Hadoop
How it all started?
The large-scale process such as a search engine system that can index 1 million pages costs a tons of money and running cost. Meanwhile, a paper described about the architecture of the Google's distributed file system was published in 2003. Later in 2004, Google published one more paper that introduced MapReduce. Finally, these 2 papers led to the hadoop.
General architecture of hadoop
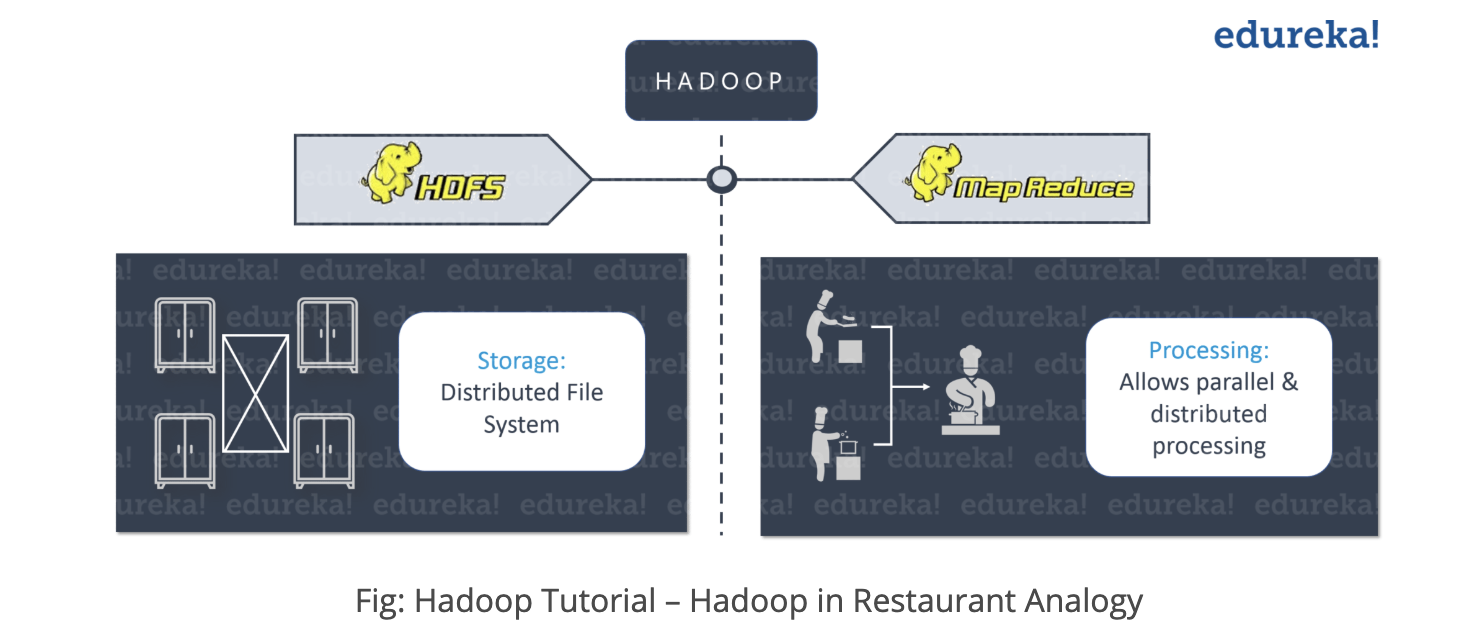
Hadoop architecture is similar to the Bob's restaurant.
Let's say that there is a restaurant which struggles with dealing with many orders by only 1 chef. To solve this problem, Bob hires much more chefs to distribute the task into those chefs(Distributed File System).
Everything is going well, but there occurs another problem. Since each chef trys to access the very food shelf, the food shelf becomes the bottle neck of the whole process. In order to solve this, Bob divided each chef into 2 hierarchies(Junior and Head chef). Each Junior chef will do small task, prepare the ingredient(ex. prepare sauce, cook meat, vegetable..). Then, all those task will be derived to the each head chef, that will combine all the task and done the process(Map Reduce).
How Hadoop provides the solution to the Big Data problem
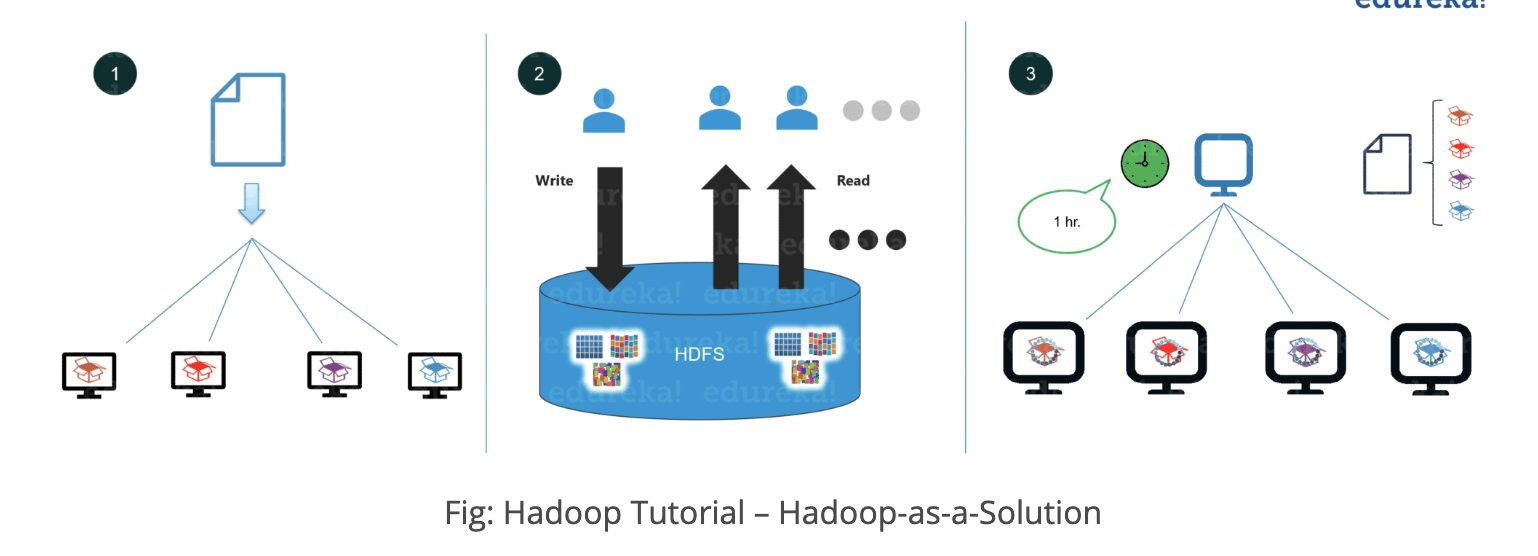
Hadoop Core Component
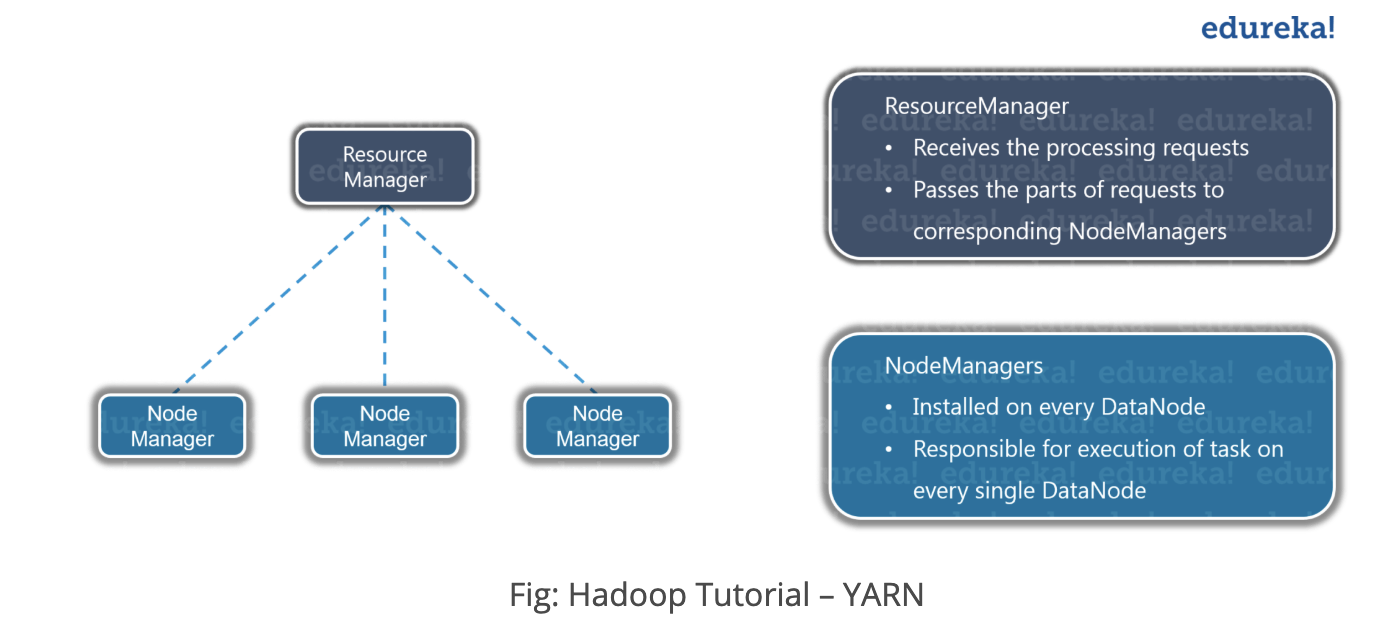
One is HDFS(storage)(Hadoop Distributed File System) and another one is YARN(Processing).
HDFS
The main components of HDFS are NameNode and DataNode.
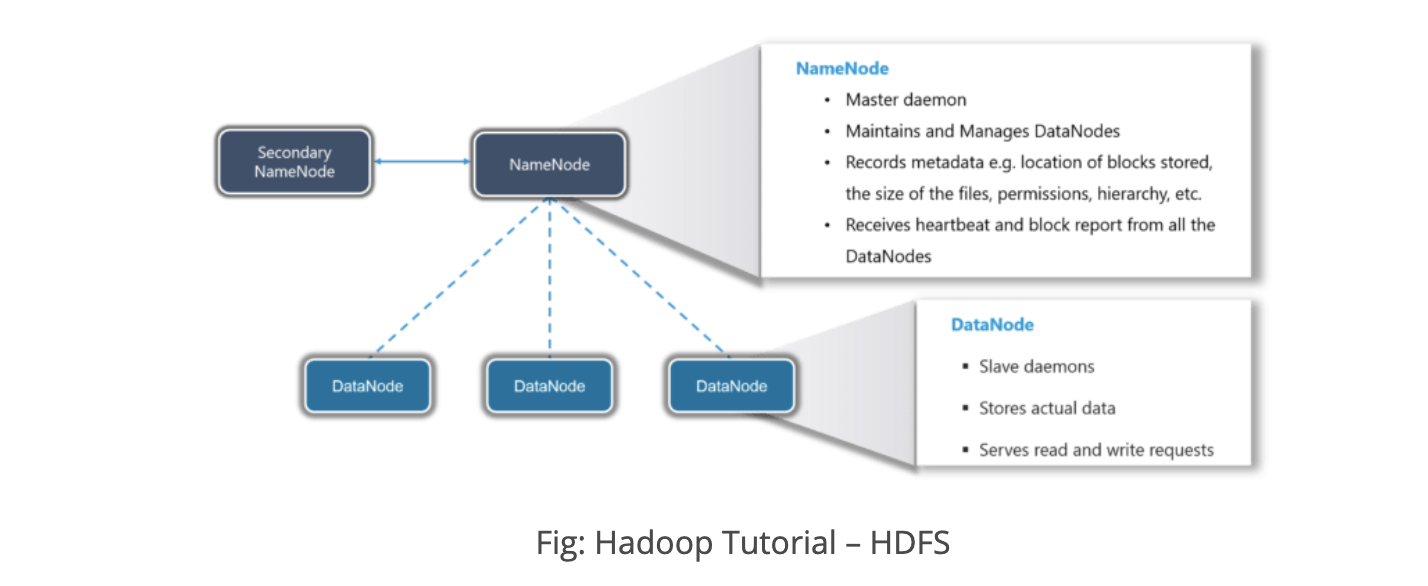
NameNode maintains the information of each DataNode.
YARN