動機
機械学習の最新動向を追うために、arXivをチェックしたい!
けど、毎日100本以上上がるから、全部チェックなんかできない!
重要なのだけ読みたいけど、どれが重要な論文かわからん!
と思って、作りました。
作ったもの
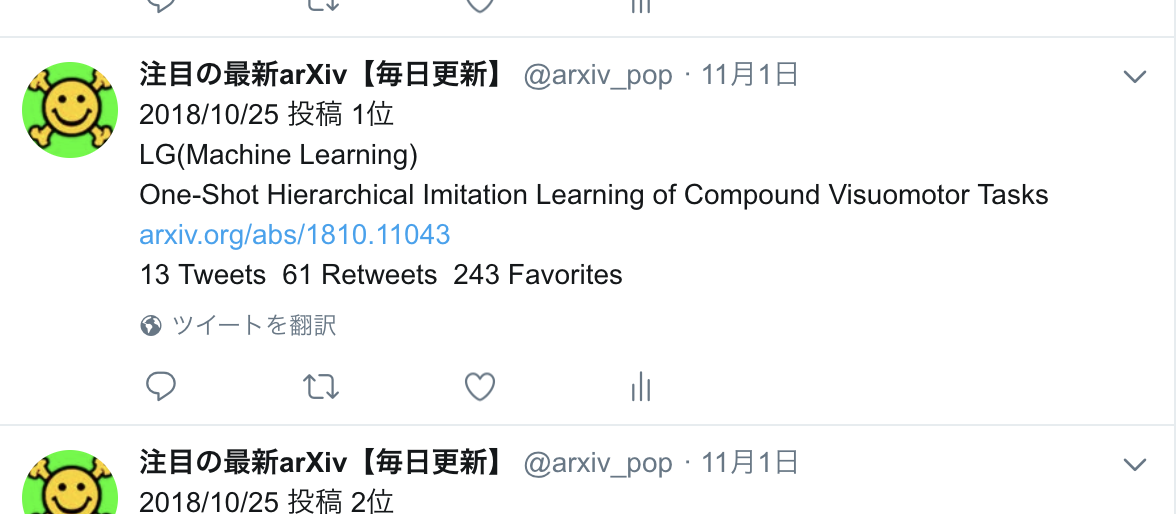
1週間前に投稿されたComputer Scienceの論文から、ツイッターで反応が大きいもの5件を毎日つぶやくボット
こちらになります!
中身
Githubにあげました。
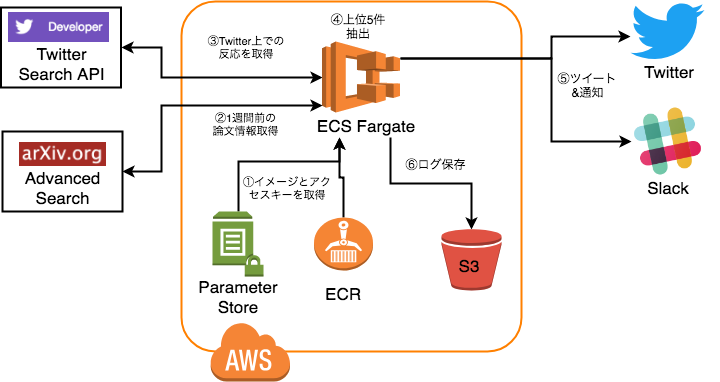
・構成図
-
DockerイメージをECRから、Twitter等のアクセスキーをParameter Storeから取得
-
1週間前に投稿されたComputer Scienceの論文を全て取得
-
論文のURLをTwitterの検索APIに投げて、ツイート数、リツイート数、いいねの数を取得
-
全部足して、大きいもの順に並び替えて、上位5件を抽出する。
-
ツイッターとSlackに通知する。
-
ログをS3に保存
開発に辺り工夫した点
アクセスキーはParameter Storeから直接取ってくる
Docker上で、アクセスキー等を扱うときは環境変数に格納しておくのが、一般的だと思います。
しかし、今回は環境変数には格納せずに、AWSのパラメタストアに全て入れておいて、
import boto3
ssm = boto3.client('ssm')
def parameter_aws(parameter_name):
return ssm.get_parameters(Names=[parameter_name],WithDecryption=True)['Parameters'][0]['Value']
class Params(object):
TWITTER_CONSUMER_KEY = parameter_aws('arxiv_pop.TWITTER_CONSUMER_KEY')
TWITTER_CONSUMER_SECRET = parameter_aws('arxiv_pop.TWITTER_CONSUMER_SECRET')
TWITTER_ACCESS_TOKEN = parameter_aws('arxiv_pop.TWITTER_ACCESS_TOKEN')
TWITTER_ACCESS_SECRET = parameter_aws('arxiv_pop.TWITTER_ACCESS_SECRET')
SLACK_URL_PRIVATE = parameter_aws('arxiv_pop.SLACK_URL_PRIVATE')
SLACK_URL_OFFICE = parameter_aws('arxiv_pop.SLACK_URL_OFFICE')
S3_BUCKET_NAME = parameter_aws('arxiv_pop.S3_BUCKET_NAME')
のような形で、プログラムから、パラメタストアを呼び出す形にしました。
こうすることで、手元のPCで動作させる際には、
docker run -v $HOME/.aws:/root/.aws -e ARXIV_POP_TEST_OR_PROD=test --rm arxiv_pop:1.0 python /root/arxiv_pop/paper_bot.py
のように、AWSのキー(とtest環境とprod環境の区別)のみを、dockerに渡せば良くなりました。
これは、Fargateでも同様です。
しかもこちらに関しては、AWSへのアクセスはロールで管理出来るので、
渡すパラメタは、ARXIV_POP_TEST_OR_PROD=prodの環境変数のみとなります。
arXivから論文の取得
1週間前に投稿された論文のタイトルとabstractのページのURLを取得します。
最初はarXivのAPIを普通に使うつもりだったのですが、
どうやら日にちの指定が出来なさそうだったため、
Advanced SearchのURLにパラメタを直接入れて、
帰ってきたHTMLをパースして結果を取得する形にしました。
Twitter上での、ツイート、リツイート、お気に入りの数を取得
TwitterのSearch APIでアブストのURLを検索して、ツイートを取得します。
課金はしておらず、standard APIで十分でした。
論文タイトルではなく、URLで検索している理由ですが、
タイトルが短い論文の場合に、関係のないツイートが大量に引っかかる可能性があること。
逆に長過ぎるタイトルは、省略されてしまっていることが多いからです。
arXivのURLは短いですし、
関連するツイートにはほぼリンクが貼ってあるので、URLでの検索結果を利用しました。
反応が大きいもの順に並び替える。
反応の大きさをどう測るかですが、検索にヒットした、ツイート数、そのツイートのリツイート数、お気に入りの数を単純に全部足しています。
重みを変えるなどの工夫は特にしていません。
色々見てみましたが、ツイート数はどの論文も2~20程度で、そこまで違いがありません。
そのため、反応の大きさはほぼリツイート数とお気に入りの数で決まってしまいます。
ただ、リツイート数が多いものは、お気に入りの数も多いため、
単純に足して出した「反応の大きさ」と、人がツイッターを見て思う「反応の大きさ」とはほぼ一致すると思います。
上位5件をつぶやく
上位5件を取ってきて、Twitterに通知します。
5件に根拠は無いです。なんとなくです。
slackにも通知
ついでに会社とプライベートのslackにも通知しています。
会社の人にも結構好評でした。

料金
CPU: 0.25 vCPU
メモリ: 0.5GB
起動時間2分/日。
分単位課金。
おかげで料金は月々3円!!!
雑感
個人的にはかなり便利だと感じています。
もちろん、ツイッター上で全然話題になってならないけれどめっちゃ良い論文はあると思うのですが、
逆にツイッターで反応が大きいのに微妙な論文は少ない印象です。
とりあえず、個人的な目的は十分果たせたかと思います。
ちゃんと良い論文が上位に来ているかどうかですが、
arXivの論文をまとめているところで出てくる論文は、今回のbotでも上位に来ている印象です。
(arXivTimesとかはとても参考にさせてもらっています。)
このようなサイトがあるにも関わらず、作った理由ですが、
現状の「研究の流れ」みたいなものを把握したかったからです。
実際、毎日来る論文を見ることで、この辺のキーワードの論文多いなというのはなんとなくわかります。
(Graph Convolution多い!)
ちなみに友人に聞いたら、IFの高い論文を話題になる前からつぶやいているユーザをフォローしていると言っていました。
みんな考えることは似ていますね。
もし、良いなと思ってもらえましたら、こちらをフォローしてもらえると嬉しいです!