はじめに
Microsoft Build 2023の発表で、AzureMLのアップデートがいくつか入りました。今回はHugging Faceに登録されているモデルをエンドポイントへデプロイできる『モデルカタログ』という機能を触ってみます。
デプロイするモデルはOpenAIのWhisperを使ってみます。
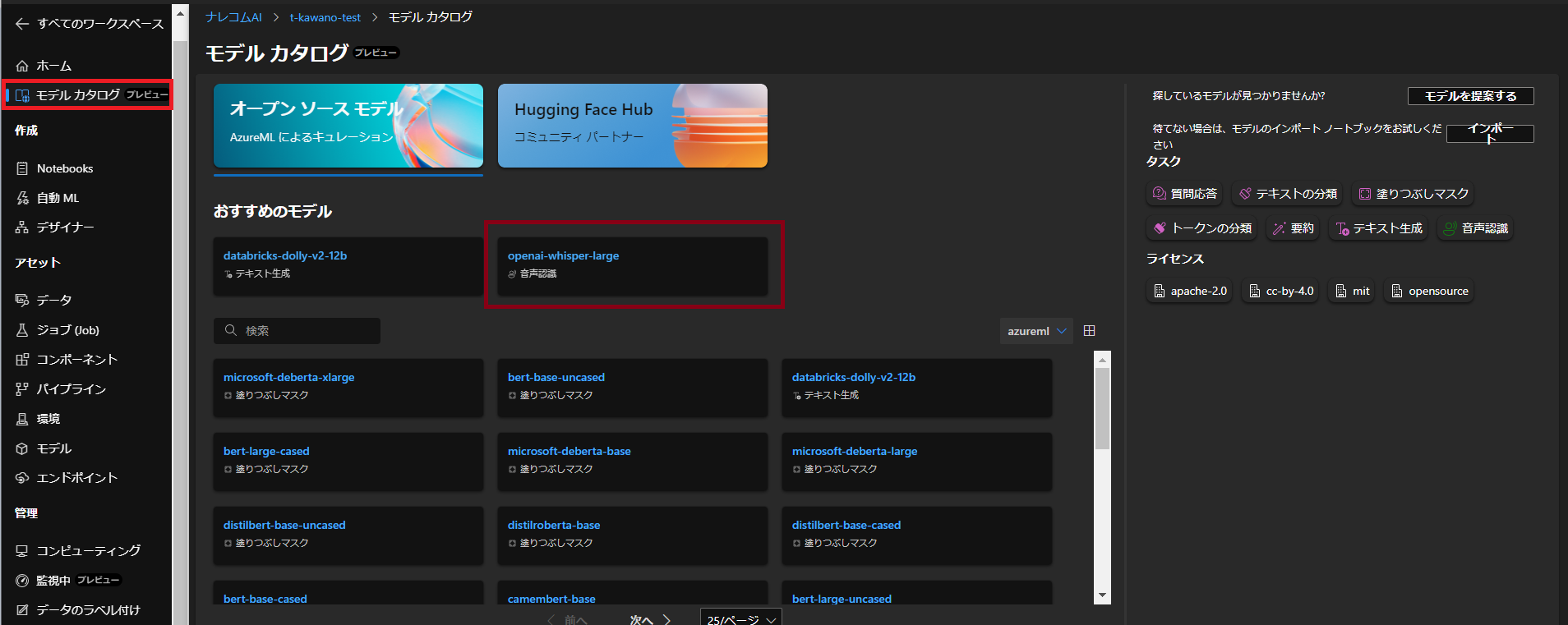
OpenAI Whisper
WhisperはOpenAIによって訓練され、オープンソース化された自動音声認識システムです。
今回試す音声は「あんまりむずかしく考えすぎるといろいろ大変だしね、しっかり反省したらぱぱっと次行こう!」というセリフが入っています。この音声を文字起こししてみましょう。
(音声素材提供:あみたろの声素材工房 https://amitaro.net/)
まずは「デプロイ」ボタンから「リアルタイム エンドポイント」を選択します。
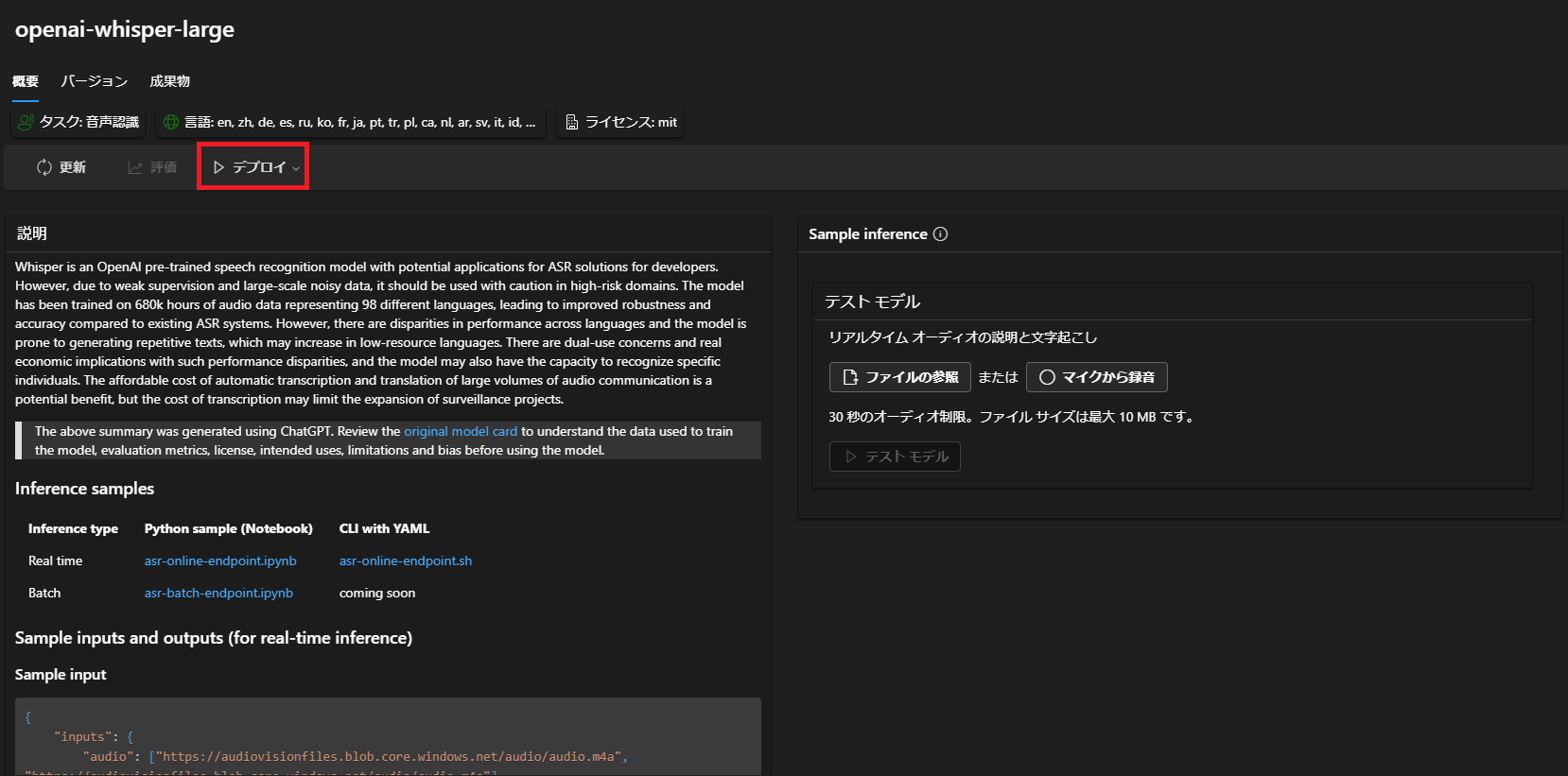
続いてデプロイの詳細。
仮想マシンは「Standard_E8s_v3」を選択し、デプロイします。
そして約10分後...デプロイが完了しました。
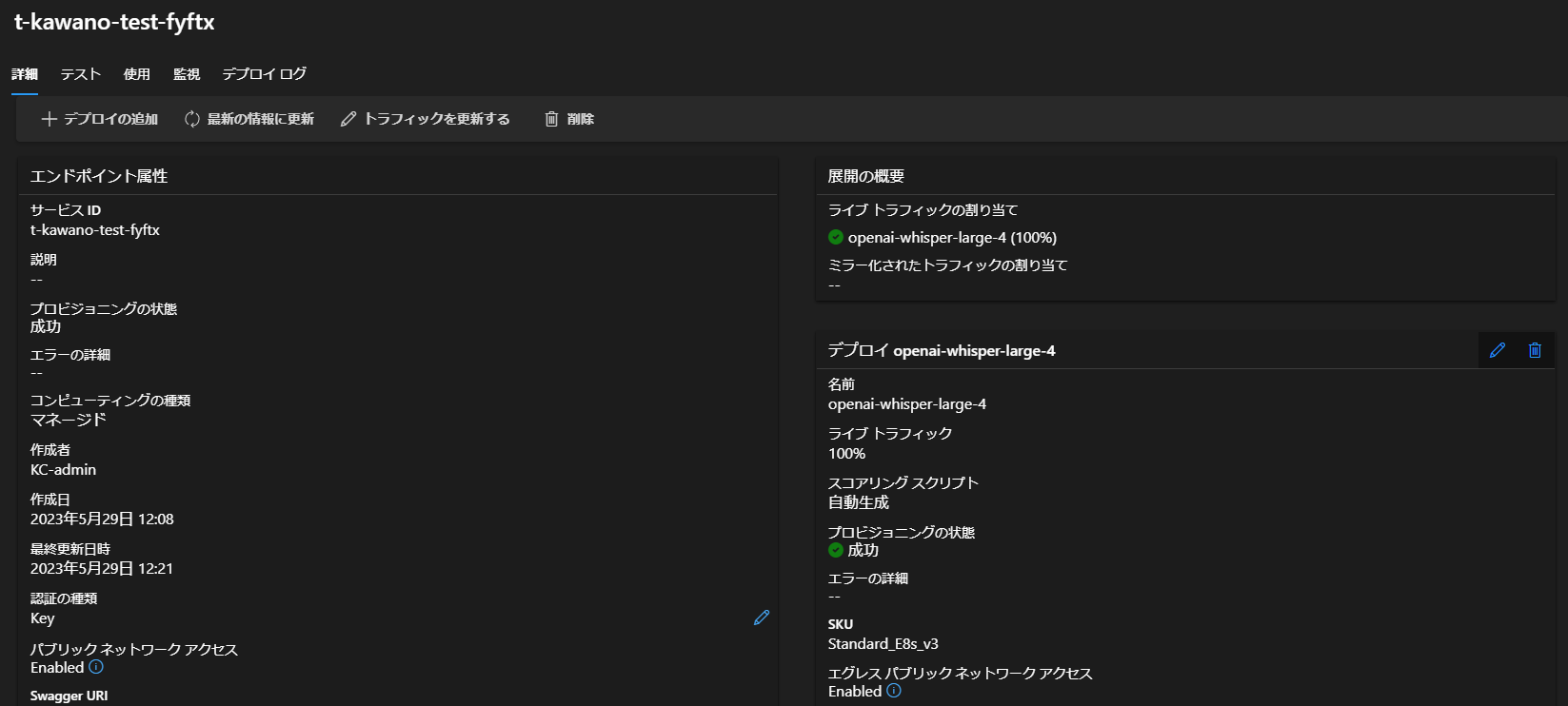
今回もPythoneでAPIを叩いてみようと思います。
「使用」タブに移り、コードをコピペします。

そのままのコードではUnicodeエスケープシーケンスにより日本語での出力ができないので変更します。
また、音声サイトの直リンクを使うのではなく、ローカルファイルから音声データを送りたいのでそこも追加しました。
以下が編集したコードです。
import re
import urllib.request
import json
import os
import ssl
import base64
def allowSelfSignedHttps(allowed):
# bypass the server certificate verification on client side
if allowed and not os.environ.get('PYTHONHTTPSVERIFY', '') and getattr(ssl, '_create_unverified_context', None):
ssl._create_default_https_context = ssl._create_unverified_context
allowSelfSignedHttps(True) # this line is needed if you use self-signed certificate in your scoring service.
# Request data goes here
# The example below assumes JSON formatting which may be updated
# depending on the format your endpoint expects.
# More information can be found here:
# https://docs.microsoft.com/azure/machine-learning/how-to-deploy-advanced-entry-script
with open("<音声ファイルのパス>", "rb") as audio_file:
encoded_audio = base64.b64encode(audio_file.read()).decode('utf-8')
data = {
"inputs": {
"audio": [encoded_audio],
"language": ["ja"]
}
}
body = str.encode(json.dumps(data))
url = 'https://XXX.japaneast.inference.ml.azure.com/score'
# Replace this with the primary/secondary key or AMLToken for the endpoint
api_key = '<API Key>'
if not api_key:
raise Exception("A key should be provided to invoke the endpoint")
# The azureml-model-deployment header will force the request to go to a specific deployment.
# Remove this header to have the request observe the endpoint traffic rules
headers = {'Content-Type':'application/json', 'Authorization':('Bearer '+ api_key), 'azureml-model-deployment': 'openai-whisper-large-4' }
req = urllib.request.Request(url, body, headers)
try:
response = urllib.request.urlopen(req)
result = response.read()
result_str = result.decode("utf-8")
data=json.loads(result_str)
print(data)
except urllib.error.HTTPError as error:
print("The request failed with status code: " + str(error.code))
# Print the headers - they include the requert ID and the timestamp, which are useful for debugging the failure
print(error.info())
print(error.read().decode("utf8", 'ignore'))
ローカルの音声ファイルのパスとAPIキーを入力したら、実行してみます。
(APIキーは「使用」タブの「主キー」から取得可能)
結果はこちら
[{'text': 'あんまり難しく考えすぎると色々大変だすねしっかり反省したらパパッと次行こう!'}]
「大変だすね」になってしまっていますが…ほぼ完ぺきに文字起こしができてます!
ちなみに別の音声では一語一句違わずにできました。
[{'text': '優先席付近では携帯電話はマナーモードにしていただくか電源をお切りください'}]
感想
本来、Whisperでは翻訳もできるみたいですが、Azureの方では使い方がわかりませんでした・・・。
引き続き、調べてみます!