概要
- ニューラルネットの解釈性を与える手法(Saliency Mapやその派生系,Influence Function)に対するAdversarial Attackの提案
- 分類に対する予測値は変更せずに,解釈だけを変更するように画像にノイズを与える
- ノイズが与えられた画像をモデルで識別すると,判別結果は変わらないのに,解釈性を与える手法による「画像のどこに着目しているか(Attribution)」や「学習サンプルの貢献度(Influence Function)」が変化するようになる
Attribution適用結果の一例
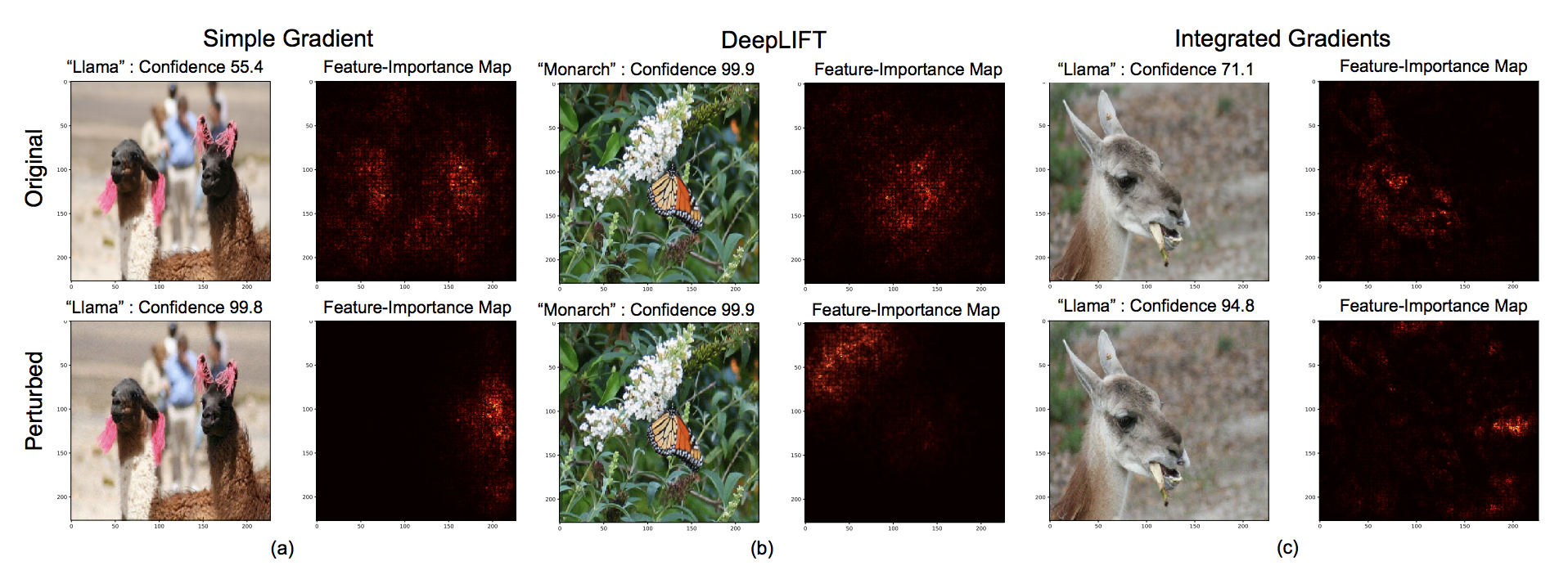
今回の手法を用いるとこうなります。
3つの画像に対してSimple Gradient (いわゆるSaliency Map)とその派生系であるDeep LIFT, Integrated Gradientsを適用しています。上は動物のオリジナル画像に適用した結果,下は本提案手法で摂動を加えた画像に対して上記の手法を与えたものになります。上の例では対象物があるピクセルが赤くなっていますが,摂動を与えたあとはものの見事に赤くなる場所が変化してます。
こんな感じで判断根拠を「ずらす」ことができます。
どうしてこんな事ができるのか?
筆者曰く,Interpretation is fragileだからだそうです。それを直感的に示した図が以下です。
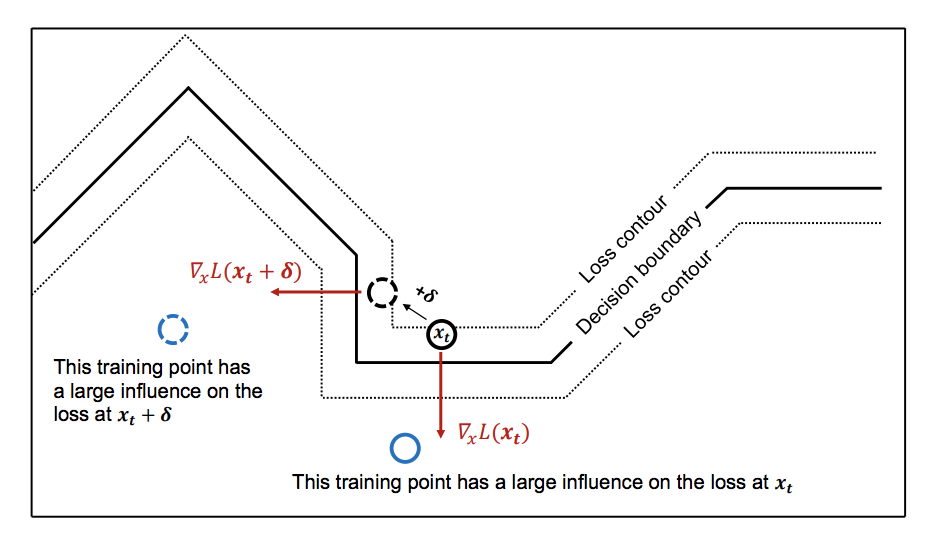
ニューラルネットの決定境界は線形のピースで表されているために,滑らかではなく若干ギザギザしたものとなっています。よって,図のように入力サンプル$x_t$を$\delta$だけ境界の中で変動させたとしてもその境界への方向,すなわちAttributionはまるっきり方向が変わってしまいます。方向が変われば重要となる学習サンプルの場所も当然変わるはずです。(図の青丸)
式的にはどうやってるの?
式の概要
概要に__分類に対する予測値は変更せずに,Attributionを変更するように画像にノイズを与える__と書いているそのままのことをします。
すなわち式に書くと以下のようなことをします。
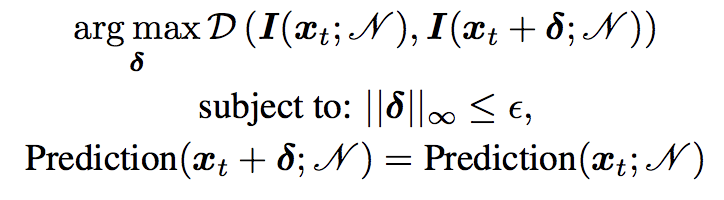
$x_t$をテストサンプル,$N$をモデルとします。式からして最適化問題なのでちょっと冗長ですが,分解して指揮を追ってみます。
- 上の式について
何を表すかというと,__入力に足し合わせたときに解釈の差分が最大になるような最適な摂動$\delta$を探す__式を示しています。関数$I()$はSaliency Mapなどの解釈性の値を与え,$D()$は解釈の差分を示す何らかの尺度です。
- 下の式
下の式二つは最適化の条件を示しています。一つ目は摂動$\delta$が十分小さいこと,二つ目は摂動を与えられる前とあとで予測値が一致することを示してます。
摂動のさせ方について(Attribution)
論文では摂動のさせかた(Attack)について3つの手法を提案しています。
- top-k attack
ピクセルのうちAttributionの大きなk番目までのピクセルのが小さくなるように摂動させます。
- mass-center attack
画像で重要なのはだいたい真ん中なので,できるだけAttribution mapの真ん中の差分が大きくなるように摂動させる
- targeted attack
特定の場所を選んで,そこのAttributionの値が小さくなるように摂動させる
これらをまとめたのが以下のアルゴリズムです。

摂動させるというのは曖昧なのですが,基本上記の3つを表した式
の偏微分値を足し合わせることで入力サンプル$x$を更新していきます(この辺はAdversarial Attackと一緒)。普通の勾配法のように偏微分の値をそのまま使うのではなく,符号だけを用いているところに注意してください。
実験結果(Attribution)
視覚的な実験結果ははじめに示した通りです。(ちなみにCenter Attackの結果だそうです。)論文中ではランダムな摂動をベースラインとしてもう一つ実験を行なっています。それが以下のグラフです。
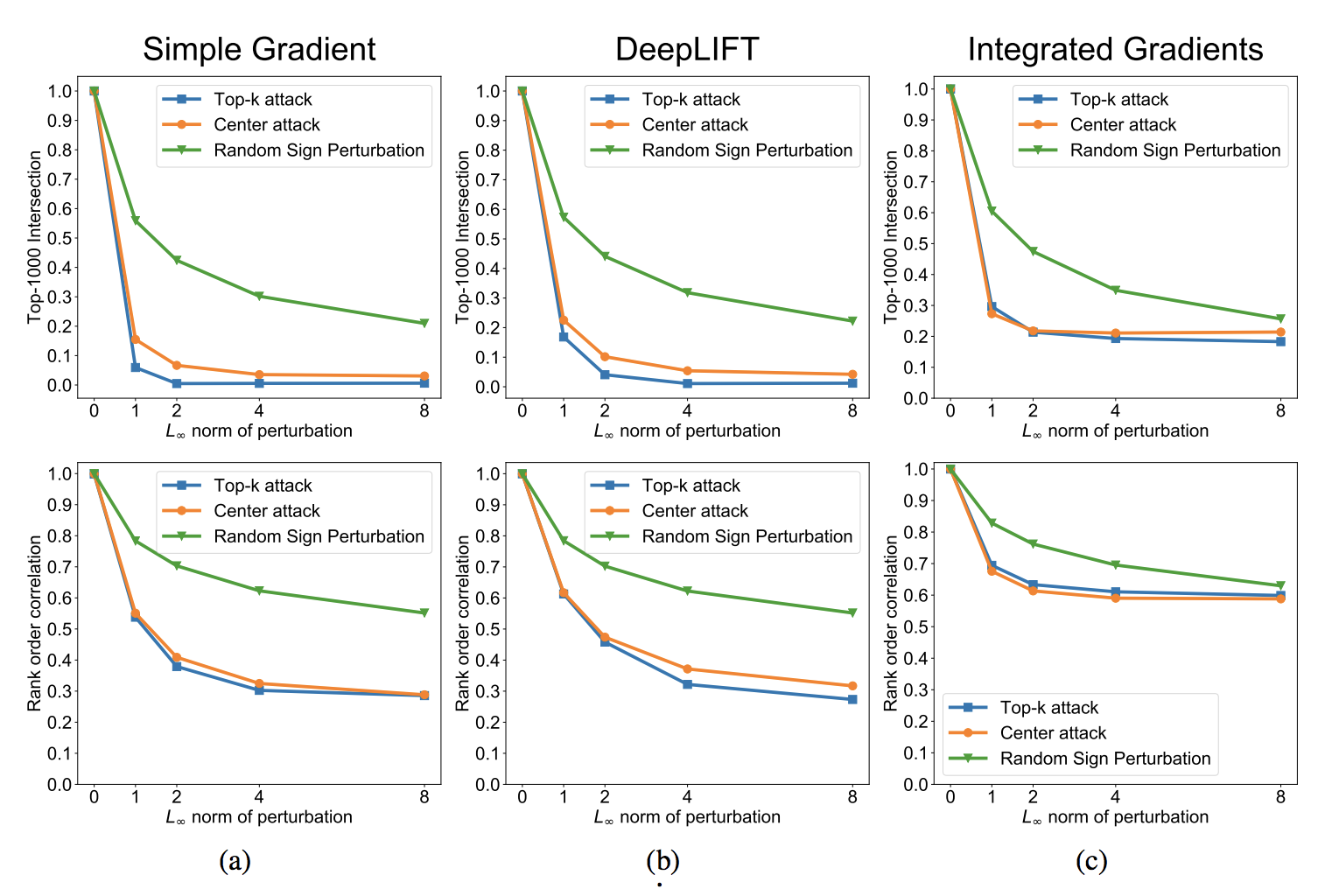
簡単にいうと,摂動を大きくしていったときにOriginalのAttributionからどれくらい離れていっているかをかしかしたものになります。横軸が摂動の大きさ,縦軸は上の図はtop-1000のAttributionの一致度,下の図は摂動前後でのAttributionの相関になります。
摂動を大きくするにつれてどんどんずれている事がわかります。
摂動のさせ方について(Influence Function)
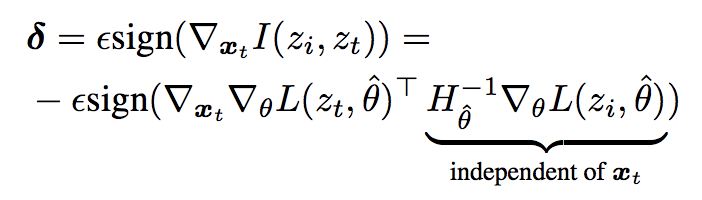
基本的に元論文で示される各訓練サンプル毎のInfluence Functionの式のサンプル$x_t$に対する微分をそのまま摂動の値にしています。今回は影響度の高い順に3つのサンプルに対するInfluence Functionの和を用いています。
実験結果(Influence Function)
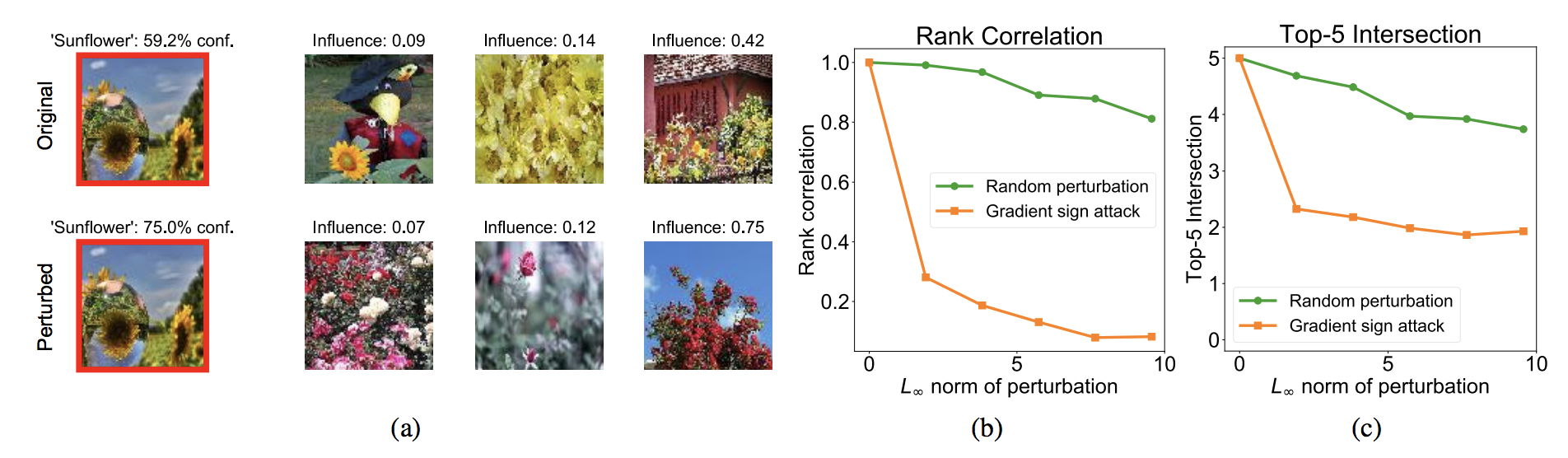
左側の(a)は一番左のひまわりの画像の認識に対して,影響の大きかった学習サンプルを影響度の大きい順に右から並べたものです。上が元々の結果,下が提案手法となります。
元々の画像に対して影響度の高い学習サンプルは基本的にひまわりの画像となってます。一方で摂動を加えたものはひまわりの画像ではなく別の花の画像になってます。
(b), (c)は摂動を大きくした場合の影響度のランキングと元々の影響度のランキングの相関を表しています。提案手法はランダムよりもすぐに下がっているので,選択的に影響度の高いサンプルを変更できている事がわかります。
まとめ
Interpretation of Neural Networks is Fragile
参考文献:
Goodfellow, Shlens, and Szegedy 2014] Goodfellow, I. J.;
Shlens, J.; and Szegedy, C. 2014. Explaining and harnessing
adversarial examples. arXiv preprint arXiv:1412.6572.