目次
1.環境構築【docker-composeでNginx+Gunicorn+Flask+MariaDB+phpMyAdmin】
2.Flask+RoboBrowserでスクレイピングした結果をbootstrap(honoka)で表示※本記事
3.flask-sqlalchemyを使ってみる(MariaDBと接続)
4.flask-loginを使ってみる(ログイン機能実装)
内容
目次1で構築したdocker-compose環境をベースにはてなブックマークのテクノロジーの人気エントリーを
WEBスクレイピングで取得してtableで表示するというものです。
APIを使わずにrobobrowserを使って取得してみます。
業務でAPIが提供されていないサービスから情報取得が必要になったためその練習です。
robobrowserでログイン処理は行いません。
ついでにtableはbootstrapのhonokaで見映えを調整します。
htmlテンプレートはbase.htmlを作成し、そこにBootstrapの読み込みを記載します。
参考記事
・RoboBrowserを使ってWebページにログインしてクローリング
※RoboBrowserの要素の指定が参考になりました。
・Bootstrap4に用意されているクラス【table編】
※tableのデザイン時に必要なものをコピーさせていただきました。
完成形
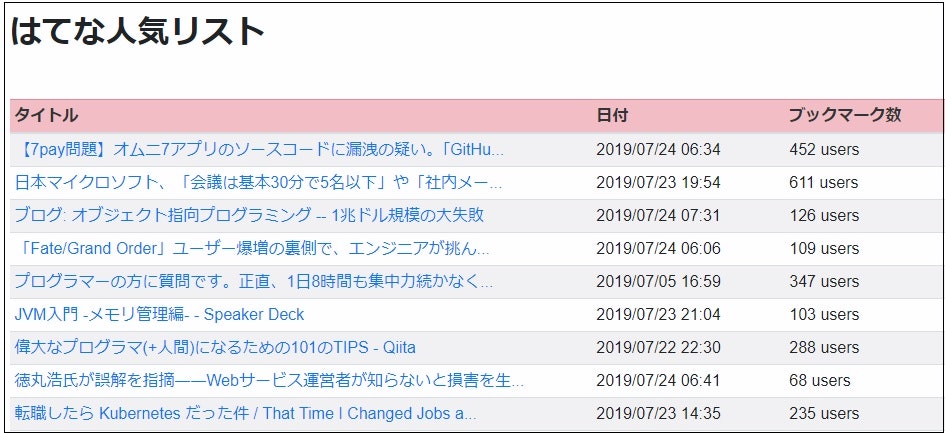
webブラウザで [ホストIP]:8889/list にアクセスすると裏側でscrap.pyが実行されて必要な情報を取得します。その情報をflaskのrender_templateでlist.htmlに表示するという流れです。
データが取得できなかった場合

ソース
ディレクトリ構成
.
├── README.md
├── db
│ ├── Dockerfile
│ ├── backup
│ │ └── init.sql
│ └── conf.env
├── docker-compose.yml
├── nginx
│ ├── Dockerfile
│ ├── default.conf
│ ├── log
│ │ ├── access.log
│ │ └── error.log
│ └── nginx.conf
├── phpmyadmin
│ ├── Dockerfile
│ └── conf.env
└── web
├── Dockerfile
├── application
│ ├── __init__.py
│ ├── scrap.py #はてなブックマークよりリストを取得するスクリプト
│ ├── static #honoka4.3.1よりアップロード
│ │ ├── css
│ │ │ ├── bootstrap.css
│ │ │ └── bootstrap.min.css
│ │ └── js
│ │ ├── bootstrap.bundle.js
│ │ ├── bootstrap.bundle.min.js
│ │ ├── bootstrap.js
│ │ ├── bootstrap.min.js
│ │ └── jquery-3.4.1.min.js
│ ├── templates
│ │ ├── base
│ │ │ └── base.html #index.html, list.htmlの共通部分を記載
│ │ ├── index.html #honokaのサンプルを利用して作成
│ │ └── list.html #scrap.pyの結果を表示
│ └── views.py
├── requirements.txt
└── startup.py
requirements.txt
Flask==1.1.1
Flask-SQLAlchemy==2.4.0
gunicorn==19.9.0
PyMySQL==0.9.3
SQLAlchemy==1.3.5
robobrowser==0.5.3 #追加
scrap.py
ログイン等のフォーム操作がありませんので「RoboBrowserを使ってWebページにログインしてクローリング」を参照すれば特に難しい部分はありませんでした。
from robobrowser import RoboBrowser
def get_hatena_entries(target_url):
results = []
robo = RoboBrowser(
parser='html.parser', # Beautiful Soupで使用するパーサーを指定
timeout=5 #応答の遅いサイトではこの値を変更
)
robo.open(target_url)
target_class = 'div.entrylist-contents-main' #エントリーの一番大枠のクラスを指定
for data in (robo.select(target_class)):
title = data.select('a.js-keyboard-openable')
users = data.select('span.entrylist-contents-users')
posted_date = data.select('li.entrylist-contents-date')
link = data.find('a').get('href') #<a href=''>のURLを取得するにはgetを使用
line = [] # 1件ですがリストで帰ってくるので取り出す
line.append(title[0].text)
line.append(posted_date[0].text)
line.append(users[0].text)
line.append(link)
results.append(line)
return(results)
views.py
from flask import url_for, render_template
from application import app
from application import scrap #scrape.pyをインポートする
@app.route('/')
def top_page():
title = 'ようこそ日本語!!'
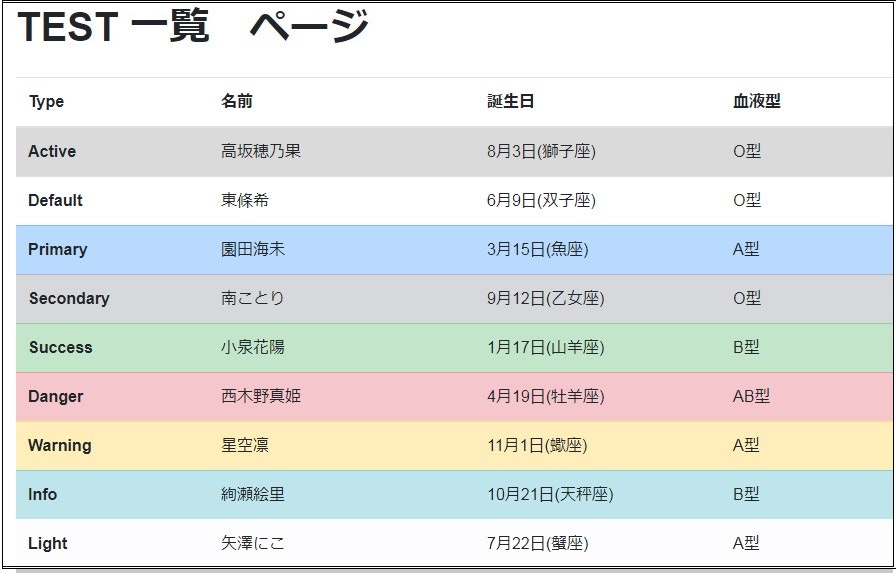
msg = 'TEST 一覧ページ'
return render_template('index.html', title = title, msg = msg)
@app.route('/list')
def show_list():
title = "はてな人気リスト"
results = scrap.get_hatena_entries('https://b.hatena.ne.jp/hotentry/it')
# URLを変更すれば別ジャンルも取得できます。
# results = scrap.get_hatena_entries('https://b.hatena.ne.jp/hotentry/life')
return render_template('list.html', title = title, results = results)
list.html
{% extends "base/base.html" %} #base.htmlを読み込む
{% block content %}
<h2 class="mt-3">{{ title }}</h2>
{% if results %} #scrape.pyで取得した結果が入ってくる
<table class="table table-hover table-striped table-sm mt-5">
<thead class="thead-dark">
<tr>
<th>タイトル</th>
<th>日付</th>
<th>ブックマーク数</th>
</tr>
</thead>
<tbody>
{% for result in results %}
<tr>
<td><a href="{{ result[3] }}">{{ result[0] }}</a></td>
<td>{{ result[1] }}</td>
<td>{{ result[2] }}</td>
</tr>
{% endfor %}
</tbody>
</table>
{% else %} #scrape.pyで取得に失敗した場合の処理
<h3 class="pt-3">データを取得できませんでした。</h3>
{% endif %}
{% endblock %}
補足 honoka
上記ソースのjs, cssはhonokaのjs, cssを適用済みです。
日本語表示がきれいなBootstrap 【Honokaサイト】
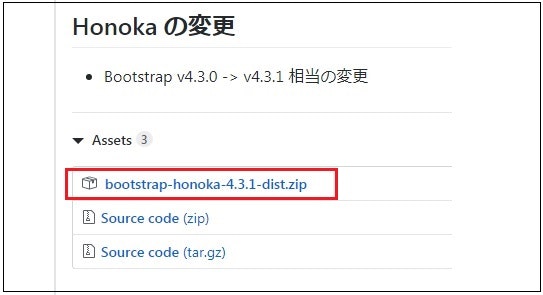
githubよりjs, cssをダウンロード
※index.htmlはhonokaのサンプルのtableを利用させていただきました。