はじめに
はじめまして、30代後半かつ未経験からITエンジニアを目指しているまっきーと申します。
理系大学院(専攻はメカ系)を卒業後、新卒で12年間大手メーカーでものづくり技術者として働いてきましたが、この度社内制度の『研修型社内転職制度』に応募し、本研修を経たのちにソフトウェアエンジニアとして再スタートすることが決まっています。
11月より4ヶ月間みっちり研修で学んでから実務に入る予定なのですが、ここでの学びを自分用のメモとして残そうと思い、今回Qiitaに初めて記事を投稿することにしました。
これを書くまでマークダウン記法の意味すらわかっていなかったアラフォーのおじさんですが、
同じく30代後半以上の方や未経験からエンジニア転職を目指す方の励みに少しでもなればうれしいです。
(記事は4ヶ月にわたり都度更新していきます)
※更新終わり
研修に参加しよう(=ソフトウェアエンジニアとして再スタートしよう)と思った理由
入社以降、生産技術に関わる研究開発に12年関わってきました。
業務内容はレンズの研削研磨加工、材料開発、スパッタによる光学薄膜の成膜、と専門のメカを超えた業務に 広く浅く 関わってきました。
しかしながら「市場価値」という点でみると、これまでの業務経験は積み上げにつながっていないのでは・・・という不安も日々高まっていました。
そんな中で知った本研修でした。
ソフトウェアエンジニアには20代の頃から憧れはありました。
ただ、「30代後半からこの世界にまったくのゼロから飛び込む入るのは手遅れなのでは・・」という不安もありました。
ですが、 「やらない後悔」より「やってから後悔」 しようという思いから、チャレンジすることにしました。
このときはまだ、ソフトウェアエンジニアとして何がしたいか漠然としていて面談でもうまく言葉にできなかったことを覚えています。
※なお、今では理想の職場(工場のIoT化、AI化を推進する部門)に配属され、あとは自分の努力次第という環境でがんばっています。
研修を終えての所感(※研修受講後に追記)
4ヶ月というまとまった時間を学習に充てることができただけでもこの研修に参加できて本当によかったと感じています。(しかも給料をもらいながら・・)
僕は大学時代にC言語の学習を早々に投げ出してしまったこともあり、地頭の悪さも相まって4ヶ月間はまわりより遅れることもしばしばありました。
そのときは苦しかったと感じます(チーム開発では特に)。
経産省のレポート『2025年の崖』(https://www.meti.go.jp/shingikai/mono_info_service/digital_transformation/20180907_report.html)にもある「IT人材の再教育」という点で、まさに自分が当事者になっていることを実感します。
ITの全体像を知り、その中で自分が何をやりたいかを研修期間中にはっきりさせることができました。
今ではすべての機器やプロセスをIoT化、AI化させて、ひとの暮らしを1ランク引き上げたいと考えています。
スタートラインに立てたばかりなので、これからもずっと平日の朝晩、休日はひたすら学習を続けることになると思いますが、高いモチベーションを保てているので、楽しんで学習を継続できそうです。
(早く貢献しなければ、という焦りや不安ももちろんありますが)
研修カリキュラム
はじめの1ヶ月は座学で以下を学びます。
WBT教材はネットラーニング社のものを用いました。
■WBT:はじめての情報技術(3日)
・コンピュータとは、コンピュータと生活
・情報の基礎理論
・アルゴリズムの基礎知識
・ハードウェアの基礎知識
・ソフトウェアの基礎知識
・ネットワークの基礎知識
・データベースの基礎知識
・情報システムの構築・運用・整備の基本的な流れ
■WBT:C言語プログラミングStep1(3日)
・C言語入門
・さまざまな基本データ型
・定数(リテラル)
・式と演算子
・制御フロー
・ファイル入出力
・関数と構造化プログラミング
■WBT:C言語プログラミングStep2(3日)
・ビット演算とマクロ
・ポインタ入門
・さまざまなデータ型とポインタ
・動的なメモリ管理
・コンパイルの仕組みとライブラリ
・ANSI標準ライブラリ
・低水準入出力
・データ構造
・アルゴリズム
■開発プロセス入門(1日、11/18)
ウォーターフォール型、アジャイル型それぞれの特徴を学ぶ
■ネットワーク技術入門(1日、11/19)
・ネットワークの種類、7階層、TCP/IPネットワーク
・無線ネットワークの仕組み(Wi-Fi、Bluetooth、公衆無線等)
・Web接続の仕組み(HTTP等)、画像・映像伝送の仕組み
・実践(LinuxPCをネットワークに接続しGoogle検索できるように)
■構造化分析設計入門(1日、11/20)
・代表的な設計図面(コンテキストダイアグラム、DFD、ストラクチャ・チャート)の表記法
・凝集度・結合度(モジュール分割の良し悪しの尺度のひとつ)
■製品セキュリティ技術入門(1日、11/24)
・セキュリティに対する考え方や被害、製品セキュリティの必要性
・セキュリティ法規制
・セキュア開発プロセス概要
■アルゴリズム入門(3日間、11/25〜11/27)
Python言語を用いて以下を学ぶ
・アルゴリズムの基本概念
・アルゴリズムを作るための考え方
・Python言語を用いた簡単なプログラムの構築
ここまでが座学。
2ヶ月目からは3ヶ月にわたって
以下のとおり演習とプロジェクト開発をチームでがっつり行います。
■C言語実装演習(9日間、11/30〜12/10)
C言語でさまざまなアルゴリズムを解くことでC言語の理解を深める。
またeclipse、redmine、Subversionの使用方法を学ぶ。
・タスク管理、バージョン管理
・統合開発環境
・モジュール分割、ヘッダファイル、make
・C言語文法の確認問題
・基本アルゴリズム問題
・データ構造問題
■開発プロジェクト演習1(15日間、12/11〜1/8)
開発課題の理解・要求分析からプロトタイプ開発まで
■開発プロジェクト演習2(17日、1/12〜2/3)
要件定義から納品まで
■WBT(HTML、CSS、JavaScript)
以下のファームウェア研修@外部は緊急事態宣言に伴い延期になったため、
実施されたら更新しようと思います。
■開発プロジェクト演習3(12日)
マイコン(RX)が搭載されたボードを使いファームウェアの基礎を学ぶ
<クロスC言語>
・組み込みC言語
・メモリ配置
・スタートアッププログラミング
・入出力制御
・C言語とアセンブリ言語のリンク
・割り込みプログラム
・プログラムのチューニング
・スイッチの押し下げ検出
・タイマ
・ADコンバータ
・シリアルコミュニケーションインターフェース
・ダイナミック点灯
・キースキャン
・パルスモータ
・DMAC
<リアルタイムOS>
・リアルタイムOSとは
・リアルタイムOSの仕組み
・リアルタイムOSの機能
・リアルタイムOSの搭載
・タスク設計
・実装上のポイント
・マルチタスクシステムのソフトウェア検証
以上がカリキュラムになります。
以下、各講義で学んだこと、印象に残ったこと、難しかった点について書きたいと思います。
WBT:はじめての情報技術(3日)
コンピュータサイエンス学習のおすすめ教材「キタミ式イラストIT塾 基本情報技術者」で学習しているコンピュータサイエンス基礎と多くが重なる内容でした。
■コンピュータとは・コンピュータと生活
・「コンピュータ」とは電気信号を処理して演算を行う機械の総称
・「IT(=情報技術)」とはコンピュータおよびそれに関連する機器によって情報を処理する技術のこと
・コンピュータはいわゆるPCだけでなく、自動車や家電製品の中など目に見えないところにも使われている(むしろそういうコンピュータの方が多い)
・コンピュータは利用法でみると「サーバ」と「クライアント」の2種類に分けられる。サーバはインターネットへの接続やデータベースの検索などネットワーク経由でさまざまなサービスを提供するコンピュータ(例.スパコン、ワークステーション)、クライアントはサーバへサービスや処理を要求するコンピュータ(例.PC、スマホ)
■情報の基礎理論
・コンピュータが扱う情報は「デジタル」(情報をとびとびの数値で表す方法)である
・デジタル情報では、「ない」または「ある」という二者択一の情報の量を1情報量とし、これをビットと呼ぶ。これ(電球をイメージするとわかり安い)が8個並んだ単位を1バイトと呼ぶ
・1KBは正確には2の10乗=1024バイト。1MBは1024KB、1GBは1024MB、1TBは1024GB
・「0」と「1」を扱うのに適した数の表現方法が「2進数」
・文字が表示される仕組みとして「1バイトコード」(ASCIIコード、JISコード(JIS X 0201))と「2バイトコード」(JISコード(JIS X 0208)Unicode)がある。日本では漢字を使うので両者を併用している
・0または1の2通りの値を与えた時、0(偽)または1(真)の1つの値を結果とする演算を論理演算という。論理演算を数式のように書き表したものが論理式(例.論理積、論理和)
■アルゴリズムの基礎知識
・コンピュータで情報を処理するにはまず情報がデジタル化されていなければならない。それに加え「命令」を使う必要がある。そこで、いくつかの命令を並べて1つのまとまりのある処理を行う「プログラム」をつくる
・プログラムを書くためのことばが「プログラム言語」であり、プログラム言語を使ってプログラムを書くことを「プログラミング」という。
・プログラム言語の種類は大きく「汎用プログラム言語」と「スクリプト言語」(HTML、JavaScript、XML等)に分けられる
・汎用プログラム言語には「低水準言語」(機械語、アセンブリ言語を指す。機械語はCPUが直接解釈して実行できるが人間には理解しづらい。そこで人間にとってわかりやすいことばでプログラムを書き、それを機械語に置き換える方法が考案された。その初期のものがアセンブリ言語)と高水準言語(Fortran、COBOL、BASIC、C言語、Javaなど)がある
・高水準言語はアセンブリ言語よりももっと人間の言語や考え方に近づけた言語として開発された。
・Fortran(1956年)、COBOL(1959年)、BASIC(1960年代)、C言語(1972年)、Java(1995年)
・アルゴリズムとは・・・プログラムをつくるには問題や仕事の内容を分析し、コンピュータがそれを処理する手順を決める。この処理手順のこと。
・アルゴリズムとプログラムは一体である。よいアルゴリズムの条件は正しいこと、わかりやすいこと、一般性や拡張性があること、効率が良いこと
・アルゴリズムをプログラムで表現していくうえで、データ構造(処理対象となるデータをどのような形でもたせるか)も大切。アルゴリズム+データ構造=プログラムと言える(例.配列、リスト、木構造、スタック、キュー)
■ハードウェアの基礎知識
・「ハードウェア」とはCPUやディスプレイなど形あるもの。(これに対しプログラムなど形のないものをソフトウェアと呼ぶ)
・コンピュータの5大機能・・・入力(例.キーボード、マウス)、出力(ディスプレイ、プリンタ)、記憶(例.メモリ、HDD)、演算(CPU)、制御(CPU)
・「CPU」(中央演算処理装置)はコンピュータの中枢部であり頭脳そのもの。IC(半導体集積回路)でできている。
・CPUの役割・・・プログラムを実行する時、CPUはプログラムに書かれた命令をメモリに記憶し、メモリから1つずつ取り出して解読(解釈)し、演算を実行したり各装置に指令を送ったりする。1つの命令の処理が終わると次の命令を取り出して演算や制御を行う。プログラムの処理はこの繰り返しで進んでいく。
・命令ひとつひとつは「命令コード」と「オペランド」(処理対象のメモリの中で置かれている場所のこと)で構成される
・CPUの中には「レジスタ」と呼ばれる一時的な記憶領域が存在する。主なレジスタとして、命令レジスタ、プログラムカウンタ、アキュムレータ、汎用レジスタがある
・CPUには論理演算を実際に電気的に処理する論理回路がある
・主記憶装置(メモリ)とは、CPUが読む命令やCPUが演算を行った結果を一時的に保管する記憶場所のこと。大きくRAM(ランダムアクセスメモリ)とROM(リードオンリーメモリ)がある
・解像度・・・フルハイディビジョン(FHD)の解像度(ピクセル数)は1920×1080。4Kは3860×2160
■ソフトウェアの基礎知識
・ソフトウェアには「システムソフトウェア」(コンピュータのハードウェアを制御)と「アプリケーションソフトウェア」(業務や仕事の種類に応じて開発される)がある
・システムソフトウェアには基本ソフトウェア(オペレーティングシステム(OS)とミドルウェア(データベース管理システム(DBMS)、かな漢字変換機能など)がある
・アプリケーションソフトウェアの種類・・・Word、Excel、Photoshop、ブラウザ全般、Outlook他)
・OSの位置づけ・・・ハードウェアとアプリケーションソフトウェアの間に位置し、両者の仲立ちをすることでユーザにとってコンピュータを使いやすくする環境を提供している
・OSの種類
| 種類 | 特徴 |
|---|---|
| UNIX | 1970年代に開発されたOS。サーバやワークステーション用として利用されることが多い。現在はLinuxなどの派生OSが人気。 |
| MS-DOS | 1981年に発表された、IBMとMicrosoftの共同開発によるOS。一度に1つのアプリケーションしか実行できない。 |
| Mac OS | 1984年に現Apple社から発表されたOS。Windowsに先行してGUIを採用。 |
| Windows3.0、3.1 | 1990年に発表。ユーザインターフェースにGUIを同社で初めて採用(Macに6年遅れ) |
・OSの主な機能・・・ジョブ管理、タスク管理、記憶管理、入出力管理など
・OSはユーザからジョブを受け取ると、それを解析してタスクを生成する。タスクとはコンピュータが処理する仕事の単位であり、タスクを効率的にプロセッサ(CPU)に割り当て、制御する
・プロセッサは、タスク単位で命令をひとつひとつ順番に実行してプログラムを処理している。しかし、割り込みなどが発生するとタスクの実行が中断し、プロセッサが空いてしまう。OSは「マルチプログラミング」によりこの空き時間に別のタスクを実行し、複数のジョブを同時並行で処理している
■ネットワークの基礎知識
・通信プロトコル・・・コンピュータや通信機器の間で通信を行うための取り決めのことであり、単にプロトコルともいう。
・TCP/IP
送信するときは、データはアプリケーション層から下の層へ順次処理され、電気信号になって回線を流れる。受信側へたどり着くと、今度は反対に物理層から上の層へ順次処理される。アプリケーション層での処理が終わってデータになると受信が完了する。
| 階層 | TCP/IP | TCP/IPプロトコル群 |
|---|---|---|
| 第4層 | アプリケーション層 | FTP、HTTP、SMTP、POP3、DNS |
| 第3層 | トランスポート層 | TCP |
| 第2層 | インターネット層 | IP |
| 第1層 | ネットワークインターフェース層 | Ethernet |
| ・LANは企業内など比較的狭い範囲で構築されたローカルなネットワークであるのに対し、WANは建物や敷地をこえてLAN同士を結びつけた広域のネットワークをいう。 | ||
| ・ピアツーピアからクライアント/サーバへ・・・LANに接続されたコンピュータに役割をもたせ、それらを中心に全体をつなぐようになった | ||
| ・処理を要求するコンピュータをクライアント、その要求に応えてサービスを提供するコンピュータをサーバと呼ぶ。サーバには目的や用途に応じて「ファイルサーバ」「プリントサーバ」「データベースサーバ」「WWWサーバ」などがある | ||
| ・Ethernet・・・バス型あるいはスター型を使用するLANの標準的な規格のこと | ||
| ・インターネット・・・LANやWANを世界規模でつなげたコンピュータネットワークのことをいう。「ネットワークのネットワーク」ともいわれる。(インターネットというクラウド(雲)に無数のLANやプロバイダがつながったイメージ) | ||
| ・IPアドレス・・・インターネットの標準プロトコルTCP/IPのネットワークで、ネットワークに接続されているノード(ネットワーク接続されているコンピュータ端末の総称)を識別するためにつけられるもの。32ビットの2進数からなる。 | ||
| ・DNS・・・ノードどうしはIPアドレスを使って通信する相手を特定するが、人間が指示するには不便である。そこで、IPアドレスを人間が記憶・識別しやすいドメイン名に置き換えて使用する方法がとられている。この変換の仕組みのこと。ドメイン名はURLやメールアドレスに使われている。 | ||
| ・WWW(ワールドワイドウェブ)・・・私たちはよくWebページの閲覧や検索を指して「インターネットを利用する」と言うが、このサービスはWWWが実現している。インターネット上には数多くのWWWサーバがあり、Webページを構成するファイル(HTML、CSS、画像など)を保存し、クライアントからの要求にこたえてそれらを送り出している。WWWではHTTPというプロトコルでデータをやりとりしている。クライアントではURLという形式で、Webページが格納されているWWWサーバとWebページのファイル名を指定する(URLはインターネットにおける情報の「住所」にあたる)。URLに書かれた情報はHTTPによって指定したWWWサーバへ送られ、要求を受けたWWWサーバはそのWebページのファイルをHTTPで返す。 | ||
| ・電子メール・・・メーラというソフトウェアを使い、文字や画像などのデータをやりとりするサービスないし送受信するデータそのものを指す。電子メールを送信するときはSMTP、受信するときはPOP3というプロトコルが主に使われる。クライアントから電子メールを受け取って転送したり、届いたメールを保管したりするのは「メールサーバ」が行っている。 |
■データベースの基礎知識
・データベースからデータを取り出すなどの操作は「データベース管理システム(DBMS)が行う
・データモデル・・・現在の主流は関係データモデルと呼ばれるもので、データを表の形に整理し、その表がいくつか集まったものと考える。
・E-Rモデル・・・データモデルの種類に関係なく、個々のデータどうしの間にどのような関係が成り立っているかを表す方法。現実の世界のデータ(実体)とその関係を図に置き換え一般化したもの。
・正規化・・・データベースに必要なデータ項目を集め、その関連性を分析して複数の無駄のない表にすること
・データベース言語・・・データベースを操作するためにはDBMSへ命令を出す。その命令を記述する言語のこと。SQLが該当。
・トランザクション・・・ユーザ側からみたひとまとまりの処理の単位。具体例としては入金と出金を一連の処理で行う必要があり、片方の処理が停止した場合には両方の処理をなかったことにしなければならないようなときに必要な処理。両方の処理が正常に実行された場合は「コミット」と呼ばれる処理をし、途中で中断してしまった場合は「ロールバック」と呼ばれる処理をする。
■情報システムの構築・運用・整備の基本的な流れ
・ウォータフォールモデルの段階・・・「基本計画」→「外部設計」→「内部設計」→「プログラム設計」→「プログラミング」→「テスト」→「運用・保守」の7段階
・手続き型プログラミングとオブジェクト指向型プログラミング
| 方式 | 方法 |
|---|---|
| 手続き型プログラミング | アルゴリズムまたはサブルーチンの手続きをとり、複数のプログラマが別々のサブルーチンを開発し、あとでひとつのプログラムとして完成させる方式 |
| オブジェクト指向型プログラミング | データと手続きを一体化した「オブジェクト」を中心とした方式 |
・テストには「単体テスト」「結合テスト」「システムテスト」「運用テスト」がある
WBT:C言語プログラミングStep1(3日)
■C言語とは
・Dennis Ritchie が 1973 年に UNIX システム用に開発
・拡張子は.c
・C言語の書き方
/* 標準入出力のヘッダ ファイルをインクルード */
# include <stdio.h>
/* メイン関数 */
int main(void)
{
/* "Hello World\n" と表示する。"\n" は改行文字を示す */
printf("Hello World\n");
return 0;
}
・#include の一文でprintf関数はじめ多くの関数が使えるようになる(使用しない場合は入力不要)
・%dは数値や計算結果を入れる「箱」のようなイメージ
(使い方)
# include <stdio.h> /* 標準入出力ライブラリ */
int main(void){
int x; /* int 型の変数 x を宣言 */
int y; /* int 型の変数 y を宣言 */
x = 5; /* x に 5 を代入 */
y = 3; /* y に 3 を代入 */
printf("%d + %d = %d\n", x, y, x + y);
printf("%d - %d = %d\n", x, y, x - y);
printf("%d * %d = %d\n", x, y, x * y);
printf("%d / %d = %d\n", x, y, x / y);
printf("%d %% %d = %d\n", x, y, x % y);
return 0;
}
を実行すると
5 + 3 = 8
5 - 3 = 2
5 * 3 = 15
5 / 3 = 1
5 % 3 = 2
となる。
・while文とfor文
初期化文
while(条件式){
命令文
後処理文
}
for(初期化文 ; 条件式 ; 後処理文){
命令文
}
・関数の書き方
データ型 関数名(引数のリスト){
宣言文
本文
return 式; /* 返り値 */
}
・C言語の構成要素
1.変数の宣言
2.関数の宣言
3.関数の定義
・演習問題
1.ある数値を渡されるとその数値の2乗を求め、その値をreturnする関数func_powを作る
2.main関数において、1から10までの数値の2乗をfunc_pow関数を呼び出して求め、それぞれの値とその合計を表示する
(解)
# include <stdio.h>
/* 関数 func_pow の宣言(プロトタイプ)*/
int func_pow(int a); /* 関数の宣言では引数の名前を省略しても良い */
/* 関数 main */
int main(void)
{
int total = 0; /* 合計用の変数の宣言と初期化 */
int i; /* 繰り返し制御用の変数の宣言 */
int tmp; /* 計算で使用する一時的な変数の宣言 */
for (i = 1; i <= 10; i++) {
tmp = func_pow(i); /* i の2乗の値を求める */
printf("%d の 2 乗は %d です。\n", i, tmp); /* 求めた値を表示する */
total = total + tmp; /* 求めた値を合計用変数に加算する */
}
printf("合計は %d です。\n", total); /* 合計を表示する */
return 0;
}
/* 関数 func_pow
引数で指定された値の2乗を求めて返す。
*/
int func_pow(int a)
{
return a * a;
}
・列挙定数
# include <stdio.h>
/* 列挙型 result を宣言
列挙定数として SUCCESS と FAIL を定義*/
enum result { SUCCESS, FAIL };
/* 関数 do_something の宣言 */
enum result do_something(void);
int main(void)
{
/* do_something 関数を呼び出し、返り値を検査 */
if(do_something() == SUCCESS){
/* 関数 do_something が成功したときの処理 */
}
return 0; /* 正常終了 */
}
/* 月を表す定数 */
enum month { JAN = 1, FEB, MAR, APR, MAY, JUN,
JUL, AUG, SEP, OCT, NOV, DEC };
enum day { YESTERDAY = -1, TODAY = 0, TOMORROW = 1 }
・構造体
(構造体の宣言)
struct 構造体名 { 変数の宣言文 }
・配列
長さ 5 の char 型配列 string を作るには、次のようにします。
char string[5];
※配列の先頭の要素は、配列名 [0] 、 つまり長さ 5 であれば 0 から 4 が利用できる
※配列として利用できるデータ型はint 型でも構造体でも、どんなデータ型でも配列にできる
・char型の配列は次のように文字列形式でも表される
char string[5] = {'a', 'b', 'c', 'd', '\0' };
char string[5] = "abcd";
・配列は宣言時に初期化する場合に限り長さを省略できる(以下の配列は長さがすべて3)
char string1[] = {'a', 'b', '\0'};
char string2[] = "ab";
int intarray[] = {1, 3, 5};
struct point {
int x, y;
} points[] = { { 1, 3 }, { 2, 4 }, { 3, 6 } };
・演習問題
以下の5人の身長と体重のデータを利用して、それぞれの標準体重と肥満率を表示し、最後に平均の身長、体重、標準体重、肥満率を表示するプログラムを書け。
データ
| 名前 | 身長(cm) | 体重(kg) |
|---|---|---|
| yasuo | 170.5 | 70.5 |
| hideaki | 176.5 | 65.8 |
| nobu | 166.5 | 58.2 |
| yuichi | 168.0 | 65.4 |
| nori | 152.7 | 68.6 |
(解)
# include <stdio.h>
/* 人ごとの各データを保持する構造体 record の宣言 */
struct record {
char name[10]; /* 名前を保持する変数 name */
float height; /* 身長を保持する変数 height */
float weight; /* 体重を保持する変数 weight */
};
/* 各データを、長さ 5 の record 構造体の配列に代入 */
struct record records[5] = {
{ "yasuo", 170.5, 70.5 },
{ "hideaki", 176.5, 65.8 },
{ "nobu", 166.5, 58.2 },
{ "yuichi", 168.0, 65.4 },
{ "nori", 152.7, 68.6 }
};
/* 標準体重を返す関数 std_weight の宣言 */
float std_weight(struct record r);
/* 肥満率を返す関数 per_fatness の宣言 */
float per_fatness(struct record r);
int main(void)
{
float total_h = 0.0; /* 身長合計 */
float total_w = 0.0; /* 体重合計 */
float total_sw = 0.0; /* 標準体重合計 */
float total_pf = 0.0; /* 肥満率合計 */
float sw, pf; /* 標準体重、肥満率計算用 */
int i; /* 繰り返し制御用 */
/* 見出しの表示 */
printf("%-10s%10s%10s\n", "名前", "標準体重", "肥満率");
/* 構造体配列から個人データの表示と合計の算出 */
for (i = 0; i < 5; i++) {
sw = std_weight(records[i]); /* 標準体重算出 */
pf = per_fatness(records[i]); /* 肥満率算出 */
/* 個人データの表示 */
printf("%-10s%10.2f%10.2f\n", records[i].name, sw, pf);
/* 合計用変数への足し込み */
total_h = total_h + records[i].height; /* 身長 */
total_w = total_w + records[i].weight; /* 体重 */
total_sw = total_sw + sw; /* 標準体重*/
total_pf = total_pf + pf; /* 肥満率 */
}
/* 平均値の見出しとデータの表示 */
printf("\n");
printf("%8s%10s%14s%12s\n", "平均身長", "平均体重",
"平均標準体重", "平均肥満率");
printf("%8.2f%10.2f%14.2f%12.2f\n", total_h / 5.0, total_w / 5.0,
total_sw / 5.0, total_pf / 5.0);
return 0;
}
/*
標準体重を返す関数 std_weight の定義
record構造体を引数としてとる
*/
float std_weight(struct record r){
/* 標準体重 = (身長 - 100) * 0.9 */
return (r.height - 100.0) * 0.9;
}
/*
肥満率を返す関数 per_fatness の定義
record 構造体を引数としてとる
*/
float per_fatness(struct record r){
/* 標準体重を求める */
float stdweight = std_weight(r);
/* 肥満度 = (体重 - 標準体重) * 100.0 / 標準体重 */
return (r.weight - stdweight) * 100.0 / stdweight;
}
・文字定数・・・'a'と表す。ASCII文字を表す整数を扱うときに使用
・文字列定数・・・"hello"と表す。たとえば"Hi!\n" char型の配列c「char c[5] = {'H', 'i', '!', '\n', '\0'};」と同様のふるまいをする
・文字列・・・「終端文字までの文字の配列」のことで、文字列定数やchar型の配列によって表現する。文字列定数の中には、配列要素の途中でも終端文字を含むことができる。したがって、以下のように文字列定数と文字列が一致するとは限らない。
| 文字列定数 | 文字列 |
|---|---|
| "Hi,\0\0 Joe!\n" | "Hi," |
| "I\0 am Joe." | "I" |
| "you\n" | "you\n" |
# include <stdio.h>
int main(void){
/* 配列 c に文字列定数を代入 */
char c[] = "Hi!\n";
int i;
/* 0 から 4 まで繰り返し */
for(i = 0; i < 5; i++){
/* 配列の要素の位置と、要素を整数で表示 */
printf("c[%d] => %d\n", i, c[i]);
}
/* c を文字列として表示 */
printf("%s", c);
return 0;
}
実行結果
C:\Sample>a
c[0] => 72
c[1] => 105
c[2] => 33
c[3] => 10
c[4] => 0
Hi!
C:\Sample>
WBT:C言語プログラミングStep2(3日)
・
・コマンドプロンプト(Windows環境)とターミナル(UNIX環境)
・ポインタと配列の類似性
例.*strとstr[0]は同じものを指す({'a','b','c','¥0'}でいうa)
参考)*str[0]とするとポインタポインタ型の先頭の値にあたる
・while文+scanf、EOFについて
例.while(scanf("%s%d", name, &height) != EOF{・・・}
・連結リスト(線形リスト)
# include <stdio.h>
/* 初めに構造体を宣言 */
struct station{
struct station *next;
char name[60];
int rapid;
};
int main(void){
struct machida = { NULL, "machida", 1 };
struct kobuchi = { &machida, "kobuchi", 0 };
struct fuchinobe = { &kobuchi, "fuchinobe", 0 };
struct yabe = { &fuchinobe, "yabe", 0 };
for (p = head; p !=NULL; p= p->next) {
printf("%s", p->name);
}
return 0;
}
※for(p=head; p !=NULL; p=p->next){・・・ は連結リスト(線形リスト)の常套句
※「p->name」は「pが指す先のnameというメンバ」の意
・「void *」は「どのような型にするかは後で決めてください。とりあえずポインタを返しますよ。」の意
開発プロセス入門(1日、11/17)
ソフトウェア開発のプロセスについて座学を受けました。
ただ、この後に行うプロジェクト演習での実践によって初めて理解ができたかなと思います。
・ソフトウェア開発プロセスとは
要求分析 → 要件定義 → 基本設計 → 詳細設計 → 実装・単体テスト →結合・システムテスト
・各工程の成果物
要求分析:要求定義書
要件定義:要件定義書
基本設計:基本設計書
詳細設計:詳細設計書(ストラクチャチャート、フローチャート等)
実装・単体テスト:①ソースコード ②テストコード ③テスト結果 ④品質メトリクス
結合・システムテスト:テストケース、テスト結果
・開発プロセスモデル
自社ではウォーターフォールモデルが主流のもよう
ネットワーク技術入門(1日、11/19)
個人的にいちばんおもしろい内容でした。
コンピュータサイエンス基礎で学ぶことを一歩踏み込んだ内容を学びました。
Wiresharkというツールを用いての通信監視についても少し行いました。
・OSI 7階層参照モデルとTCP/IPモデル
・カプセル化
規定に従ったデータを作るために、第7層から第1層の順で各層で送り主や宛先などの情報を梱包していくこと。逆に、
送り先のコンピュータは送られたデータを開府していかなかればならない。この開封工程を非カプセル化という。
・パケットという考え方
従来の「回線交換方式」では、通信経路のどこかが途中で切れてしまうと特定の通信が完全に切れてしまう。
これに対し、パケットの考え方により通信の両端で途中のネットワークが行っていることを把握しなくてよくなった。
パケットとは「小包」の意。
・無線通信
-電波を介して行われる
-自由空間での速度は光と同じ(電波の速度は周波数に依存しない)
-電界と磁界が連鎖反応を起こし、それが続いて受け側に到達する
・インターネットでの通信の仕組み
-通信は、
①データ・・・HTML+HTTP
②道・・・・・TCP/IP
③相手・・・・URL
④共通認識・・HTTP+HTML
の4つに整理して考えることができる
-https://www.google.co.jp/にアクセスする場合
①ブラウザにURLを入力
②ブラウザはDNSサーバーと通信し、www.google.co.jpに割り当てられたIPアドレスを要求
③DNSサーバーは対応するIPアドレス「153.142.218.28」をブラウザに返す
④ブラウザは確認したIPアドレス「153.142.218.28」のサーバーにアクセスし、HTMLファイルを要求
⑤ブラウザはHTMLファイルを読み込んで表示する
・Webセキュリティに関する基礎知識
-プロトコル
・サービスを提供するための約束事
・HTTP(Webアクセス)、FTP(ファイル転送)、POP(メール受信)、SMTP(メール送信)
-ポートと脆弱性
・ポートとはインターネットで特定のサービスを通信させるための識別番号
-例.HTTP→ポート80番、SMTP→ポート25番、POP3→ポート110番
・ポートは開けたり閉じたり制御できる ←不要なポートは閉じる
・ポートが開いていると・・・
-提供サービスがわかる
-開いているポートを悪用して侵入・攻撃
-脆弱性があるとさまざまな被害を受ける(ウイルス感染、操作権限奪取、DoS攻撃を仕掛けるプログラム埋め込み)
・対策
-使わないポートは閉じる
-パッチを適用し脆弱性をふさぐ
-ファイアウォール
・インターネットと内部ネットワーク(LAN)の境界上でアクセス制御を行う装置
・主な機能
-外部との出入り口を絞る
-内部ネットワーク(LAN)の構造を外部に見せない
-外部からの不正アクセスを排除
-必要なアクセスのみ通過させる
・万全ではなくDoS攻撃やウイルスは防げないことも
-パケットフィルタリング
パケット情報に基づいて通過させるパケット、させないパケットを選別
-アプリケーションゲートウェイ
アプリケーションプロトコルごと(HTTP,FTP,POP,SMTPなど)に許可/禁止を制御
-暗号技術
・共通鍵暗号方式、公開鍵暗号方式、両者の組み合わせ(ハイブリッド暗号方式)
・WWWでの暗号化(SSL)・・・データを暗号化して送受信(HTTPプロトコルではデータは暗号化されずそのまま流れる
・暗号化メール・・・PGP、S/MIME
・デジタル署名、認証局
・Webサイトへの攻撃は3つに大別される
(逆にいえばこの3つの対策を施せば脅威を遠ざけられる)
①脆弱性を突いた攻撃
・最も気をつけたい攻撃
・プログラムの欠陥をついてくる
・常にOSやソフトウェアの更新情報を収集し、迅速にパッチをアップデートする必要がある
・例として「ポケモン」のレベルを一気に100にする裏ワザ(バグ)など
②認証突破
・最も狙われやすいのは「入力フォーム」
・古くからある攻撃手法
・OSコマンドインジェクションやSQLインジェクションなど、プログラムに影響を与えるパラメータにOSへの命令文をフォームから送信
・サーバー自体を乗っ取ったり、DBを操作するSQL文を紛れ込ませ、遠隔操作で情報を抜き取ろうとする
③サービス妨害
・DDoS攻撃・・・サーバーに過剰な負荷を与え、機能停止へ追い込む
・DDoS攻撃の平均サイズは約1Gbpsであり、攻撃の80%は1Gbps未満
・TCP/IP
-TCP/IPはトランスポート層とネットワーク層のプロトコルで構成される
-トランスポート層
・TCP・・・コネクション指向のプロトコル。通信の信頼性に強み
・UDP・・・コネクションレス指向のプロトコル。単純な仕組みのため高速
-ネットワーク層
・IP・・・
-ネットワーク上のノード間をつなぐプロトコル
-異なるネットワーク間でのデータのルーティングや転送を可能にする
-TCPやUDPはIPの機能を使ってEnd to End(ネットワーク上に存在する2つのノード間)での通信を実現している
・ARP・・・IPアドレスから物理層のMACアドレスを取得するためのプロトコル
・ICMP・・・
-IP接続をテストしたり、通信経路でのエラー報告などを行うためのプロトコル
-pingコマンドはこのICMPを使って実装されている
・IPアドレス
-ネットワーク上の各ノードはIPアドレスと呼ばれる数値をネットワーク上の各ノードに割り当て、通信の制御を行う
-サブネット化・・・上位16bit、24bitなどでグループ処理を行うことで効率よくアドレスを管理
-ネットワーク・アドレスとホスト・アドレス
・ネットワーク・アドレス・・・各ネットワークを区別するための識別番号(例.上位24bit)
・ホスト・アドレス・・・そのネットワーク内における各ホストを区別するための識別番号(例.下位8it)
-IPパケットのルーティング
・TCP/IPでは各ネットワーク間にはルータが配置され、すべてのネットワークがいずれかのルータを介して相互に接続される
・同一ネットワーク上のホスト間で通信する場合はルータは何もしない
・異なるネットワーク上に存在する2つのホストが通信を行う場合には、ルータがパケットを中継して目的のネットワークまでパケットを届ける
・隣同士のネットワークでなければ(2つ以上先のネットワークと通信したければ)、ルータによる中継が何段も行われながらパケットが順次転送されていく
・IPパケットルータ
正確にはIPアドレス全体を見るのではなく、ネットワーク・アドレス部に基づいてどこのネットワークへパケットを中継するかを判断している
・ARP(Address Resolution Protocol、アドレス解決)
-TCP/IPが動作(正確にはIPパケットを送受信)するためには不可欠の補助プロトコル
-MACアドレスとIPアドレスを相互に変換するための機能を有する
-ARPプロトコルの役割は「IPアドレスとMACアドレスの対応表を作成」すること
-ARPコマンドによるARPテーブルの表示・・・「arp -a」
構造化分析設計入門(1日、11/20)
本講義では、開発プロセスの「要求分析」および「要件定義」に当たる「構造化分析」と、「基本設計」および「詳細設計」に当たる「構造化設計」について学んだ。
講義では「アラーム機能付き時計」を題材に「DFD」と「機能階層図」の作成を、またストラクチャチャートや凝集度・結合度についても学んだ。
本講義で学んだことは後に行われたチーム開発プロジェクト演習で実践を通じて理解を深めることができたと思う。
・モデリング・・・対象のシステムを単純化してわかりやすく可視化すること
・分析モデリングと設計モデリング
-分析モデリング
・ソフトウェアシステムとして何を実現すべきか(What)
・コンテキストダイアグラム、DFD
-設計モデリング
・どのように目的のソフトウェアシステムを実現するか(How)
・機能階層図、ストラクチャチャート、凝集度・結合度
・機能要件と非機能要件
-機能要件
・ユーザーがソフトウェアにどのような機能を必要としているか
例.スマホとWi-Fi接続できること、オートフォーカス機能、など
-非機能要件
・ソフトウェアが提供する機能が達成すべき性能や制限
例.第三者が不正改造できないこと、電源OFFしても撮影画像が消失しないこと、など
・DFDの表記方法・・・データフロー(→)、プロセス(○)、データストア(=)、ターミネータ(□)の4つ
・DFDとコンテキストダイアグラムの関係
-DFDの最上層を特にコンテキストダイアグラムと呼ぶ
・ストラクチャチャート
-モジュールの呼び出し関係の可視化およびモジュール間の情報(=データ)の受け渡しの明確化
・凝集度と結合尾
-凝集度は高いほどよく、逆に結合度は低いほどよい
-凝集度・結合度を良くすると・・・
・修正などによる他モジュールへの影響が少なくなる
・対象モジュールを理解する時、他モジュールも知る必要性が減る
・構造株席設計技法の特徴
①データフローに着目して機能を洗い出し、ソフトウェアの構造を決定
②段階的に詳細化するトップダウンアプローチ
③複雑な機能を単純な機能モジュール群に分割
製品セキュリティ技術入門(1日、11/18)
本講義の位置づけは
・セキュリティに関係する法律、業界標準、ガイドライン等があることを知ること
・セキュア開発プロセスについて理解すること
であった。
前半の法規制では製品セキュリティに脆弱性があったために起きた事例を複数説明を受けた(お掃除ロボットを遠隔操作&盗撮ほか)。
要点は以下。
・セキュリティに関連する組織・団体
-アメリカ国立標準技術研究所(NIST)←米総務省配下の技術部門
-内閣サイバーセキュリティセンター(NISC)←内閣官房に設置された組織
-独立行政法人情報処理推進機構(IPA)←経済産業省所管
-困ったときは「NIST」と「IPA」に
(以下はセキュリティの団体ではないが)
-IETF・・・インターネット技術の標準化を推進する任意団体
-OWASP・・・ウェブアプリケーションをとりまく課題の解決を目的とするオープンコミュニティ
・不正アクセス禁止法
-禁止される行為の例
・不正アクセス罪(本来制限されている機能を利用可能な状態にする、など)
・不正取得罪
・不正助長罪
・不正保管罪
・不正入力要求罪(フィッシングサイト構築や電子メール送信によるフィッシング行為など)
・電子署名法
・個人情報保護法
-個人情報はできるだけ扱わない、扱う場合は要注意
・政府機関の情報セキュリティ対策のための統一基準
-NISC制定
-要件を満たしていないと利用してもらえない
後半のセキュア開発についての要点は以下。
・Microsoftのセキュア開発プロセスについて
-反復可能なプロセスであること
-セキュリティの観点で安全なソフトウェアはコストよりも重要
→セキュア開発プロセス適用を義務付け
→セキュリティ品質基準の策定
-セキュリティの専門チームが社内に存在することが前提
→教育の充実化
→セキュリティチームの設立
→コードレビューは欠かせない
アルゴリズム入門(3日、11/25〜27)
Python言語を用いて代表的なアルゴリズムについて学んだ。
統合環境としてAnaconda
をインストールし、JupiterNotebookによる演習問題をひたすら行った。
二分探索法とかマージソートとか、再帰関数とか、、、
C言語実装演習(9日、11/30〜12/10)
各々が用意された演習問題(具体的には以下にて記載)を解きつつ、Redmine(チケット管理システム)による進捗管理や講師、受講生にコードレビューを依頼する方法などを経験した。
また、Subversion(バージョン管理システム)、Eclipse(エディタ兼Subversion連携もできる統合開発環境)、の使い方や機能について学んだ。
講師によるコードレビューでは、
・見落としていたエラーケースやバグ
・モジュール化、関数化への意識づけ
などの指摘を受け、実践的な理解を深めることができた。
またこのタイミングでフローチャートの作成やDoxygenによる詳細設計文書の作成についても教わった。
開発プロジェクト演習1(15日)12/11〜1/8
本研修の目玉。
本プロジェクトでは一次開発と二次開発に分かれていたが、目指す成果物は以下のとおり。
WCASLⅡのアセンブラとシミュレータをC言語で実装する####
というもの。
これを5人のチームで開発した。
非常に日程がタイトだったこと、かつお題が与えられた当初はメンバー皆ソフトウェア開発プロセスのイメージができていなかっただけでなく、成果物のイメージすらついていない有様というところからのスタートだった。
もちろん「アセンブリ言語?なにそれ」レベルからのスタート。
とりあえず以下の書籍を配られ、各々で学習するスタイル。
僕はここのところの理解が人より遅かったことがのちに苦労することになる。
この期間中は並行して講師の方より
・GoogleTest
・静的テストツール
-Sourceモニター(LOC、サイクロマティック計測)※サイクロマティック目標値は29以下
-Gcovr(C0カバレッジ、C1カバレッジ計測)
・テスト技法の講義
・アセンブリ言語の演習
・メモリリークについての講義
・Doxygen(詳細設計のためのストラクチャチャートを作成可能)
・コマンドプロンプトツール
-コマンドプロンプト上の任意の配置に任意の文字色・背景色を設定可能
-シミュレータ表示の見栄えをよくするために各チーム工夫して使用する研修方針
についてのレクチャーを受けた。
アセンブラ開発→3人
シミュレータ開発→2人(僕はこちら)
に分かれて各チーム開発を進めたが、
・要件定義書
・基本設計書
については全員で分担して作成を進めていった。
ただ、のちに開発を進めるうえで要件定義書、基本設計書の修正
開発プロジェクト演習2(17日、1/12〜2/3)
一次開発で開発し切れなかった機能の実装がこのフェーズのメイン。
「一次開発でなんとか動くものが作れたので二次開発ではもう少し余裕ができるだろう」
という甘い考えは計画を立てているうちにすぐに絶望へと変わった。
一次開発ではスコープに入れなかった
・マクロ命令(IN,OUT)
・サブルーチンコール命令
・スーパーバイザーコール命令
・1命令ごとのレジスタおよびメモリ内の演算結果の出力
・膨大な量の単体テスト、結合テスト
の実装を残していたからだ。
また、本二次開発より緊急事態宣言発令により、週3日は在宅で作業を進めることになったが、実務に向けていい経験をさせてもらえたと思う。
WBT(HTML、CSS、JavaScript)(10日、2/8〜2/22)
詳しくはこちらの限定記事(https://qiita.com/42urawa/private/9c02c618e17215a945a5)に書きましたのでもしご興味あれば。
JavaScriptの途中から現れるクラス、Promise、非同期通信のあたりから一気に難しくなってくる。
個人的には関数とDOMについて理解できたことで、ネット記事や書籍(たとえばリーダブルコードや安全なWebアプリケーションの作り方など)を読みやすくなったことがとても大きいと感じた。
あとReactやVue.jsも少しだけ概要を学習できた。
画像処理@C言語(4日、2/22〜2/26)
研修最後は画像処理について学ぶ。
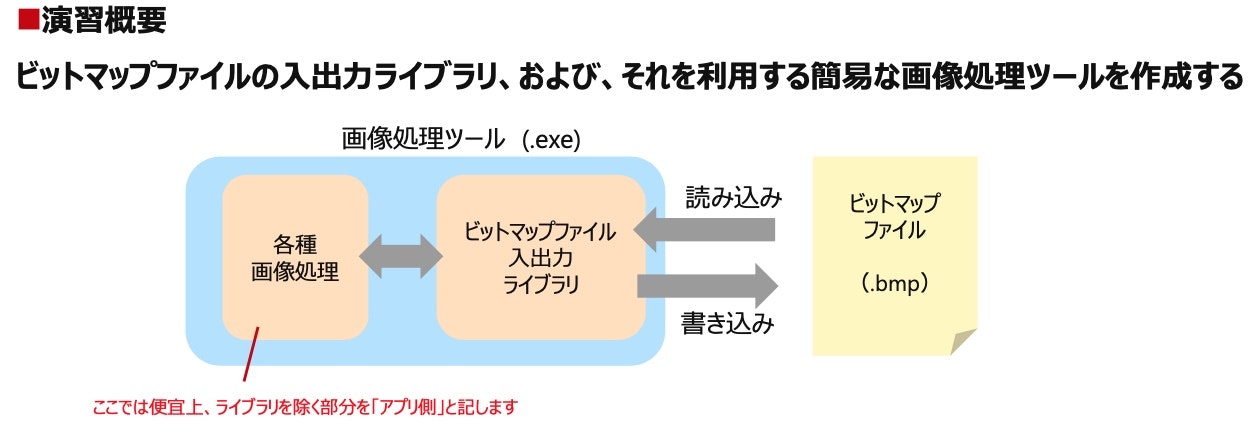
学んだ概要は上のような感じで、
・ビットマップファイルの構造の理解(バイナリ形式ファイルの読み込みと書き出し)
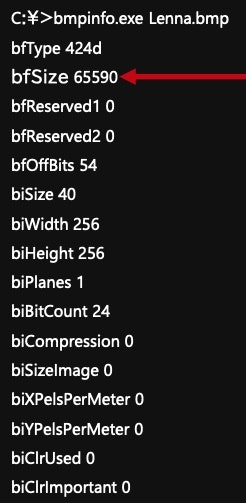
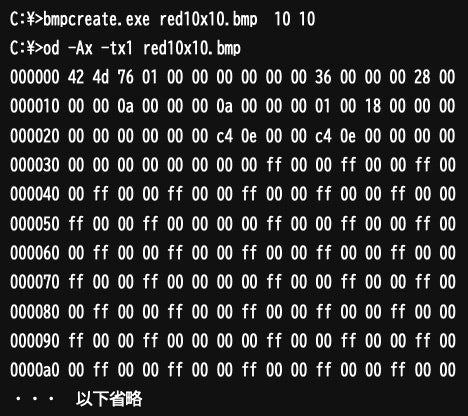
・画像の切り出しと結合(縦と横)

・実際に画像を処理
(ネガポジ反転、2枚の画像の合成、エッジ強調などなど)