はじめに
web開発の学習のアウトプットとして大規模言語モデルを活用したwebアプリを作成しました。
備忘録を兼ねて開発の詳細について記していこうと思います!
目次
1. アプリの概要
2. アプリを作ったきっかけ
3. アプリの機能
4. 使用技術
5. 工夫したところ・こだわったところ
6. 大変だったところ・詰まったところ
7. 追加したい機能・改善点
8. 学んだこと
1.アプリの概要
一言で言うと、チャットアプリです。
研究室の学生に向けて作成したもので、研究関連の資料に特化したチャットボットを作成し、その内容について質問することができるアプリです。
開発期間は1ヶ月程度でした。
イメージ
アプリは3画面構成になっています。チャットを行うチャットページ、チャット履歴を確認できる履歴ページ、ファイルの共有ができる資料共有ページがあります。
チャットページと履歴ページ

チャットページ
チャット名を入力 → ファイルアップロード → チャット開始
という流れで実行します。
メッセージを入力して送信ボタンを押すとメッセージがポストされます。
デモ動画では2024年卒大学生就職企業人気ランキングの内容についてチャットしています。
「要約して」に対してしっかり回答が返ってくることがわかります。また、ソニーの得票数もしっかり合致しています。
※APIのトークンの関係で英語で入力しています。
履歴ページ
ここでは過去のチャット内容が閲覧できるようになっています。
削除ボタンを押せば、チャット履歴を削除することができます。
資料共有ページ
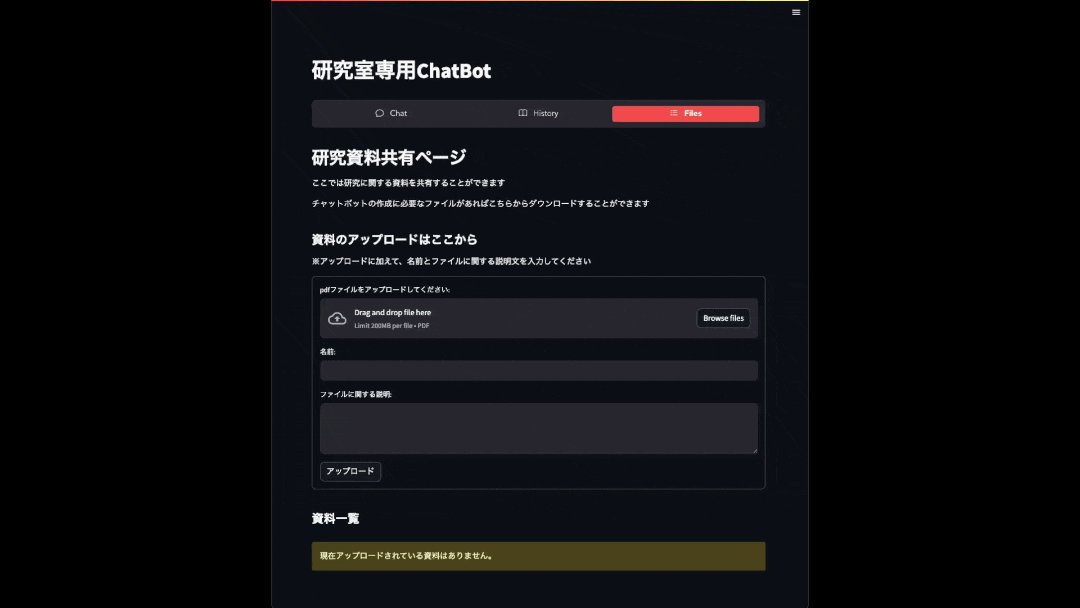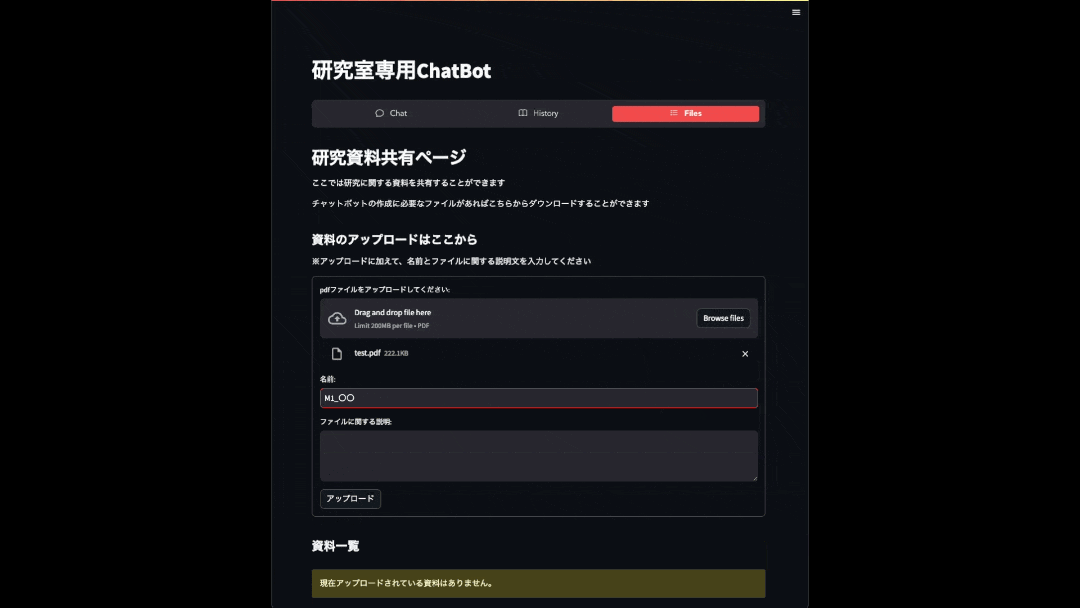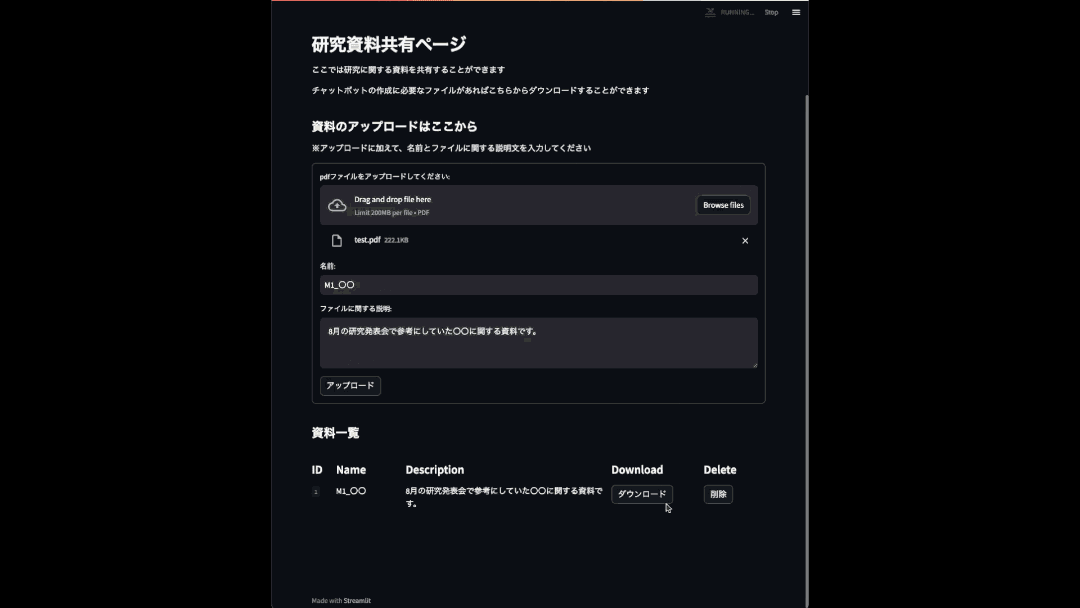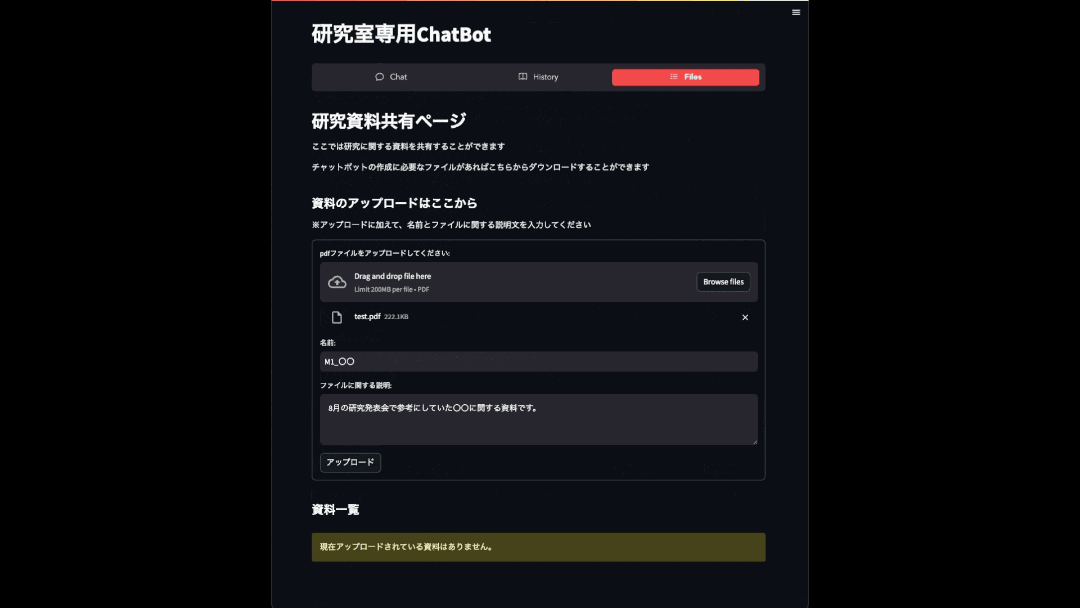
ここでは、教授や学生の間で資料が共有できるページになっています。
アップロード欄からファイルをアップロードすることができます。
アップロードした資料は資料一覧のところに保存されていく仕様になっています。
資料をダウンロードしたいときはダウンロードボタンを、データを削除したい場合は削除ボタンを押します。
このページを作成した理由
友人からの要望が理由です。元々はチャットページと履歴ページのみの構成でした。
研究活動において、教授や学生同士でメールやLINEで研究資料を送り合うことが多いです。
資料を探す際、メールやLINEだとメッセージの履歴を辿っていかなければならず、面倒でした。
そこで、共有する資料を一元管理できる機能があれば便利ではないかと思い、このページを作成しました。
ER図

2.アプリを作ったきっかけ
大学での研究活動の効率化が目的です。友人や後輩に聞いたところ、研究活動を進めるにおいて以下の課題がありました。
- 教授や先輩は忙しく、質問できる機会が限られておりなかなか疑問を解消することができない
- 簡単な質問はなんとなくしづらい、、、
- 研究内容は専門性が高く、webやChatGPTを使っても有効な答えを得られない
- ChatGPTの有料版でないとPDFファイルの内容を学習させることができない
- 無料で使えるChatPDFだと一つのファイルしか学習させることができず、回答範囲が狭い
これらの課題を解決して研究活動を進めやすくなれればいいなと思い、研究室専用のチャットボットを作成しました。
3.アプリの機能
◆ チャット機能
- PDFファイルのアップロード機能
- ChatGPTAPIの機能を利用し、PDFファイルの内容をベクトル化する機能(OpenAI Embeddings API使用)
- Vector Store (Chroma) を利用してベクトル化された文章を保存・検索する機能
- アップロードされたファイルの内容に関してのチャット機能(ChatGPT API使用)
◆ チャット履歴閲覧機能
- チャット履歴の取得 / 作成 / 削除機能
◆ ファイル共有機能
- PDFファイルのアップロード機能
- 資料共有データの取得 / 作成 / 削除機能
- PDFファイルのダウンロード機能
4.使用技術
フレームワークについて
今回のアプリではバックエンドにPythonのFastAPI、フロントエンドにPythonのStreamlitを使用しています。
FastAPIを選択した理由について
- Pythonでコードを書きたい
- 学習コストが低い
- APIドキュメントが自動生成される
正直なところ、自分はプログラミング経験が浅くPythonしか勉強したことがなかったため、まずはアプリを動かすことが最優先だったこともあり慣れているPythonのフレームワークを使用することにしました。
また、型定義ができることやドキュメントの自動生成はPythonの他のフレームワークであるDjangoやFlaskなどにはない機能で、開発経験が少ない自分にとって効率的にAPI開発ができるところに魅力を感じ、FastAPIを選択しました。
Streamlitを選択した理由について
- 直感的かつ容易にフロントエンド開発ができる
特にデザインにこだわりはなく、シンプルなUIができれば十分だと考えていました。数行コードを書くだけで簡単にUIが作成できるのがとても便利だと感じました。
また、バックエンドにFastAPIを使用しており、バックエンドとフロントエンドで言語を揃えることができるのも魅力の一つでした。
DBについて
データベースはSQLiteを使用しています。
SQLiteを選択した理由について
- 今回のwebアプリのユーザー数が限られている
- 他のDBに比べて設定が簡単
サーバーを用いないのでサクッと利用できるところがいいなと思いました。また、想定のユーザー数は数人を想定していたため小規模アプリケーションに向いているSQLiteを選択しました。
開発環境について
Pythonのパッケージ管理ツールであるPoetryを使用しました。
フロントエンドもバックエンドも全てPythonで実装しているため、Poetryを用いてパッケージの管理と仮想環境の構築を行いました。
デプロイについて
フロント、バックエンドともにRender.comというクラウドサービスを採用しました。
簡単にデプロイできるHerokuを使おうと思っていたのですが、有料化になったと聞き、別のサービスを探したところ多くの人がRender.comを使用していたので採用しました。
管理画面を簡単に操作するだけでデプロイが完了しました。
また、GitHubのレポジトリと紐づけているので、pushした際に自動でデプロイしてくれるのはとても便利でした。
APIについて
チャット機能を実装する際に、OpenAIのAPIを使用しました。
APIを活用してPDFファイルの内容の解析や、ユーザーからの質問に対する回答の生成の実装を行いました。
5.工夫したところ・こだわったところ
PDFファイルのテキストをEmbeddingし、ベクトル検索を行うことでチャット機能を実現
チャット機能の実現方法としてPDFファイルの内容をChatGPTのモデルにファインチューニングする方法も考えられました。PDFの内容についてモデルを最適化することでより精度の高い回答を生成することができます。しかし、
- ファインチューニングは計算資源を大量に消費し、チャットボットの作成に時間がかかることでユーザーがスムーズに利用できない
- 実装がより複雑になる
という問題がありました。ファインチューニングと比べ回答精度は劣るものの、すぐにチャットボットを作成して疑問を解消することが重要だと判断し、Embeddingによるベクトル検索での実装を試みました。
ChatGPTなどの大規模言語モデルの機能を拡張できるLangChainライブラリを用いて簡単に実装することができました。
実装の流れ
PDFからテキストデータを抽出
from langchain.document_loaders import PyPDFLoader
# PDFファイルのテキスト抽出
def pdf_load(files):
docs = []
for file in files: # 複数ファイルにも対応
loader = PyPDFLoader(file.name) # インスタンスを作成
loaded_docs = loader.load() # テキストを抽出
if loaded_docs:
docs.extend(loaded_docs)
return docs
これでPDFファイルのテキストを抽出することができました。
テキストデータのEmbedding(ベクトル化)
質問内容とPDFの内容をもとに回答を生成します。つまり、質問に似た内容がPDFにあるかどうかを探す必要があります(文章の類似性を判断することになる)。
テキストデータは非構造化データであり数値化されていないため、類似性を図ることができません。
そこで文章を数値に変換(ベクトル化)する必要が出てきます。これがEmbeddingと言われるものです。
そこでOpenAIのEmbeddings APIを利用してPDFのテキストデータをEmbeddingします。
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.indexes import VectorstoreIndexCreator
# Embedding
def embedding(docs):
index = VectorstoreIndexCreator(
vectorstore_cls=Chroma,
embedding=OpenAIEmbeddings(),
).from_documents(docs)
return index
VectorstoreIndexCreatorを用いてEmbeddingされたテキストデータをインデックス化します。
その際、Chromaというデータベース(ベクトルストア)にデータを保存します。こうすることで、類似性の検索が可能となります。
これでPDFのEmbeddingが完了しました。
ユーザーの質問内容をEmbeddingし、類似性の高い文書を検索
ユーザーからの質問内容のテキストデータを先ほどと同じようにEmbeddigします。
Embddingしたユーザーからの質問内容をもとに、Chromaデータベースから類似性の高い文書を検索し、最も関連性の高い文書を特定します。
回答の生成
先ほど取得した類似性の高い文書の内容を前提知識とし、ChatGPT APIを用いてユーザーの質問内容から回答を生成します。
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(temperature=0.0, model="gpt-3.5-turbo-1106")
pdf_response = index.query(user_input, llm=llm) # user_inputはユーザーの質問内容
temperatureは回答の精度を指示するための引数です。0に近いほどPDFの内容に沿った確実性の高い回答を生成し、値が大きいほどより創造的な回答をするようになります。
回答の一貫性を出すためにtemperature=0.0と設定しています。
参考文献
チャット履歴の閲覧・削除ができるようにしたこと
履歴が残れば過去のチャット内容を後から見返すことができるので、ユーザーにとって必要な機能なのではないかと考え実装しました。
履歴機能があれば、同じことを調べたくなった時に再度チャットする必要がないので便利だという意見をもらうことができました。
6.大変だったところ・詰まったところ
バージョン管理
当初、ローカル環境では正しく動いたのにデプロイ後は思うように動きませんでした。
具体的には、ローカルではそれぞれのライブラリのバージョンの互換性が合っていたものの、Render.com上では対応しておらず、その調整が大変でした。
例えばSQLiteとChromaのバージョンの対応が合わずRuntimeError: Your system has an unsupported version of sqlite3. Chroma requires sqlite3 >= 3.35.0となったり、これが解決できたと思ったら次にlangchainとpydanticのバージョンが合わずTypeError: issubclass() arg 1 must be a classというエラーがでたりしていました。
一つのライブラリのバージョンを変更すると、エラー対象になっていたライブラリの依存関係は解消できたものの、別のライブラリとの互換性に問題が発生するなど、バージョン管理が大変でした。
どうやって乗り越えたか
- ローカルとRender.comでの環境の違いを調べる
Render.comでデプロイする際にDBとしてSQLiteを設定していましたが、Render.comではデフォルトで古めなバージョンのSQLiteが入っていることがわかりました。
それにより、今回使用したChromaライブラリがSQLiteに対して要求する最低バージョンを満たしておらず、エラーになっていました。
Render.comのSQLiteのバージョンを指定することはできなそうだったので、ChromaやRender.domのドキュメントを参考にしてpoetryでChromaのバージョンを変更することにしました。
バージョンを変更したらその都度コードを実行し、次のエラーを確認してそれを潰していくというサイクルで、解決することができました。
セッション管理
当初の実装では、1回目のチャットではメッセージを送信してそのメッセージに対する回答が返ってきていたのですが、2回目のチャットではメッセージを入力して送信ボタンを押すとメッセージは送信されず、最初のチャット名の入力に戻ってしまうようになっていました。
原因としてはStreamlitの仕様に問題がありました。「ボタンを押す」などリロードが発生した場合、初めのコードから再実行するようになっており、セッションが保持できず、チャット名ごとにチャットを続けることができなくなっていました。
どうやって乗り越えたか
- コードの途中にいくつか
st.json()を挟み、レスポンス内容を確認して問題箇所を特定する - Streamlitの
Session State機能を用いる
Session State機能はリロード時もデータが保持できるようにする機能です。
送信ボタンの実行の次に以下のように条件を設けました。session_idがなければまだチャットを開始していないということなので、チャット名を入力した際に発生したidをsession_idとして保持するようにしました。また、session_idが保持されている場合は引き続きそれをsession_idとして用いるように実装しました。
# session_idがすでにあるかどうかの確認
if 'session_id' not in st.session_state or not st.session_state['session_id']:
この機能を使うことでフロント側のsession_idを保持し、2回目以降のチャットも継続できるようになりました。また、保持しているsession_idを元にバックエンド側と通信するようにし、session_idごとにチャット内容を保存するようにしました。
※
not st.session_state['session_id']まで条件に含めている理由としては、保持しているsession_idが0の時は無効と判断され新たにsession_idが生成される場合もあるからです。(ここでかなりはまりました)
if 'session_id' not in st.session_state:のみでは時々うまく実行できないことが多かったので、条件を増やし常に有効なsession_idになるようにしました。
7.追加したい機能・改善点
-
キャッシュ機能を持たせる
Streamlitの仕様上、リロードするたびにコードが最初から再実行されます。そのため処理速度が遅くなるという問題があります。友人からのフィードバックでもたまに処理が遅いのが気になると言われました。
PDFファイルの解析などは関数化し、その関数に対してキャッシュ機能を持たせることで改善しようと考えています。
後からコードを修正することを考えて、コードを記述する際に関数化することを意識しておけばよかったと後悔しました。 - OAuth2認証を導入し、各ユーザーごとにチャット・履歴閲覧をできるようにする
- 資料一覧に保存されたファイル名と容量を表示する
8.学んだこと
- CRUD処理のためのAPIの実装
-
途中でデータベースのテーブルを変更する際はマイグレーションが必要
ORMライブラリとしてSQLAlchemyを使用していたので、Alembicを用いてテーブル変更を行いました。 - 実際に誰かに使ってもらってフィードバックをもらうこと
- LangChainによる大規模言語モデルLLMの基礎的な扱い方
- コードの再利用性、可読性、保守性を考えてコードを記述するときはなるべく関数化できないかを意識する
-
Dockerを用いて開発環境を構築した方が便利
今回はpoetryでバージョン管理を行いましたが、それによりRender.comを使用する際にエラーが出てしまう問題が発生しました。今後はDockerを用いてアプリケーションとその依存関係を一つのパッケージにまとめることで他サービスの影響を少なくしていきたいです。そのためにもDockerについての知見を深めていこうと思います。