リストの中に特定の要素があるか探す処理
とある競技プログラミングで、「大量の要素群の中に特定の要素が入っているかチェックする」といった処理を実装する必要がありました。
私は何も考えずに List 型で実装しました。
概ね同じ事をしているのが以下のコードになります。
import time
from random import randint
a = list()
for _ in range(100000):
a.append(randint(1, 10000000)) # 1 ~ 10000000 の間の数値をランダムに 100000 個リストに append
for _ in range(10): # 今回は実験のため、10回実行
result = 0
start_time = time.time()
for _ in range(100000):
num = randint(1, 10000000) # 改めて1 ~ 10000000 の間の数値をランダムに 100000 個選び、リスト中にあれば result を + 1 する
if num in a: # 要素がリスト中に存在するかチェック
result += 1
# print(result)
print("elapsed_time:{time} sec".format(time=time.time() - start_time))
elapsed_time:240.42141199111938 sec
elapsed_time:227.7156150341034 sec
elapsed_time:220.98236417770386 sec
elapsed_time:216.4878408908844 sec
elapsed_time:213.12895107269287 sec
elapsed_time:214.8469820022583 sec
elapsed_time:218.6278579235077 sec
elapsed_time:215.24347305297852 sec
elapsed_time:223.3752110004425 sec
elapsed_time:218.8238799571991 sec
平均3分半かかります。
これでは遅くてどうやっても規定の秒数以内で終わりませんでした。
その旨を Twitter で愚痴ったところ、「List じゃなくて Set でやれば高速化できますよ」という天の声を頂きました。
本当に?と思い、試しに実装してみました。
同じ処理を Set で書いてみる
では、同じ処理を Set 型を使ってやってみましょう。
import time
from random import randint
a = set()
for _ in range(100000):
a.add(randint(1, 10000000)) # 1 ~ 10000000 の間の数値をランダムに 100000 個を集合に add
for _ in range(10): # 今回は実験のため、10回実行
result = 0
start_time = time.time()
for _ in range(100000):
num = randint(1, 10000000) # 改めて1 ~ 10000000 の間の数値をランダムに 100000 個選び、集合中にあれば result を + 1 する
if num in a: # 要素が集合中に存在するかチェック
result += 1
# print(result)
print("elapsed_time:{time} sec".format(time=time.time() - start_time))
elapsed_time:0.23300909996032715 sec
elapsed_time:0.22655510902404785 sec
elapsed_time:0.20099782943725586 sec
elapsed_time:0.23000216484069824 sec
elapsed_time:0.25554895401000977 sec
elapsed_time:0.2030048370361328 sec
elapsed_time:0.22499608993530273 sec
elapsed_time:0.24254608154296875 sec
elapsed_time:0.24500298500061035 sec
elapsed_time:0.21805286407470703 sec
__速っ!__リストの時のおよそ 100 倍のスピードで処理が完了しています。
どうしてこんなに差が出るのか
Python における List の実装
Python では list() は 「リスト構造」で実装されています。
つまり、リスト a に入っている各要素は .append が呼ばれた順番に入っているだけで、要素を探す時のヒントはありません。
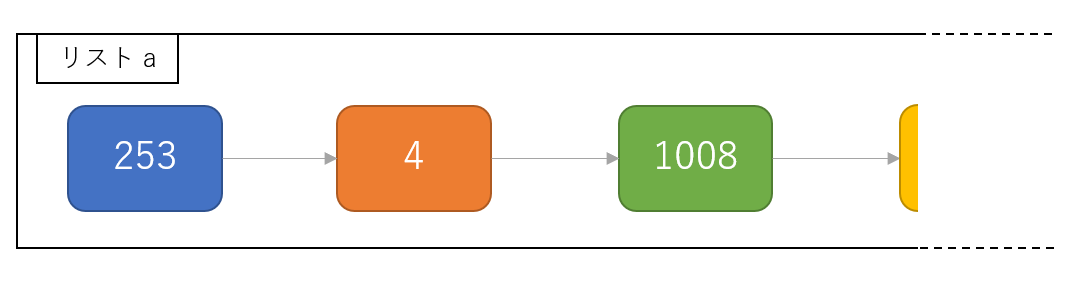
if num in a: の処理を行うためには、リストの要素を__全探索する必要があります。__
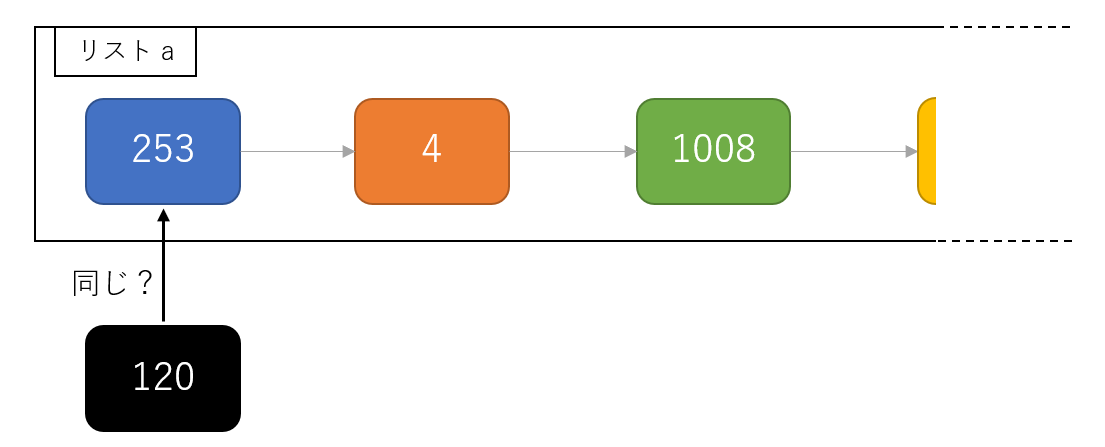
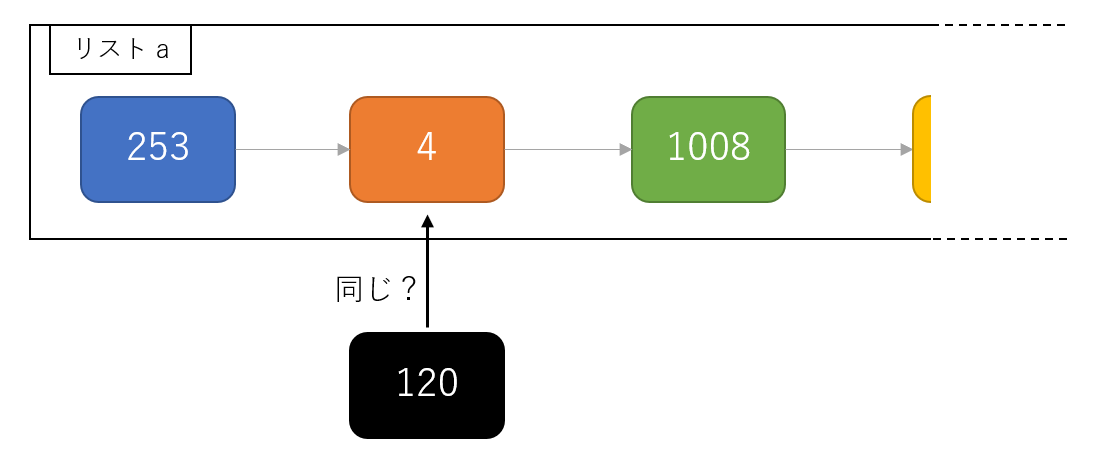
上記を延々繰り返す…
そのため、100000回100000個の要素の全探索が走った list 版は非常に実行に時間がかかったのです。
Python における Set の実装
Python では set() は「ハッシュテーブル」で実装されています。(今回調べて知りました…!)
つまり、実際の数値以外に__インデックスが貼られた探索しやすい整数__とのペアで値が入っています。
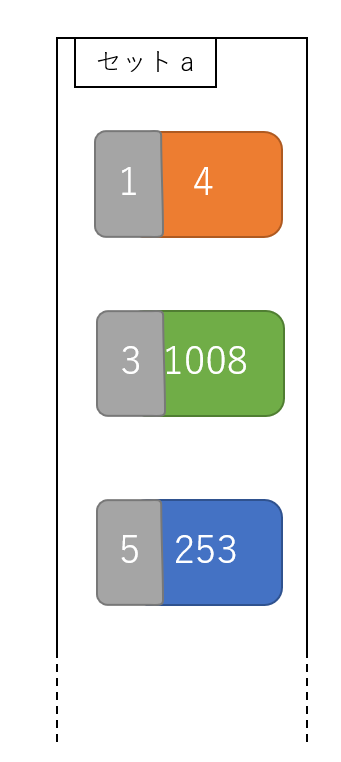
そのお陰で、例えば「集合中に120という値があるか」という探索は、ハッシュ値を元に要素を探すことができるため、探索は非常に少ない回数で済みます。(CPythonのコードまでは読めませんでしたが、きっと凄い人達が凄い方法で実装しているのです…)
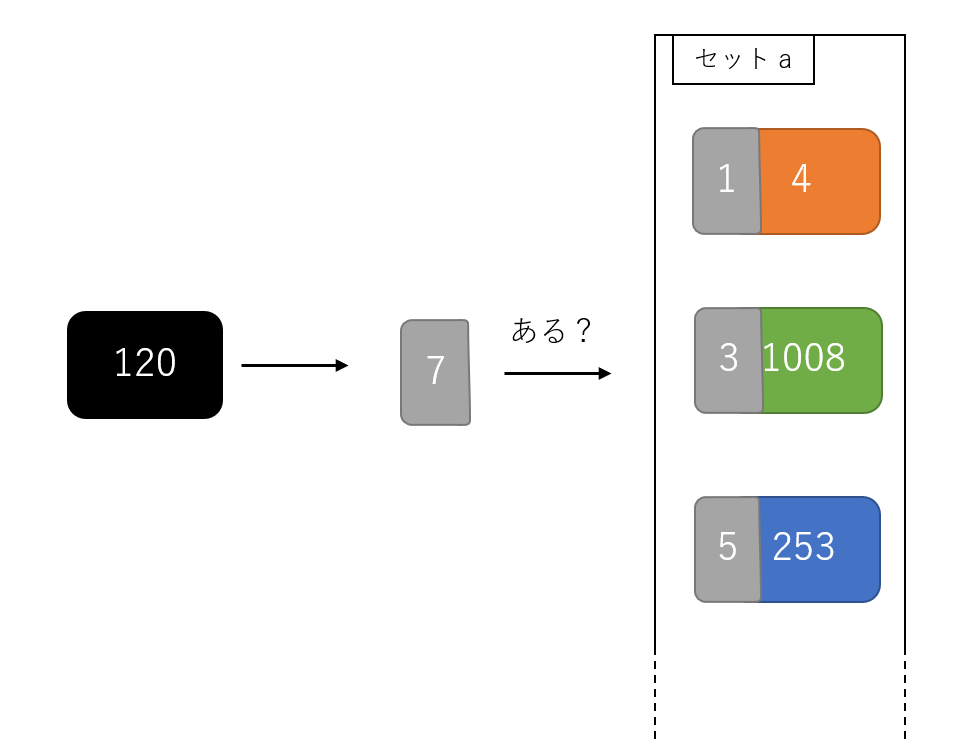
これが、探索時間に圧倒的な差が出た理由です。
ちなみに、dict() のキーも同じハッシュテーブルのため、辞書型のキーの探索はとても高速に行われます。
Set は単純に重複を許さないことや、和集合・差集合を計算できるだけでなく、こんなメリットがあったんですね。
Python を業務で3年触って、大分分かっているつもりでしたが、まだまだでした。