GraphWise - Graph Convolutional Networks in PGX
GraphWiseは、人気のある論文(GraphSAGE)に基づくグラフニューラルネットワーク(GNN)アルゴリズムです。本記事では、アルゴリズムの背後にある一般的なアイデアと機能を説明します。まずは、グラフ畳み込みネットワークの一般的な使用例をいくつか考えてみましょう。
グラフ畳み込みネットワークの使用例
下記のような使用例があります。
リコメンデーション・システム
リコメンデーション・システムは、オンラインマーケットプレイスの背後にある最も重要なソフトウェアの一部です。推薦されるものの品質は、販売指標に直結します。
リコメンデーション・システムのユーザーアクションを、ユーザーとアイテムで構成されるグラフのエッジとみなします。ユーザーがアイテムを購入するとき、そのユーザーのノードとユーザーが購入したアイテムのノードの間にエッジを追加することで、そのグラフを表すことができます。
Pinterestでは、GraphSAGEをベースとしたアルゴリズムを使用して、巨大なWebスケール(180億エッジ!)のグラフですべての推奨事項を作成します。GraphSAGEは、このような大規模なWebサイトに対しても十分に高速である同時に、グラフの情報を活用することで非常に精度の高い推奨事項を提供できるため、興味深いですね。「PinSage」として知られるこのグラフ畳み込みニューラルネットワークは、A / Bテストにおいて、既存の非グラフ機械学習モデルよりも一貫して優れています。
不正検知 / 異常検知
グラフ内での異常な動作を検出したいアプリケーションはいくつも存在します。大規模なトランザクショングラフ(銀行セクターなど)からサイバーセキュリティに至るまでの例を見てきました。このような例の場合、グラフは業務システムのプロセスやその他のコンポーネントを表しています。このような場合、グラフ構造はタスクにとって非常に貴重であることが多く、グラフニューラルネットワークを使用すると、このデータを効果的に活用できます。
2つの例のみを示しましたが、これらは1つだけではありません。グラフは、ナレッジグラフから地図、ソーシャルグラフ(Facebookなど)、Webネットワーク(GoogleのPageRankなど)、さらには幾何学的(3D)対象まで、幅広いデータを表すことができる、最も自然な方法です。
グラフ畳み込みネットワーク
グラフ畳み込みネットワークの実行例として、銀行取引のグラフで不正を特定することを考えます。
ここで、次のグラフを考えます。ノードは銀行の顧客であり、ノード(銀行の顧客)間の送金が行われた場合、ノードは相互に接続されます。例として、次のグラフGを図示します。
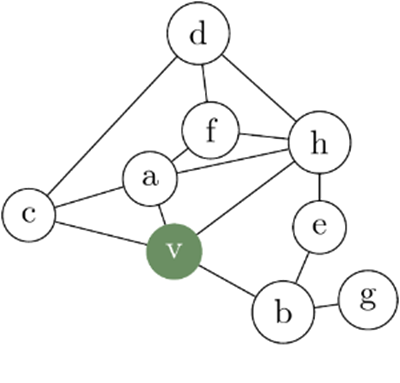
グラフ内の不正の特定は、グラフのトポロジ、つまりグラフの構造に大きく依存します。GNNアルゴリズムを通じて、このデータを活用してより正確な予測を行うことができます。
より標準的な機械学習アルゴリズムでは、グラフデータは通常行列として表現するため、直接取り込むことはできません。よって、口座のサイズなど、いくつかのノードの特徴に基づいて予測を行うのが一般的なアプローチです。これらは、グラフとその属性(平均取引時間やノードの次数など)に基づいて、作成した特徴量抽出方法と連結されます。
したがって、データフローは次のようになります。

GNNアプローチは、手動で行っていた特徴量作成のステップを、タスクに適した特徴を学習できるグラフ畳み込み層に置き換えます。これを行うことで、グラフデータを直接取り込むことができます。

GraphSAGE
これを行うために、GraphSAGEは、グラフデータを取り込んでベクトルを出力するフォワードパスを定義します。このパスは、より標準的なニューラルネットワークレイヤーに供給することができます。このアルゴリズムは次のような面白い機能をもっています。
- グラフ学習に対する他のアプローチとは異なり、GraphSAGEは帰納的である。グラフ全体で学習する必要はない。学習が完了すると、未知のノードやグラフで推論を実行できます。(レコメンダーシステムのように、リアルタイムの予測を必要とするシステムにとっては重要)。
- GraphSAGEは、node2vecやDeepWalkなどのアルゴリズムとは異なり、ノードの特徴を考慮に入れる。
フォワードパス
このような変換を行うために、フォワードパスはサンプリングと集計の2つの段階で進行します。上記のグラフ例のノードvを使って、フォワードパスについて確認します。
最初の層が3つの隣接ノードをサンプリングし、2番目の層が2つの隣接ノードをサンプリングする2層モデルについて考えます。
サンプリング
最初に、隣接ノードのセットがサンプリングされます。2層モデルがあるため、1番目と2番目のホップ可能な隣接ノードをサンプリングする必要があります。ここではこれをランダムに行いますが、実際には、閾値に基づいてネイバーをサンプリングすると役立つことがよくあります。最初のホップでは、ノード{a、h、b}をサンプリングします。これらのノードごとに、2つの隣接ノードをサンプリングする必要があります。aの場合は{f、h}をサンプリングし、hの場合は{a、d}をサンプリングし、bの場合は{e、g}をサンプリングします。実際には、パフォーマンス上の理由から、サンプリングは置換を使用して実行されることが多いことに注意してください。
集約
次のステップは、これらのノードからの情報を集約することです。一般的には、サンプリングされた隣接ノードのセットごとに、列ごとの対称集計を使用してノードの特徴を集計します。実際には、一般的に使用される集計は、平均、最大、さらにはLSTM集計です(これらは対称ではありませんが)。次の図では、特徴量がグラフをどのように流れるかを確認できます。
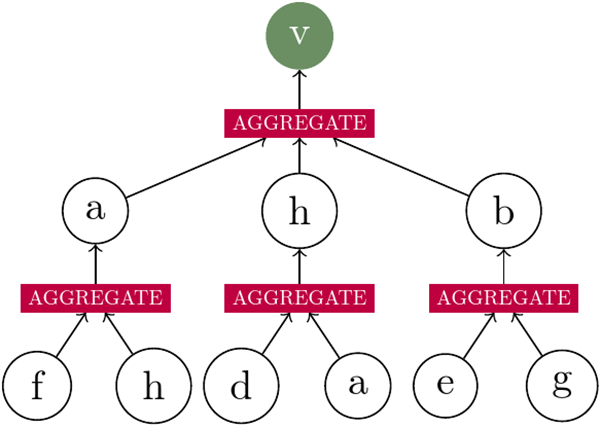
例として、ノードの特徴量が、月間純残高と口座の日数であると考えてください。次に、ノード「f」と「h」に特徴ベクトルがそれぞれ[-$ 200、40日]と[$300、100日]がある場合、「a」の平均アグリゲーターは平均ベクトル、つまり[$ 50、70日]となります。
各集計の後、前の層の値に行列を掛けます。この行列の重みは学習可能であり、これにより、アルゴリズムは適切な特徴量を学習できます。
ただし、GraphSAGEはこれだけでは終わりません。重要なステップとして、連結操作が残っています。
今説明したモデルでは、ノード「v」自体の特徴は無視されます(タスクにとって非常に重要ですが)。これを回避するために、アグリゲーターが使用されるたびに、集約された特徴をノード自体の特徴と連結します。
より理解しやすくするために、層におけるノードの表現の概念を形式化します。ノードの第0層表現は、その入力特徴ベクトルです。次に、ノードの第1層表現は、ノード自体の特徴ベクトルに加え、1ホップ先の隣接ノードの集約された特徴量と連結したものとして定義されます。
一般に、ノードvのi番目のレイヤー表現(f_i(v)で示される)は、次を使用して見つけることができます。
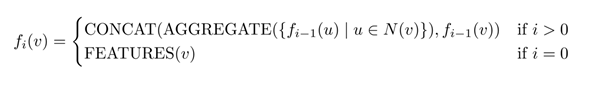
ここで、N(v)は、隣接ノードのセットを返すサンプリング関数です(簡単化のために、サンプリングサイズは意図的に省略しています)。
最後に、フォワードパスの出力は、ノード「v」のL2正則化された最後のレイヤー表現です。
GraphWiseは、Oracle Database(12.2以降)と統合されたGraph Server and Clientバージョン21.1以降に実装されています。
入力グラフでGraphWiseモデルを実行するには、次のコードを使用できます。
SupervisedGraphWiseModel model = analyst.supervisedGraphWiseModelBuilder()
.setVertexInputPropertyNames("account_size" // scholar
, "monthly_net_balance"
, "one_hot_account_location" // vector
...
)
.setVertexTargetPropertyName("labels")
.build();
個々のレイヤーに対してより具体的なパラメーターを有効にすることもできます。上記のフォワードパスを再作成するには、次のコードを使用できます。
GraphWiseConvLayerConfig layerConfig1 = analyst.graphWiseConvLayerConfigBuilder()
.setNumSampledNeighbors(3)
.build();
GraphWiseConvLayerConfig layerConfig2 = analyst.graphWiseConvLayerConfigBuilder()
.setNumSampledNeighbors(2)
.build();
SupervisedGraphWiseModel model = analyst.supervisedGraphWiseModelBuilder()
.setVertexInputPropertyNames("account_size" // scholar
, "monthly_net_balance"
, "one_hot_account_location" // vector
...
)
.setVertexTargetPropertyName("labels")
.setConvLayerConfigs(layerConfig1, layerConfig2)
.build();
学習
次に、モデルの重みをエンドツーエンドの方法で学習できます。たとえば、畳み込みレイヤーの結果をいくつかの密な層に供給し(これは、GraphWiseで実行されます)、出力層における分類損失に基づいて学習します。
ただし、出力層は密な層である必要はなく、損失は分類損失である必要はありません。フォワードパスとトレーニング可能なウェイトがあるので、必要な損失や出力を追加できます。
埋め込み
畳み込み層の後でモデルのアクティブ化を取得し、それらを埋め込みと見なすことができます。これらの埋め込みは、リンク予測、リコメンデーション・システム、クラスタリングなどのダウンストリームタスクで使用できます。
教師なし埋め込み
また、Skip-Gramのような損失を使用して、教師なしの方法でフォワードパスの重みを学習することもできます。
まず、コンテキストペア、つまり埋め込み空間内で近接しているノードを生成します。
DeepWalk等のアルゴリズムと同様に、グラフ上のランダムウォークからこれらのコンテキストペアを取得できます。
ノード「v」からランダムウォークを実行し、これらのランダムウォークで到達するすべてのノード「u」に対して、コンテキストペア(v、u)を追加します。
これらのコンテキストペアを使用すると、次の損失を得ることができます。
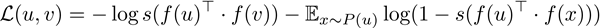
ここで、sはシグモイド活性化、fはフォワードパス、Pは負のサンプリング分布です。基本的な考え方は、コンテキストペア(u、v)の場合、この損失により、uとvが埋め込み空間で近くに存在し、一部の負のサンプルxの場合、uが埋め込み空間でxから遠く離れていることが表現されます。
推論
上記のように、GraphSAGEは、学習中に表示されなかったノードの埋め込みを推論できます。学習中に取得した重みを使って、ノードを同じフォワードパスに渡すだけで、推論が可能です。
結論
この記事では、グラフニューラルネットワークアルゴリズムであるGraphWiseと、精度の高いのリコメンデーション・システムや不正検出を含むそのユースケースについて説明しました。
また、銀行取引のグラフで不正を特定するためのグラフニューラルネットワークを構築する方法についても説明しました。