はじめに
スタックチャン(Stack-chan)で10分ポモドーロ(10分毎に時刻をお知らせ)を動かしています。
enebularのクラウド実行環境を使用して実装しています。
何もしていないのに動かなくなった
ある日(2025年4月10日くらいから)、スタックチャンが動かず、「分」の発話しかしなくなりました。
動き(上を向いて口を動かす)→発話(「時」と「分」)→動き(元に戻る)
から
発話(「分」)
のみに動作が変わってしまいました。

無意識的にいつもの期待している動作が変わると、違和感しかありません。
動きがなく、いきなり発話(しかも「分」のみ)されると、少し怖いです。
一時的だと思いたい
最初は「なんか、動かないなー」と様子見していましたが、常態化するとストレスを感じ始めます。
「AWS Lambda」の調子が悪いのかなー、とか「enebular」の不具合かなー、とか他人のせいを考えますが、同じ状態が1〜2日続くとなんとかしなきゃ、と考え始めます。
再デプロイ
enebularのアップデートでNode-REDの実行環境が変わることがある(バージョンアップなど)ので、同じフローをクラウド実行環境に再デプロイしました。
クラウド実行環境のログを確認して、AWS Lambdaも問題なく実行されていることを確認しましたが、動作が変わりません。
切り分け調査
enebularのフロー編集から実行すると動作は問題ありません。
クラウド実行環境のHTTPトリガー(HTTPリクエストでフローを実行)の動作も問題ありません。
クラウド実行環境のスケジュールトリガー(フローを時刻指定で実行)の動作だけ動作がおかしいことを確認しました。
(あとの調査で、HTTPトリガーの動作も時間を空けると動作がおかしいことを確認しました。)
原因を推察する
Node-REDのフローは以下のとおりです。

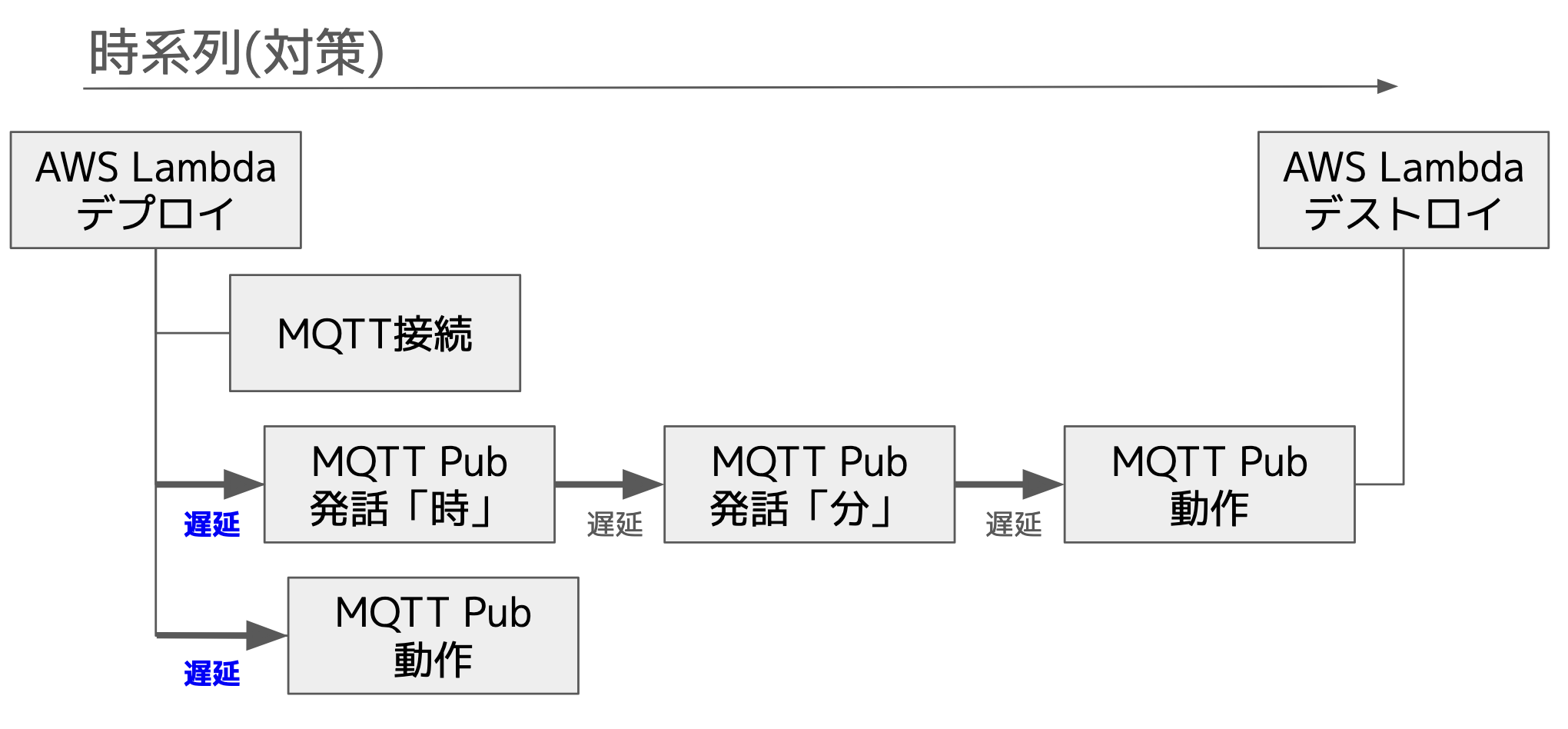
期待する動作の時系列は以下のとおりです。(AWS Lambdaの場合)

通常、Node-REDは常時プロセスが起動していますが、AWS Lambdaの場合はNode-RED実行環境がデプロイされ、フローの実行(「LCDP in」ノードから「LCDP out」ノードまで)が完了すると、破棄(デストロイ)されます。
(デストロイされてから短い時間で再度フローを実行する場合は、キャッシュが利用され高速にデプロイ実行されます。)
切り分け調査の結果から、Node-RED実行環境がデプロイされ、フロー実行開始直後の動作に問題がありそうです。
仮説としてMQTT接続が遅れた場合、発話(「時」)と動作の情報が破棄される可能性があります。
Node-REDはNode.jsで動作しており、基本的に非同期処理でフローが進行するため、MQTT接続の完了を待ってからMQTT(Publish)の送信をしていません。

対策を考える
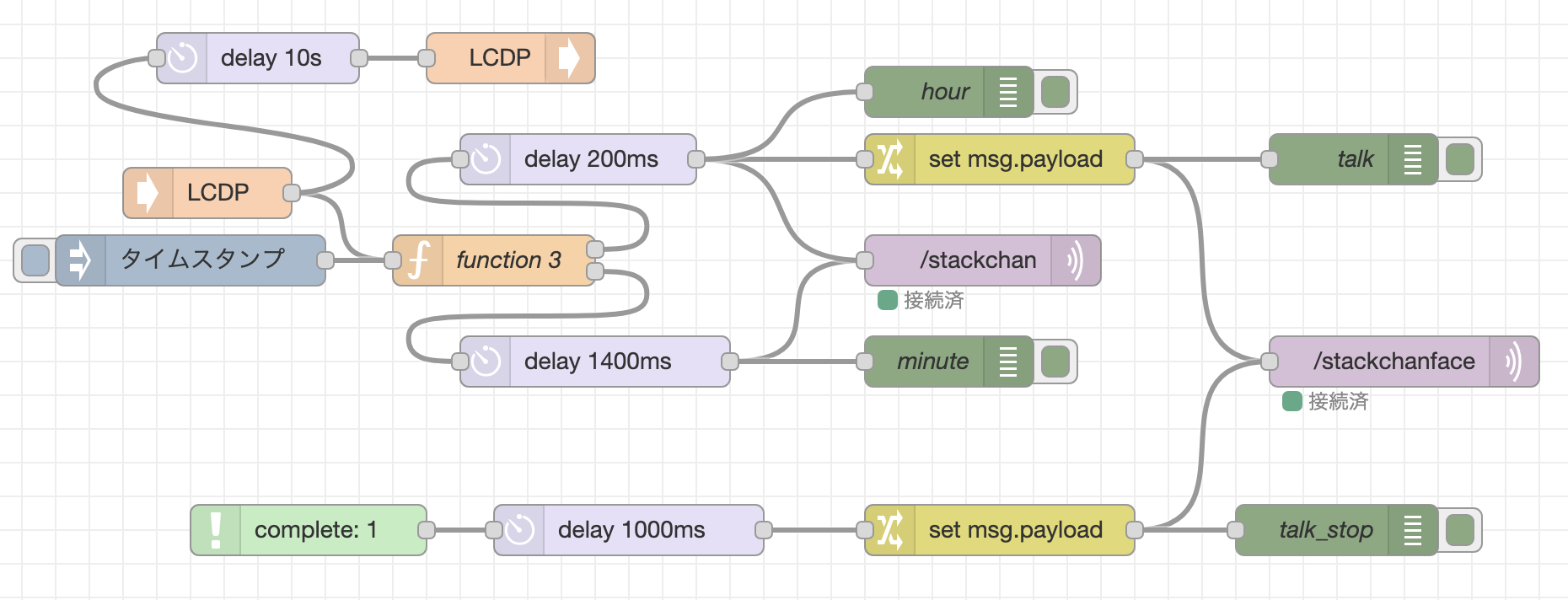
Node-REDには「complete」ノードが存在し、指定したノードの実行完了をトリガーにすることが可能ですが、「MQTT out」ノードのMQTT Brokerとの接続完了をトリガーにすることができないので、単純にMQTT(Publish)の送信の前に遅延(200 msec)を入れることにしました。
フローを変更する
変更後のNode-REDのフローは以下のとおりです。
あとがき
いまのところ期待通りに動作しています。
原因が分かってしまえば対策は簡単ですが、原因の推察〜仮説〜対策の検討〜検証までの一連のプロセスを経験することは、現実の世界で環境が変わった場合に適応するために重要です。