本エントリは、ulgeek Advent calendarの22日目です。
はじめに
AWSではS3をデータレイクとして位置づけ、S3上のデータに直接アクセスできるインターフェースを用意しています。現在、Tokyoリージョンでも利用できる S3 のフロントサイドに Athena と Redshift Spectrumがあります。これらはユースケースによって利用すべきプロダクトが違ってきますが、その指針となるよう特徴をまとめてみました。
※ Athenaは2017/6/22, Redshift Spectrum は 2017/10/20 からTokyoリージョンでも利用できるようになりました。
Athena と Redshiftの違い概要
共通
- ファイルシステムに対して SQL を発行するプロダクトの Presto によって動作します。
- スキャン課金が1TBあたり$5
- パーティション、列指向フォーマット、圧縮を活用することでスキャンするデータを減らしてコスト削減が可能。
Athena の特徴
- クラスタ(サーバ)を必要とせず、(S3にデータがあれば)すぐに利用可能。
- リトライ機構がなく、データを絞って高速にスキャンする。
- マネージメントコンソールをはじめ、JDBC経由でのアクセスやAWS CLI、Quicksight等から利用可能。
- ファイルフォーマットとして、TEXTFILEのほか、PARQUET、ORCなどの列指向フォーマットが利用可能。また、JSONなどの非構造化データや、正規表現による抽出も利用可能(その場合、JsonSerDe、RegexSerDeのシリアライズ方法を定義したクラスを指定する)。
- array, struct, mapなどのデータ型にも対応。
Redshift Spectrum の特徴
- Redshiftクラスタを立ち上げる必要がある。
- 大規模データに対して、複数クラスタで動作するため、高速なレスポンスが期待できる。
- Redshiftクラスタ内のテーブルとSpectrumの外部テーブルの結合や、多数のテーブル間で結合があるような複雑なクエリにも対応可能。
- ファイルフォーマットはAthenaで利用できるものと同様であるが、JSONには未対応。
AthenaはS3上にログ等のデータを保管しておりそれを分析用途に簡単に利用したい場合や、新しく取得したデータに対してDWHに入れるべきかを検証する場合に利用が適していそうです。
Redshift Spectrumは、既存でRedshiftを利用している場合のロード対象データ容量に対するノード課金を抑える用途や、データロードにかかるリソース負荷や金額負担を抑えたい場合の移行対象として利用できそうです。
環境構築からクエリ実行
S3上にデータを配置
- Athenaの場合、同一リージョン内では追加料金がかからないが、別リージョンではデータの転送料金が発生。Redshift SpectrumはS3とRedshiftクラスタが同一リージョンである必要がある。
- AthenaもRedshift spectrumも読込範囲をパーティションで区切る。
- Athenaはパーティションを区切らないと、基本的にはS3上のフルスキャンになってしまうので注意が必要。
- s3://example/year=xx/month=yy/day=zz/ のようにHiveフォーマットで指定しておくと、外部テーブルとしてパーティションを指定できる。
例) s3://example/year=2017/month=12/day=18/hoge.tsv.gz- 圧縮には bzip2, gzip, snappy、lzo(Athenaのみ) が利用可能。
- 以降の作業では圧縮しているか否かは意識しなくてよいです。
- 圧縮には bzip2, gzip, snappy、lzo(Athenaのみ) が利用可能。
フロントエンド構築
-
Athenaは、AWSマネージメントコンソールから容易にアクセスすることができます。

-
Redshift のクラスタ立ち上げ
- アクセスしたいS3バケットと、Athenaのアクセス権限をIAMロールに設定し、クラスタにアタッチします。
- Redshiftクラスタ起動時に「使用可能なロール」を選択します。複数ロールが指定可能です。

- psql コマンドでRedshift に直接ログインできます。
外部テーブル作成
Athena の場合、CatalogManagerからGUIベースでの作成もできます。以下はDDLを直接発行する場合のコマンドです。
# DBがない場合、DBを作成
CREATE DATABASE IF NOT EXISTS athenadb;
# S3上のデータに合わせて、テーブル定義を作成
CREATE EXTERNAL TABLE IF NOT EXISTS athenadb.test_table (
col1 string,
col2 string,
col3 string,
col4 string
) PARTITIONED BY (
year int,
month int,
day int
)
STORED AS TEXTFILE
LOCATION 's3://exapmle/'
Redshift Spectrumの場合、まずS3へのアクセスを指定したスキーマを作成し、その中にテーブルを作成します。
# スキーマ作成
CREATE EXTERNAL SCHEMA spectrumschema FROM data catalog
DATABASE 'spectrumdb'
IAM_ROLE 'arn:aws:iam::<AWS ACCOUNT ID>:role/xxx-redshift-role'
CREATE EXTERNAL DATABASE IF NOT EXISTS;
# S3上のデータに合わせて、テーブル定義を作成
CREATE EXTERNAL TABLE spectrumschema.test_table (
col1 varchar,
col2 varchar,
col3 varchar,
col4 varchar
)
PARTITIONED BY (year integer, month integer, day integer)
STORED AS TEXTFILE
LOCATION 's3://example/';
※作成した外部テーブルにパーティションを作成するには、alter table add partition ~ を発行する必要がありますが、手間な場合は msck repair table <tablename> でS3上に配置されたファイルから自動的にパーティション情報を認識させることができます(「msck repair table」はAthenaからのみ実行可能なコマンドです。)
クエリ実行
# DB名.外部テーブル名で指定。パーティションを指定することでスキャン量を削減可能。
SELECT col1, col2, col3, col4 FROM athenadb.test_table WHERE year=2017
出力例
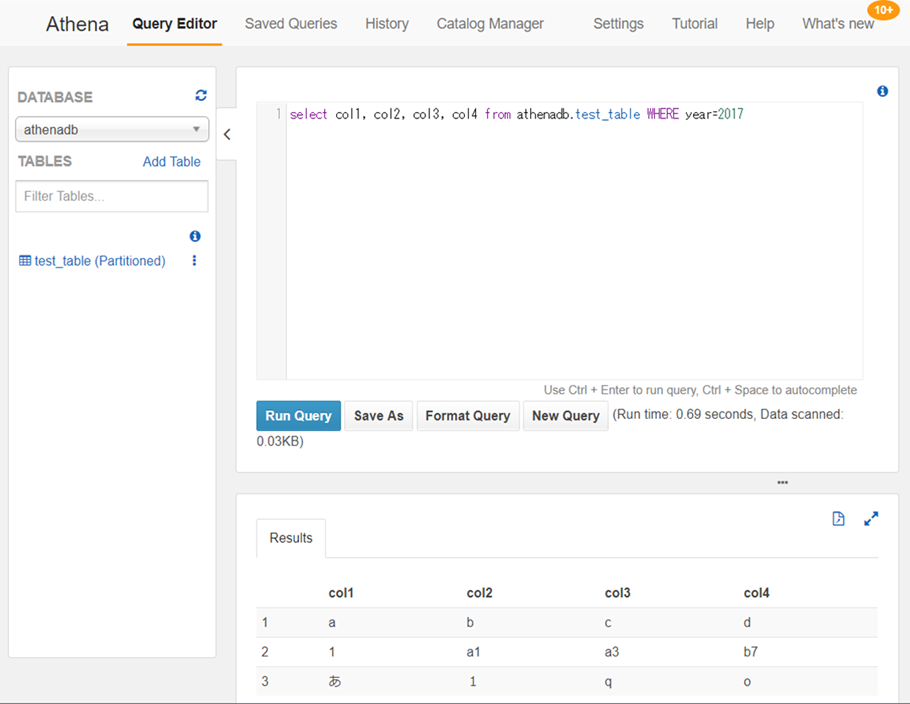
# スキーマ名.外部テーブル名。パーティションを指定することでスキャン量を削減可能。
SELECT * from spectrumschema.test_table WHERE year=2017
出力例
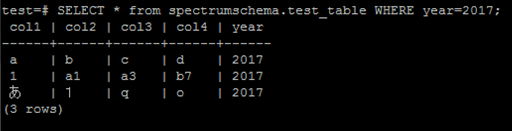
出力に関する制約
- Athenaでは、実行リージョンの S3にヘッダ付きCSVで出力することに対応。SELECT INSERT には未対応。
- Redshiftのクラスタ内のテーブルに対してINSERTが可能だが、S3上に出力することはできない。
最後に
AWSでもS3上の大量データを分析等に利用するためにデータ課金のサービスによる選択肢が増えてきました。ただし、サービスによってユースケースや制約は異なるため、その特徴をふまえて適切なサービスを選定する事が必要です。場合によってはAthenaで処理したファイルをRedshift spectrumで取り込むなど、複数のサービスを組み合わせた用途も考えられると思います。
AWSブログでも紹介されているコストやパフォーマンスに関するベストプラクティスも試行しながらアーキテクチャを考えていければよいと思いました。
https://aws.amazon.com/jp/blogs/news/top-10-performance-tuning-tips-for-amazon-athena/
https://aws.amazon.com/jp/blogs/news/10-best-practices-for-amazon-redshift-spectrum/