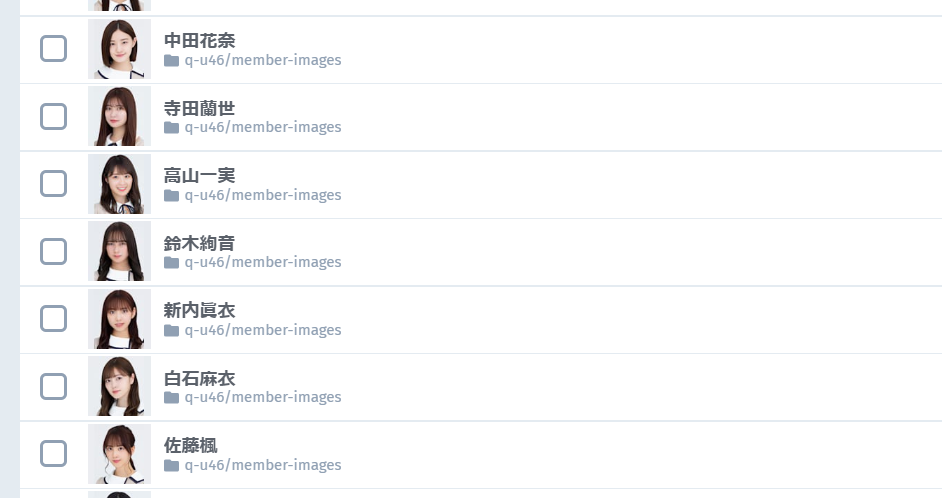
目標
このように、メンバー名.jpgの名前を付けて画像ファイル(画像のパス)を保存すること。
※今回は保存先をcloudinaryにしています。実行する際は何かしらのストレージや、ローカルに保存先を変更して下さい。
最終的なコード
それぞれの公式HPのhtmlが異なっていたので、微妙にコードが異なります。
乃木坂
from bs4 import BeautifulSoup
import urllib
import cloudinary
import cloudinary.uploader
import os
cloudinary.config(
cloud_name = os.environ.get("cloud_name"),
api_key = os.environ.get("api_key"),
api_secret = os.environ.get("api_secret")
)
def get_mem_list():
url = "http://www.nogizaka46.com/member/"
headers = {
"User-Agent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:47.0) Gecko/20100101 Firefox/47.0",
}
request = urllib.request.Request(url, headers=headers)
html = urllib.request.urlopen(request)
soup = BeautifulSoup(html, 'html.parser')
li = soup.select('#memberlist div[class="clearfix"] a')
li = [url + str(l.attrs['href'])[2:] for l in li]
return li
def get_img(url):
headers = {
"User-Agent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:47.0) Gecko/20100101 Firefox/47.0",
}
request = urllib.request.Request(url=url, headers=headers)
html = urllib.request.urlopen(request)
soup = BeautifulSoup(html, 'html.parser')
img = soup.select('#profile img')[0].attrs['src']
name = str(soup.select('#profile div[class="txt"] h2')[0].contents[1]).replace(' ', '')
res = cloudinary.uploader.upload(file=img, public_id="q-u46/member-images/"+name)
return 'finished {} !!'.format(name)
def main():
list_ = get_mem_list()
for url in list_:
print(get_img(url), end=' | ')
if __name__ == "__main__":
main()
欅坂
from bs4 import BeautifulSoup
import urllib
import cloudinary
import cloudinary.uploader
import os
cloudinary.config(
cloud_name = os.environ.get("cloud_name"),
api_key = os.environ.get("api_key"),
api_secret = os.environ.get("api_secret")
)
def get_mem_list():
url = "https://www.keyakizaka46.com/s/k46o/search/artist?ima=0000"
base = "https://www.keyakizaka46.com"
headers = {
"User-Agent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:47.0) Gecko/20100101 Firefox/47.0",
}
request = urllib.request.Request(url, headers=headers)
html = urllib.request.urlopen(request)
soup = BeautifulSoup(html, 'html.parser')
li = soup.select('div[class="sorted sort-default current"] li a')
li = list(set([base + str(l.attrs['href']) for l in li]))
return li
def get_img(url):
headers = {
"User-Agent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:47.0) Gecko/20100101 Firefox/47.0",
}
request = urllib.request.Request(url=url, headers=headers)
html = urllib.request.urlopen(request)
soup = BeautifulSoup(html, 'html.parser')
img = soup.select('div[class="box-profile_img"] img')[0].attrs['src']
name = str(soup.select('div[class="box-profile_text"] p[class="name"]')[0].text).replace(' ', '')
res = cloudinary.uploader.upload(file=img, public_id='q-u46/member-images/'+''.join(name.splitlines()))
return 'finished {} !!'.format(name)
def main():
list_ = get_mem_list()
for url in list_:
print(get_img(url), end=' | ')
if __name__ == "__main__":
main()
日向坂
from bs4 import BeautifulSoup
import urllib
import cloudinary
import cloudinary.uploader
import os
cloudinary.config(
cloud_name = os.environ.get("cloud_name"),
api_key = os.environ.get("api_key"),
api_secret = os.environ.get("api_secret")
)
def get_mem_list():
url = "https://www.hinatazaka46.com/s/official/search/artist?ima=0000"
base = "https://www.hinatazaka46.com"
headers = {
"User-Agent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:47.0) Gecko/20100101 Firefox/47.0",
}
request = urllib.request.Request(url, headers=headers)
html = urllib.request.urlopen(request)
soup = BeautifulSoup(html, 'html.parser')
li = soup.select('ul[class="p-member__list"] li[class="p-member__item"] a')
li = list(set([base + str(l.attrs['href']) for l in li]))
return li
def get_img(url):
headers = {
"User-Agent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:47.0) Gecko/20100101 Firefox/47.0",
}
request = urllib.request.Request(url=url, headers=headers)
html = urllib.request.urlopen(request)
soup = BeautifulSoup(html, 'html.parser')
img = soup.select('div[class="c-member__thumb c-member__thumb__large"] img')[0].attrs['src']
name = str(soup.select('div[class="p-member__info"] div[class="p-member__info__head"] div[class="c-member__name--info"]')[0].text).replace(' ', '')
#print(img)
res = cloudinary.uploader.upload(file=img, public_id='q-u46/member-images/'+''.join(name.splitlines()))
return 'finished {} !!'.format(name)
def main():
list_ = get_mem_list()
for url in list_:
print(get_img(url), end=' | ')
if __name__ == "__main__":
main()
コードの説明
乃木坂のコードをメインに説明します。
準備
☆付きは、スクレピングだけを行う際に必要なものです。
それ以外は、ストレージに保存するためのものなので無視してください。
from bs4 import BeautifulSoup #☆
import urllib #☆
import cloudinary
import cloudinary.uploader
import os
cloudinary.config(
cloud_name = os.environ.get("cloud_name"),
api_key = os.environ.get("api_key"),
api_secret = os.environ.get("api_secret")
)
メンバー詳細ページへのリンクをリストに入れる
メンバー紹介Topから、詳細ページへのリンクを全員分取得します。
まずはメンバー紹介Topのhtmlを眺めて見ます。
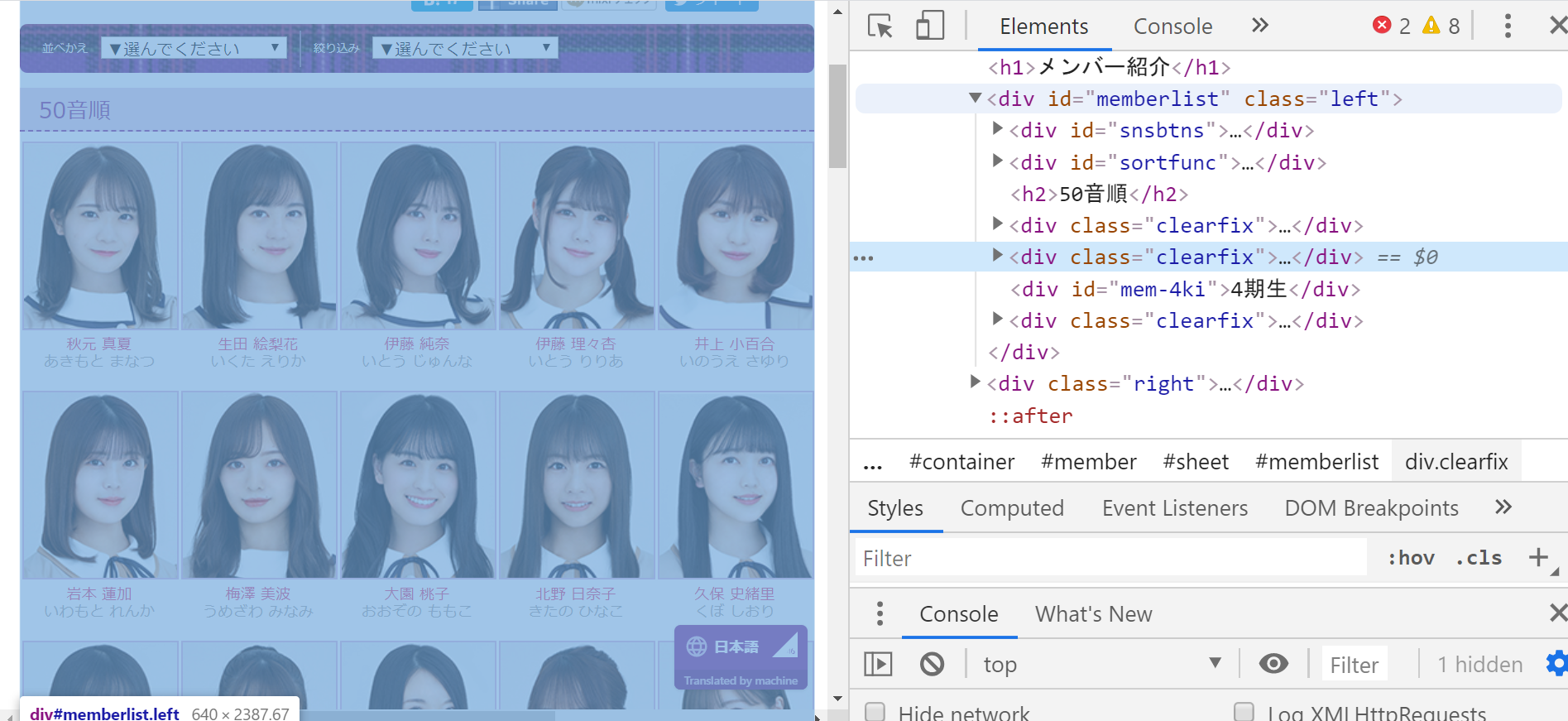
<div id="memberlist" class="left">タグの子要素に目的の画像リンクが入ってそうなことがわかります。
そして子要素の<div class="clearfix">タグが並列して3つあります。
1つ目は、4期生以外のメンバーが全員いるブロックで、2つ目は空で、3つ目は4期生のブロックでした。
よって、#memberlist div[class="clearfix"]で絞ります。
次に、<div class="clearfix">の子要素を覗いてみます。
下のように<div class="unit">タグがメンバーごとに存在し、その中にaタグに相対パスが書いてあります。
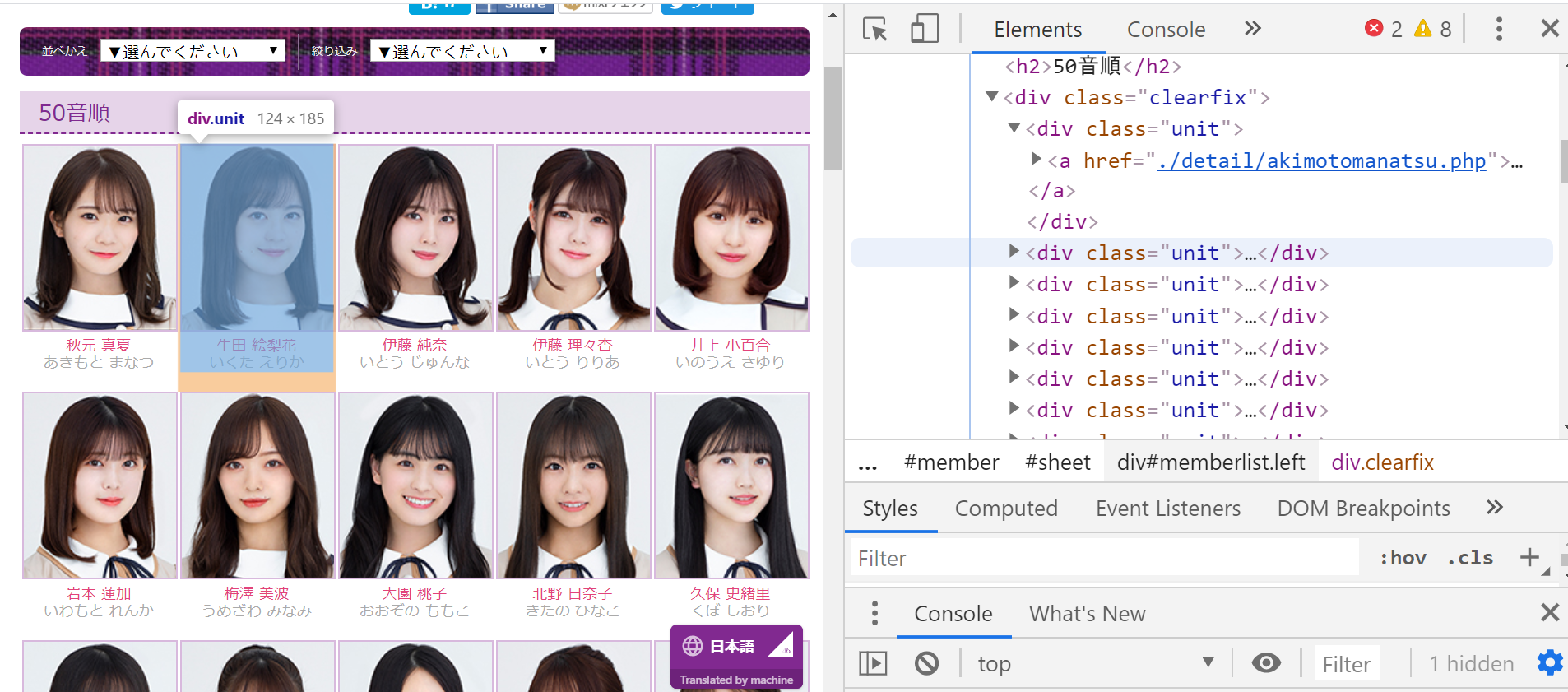
よって #memberlist div[class="clearfix"] aでaタグがメンバー分取得できそうです。
def get_mem_list():
url = "http://www.nogizaka46.com/member/"
# headersで以下のように指定しなければエラーが出たので、付けておきます。
headers = {
"User-Agent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:47.0) Gecko/20100101 Firefox/47.0",
}
request = urllib.request.Request(url, headers=headers)
html = urllib.request.urlopen(request)
soup = BeautifulSoup(html, 'html.parser')
# 条件に合致する要素のリストを得る。
li = soup.select('#memberlist div[class="clearfix"] a')
# 相対パスの最初の'./'を調整, .attrsでタグ内の属性を取得できる。
li = [url + str(l.attrs['href'])[2:] for l in li]
return li
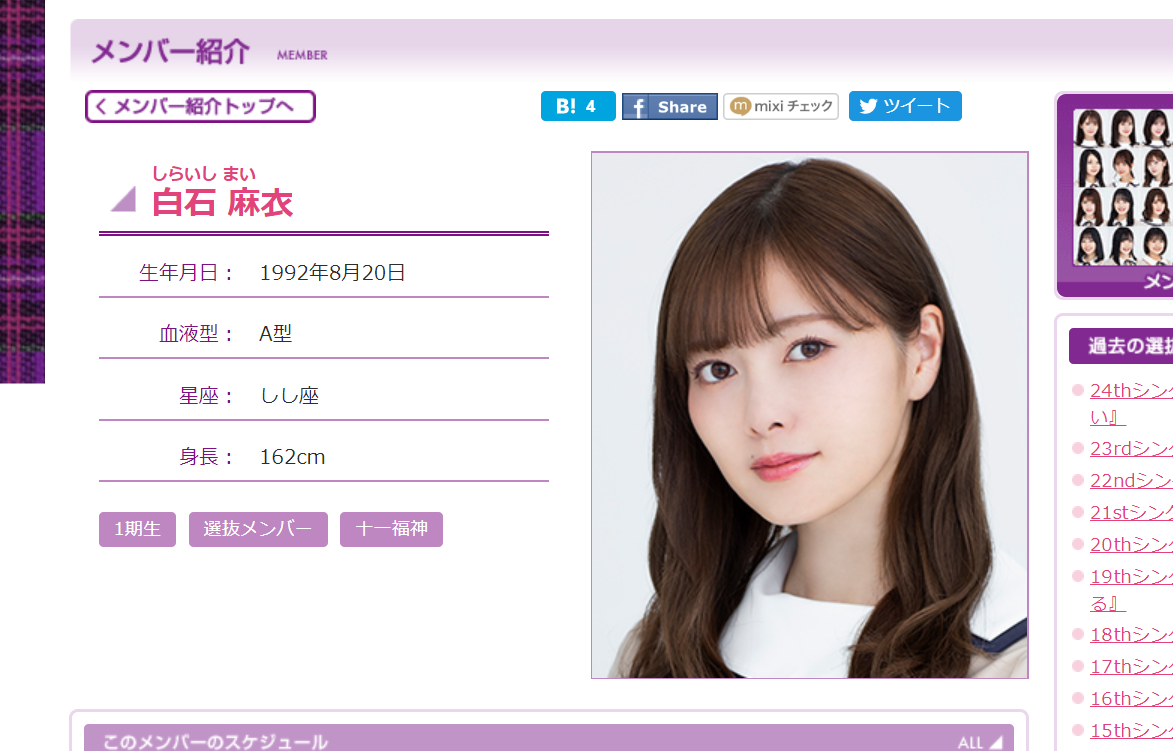
画像と名前を取得
画像
<div id="profile">タグ内の img タグで取得できそうです。
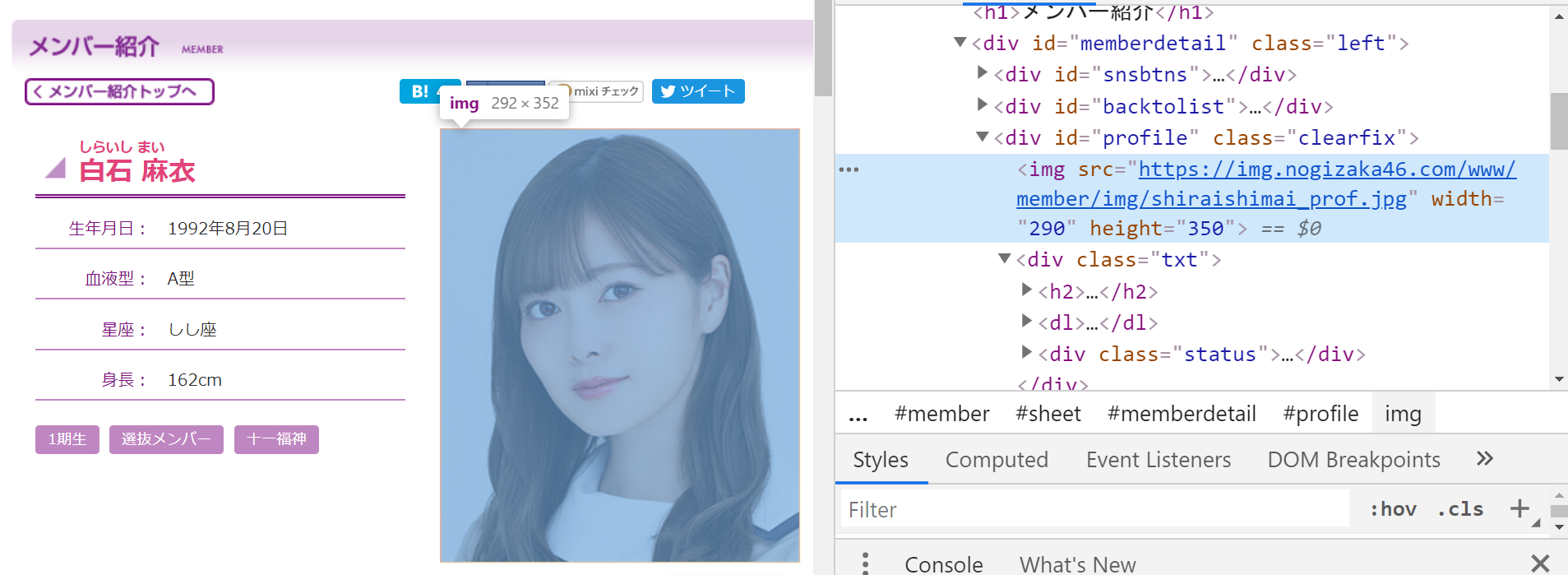
img = soup.select('#profile img')[0].attrs['src']
こんな感じになりました。
soup.selectで返ってくるのはリスト型なので[0]で取り出しています。
名前
<div id="profile">タグ内の <div class="txt"> <h2>の要素であることがわかります。
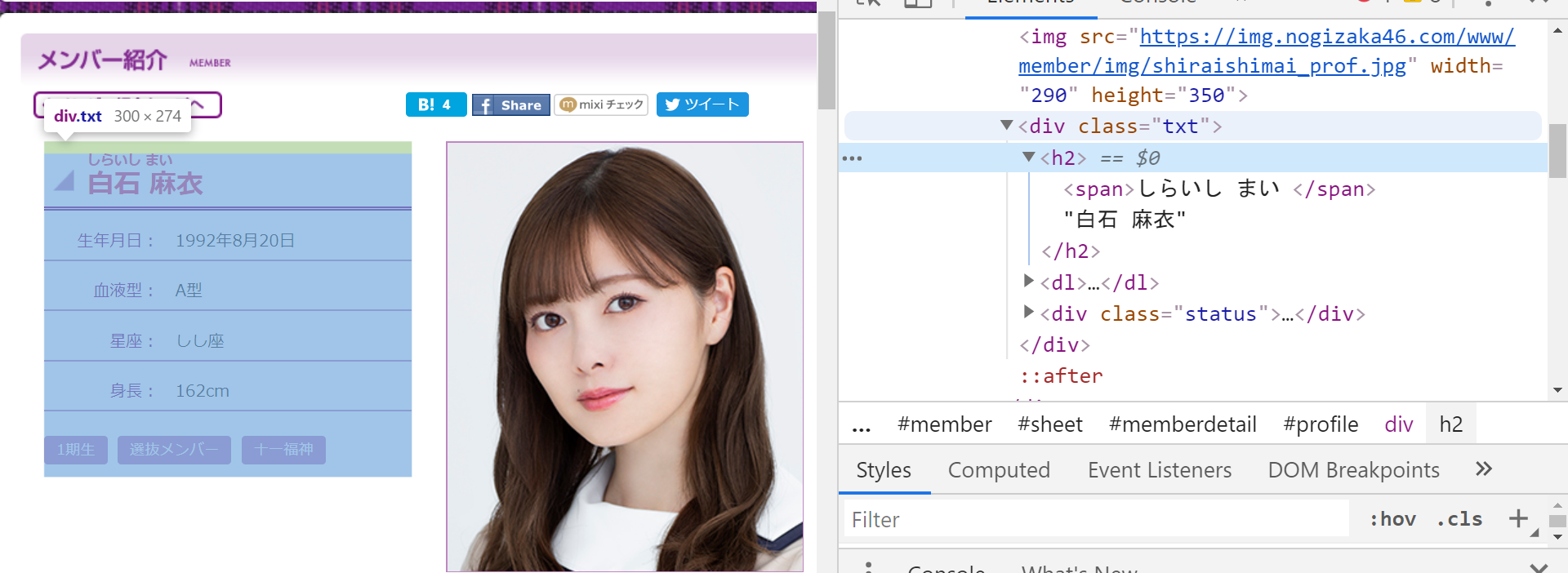
今回の目的は漢字表示の名前の取得なので頑張ってしらいし まいを無視したいです。
そこでh2タグ.contents[1]のようにします。
[<span>しらいし まい</span>, "白石 麻衣"]のようなリストが得られるので、[1]を指定し、漢字表示のものだけを取得します。
姓名間の空白も除きたいので、replaceで除きます。
# 引数はメンバー詳細ページ
def get_img(url):
headers = {
"User-Agent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:47.0) Gecko/20100101 Firefox/47.0",
}
request = urllib.request.Request(url=url, headers=headers)
html = urllib.request.urlopen(request)
soup = BeautifulSoup(html, 'html.parser')
img = soup.select('#profile img')[0].attrs['src']
name = str(soup.select('#profile div[class="txt"] h2')[0].contents[1]).replace(' ', '')
# 以下は保存先によって変わります。
res = cloudinary.uploader.upload(file=img, public_id="q-u46/member-images/"+name)
return 'finished {} !!'.format(name)
メインの処理
def main():
# メンバー詳細ページへのリンクをリストに入れる
list_ = get_mem_list()
# for文で画像取得関数をループ処理
for url in list_:
print(get_img(url), end=' | ')
if __name__ == "__main__":
main()
欅坂と日向坂
セレクタは少し異なりますが、基本のやり方は乃木坂と同じです。
名前取得でなぜか、改行まで取得してしまい、ファイル名を付ける際にエラーがでてしまいました。
なので、''.join(name.splitlines())で改行を無視しました。(リストにして、joinという汚いやり方ですが許してくださいmm)
おわりに
スクレイピングはとても便利なのでバシバシ使っていきましょう!
※ 今回はメンバー分のリクエストしかしないので、time.sleepを省きました。
大量にリクエストを送るときは、しっかりtime.sleepしましょう。