようです。
(コマンドの詳細なオプションとかプロセス間通信のアルゴリズム等で違いがあるようです)
ただし、一つのノードにMPICHとOpenMPIを両方インストールすると競合してエラーが出る場合があるようです。どちらか片方だけを選びましょう。
MPIのインストール
MPICHやOpenMPIのインストールはyumで行えます。このとき、mpich-develやopenmpi-develのようなdevelパッケージも合わせてインストールしておきましょう。(これが無いとMPIを使ったプログラムのコンパイルができません)
インストール後は、MPI関係のコマンドが使えるようにパスを通しておく必要があります。
/usr/lib64/mpich/binまたは/usr/lib64/openmpi/binにパスを通しておいてください。
MPIのプログラム
MPIを使って並列処理する場合には、MPIのAPIを使ってC, C++, Fortranなどでコードを書き、それをmpiccなどのMPIに対応したコンパイラでコンパイルする必要があります。(ここではMPIプログラミングについて詳しく触れることはしません)
以下の説明では、sample.cをmpiccでコンパイルしたsampleというプログラムを使います。これは「各プロセスが自身のランクと自身が起動しているホスト名を表示する」という単純なものです。
#include <stdio.h>
#include <mpi.h>
int main(int argc, char *argv){
int rank, proc; // ランク, 全プロセス数
int name_length = 10; // ホスト名の長さ
char *name[name_length]; // ホスト名
MPI_Init(&argc, &argv); // MPIの初期化
MPI_Comm_rank(MPI_COMM_WORLD, &rank); // ランクの取得
MPI_Comm_size(MPI_COMM_WORLD, &proc); // 全プロセス数の取得
MPI_Get_processor_name(name, &name_length); // ホスト名の取得
printf("%s : %d of %d\n", name, rank, proc); // 結果の表示
MPI_Finalize(); // MPIの終了処理
return 0;
}
ちなみに、MPIのAPIを使わず普通にコンパイルされたプログラムをMPIで並列実行すると、同じプロセスを独立に複数起動した場合と同じ効果が得られます。
例えばlsコマンドをMPIで3並列で起動した場合、lsを3回起動した分の標準出力が得られます。
MPIによる並列処理
MPIでは次の2通りの並列処理ができます。
1. 単一ノード上での複数プロセスによる並列処理
2. 複数ノード上での複数プロセスによる並列処理
1. 単一ノード上での複数プロセスによる並列処理
一つのノード上で複数のプロセスを起動し、それらの間で通信しながら並列処理を行います。全プロセスが同一ホスト上にあるので、外部ネットワークを利用しません。
並列数が増えれば処理がより細かく分散されるので処理時間が短くなっていきますが、並列数が多すぎると高頻度のプロセス間通信やコンテキストスイッチの影響で逆に処理時間が長くなってしまいます。搭載CPUのコア数と近しい数の並列数で実行するのが良いと思います。
実行方法
mpirunというコマンドを使って、複数プロセスによる並列処理を行います。(mpiexecでもOKです。mpirunとmpiexecはほぼ同じ内容のコマンドです)
mpirunの使い方は以下の通りです。並列数は-npオプションで指定します。
(-npの代わりに-nも使うことも可能です)
$ mpirun -np <並列数> <実行コマンド>
(例) sampleを4並列で実行する
$ mpirun -np 4 ./sample
ホスト名がnode01なら、このコマンドを実行すると以下のように表示されます。
node01 : 0 of 4
node01 : 2 of 4
node01 : 1 of 4
node01 : 3 of 4
MPIによって起動された各プロセスにはそれぞれ、「ランク」と呼ばれる0から始まる識別番号が付与されます。 このランクの値によって各プロセスの処理の内容を制御することができます。(if文による分岐などを利用します)
今回の場合はランクが0,2,1,3の順にプロセスが終了していることが分かります。プロセスが終了する順序は一定ではないので、この結果の表示は毎回変わります。
"-np <並列数> <実行コマンド>"の組を複数指定して実行することもできます。この場合は":"で区切ります。"-np <並列数> <実行コマンド>"の組は":"で区切ることでいくらでも追加できます。
$ mpirun -np <並列数> <実行コマンド> : -np <並列数> <実行コマンド> : … : -np <並列数> <実行コマンド>
(例)sample1を2並列で実行し、なおかつsample2を3並列で実行する
$ mpirun -np 2 ./sample1 : -np 3 ./sample2
この場合は、sample1が2並列で実行されると同時にsample2が3並列で実行されます。
2. 複数ノード上での複数プロセスによる並列処理
複数のノードにまたがって複数のプロセスを起動し、それらの間で互いに通信しながら並列処理を行います。各プロセスが異なるホスト上にあるので、外部ネットワークを利用してプロセス間通信を行います。
外部ネットワークを利用するためには、SSH・NFS・ホストファイルを準備する必要があります。
複数ノード上での並列処理を実行するには、当然ですが複数台の物理マシンが必要になります。「物理マシン1台しか持ってないけどやってみたい」という方は、仮想マシンを利用すると良いかと思います。(当然、物理マシン利用時よりも並列処理の性能は落ちますが)
Dockerコンテナを使っても可能です。(仮想マシンより環境構築が複雑になりますが)
マスターノードとスレーブノード
複数ノードによるMPIにおいて、ノードは「マスターノード」と「スレーブノード」の2種類に分けられます。
「マスターノード」は、担当分の処理を行うと同時に並列処理の制御や結果の集約を担当するノードです。もっと詳しく言うと、ランクが0のプロセス (マスタープロセス) が動作するノードです。このノードは1台だけです。
「スレーブノード」は、マスターノードと連携して担当分の処理を行うノードです。このノードは一般に複数台あります。
マスターノードは、パスフレーズ無しのRSA認証が可能なSSHによって自身及び各スレーブノードにログインできる状態にする必要があります。
(各スレーブノードからマスターノード及びスレーブノード間でのSSHの準備は不要です)
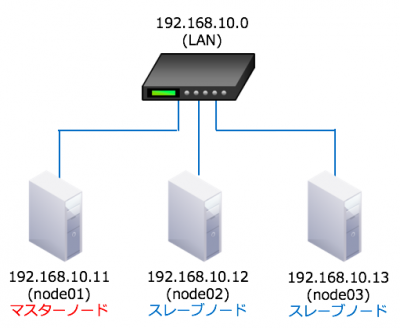
今回の説明では、以下のようなノード構成でMPIを利用することを想定します。
・マスターノード (IP: 192.168.10.11, ホスト名: node01)
・スレーブノード (IP: 192.168.10.12, ホスト名: node02)
・スレーブノード (IP: 192.168.10.13, ホスト名: node03)
・全てのノードは同一のLAN内にあり、互いにpingが通る状態である
(1) パスフレーズ無し認証のSSHとMPIの準備
MPIを使うためには、パスフレーズ無しのRSA認証が可能な状態にする必要があります。また、ファイアウォール等のセキュリティ機能を停止させる必要もあります。
以下の通りに準備を行っていきます。
a. 全ノードで同じユーザ名のアカウントを作る (ここではuserというアカウントを作ることにします)
$ useradd user
b. 全ノードでopenssh-serverをインストールする
$ sudo yum -y install openssh openssh-server
c. マスターノードでopenssh-clientsをインストールする
$ sudo yum -y install openssh-clients
d. 全ノードで/etc/ssh/sshd_configを編集する (以下の箇所で#を削除し有効化)
#PubkeyAuthentication yes → PubkeyAuthentication yes
e. 全ノードでsshdを再起動して、設定変更を反映する
$ sudo systemctl restart sshd
f. マスターノードでパスフレーズ無しのRSA鍵を生成(1個でよい)
$ ssh-keygen -t rsa -N "" -f ~/.ssh/id_rsa
g. 公開鍵を全ノード(マスターノード含む)に転送し、authorized_keyに書き込む(全て同一の鍵を使う)
$ cat id_rsa.pub >> authorized_key
h. マスターノードから自身を含め全ノードに1回ずつログインしておく (known_hostsに登録しておくためで、やっておかないとMPI利用時が接続できないで止まる)
sshのconfigに'StrictHostKeyChecking=no'を設定する方法もアリです。
i. 全ノードでmpich or openmpiをインストールする (全ノードで片方に統一すること)
# MPICHの場合
$ sudo yum -y install mpich mpich-devel
# OpenMPIの場合
$ sudo yum -y install openmpi openmpi-devel
j. 全ノードで、1.で作ったユーザの.bash_profileを変更してmpirunコマンドのパスを通す
k. 全ノードのファイアウォール・iptables・SELinuxを停止する (これらを停止しないとMPIは動かない)
MPIはSSH用のポート以外にも、各ノードでランダムにポートを選んで利用します。そのため、MPI利用時にはファイアウォールを停止しておくのがセオリーです。
$ sudo systemctl stop firewalld
$ sudo systemctl stop iptables
$ sudo setenforce 0
以上で(1)は終了です。次はNFSの設定です。
(2) NFSの設定
NFS (Network File System) は分散ファイルシステムの一種で、あるノードが所有する1つのディレクトリを、他の複数のノードで共有(マウント)して使うための仕組みです。これを使うことで、全ノードでファイルシステムの同じ位置に同じファイルの入ったディレクトリを簡単に共有することができます。
NFSを使うのは、MPIを使う際には実行ファイルが全ノードで同じ位置に置かれている必要があるからです。 もちろん、NFSを使わずに、手動で全ノードの同じ場所に同じ名前のディレクトリを作り、その中に同じ実行ファイルや利用するファイルを置いても構いません。(割と面倒くさいですが)
NFSの設定方法の説明については、ここでは省略します。以下のページを参考にしてください。
(/etc/exportsで設定するパーミッションには、(rw,no_root_squash)を使ってください)
CentOS7でNFSサーバを構築してみた
http://qiita.com/tanuki-project/items/5c706b2eab6e7eed71fd
今回は、マスターノードの/home/user/shareを、各スレーブノードの/home/user/shareにマウントしたとします。
(3) ホストファイルの準備
MPIを使うためには、マスターノードに「ホストファイル」というテキストファイルを置く必要があります。ホストファイルは、拡張子や名前、配置場所などに指定はありません。
今回はhostという名前のホストファイルを/home/user/share以下に置くことにします。(実行するプログラムと一緒に置いている方が無難かと)
ホストファイルに書くのは各ノードのIPアドレス or ホスト名です。一行目に書いたIP(ホスト名)のノードがマスターノードになります。
また、ホストファイル内では__#以降はコメント扱いになります。__
(注意)
ホスト名を使う場合は、使用するホスト名の名前解決ができないといけません。また、各スレーブノードに対応するホスト名が設定されている必要もあります。必要に応じて全ノードの/etc/hostsを書き換えておきましょう。
・ホストファイルの例 (1)
# IPアドレスを使った場合
192.168.10.11 # マスターノード
192.168.10.12 # スレーブノード
192.168.10.13 # スレーブノード
・ホストファイルの例 (2)
# ホスト名を使った場合
node01 # マスターノード
node02 # スレーブノード
node03 # スレーブノード
ホストファイルが書けたら、環境構築は完了です。
複数ホスト上にまたがってのMPIプログラムの実行
ようやくMPIプログラムを実行できます。まず、NFSで共有しているディレクトリへ移動します。
$ cd /home/user/share # 中身はsample.c(ソースコード), sample(実行ファイル), host(ホストファイル)
次にmpirunコマンド(またはmpiexecコマンド)でsampleを並列実行します。このとき、--hostfileオプション(または--machinefileオプション)を利用してホストファイルを参照します。
$ mpirun --hostfile <ホストファイルのパス> -np <並列数> <実行コマンド> : -np <並列数> <実行コマンド> : … : -np <並列数> <実行コマンド>
今回はnode01, node02, node03上でsampleを3プロセスだけ並列実行させることにします。
$ mpirun --hostfile host -np 3 ./sample
このコマンドを実行すると以下のように表示されます。
node01 : 0 of 3
node03 : 2 of 3
node02 : 1 of 3
各プロセスが終了する順番は毎回バラバラなので、出力結果の順番は毎回異なります。しかし、node01には必ずランク0のプロセスが、node02には必ずランク1のプロセスが、node03には必ずランク2のプロセスが起動していることを確認できます。これは、ホストファイル内で列挙したIP・ホスト名の順番に関係しています。
各ノードへの実行プロセスの割り振りは、ホストファイル内で列挙された順番に上から沿って行われます。 例えば、ホストファイルが
node01 # マスターノード
node02 # スレーブノード
node03 # スレーブノード
となっていた場合に、mpirun --hostfile host -np 10 ./sampleを実行すると、
・node01上でランク0のプロセスを起動
・node02上でランク1のプロセスを起動
・node03上でランク2のプロセスを起動
・node01上でランク3のプロセスを起動
・node02上でランク4のプロセスを起動
・
・
・
・node01上でランク9のプロセスを起動
という風なローテーションで各プロセスが割り振られていきます。
1つのノードに連続したランクのプロセスを割り当てることもできます。(OpenMPIとMPICHで書き方が異なります)
例えば、ホストファイルが
# MPICHの場合
node01:2 # マスターノード (2プロセス割り当て)
node02:3 # スレーブノード (3プロセス割り当て)
node03:1 # スレーブノード (1プロセス割り当て)
# OpenMPIの場合
node01 slots=2 # マスターノード (2プロセス割り当て)
node02 slots=3 # スレーブノード (3プロセス割り当て)
node03 slots=1 # スレーブノード (1プロセス割り当て)
となっていた場合に、mpirun --hostfile host -np 10 ./sampleを実行すると、
・node01上でランク0のプロセスを起動
・node01上でランク1のプロセスを起動
・node02上でランク2のプロセスを起動
・node02上でランク3のプロセスを起動
・node02上でランク4のプロセスを起動
・node03上でランク5のプロセスを起動
・node01上でランク6のプロセスを起動
・node01上でランク7のプロセスを起動
・node02上でランク8のプロセスを起動
・node02上でランク9のプロセスを起動
という風なローテーションで各プロセスが割り振られていきます。
おわりに
何か間違っている点などに気づかれましたら、コメントにてお知らせください。この記事がMPIを使おうとしている方の助けになれば幸いです。