プロ野球のデータ分析をしようと思いましたが、想定したデータ形式にするまでに手間取ったので、その備忘録として記録しています。今回の目的は、数年分のプロ野球データをプロ野球データFreakから取得し、取得した各年の選手成績を統合するまでです。
選手成績の取得
スクレイピングという言葉も知らないまま、pandasでページに記載されている表をpandas形式に読み込めないかと探したら、丁度よいリンクHTML の表(<table>タグ) をスクレイピングする時も pandas が超便利がありました。
表も各ページに1つしかなく、また、各年の情報が記載されているURLのルールもシンプルだったため情報を取得するのに、工夫はありませんでした。今回は、投手データを規定回数に関係なく取得しています。条件によってURLが少し変わるので注意してください。
import numpy
import pandas as pd
# import matplotlib.pylab as plt
# urlをリスト形式で取得
df_all = []//各要素に各年のデータが入る
years = range(17,8,-1)
urls = []
# URLを入力:2017年だけ命名規則が違う
for year in years:
if(year==17):
urls.append('http://baseball-data.com/stats/pitcher-all/era-1.html')
else:
urls.append('http://baseball-data.com/'+ "{0:02d}".format(year)+'/stats/pitcher-all/era-1.html')
# データをURLから取得
for url in urls:
print('取得URL:'+url)
df = pd.io.html.read_html(url)
df = df[0]
df_all.append(df)
各年のデータ統合
各年のデータを紐づけるのに、選手名をindexにしようと思いましたが、pd.concatでさくっとできませんでした。問題は2つあって、1つはpd.concatが日本語に対応していないこと、2つ目はindexの重複に対応していないことです。重複の発生原因は、シーズン中の移籍による複数チームへの所属でした。
まず、9年間の選手名から重複を除去して、各選手名にIDを与えています。
# 選手IDの作成
name_list = []
dic = {}
for i in range(len(df_all)):
name_list.extend(df_all[i]['選手名'])
name_list = list(set(name_list))
for i,name in enumerate(name_list):
dic[name] = i
# 選手IDの付与
for i in range(len(df_all)):
df_all[i]['ID'] = -1
for j in range(len(df_all[i])):
df_all[i].loc[j,'ID'] = dic[df_all[i].loc[j,'選手名']]
df_all[i].index = df_all[i]['ID']
df_all[i] = df_all[i].drop('ID',axis=1)
次に各年に複数球団に所属した選手を除去しています。
# index被りを除去
for i in range(len(df_all)):
doubled_index = []
count = df_all[i].index.value_counts()
for j in count.index:
if(count.loc[j]>1):
doubled_index.append(j)
df_all[i] = df_all[i].drop(doubled_index)
最後に選手IDで紐づけることにより、選手の9年間のデータをまとめることができました。
# カラム名に年を付ける
for i in range(len(df_all)):
for col_name in df_all[i].columns:
df_all[i] = df_all[i].rename(columns = {col_name:col_name+"20"+"{0:02d}".format(years[i])})
df_m = pd.concat(df_all,axis=1)
データの確認
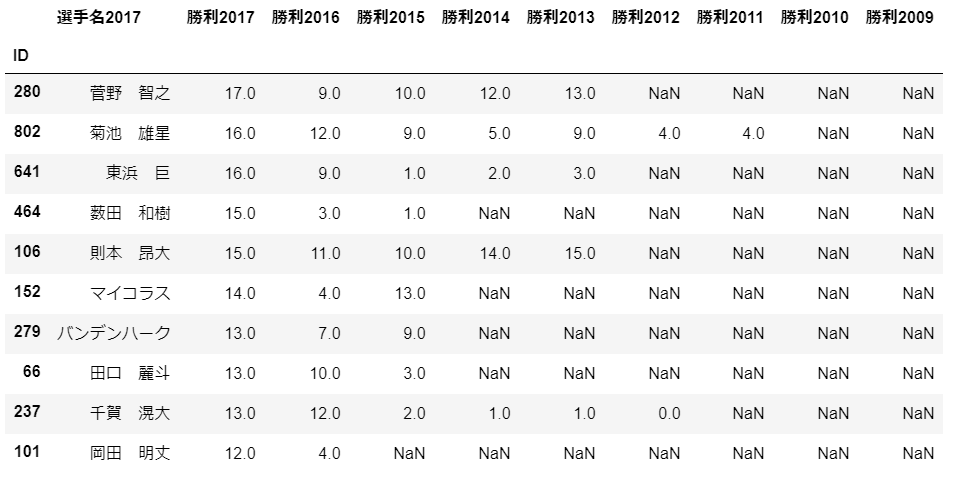
最後にデータの確認をします。今回は2017年の勝利数上位20人の最近9年間の勝利数を見たいと思います。
data = '勝利'
data_col = ['選手名2017']
for col in df_m.columns:
if '勝利' in col:
data_col.append(col)
df_m = pd.concat(df_all,axis=1)
df_m = df_m.sort_values('勝利2017',ascending=False)
df_m = df_m[data_col]
df_m.head(20)
結果
終わりに
TOP10にここ9年間毎年勝利している人っていないんですね。なかなか厳しい世界だなと改めて感じました。今回は、分析せずに終わったので、面白い分析ができたらまた上げたいと思います。分析した方は、コメントなりここのリンクを張るなりしていただけると幸いです。