やりたいこと
- Twitterの肉食女子大生アカウント 暇な女子大生のツイートをテキストマイニング
- 暇な女子大生がよく使う単語の可視化
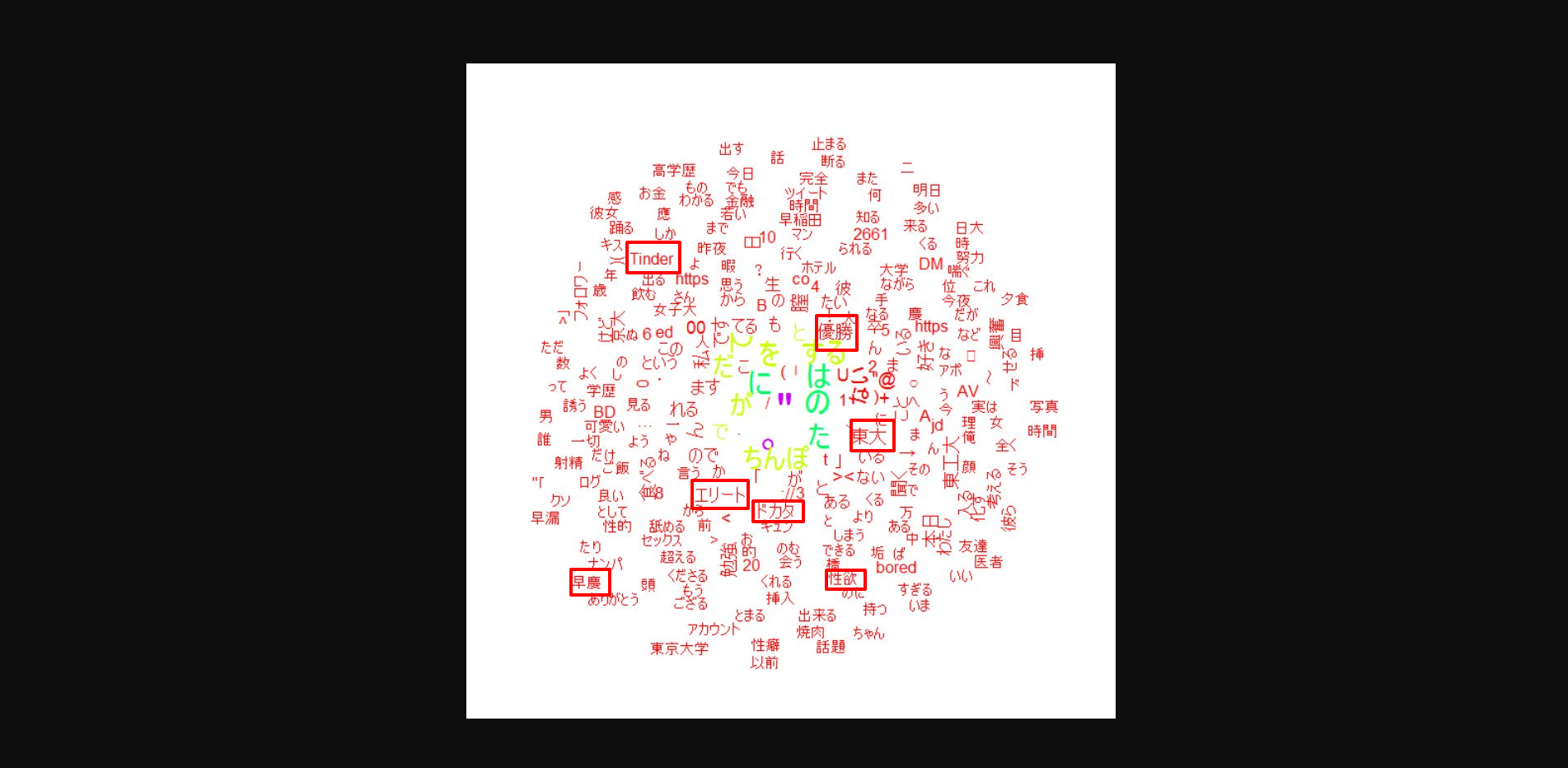
結果
- 優勝、エリート、ドカタ、早慶、東大、Tinderなどの言葉が検出された
ソースコード
textmining.r
# TwitteR
consumerKey <- "Consumer Key (API Key)を入力"
consumerSecret <- "Consumer Secret (API Secret)を入力"
accessToken <- "Access Tokenを入力"
accessSecret <- "Access Token Secretを入力"
setup_twitter_oauth(consumerKey, consumerSecret, accessToken, accessSecret)
# 過去2000件のツイートを分析
tweets <- userTimeline("boredjd", n = 2000)
# データフレームに変換し、テキスト部分だけを指定しツイートを取得
tweets <- twListToDF(tweets) #これでデータフレームにできます
tweets <- tweets$text #テキストデータだけ取得します
# テキスト変換
write.table(tweets,"tweets.txt") #一時的にテキストデータに保存します
# 日本語テキストの解析用に、パッケージ「RMeCab」を呼び出し、名刺、形容詞、動詞のみ抽出
tweetsFrq <- RMeCabFreq("tweets.txt")
tweetsFrq2 <- tweetsFrq %>% filter(Freq>10&Freq<400, Info1 %in% c("名詞"), Info2 != "数")
# URLや@などを削除
tweetsFrq2 <- gsub("^RT\\s@[0-9a-zA-Z\\._]*:\\s+","",tweetsFrq2 )
tweetsFrq2 <- gsub("https?://t.co/[0-9a-zA-Z\\._]*","",tweetsFrq2 )
wordcloud(tweetsFrq$Term,tweetsFrq$Freq,random.order=FALSE,
color=rainbow(5),random.color=FALSE,scale=c(3,1),min.freq=10)
参考
- 詳しい実装方法はこちらの記事を参考にしてください
【R】テキストマイニングを利用して、東京ちんこ倶楽部と暇な女子大生を分析する
https://review-of-my-life.blogspot.jp/2017/08/r-text-mining.html