はじめに
今回はAzureMLのプロンプトフローを試してみます。いくつかサンプルフローがありますが、今回はAsk Wikipediaを試します。
Ask Wikipedia
それでは試してみましょう!
まず、プロンプトフローを「作成」すると、このようにいくつかサンプルのフローが表示されます。

今回はこのうちのAsk Wikipediaのサンプルフローを使います。
Azure OpenAIの接続
はじめにプロンプトフローではLLM接続が必要となってくるため、すでにデプロイしたAzure OpenAIのモデルに接続します。
「接続」タブの「作成」から下記の必要な項目を入力してください。

Runtimeの作成
続いてプロンプトフローを実行するにあたり、Runtimeの作成を行う必要があります。
「ランタイム」タブをクリックし、「作成」をすると「マネージドオンラインエンドポイントデプロイ」と「コンピューティングインスタンス」のどちらかを選択できるようになります。
今回は推奨されている「コンピューティングインスタンス」でRuntimeを作成します。

「AzureMLコンピューティングインスタンスを作成する」をクリックし、

「コンピューティング名」や仮想マシンのサイズを選びます。

数分待てば、コンピューティングインスタンスが作成されるので、完了したら「ランタイム名」を入力し、Runtimeを作成します。

処理の流れ
このプロンプトフローでは、Wikipediaの情報を用いて質問に答えるものです。
Wikipediaのソースを使用して、情報を取得し、プロンプトを補強して回答を生成します。
Ask Wikipediaのサンプルを作成すると、次のような画面になります。「入力」と「出力」でユーザーの質問を記載できるようになっています。
デフォルトで「When did OpenAI announce GPT-4?」という質問がすでに入力されているので、今回はそのまま実行してどんな結果が返ってくるか見てみます!

Ask Wikipediaのプロンプトフローでは下記のような流れで処理が行われます。

1つずつ処理の流れを見ていきます。
・get_wiki_url
ユーザーが入力した「When did OpenAI announce GPT-4?」をrequestsからWikipediaで検索し、その結果のうち上位2つのページのURLを取得します。
from promptflow import tool
import requests
import bs4
import re
def decode_str(string):
return string.encode().decode("unicode-escape").encode("latin1").decode("utf-8")
def remove_nested_parentheses(string):
pattern = r'\([^()]+\)'
while re.search(pattern, string):
string = re.sub(pattern, '', string)
return string
@tool
def get_wiki_url(entity: str, count=2):
# Send a request to the URL
url = f"https://en.wikipedia.org/w/index.php?search={entity}"
url_list = []
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.35"}
response = requests.get(url, headers=headers)
if response.status_code == 200:
# Parse the HTML content using BeautifulSoup
soup = bs4.BeautifulSoup(response.text, 'html.parser')
mw_divs = soup.find_all("div", {"class": "mw-search-result-heading"})
if mw_divs: # mismatch
result_titles = [decode_str(div.get_text().strip()) for div in mw_divs]
result_titles = [remove_nested_parentheses(result_title) for result_title in result_titles]
print(f"Could not find {entity}. Similar ententity: {result_titles[:count]}.")
url_list.extend([f"https://en.wikipedia.org/w/index.php?search={result_title}" for result_title in
result_titles])
else:
page_content = [p_ul.get_text().strip() for p_ul in soup.find_all("p") + soup.find_all("ul")]
if any("may refer to:" in p for p in page_content):
url_list.extend(get_wiki_url("[" + entity + "]"))
else:
url_list.append(url)
else:
msg = f"Get url failed with status code {response.status_code}.\nURL: {url}\nResponse: " \
f"{response.text[:100]}"
print(msg)
return url_list[:count]
except Exception as e:
print("Get url failed with error: {}".format(e))
return url_list
下記のように入力を行い、
{
"entity":"When did OpenAI announce GPT-4?"
"count":2
}
このフローの出力はこちらのようになりました。
[
0:{
"system_metrics":{
"duration":1.723954
}
"output":[
0:"https://en.wikipedia.org/w/index.php?search=GPT-4"
1:"https://en.wikipedia.org/w/index.php?search=ChatGPT"
]
}
]
GPT-4とChatGPTの2つのページのURLを取得したようです。
・search_result_from_url
先ほど取得したURLのページからテキストを取得します。各リクエストの結果はリストとして、URLとそのテキストをまとめて返します。
from promptflow import tool
import requests
import bs4
import time
import random
from concurrent.futures import ThreadPoolExecutor
from functools import partial
session = requests.Session()
def decode_str(string):
return string.encode().decode("unicode-escape").encode("latin1").decode("utf-8")
def get_page_sentence(page, count: int = 10):
# find all paragraphs
paragraphs = page.split("\n")
paragraphs = [p.strip() for p in paragraphs if p.strip()]
# find all sentence
sentences = []
for p in paragraphs:
sentences += p.split('. ')
sentences = [s.strip() + '.' for s in sentences if s.strip()]
# get first `count` number of sentences
return ' '.join(sentences[:count])
def fetch_text_content_from_url(url: str, count: int = 10):
# Send a request to the URL
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.35"
}
delay = random.uniform(0, 0.5)
time.sleep(delay)
response = session.get(url, headers=headers)
if response.status_code == 200:
# Parse the HTML content using BeautifulSoup
soup = bs4.BeautifulSoup(response.text, 'html.parser')
page_content = [p_ul.get_text().strip() for p_ul in soup.find_all("p") + soup.find_all("ul")]
page = ""
for content in page_content:
if len(content.split(" ")) > 2:
page += decode_str(content)
if not content.endswith("\n"):
page += "\n"
text = get_page_sentence(page, count=count)
return (url, text)
else:
msg = f"Get url failed with status code {response.status_code}.\nURL: {url}\nResponse: " \
f"{response.text[:100]}"
print(msg)
return (url, "No available content")
except Exception as e:
print("Get url failed with error: {}".format(e))
return (url, "No available content")
@tool
def search_result_from_url(url_list: list, count: int = 10):
results = []
partial_func_of_fetch_text_content_from_url = partial(fetch_text_content_from_url, count=count)
with ThreadPoolExecutor(max_workers=5) as executor:
futures = executor.map(partial_func_of_fetch_text_content_from_url, url_list)
for feature in futures:
results.append(feature)
return results
このフローの出力は下記のようになりました。
[
0:{
"system_metrics":{
"duration":2.312796
}
"output":[
0:[
0:"https://en.wikipedia.org/w/index.php?search=GPT-4"
1:"Generative Pre-trained Transformer 4 (GPT-4) is a multimodal large language model created by OpenAI, and the fourth in its series of GPT foundation models.[1] It was initially released on March 14, 2023,[1] and has been made publicly available via the paid chatbot product ChatGPT Plus, and via OpenAI's API.[2] As a transformer-based model, GPT-4 uses a paradigm where pre-training using both public data and "data licensed from third-party providers" is used to predict the next token. After this step, the model was then fine-tuned with reinforcement learning feedback from humans and AI for human alignment and policy compliance.[3]: 2. Observers reported that the iteration of ChatGPT using GPT-4 was an improvement on the previous iteration based on GPT-3.5, with the caveat that GPT-4 retains some of the problems with earlier revisions.[4] GPT-4 is also capable of taking images as input, though this feature has not been made available since launch.[5][6] OpenAI has declined to reveal various technical details and statistics about GPT-4, such as the precise size of the model.[7]. OpenAI introduced the first GPT model (GPT-1) in 2018, publishing a paper called "Improving Language Understanding by Generative Pre-Training."[8] It was based on the transformer architecture and trained on a large corpus of books.[9] The next year, they introduced GPT-2, a larger model that could generate coherent text.[10] In 2020, they introduced GPT-3, a model with 100 times as many parameters as GPT-2, that could perform various tasks with few examples.[11] GPT-3 was further improved into GPT-3.5, which was used to create the chatbot product ChatGPT.. Rumors claim that GPT-4 has 1.76 trillion parameters, which was first estimated by the speed it was running and by George Hotz.[12]. OpenAI stated that GPT-4 is "more reliable, creative, and able to handle much more nuanced instructions than GPT-3.5."[13] They produced two versions of GPT-4, with context windows of 8,192 and 32,768 tokens, a significant improvement over GPT-3.5 and GPT-3, which were limited to 4,096 and 2,049 tokens respectively.[14] Some of the capabilities of GPT-4 were predicted by OpenAI before training it, although other capabilities remained hard to predict due to breaks[15] in downstream scaling laws. Unlike its predecessors, GPT-4 is a multimodal model: it can take images as well as text as input;[6] this gives it the ability to describe the humor in unusual images, summarize text from screenshots, and answer exam questions that contain diagrams.[16]. To gain further control over GPT-4, OpenAI introduced the "system message", a directive in natural language given to GPT-4 in order to specify its tone of voice and task. For example, the system message can instruct the model to "be a Shakespearean pirate", in which case it will respond in rhyming, Shakespearean prose, or request it to "always write the output of [its] response in JSON", in which case the model will do so, adding keys and values as it sees fit to match the structure of its reply. In the examples provided by OpenAI, GPT-4 refused to deviate from its system message despite requests to do otherwise by the user during the conversation.[16]."
]
1:[
0:"https://en.wikipedia.org/w/index.php?search=ChatGPT"
1:"ChatGPT, which stands for Chat Generative Pre-trained Transformer, is a large language model-based chatbot developed by OpenAI and launched on November 30, 2022, notable for enabling users to refine and steer a conversation towards a desired length, format, style, level of detail, and language used. Successive prompts and replies, known as prompt engineering, are considered at each conversation stage as a context.[2]. ChatGPT is built upon GPT-3.5 and GPT-4 —members of OpenAI's proprietary series of generative pre-trained transformer (GPT) models, based on the transformer architecture developed by Google[3]—and it is fine-tuned for conversational applications using a combination of supervised and reinforcement learning techniques.[4] ChatGPT was released as a freely available research preview, but due to its popularity, OpenAI now operates the service on a freemium model. It allows users on its free tier to access the GPT-3.5-based version. In contrast, the more advanced GPT-4 based version and priority access to newer features are provided to paid subscribers under the commercial name "ChatGPT Plus".. By January 2023, it had become what was then the fastest-growing consumer software application in history, gaining over 100 million users and contributing to OpenAI's valuation growing to US$29 billion.[5][6] Within months, Google, Baidu, and Meta accelerated the development of their competing products: Bard, Ernie Bot, and LLaMA.[7] Microsoft launched its Bing Chat based on OpenAI's GPT-4. Some observers expressed concern over the potential of ChatGPT to displace or atrophy human intelligence and its potential to enable plagiarism or fuel misinformation.[4][8]. ChatGPT is based on particular GPT foundation models, namely GPT-3.5 and GPT-4, that were fine-tuned to target conversational usage.[9] The fine-tuning process leveraged both supervised learning as well as reinforcement learning in a process called reinforcement learning from human feedback (RLHF).[10][11] Both approaches employed human trainers to improve model performance. In the case of supervised learning, the trainers played both sides: the user and the AI assistant. In the reinforcement learning stage, human trainers first ranked responses that the model had created in a previous conversation.[12] These rankings were used to create "reward models" that were used to fine-tune the model further by using several iterations of Proximal Policy Optimization (PPO).[10][13]."
]
]
}
]
・process_search_result
検索結果のコンテンツとURLのリストを文字列として出力します。
from promptflow import tool
@tool
def process_search_result(search_result):
def format(doc: dict):
return f"Content: {doc['Content']}\nSource: {doc['Source']}"
try:
context = []
for url, content in search_result:
context.append({
"Content": content,
"Source": url
})
context_str = "\n\n".join([format(c) for c in context])
return context_str
except Exception as e:
print(f"Error: {e}")
return ""
出力結果はこちらです。
[
0:{
"system_metrics":{
"duration":0.00067
}
"output":"Content: Generative Pre-trained Transformer 4 (GPT-4) is a multimodal large language model created by OpenAI, and the fourth in its series of GPT foundation models.[1] It was initially released on March 14, 2023,[1] and has been made publicly available via the paid chatbot product ChatGPT Plus, and via OpenAI's API.[2] As a transformer-based model, GPT-4 uses a paradigm where pre-training using both public data and "data licensed from third-party providers" is used to predict the next token. After this step, the model was then fine-tuned with reinforcement learning feedback from humans and AI for human alignment and policy compliance.[3]: 2. Observers reported that the iteration of ChatGPT using GPT-4 was an improvement on the previous iteration based on GPT-3.5, with the caveat that GPT-4 retains some of the problems with earlier revisions.[4] GPT-4 is also capable of taking images as input, though this feature has not been made available since launch.[5][6] OpenAI has declined to reveal various technical details and statistics about GPT-4, such as the precise size of the model.[7]. OpenAI introduced the first GPT model (GPT-1) in 2018, publishing a paper called "Improving Language Understanding by Generative Pre-Training."[8] It was based on the transformer architecture and trained on a large corpus of books.[9] The next year, they introduced GPT-2, a larger model that could generate coherent text.[10] In 2020, they introduced GPT-3, a model with 100 times as many parameters as GPT-2, that could perform various tasks with few examples.[11] GPT-3 was further improved into GPT-3.5, which was used to create the chatbot product ChatGPT.. Rumors claim that GPT-4 has 1.76 trillion parameters, which was first estimated by the speed it was running and by George Hotz.[12]. OpenAI stated that GPT-4 is "more reliable, creative, and able to handle much more nuanced instructions than GPT-3.5."[13] They produced two versions of GPT-4, with context windows of 8,192 and 32,768 tokens, a significant improvement over GPT-3.5 and GPT-3, which were limited to 4,096 and 2,049 tokens respectively.[14] Some of the capabilities of GPT-4 were predicted by OpenAI before training it, although other capabilities remained hard to predict due to breaks[15] in downstream scaling laws. Unlike its predecessors, GPT-4 is a multimodal model: it can take images as well as text as input;[6] this gives it the ability to describe the humor in unusual images, summarize text from screenshots, and answer exam questions that contain diagrams.[16]. To gain further control over GPT-4, OpenAI introduced the "system message", a directive in natural language given to GPT-4 in order to specify its tone of voice and task. For example, the system message can instruct the model to "be a Shakespearean pirate", in which case it will respond in rhyming, Shakespearean prose, or request it to "always write the output of [its] response in JSON", in which case the model will do so, adding keys and values as it sees fit to match the structure of its reply. In the examples provided by OpenAI, GPT-4 refused to deviate from its system message despite requests to do otherwise by the user during the conversation.[16]. Source: https://en.wikipedia.org/w/index.php?search=GPT-4 Content: ChatGPT, which stands for Chat Generative Pre-trained Transformer, is a large language model-based chatbot developed by OpenAI and launched on November 30, 2022, notable for enabling users to refine and steer a conversation towards a desired length, format, style, level of detail, and language used. Successive prompts and replies, known as prompt engineering, are considered at each conversation stage as a context.[2]. ChatGPT is built upon GPT-3.5 and GPT-4 —members of OpenAI's proprietary series of generative pre-trained transformer (GPT) models, based on the transformer architecture developed by Google[3]—and it is fine-tuned for conversational applications using a combination of supervised and reinforcement learning techniques.[4] ChatGPT was released as a freely available research preview, but due to its popularity, OpenAI now operates the service on a freemium model. It allows users on its free tier to access the GPT-3.5-based version. In contrast, the more advanced GPT-4 based version and priority access to newer features are provided to paid subscribers under the commercial name "ChatGPT Plus".. By January 2023, it had become what was then the fastest-growing consumer software application in history, gaining over 100 million users and contributing to OpenAI's valuation growing to US$29 billion.[5][6] Within months, Google, Baidu, and Meta accelerated the development of their competing products: Bard, Ernie Bot, and LLaMA.[7] Microsoft launched its Bing Chat based on OpenAI's GPT-4. Some observers expressed concern over the potential of ChatGPT to displace or atrophy human intelligence and its potential to enable plagiarism or fuel misinformation.[4][8]. ChatGPT is based on particular GPT foundation models, namely GPT-3.5 and GPT-4, that were fine-tuned to target conversational usage.[9] The fine-tuning process leveraged both supervised learning as well as reinforcement learning in a process called reinforcement learning from human feedback (RLHF).[10][11] Both approaches employed human trainers to improve model performance. In the case of supervised learning, the trainers played both sides: the user and the AI assistant. In the reinforcement learning stage, human trainers first ranked responses that the model had created in a previous conversation.[12] These rankings were used to create "reward models" that were used to fine-tune the model further by using several iterations of Proximal Policy Optimization (PPO).[10][13]. Source: https://en.wikipedia.org/w/index.php?search=ChatGPT"
}
]
・augmented_qna
最後は作成済みのAzure OpenAIリソースへ接続を行い、デフォルトのプロンプトで実行します。
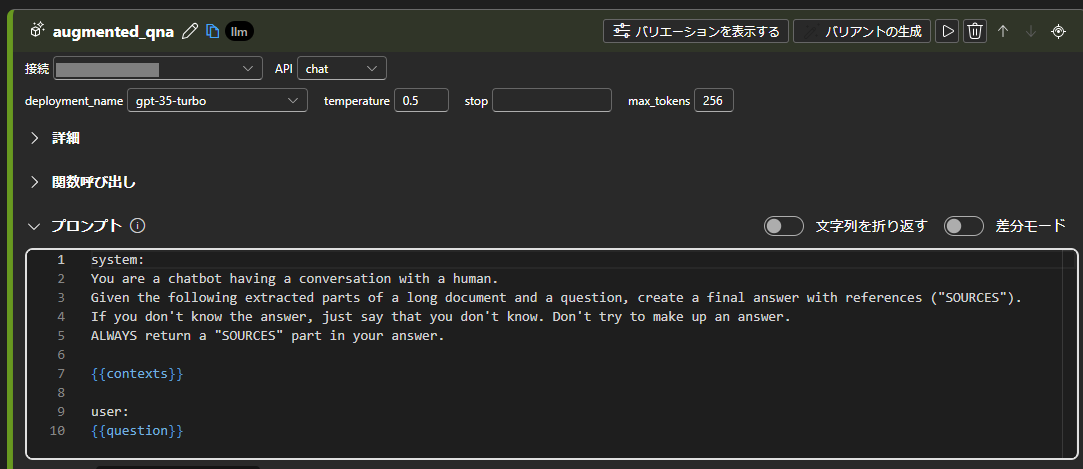
プロンプトの内容は、「Wikiから抜粋した文章と質問が与えられたら、参考文献を使って最終的に答えを作成してください。」というものです。
system:
You are a chatbot having a conversation with a human.
Given the following extracted parts of a long document and a question, create a final answer with references ("SOURCES").
If you don't know the answer, just say that you don't know. Don't try to make up an answer.
ALWAYS return a "SOURCES" part in your answer.
{{contexts}}
user:
{{question}}
これで画面右上の「実行」ボタンを押し、少し待てば出力がでてきます。
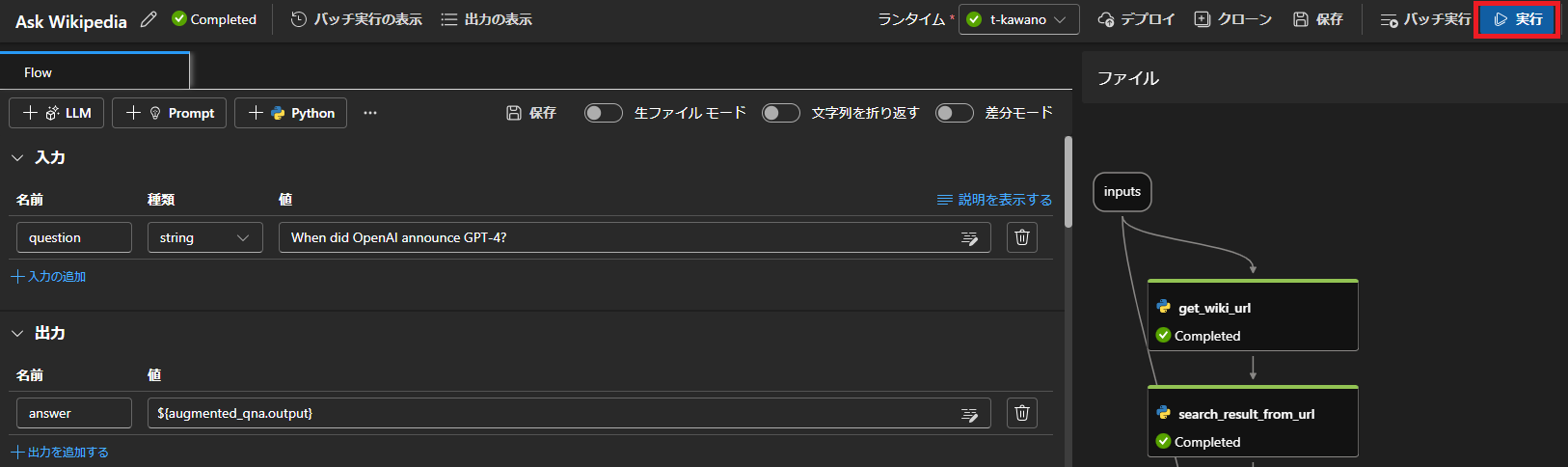
実行結果
最初の質問「When did OpenAI announce GPT-4?」に対して、次のような出力が帰ってきました。
[
0:{
"system_metrics":{
"completion_tokens":39
"duration":2.633617
"prompt_tokens":1423
"total_tokens":1462
}
"output":"OpenAI announced GPT-4 on March 14, 2023. [1] SOURCES: [1] https://en.wikipedia.org/w/index.php?search=GPT-4"
}
]
URLが載った参考文献付きで出力が返ってきました。実際にURLを開いてみると
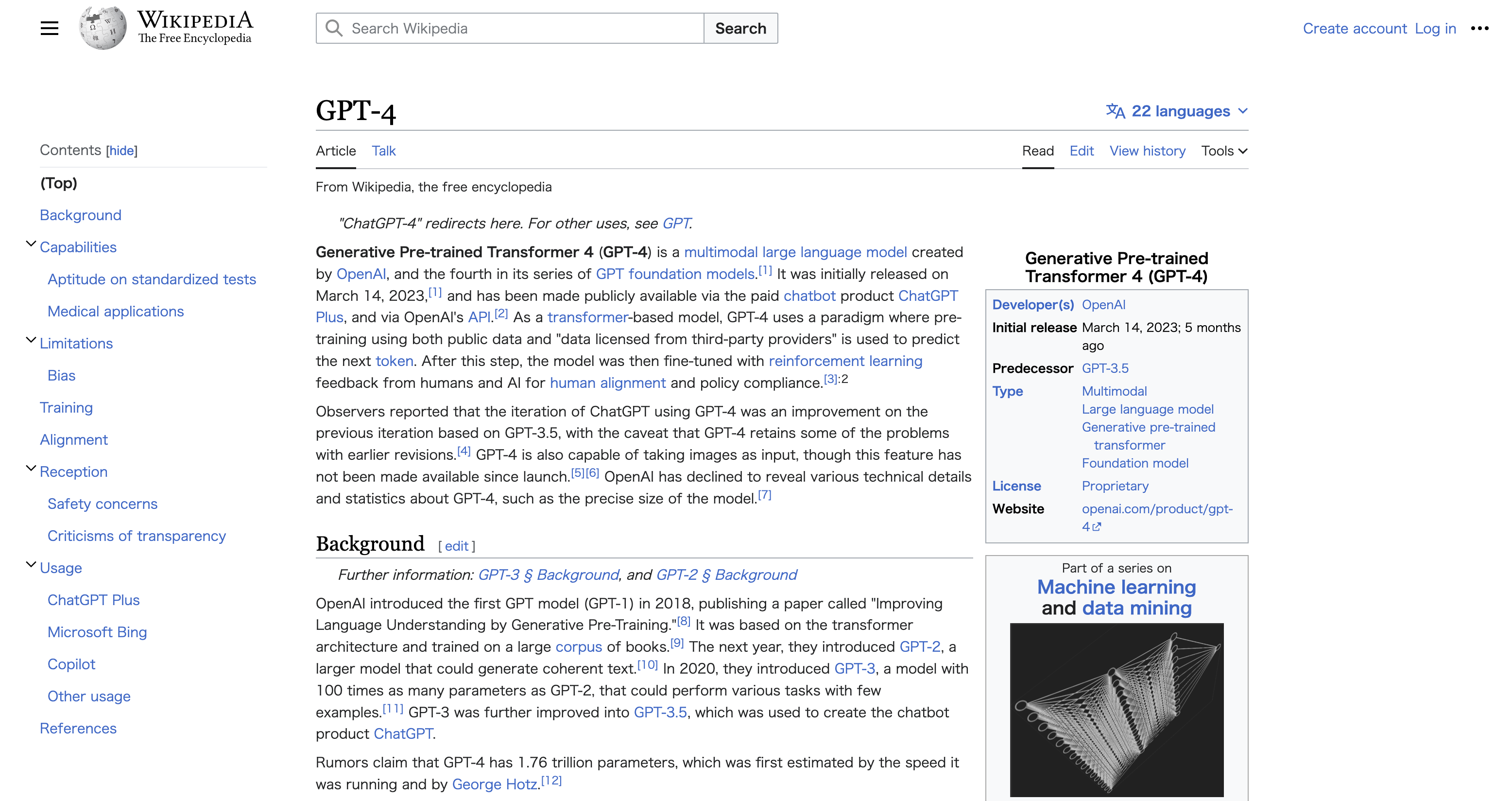
GPT-4に関するページに行けました。
ChatGPTについては、よく嘘のことが本当のように書かれている場合がありますが、このようにソース付きで返されるとすぐに確かめることができるので良いですね。