仕事でデータ解析のために取り寄せたデータが、紙をスキャンしたpdfだったので、必要なテキスト情報を何とか読み出せないかと思った。
OCR
少しググるとOCRというワードがヒットした。
Wikipediaによると、こういうものらしい。
光学文字認識(こうがくもじにんしき、Optical character recognition)は、活字の文書の画像(通常イメージスキャナーで取り込まれる)を文字コードの列に変換するソフトウェアである。一般にOCRと略記される。OCRは、人工知能やマシンビジョンの研究分野として始まった。研究は続けられているが、OCRの中心はその実装と応用に移っている。紙に印刷された文書をデジタイズし、よりコンパクトな形で記録するのに必要とされる。さらに、文字コードに変換することで機械翻訳や音声合成の入力にも使えるようになり、テキストマイニングも可能となる。研究分野としては、パターン認識、人工知能、コンピュータビジョンが対応する。
参考:Wikipediaより引用
文字認識なので、結構古典的なAI技術っぽいですね。今回の目的にあってそう。
tesseract-ocrとPyOCR
AI系だしPythonかな?ということでググるとtesseract-ocrというオープンソースのOCRエンジンがあって、それをPythonから使えるようにするライブラリでPyOCRというのがあった。
tesseract-ocrのインストール
インストール
tesseract-ocr自体はGitHubで公開されているので、wikiにインストール方法が書かれている。会社のPCはWindows10なので、Windows環境向けのインストール方法に従う。
- ここからインストーラをダウンロード
- ダウンロードが完了したらインストーラを起動する。家の環境では、発行元不明のメッセージが出たが許可して進めた。ここは自己責任で。
- インストーラが起動したらとりあえず
Next
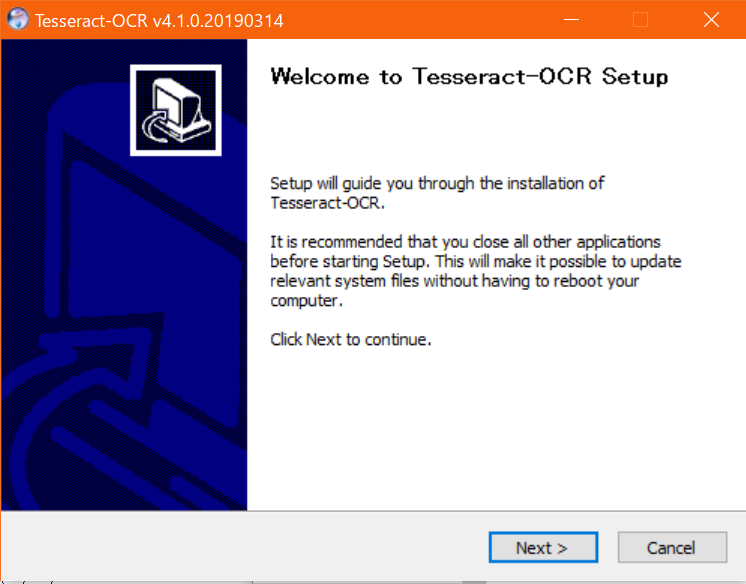
- Apacheライセンスに同意をする。
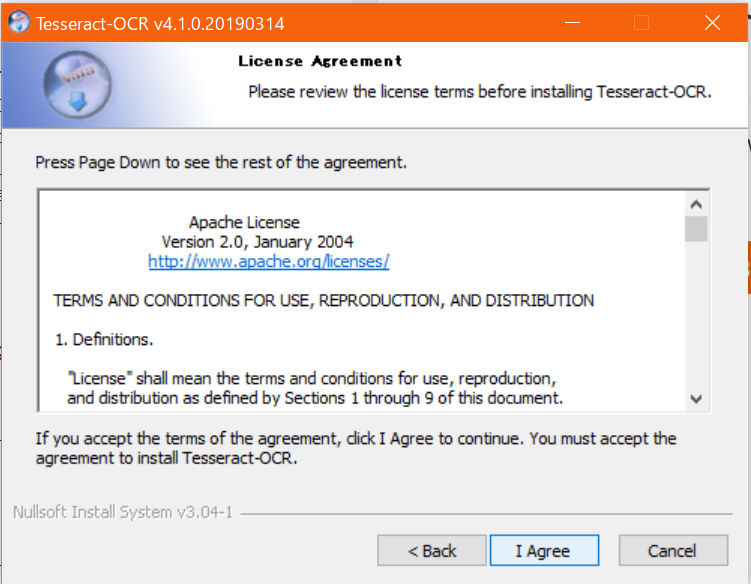
- グローバル環境か自ユーザのみにインストールするか選べる。共有マシンとかでなければグローバル環境でいいと思う。
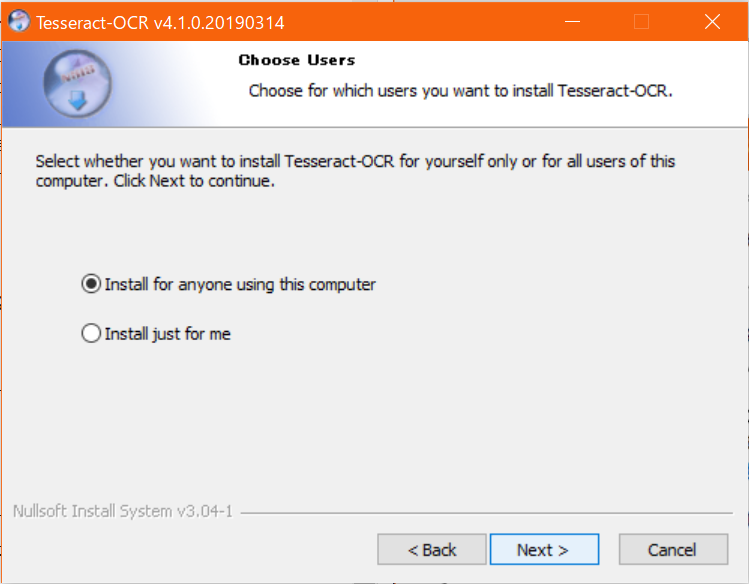
- インストールする機能を選ぶ。日本語の学習データが欲しいので、
Additional language data (download)を開く。
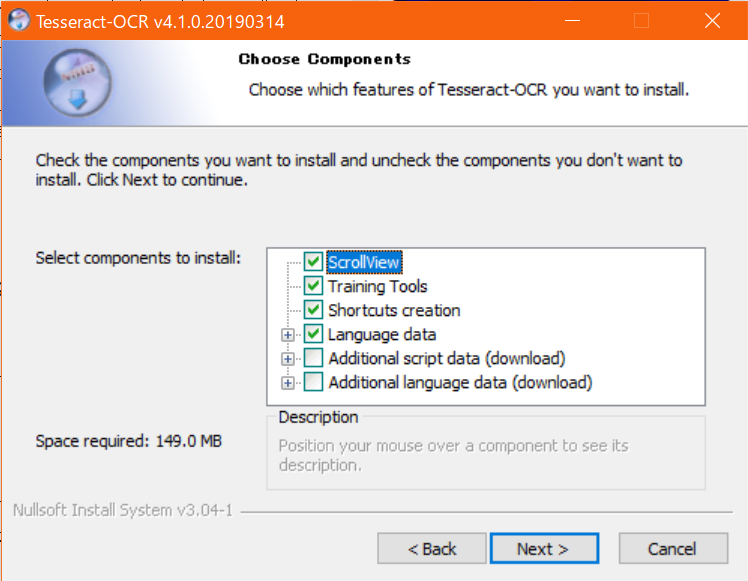
- 色んな言語がいっぱいあるが、
Japaneseを探してチェックを入れる。
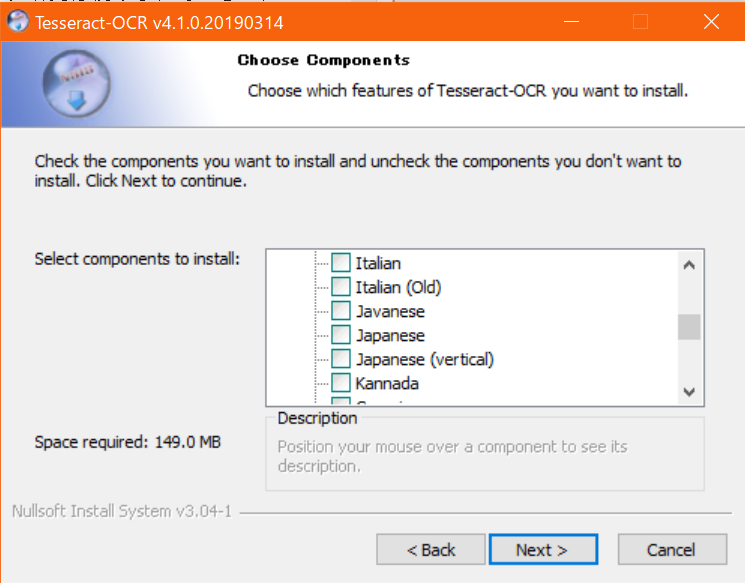
- インストールディレクトリの指定。こだわりなければデフォルトでいいと思う。(このディレクトリを後で環境変数のPathに追加する)
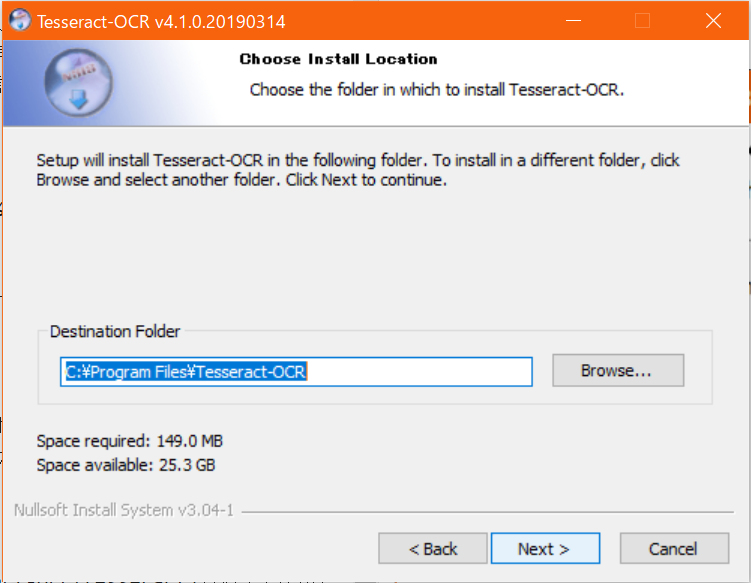
- スタートメニューに追加するフォルダ名を設定。スタートメニューにごちゃごちゃ増えるのがいやだったら、
Do not create shortcutsのチェックを入れればショートカット作らずに進む。
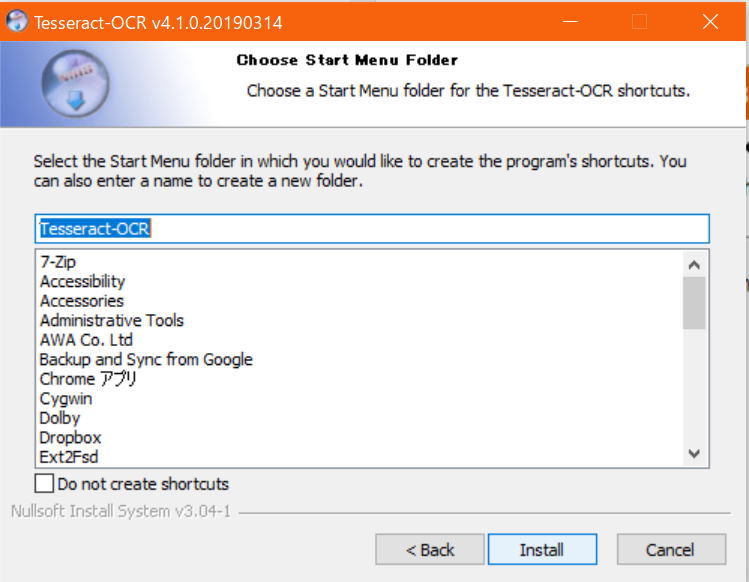
-
Installを押して、少しまでば完了。
Pathの設定
インストール時に設定したインストールディレクトリを環境変数のPathに追加する。
適当なターミナルでtesseract --versionとかで動作確認して、正常に認識されていればOK。
PyOCRのインストール
普通にpipでインストールするだけ。
ソースとかドキュメントはGitLabで公開されている。
pip install pyocr
テスト
PyOCRのリポジトリにあるReadme.mdにチュートリアルが乗っているので、それを試す。
普通の文書画像だと面白くなさそうだったので、サンプルとして好きなアーティストの辻詩音のオフィシャルサイトをスクショしたものを使ってみる。
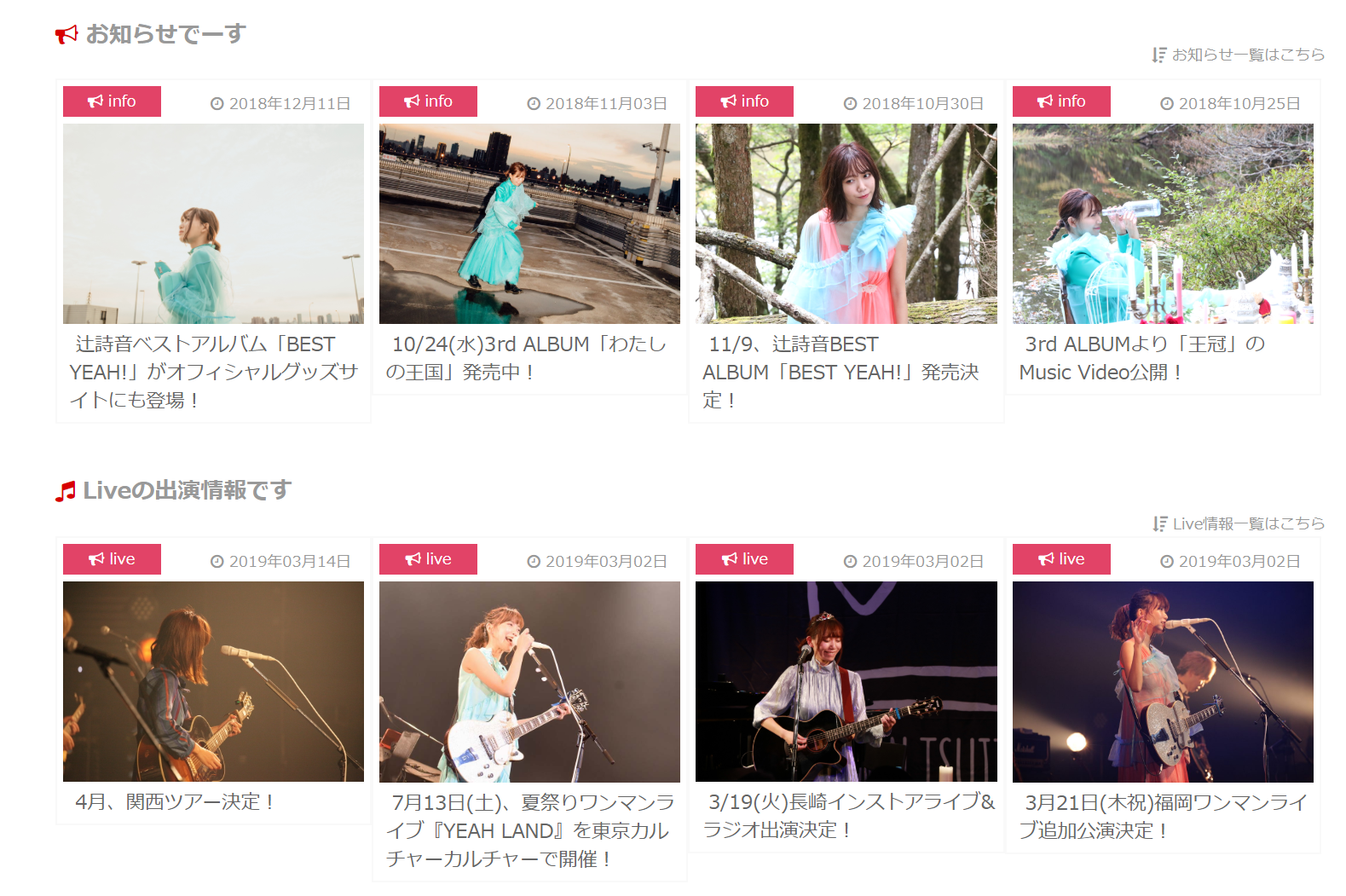
参考:辻詩音オフィシャルサイト
import pyocr
import pyocr.builders
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("No OCR tool found")
sys.exit(1)
tool = tools[0]
print("Will use tool '%s'" % (tool.get_name()))
txt = tool.image_to_string(
Image.open('data/しおんぬ.png'),
lang='jpn',
builder=pyocr.builders.TextBuilder()
)
実行結果
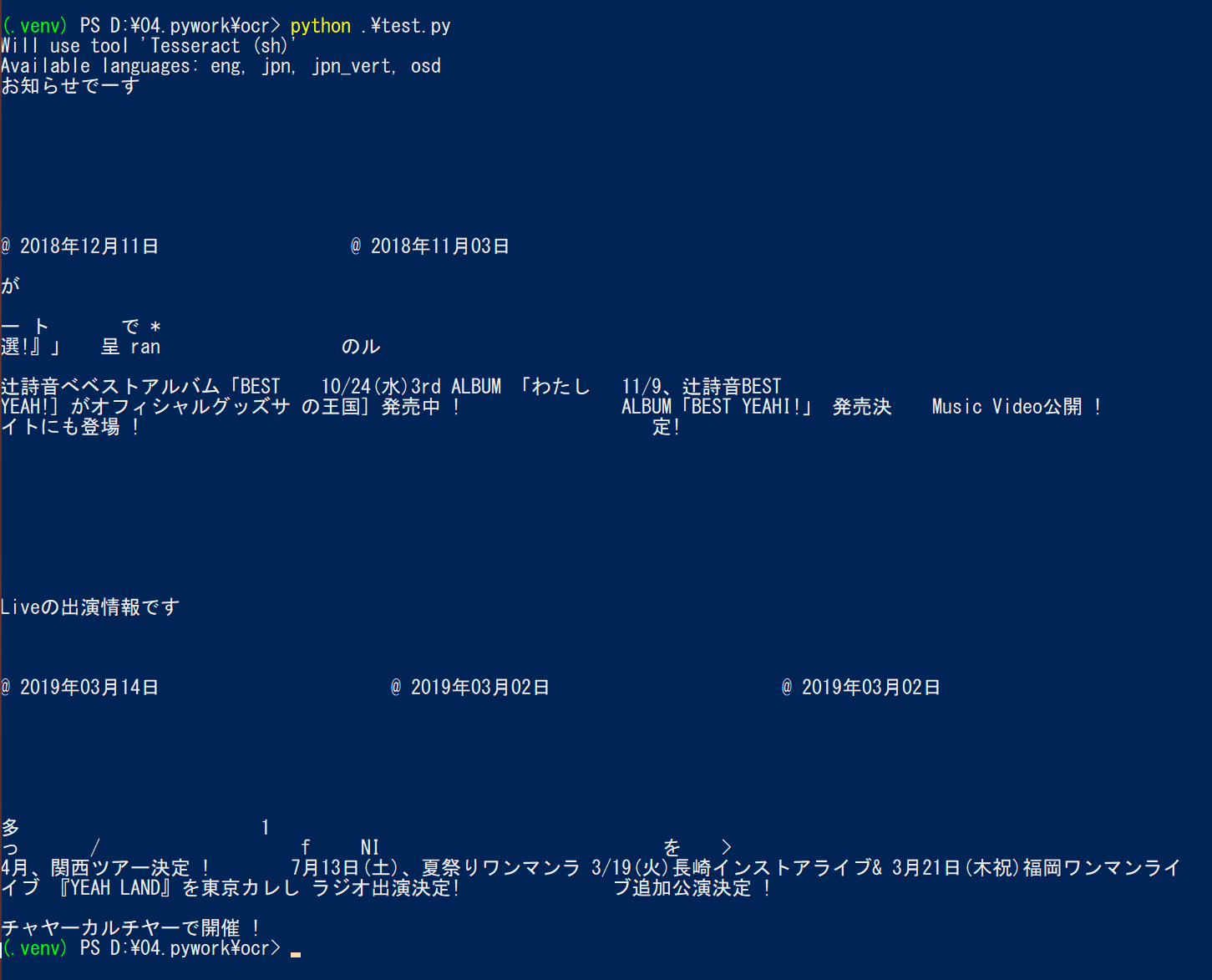
まあまあの精度かな~?という印象。仕事で実際に解析したいデータも、Excelか何かで枠作った中に、文字と画像を埋め込んたものを印刷してスキャンしたっぽいので、このサンプルほどではないものの似たような結果になるかも。
終わりに
精度的にそのままで使えるかはわからないが、とりあえず画像からテキストを抽出できるようになった。
仕事だと、紙面に上位者の自筆サイン貰ったりする都合で、保管される帳票がスキャンしたpdfとかになっていることは結構あるので、もう少し深堀していけば結構役に立ちそう。
もう少し色々試して、精度で取れるようになれば自動化できて楽できるなぁ…