Finetuning (transfer learning)は学習済みのモデルを元にして、希望のターゲットについて学習させ直す技術。正しいモデルを選ぶと1から学習させるよりも少ない学習データで圧倒的に早く望みの結果を得られ、学習にかかる時間とコストを削減できるぞ。
今回は人間の顔を生成するモデルをFinetuneして、anime-facesを生成させるようにする。
また、マシンも金もないので、GCPのVMを使ってなるべくコストを抑える。
参考
https://github.com/NVlabs/stylegan2
https://towardsdatascience.com/stylegan-v2-notes-on-training-and-latent-space-exploration-e51cf96584b3
環境
[GCP]
Machine type:
custom (8 vCPUs, 50 GB memory)
GPUs:
1 x NVIDIA Tesla K80
Disc:
200GB
Framework:
TensorFlow Enterprise 1.15
※学習途中でエラーになるので、メモリとディスクはケチっちゃダメ
※gpuのquoraを増やすのを忘れないように
※Frameworkに気をつけて、Stylegan2はtf2.0では動かないぞ
※お値段$0.667/hour
準備
1.元となるモデルをダウンロード
以下から faces (FFHQ config-e 256x256) をダウンロード
https://reposhub.com/python/deep-learning/justinpinkney-awesome-pretrained-stylegan2.html
gdown https://drive.google.com/uc?id=1BUL-RIzXC7Bpnz2cn230CbA4eT7_Etp0
2.データセットをダウンロード
今回はkaggleから以下を使用
https://www.kaggle.com/splcher/animefacedataset
pip install -q kaggle
cp kaggle.json ~/.kaggle/
chmod 600 ~/.kaggle/kaggle.json
kaggle datasets download -d splcher/animefacedataset
unzip animefacedataset.zip -d animefacedataset
3.Stylegan2のリポジトリをClone
git clone https://github.com/shawwn/stylegan2.git
4.データセットの画像を学習用に加工する
Stylegan2の学習用画像は正方形かつ辺のサイズが2の累乗でなくてはいけないため、事前に画像のサイズを加工しておく。今回はPythonのスクリプトを使い、256 * 256のサイズに加工した。
from PIL import Image
import PIL
import os
import glob
filenames = glob.glob("~/animefacedataset/images/*.jpg")
stylegan_dir = '~/stylegan2/animefacedataset/'
base_width = 256
for filename in filenames:
new_filename = stylegan_dir + filename.split('/')[-1]
image = Image.open(filename)
width_percent = (base_width / float(image.size[0]))
hsize = int((float(image.size[1]) * float(width_percent)))
image = image.resize((base_width, hsize), PIL.Image.ANTIALIAS)
if image.size[0] == image.size[1] == base_width:
image.save(new_filename)
5.データセットを作成する
画像をmulti-resolution TFRecordsに変換する
リポジトリに含まれているdataset_tool.pyを使って簡単に変換できる。
詳細は以下
https://github.com/NVlabs/stylegan2#preparing-datasets
python dataset_tool.py create_from_images ~/stylegan2/datasets/animedataset ~/animefacedataset
[エラーあるある]
以下は正方形でない画像が含まれていた場合に起きるエラー
Loading images from "./animefacedataset"
Creating dataset "./datasets/animedataset"
Added 16 images.
Traceback (most recent call last):
File "dataset_tool.py", line 642, in <module>
execute_cmdline(sys.argv)
File "dataset_tool.py", line 637, in execute_cmdline
func(**vars(args))
File "dataset_tool.py", line 526, in create_from_images
tfr.add_image(img)
File "dataset_tool.py", line 78, in add_image
assert img.shape == self.shape
AssertionError
6.Finetuning用にスクリプトを改造
元のrun_training.pyを改造してFinetuningを行えるようにする。
run()に以下を書き足す
train.resume_pkl = "/home/kitigai/ffhq-256-config-e-003810.pkl" # 1でダウンロードした学習元モデル, None = train from scratch.
train.resume_kimg = 3810.0 # 学習元モデルの学習進捗 別に0.0でも良いと思う.
train.resume_time = 0.0 # 学習元モデルの学習時間 分からないし別に0.0でも良いと思う.
元のmetrics/frechet_inception_distance.pyがやたらでかい.pklをダウンロードしようとして"Google Drive quota has been exceeded"になるのでローカルにダウンロードしてきた.pklを使用するように変更
def _evaluate(self, Gs, Gs_kwargs, num_gpus):
minibatch_size = num_gpus * self.minibatch_per_gpu
#inception = misc.load_pkl('https://nvlabs-fi-cdn.nvidia.com/stylegan/networks/metrics/inception_v3_features.pkl')
inception = misc.load_pkl('/home/kitigai/inception_v3_features.pkl', 'inception_v3_features.pkl')
activations = np.empty([self.num_images, inception.output_shape[1]], dtype=np.float32)
7.学習開始
コマンドの詳細は以下
https://github.com/NVlabs/stylegan2#training-networks
python run_training.py --num-gpus=1 --data-dir=datasets --config=config-e \
--dataset=animedataset --mirror-augment=true
[エラーあるある]
- --data-dirや***--dataset***に渡すパスに"/"や"."が入っているとエラーになる
# ダメなやつ
--data-dir=./datasets
# ダメなやつ2
--dataset=/home/kitigai/stylegan2/datasets/animedatasets
- 半端なメモリだとエラーになる
RAM:30GB のVMを使っていたら以下のエラーになったので50GBまで増やした。ケチってはいけない
Traceback (most recent call last):
File "run_training.py", line 192, in <module>
main()
File "run_training.py", line 187, in main
run(**vars(args))
File "run_training.py", line 120, in run
dnnlib.submit_run(**kwargs)
File "/home/myuser/stylegan2-master/dnnlib/submission/submit.py", line 343, in submit_run
return farm.submit(submit_config, host_run_dir)
File "/home/myuser/stylegan2-master/dnnlib/submission/internal/local.py", line 22, in submit
return run_wrapper(submit_config)
File "/home/myuser/stylegan2-master/dnnlib/submission/submit.py", line 280, in run_wrapper
run_func_obj(**submit_config.run_func_kwargs)
File "/home/myuser/stylegan2-master/training/training_loop.py", line 341, in training_loop
metrics.run(pkl, run_dir=dnnlib.make_run_dir_path(), data_dir=dnnlib.convert_path(data_dir), num_gpus=num_gpus, tf_config=tf_config)
File "/home/myuser/stylegan2-master/metrics/metric_base.py", line 151, in run
metric.run(*args, **kwargs)
File "/home/myuser/stylegan2-master/metrics/metric_base.py", line 67, in run
self._evaluate(Gs, Gs_kwargs=Gs_kwargs, num_gpus=num_gpus)
File "/home/myuser/stylegan2-master/metrics/frechet_inception_distance.py", line 54, in _evaluate
labels = self._get_random_labels_tf(self.minibatch_per_gpu)
File "/home/myuser/stylegan2-master/metrics/metric_base.py", line 140, in _get_random_labels_tf
return self._get_dataset_obj().get_random_labels_tf(minibatch_size)
File "/home/myuser/stylegan2-master/metrics/metric_base.py", line 121, in _get_dataset_obj
self._dataset_obj = dataset.load_dataset(data_dir=self._data_d
ir, **self._dataset_args)
File "/home/myuser/stylegan2-master/training/dataset.py", line 192, in load_dataset
dataset = dnnlib.util.get_obj_by_name(class_name)(**kwargs)
File "/home/myuser/stylegan2-master/training/dataset.py", line 86, in __init__
self._np_labels = np.zeros([1<<30, 0], dtype=np.float32)
MemoryError: Unable to allocate 0 bytes for an array with shape (1073741824, 0) and data type float32
結果
顔の向きや口元の表情、髪型に注目すると最初の人物の顔とアニメ顔に関連性があることが分かる。これは生成画像の大雑把なところを決めるネットワークの低レベル層がほとんど共通しているため。元のモデルとアニメモデルに同じlatent space を与えると似通った顔ができておもしろいぞ。
学習30分後
まだまだ

学習10時間後
もうそれっぽい

学習48時間後
よさそう

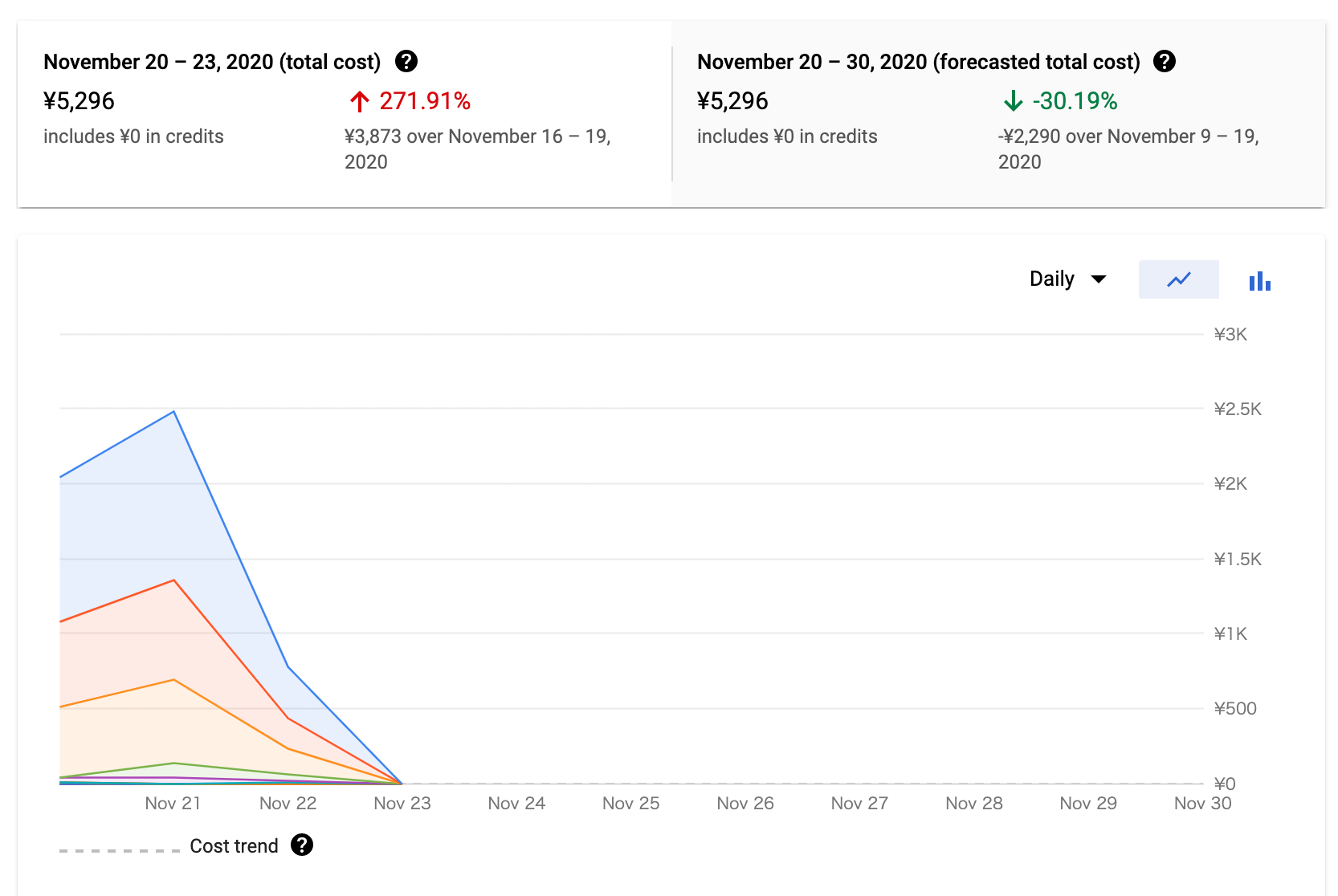
お値段
結構かかった。つれーわ。
まとめ
- Finetuningを使って短時間でそれなりの成果を出せた。
- 6時間の時点で満足しておけばコストも抑えられた
※比較:1から学習した場合の予想時間
今回はconfig-eなので下よりも時間はかからないが、それでも10dはかかるだろう
| Configuration | Resolution | Total kimg | 1 GPU | 2 GPUs | 4 GPUs | 8 GPUs | GPU mem |
|---|---|---|---|---|---|---|---|
| config-f | 256×256 | 25000 | 32d | 13h | 16d | 23h | 8d |
- 人間顔とアニメ顔で似た表情になるのは面白い。ここらへんまだ遊べそう