概要
普段使いする中で、よく使う組み込み型を紹介する。
全部でなく抜粋なので、詳細が気になる人は公式ドキュメントも参照。
対象
-
Pythonの初歩中の初歩を学習したい人
執筆時の環境
- OS: Windows10
- Python: 3.7.3
本記事中の定義
実行例中の定義
>>> "Pythonインタプリタでの実行コマンド"
# 上のコマンドに対応するターミナルの表示
用語定義
- リテラル:代数を使わずに書いた数値や文字列。いわゆるべた書き。
- ネスト:入れ子構造のこと。
- キャスト:元の型から別の型に変換すること。
紹介する型一覧
数値型
| 種類 | 概要 |
|---|---|
| int | 整数 |
| float | 浮動小数 |
| complex | 複素数 |
int
整数値を扱う型。イントと読む。
表現可能な範囲は、環境のシステムに依存する。
他の言語ではより広範囲を扱うlongなどがあるが、Python3の場合はすべてintが包括する(Python2にはlongも存在する)。
リテラル値の書き方
数字だけの連続した記述はintとして扱われる。
>>> type(123)
# <class 'int'>
他の型からの変換(キャスト)
>>> int(123.0)
# 123
>>> int("123")
# 123
少数の小数部は四捨五入ではなく切り捨て。
>>> int(123.9)
# 123
文字列からの変換は整数値の文字列のみ対応。
少数値の文字列や、数値でない文字列からは変換できない.
>>> int("123.9") # 少数値の文字列
# Traceback (most recent call last):
# File "<stdin>", line 1, in <module>
# ValueError: invalid literal for int() with base 10: '123.9'
>>> int("one") # 数値以外の文字列
# Traceback (most recent call last):
# File "<stdin>", line 1, in <module>
# ValueError: invalid literal for int() with base 10: 'one'
例外的に、次の3パターンだけは純粋な整数値文字列でなくても変換可能。
- 整数値以外に空白スペースのみが含まれる文字列
- 整数値文字列の先頭につく
+/-符号文字 - 整数値文字列の桁間に含まれるアンダースコア(バージョン3.6以上)
>>> int(" 123 ") # 前後に空白スペース
# 123
>>> int("-123") # 先頭に+/-符号
# -123
>>> int("123_456") # 桁間にアンダースコア
# 123456
float
浮動少数を扱う型。フロートと読む。
表現可能な範囲は、環境のシステムに依存する。
他言語ではdoubleなどがあるが、pythonではfloatがすべて包括する。
リテラル値の書き方
連続する数字と1つの.(ドット)で記述した値は、floatとして扱われる。
>>> type(123.4)
# <class 'float'>
e若しくはEを$10^n$の意味として書くこともできる。
この記述では、小数点以下が結果的に0になる値でも整数にはならない。
>>> 1e3
# 1000.0
>>> type(1e3)
# <class 'float'>
>>> 1E3 # 大文字でもいい
# 1000.0
他の型からの変換(キャスト)
>>> float(123)
# 123.0
>>> float("123.0")
# 123.0
文字列からの変換は、整数値文字列でも問題ない。
>>> float("123") # 整数値文字列
# 123.0
数値ではない文字列は変換不能だが、次の4パターンに限り変換可能。
- 数値以外に空白スペースのみが含まれる文字列
- 数値文字列の先頭につく
+/-符号文字 - 数値文字列の桁間に含まれるアンダースコア(バージョン3.6以上)
- 数値文字列に含まれる指数表記用の
e,E
>>> float(" 123.4 ") # 前後に空白スペース
# 123.4
>>> float("-123.4") # 先頭に+/-符号
# -123.4
>>> float("1_234.567_890") # 桁間にアンダースコア
# 1234.56789
>>> float("1e3") # 指数表記
# 1000.0
>>> float("1E3") # 指数表記(大文字E)
# 1000.0
>>> float("1e-3") # 指数表記の負数
# 0.001
変換ではないが、専用の文字列で指定すると**$\pm\infty$と非数**を作ることができる。
>>> float("infinity") # "infinity"で無限大
# inf
>>> float("inf") # "inf"でもいい
# inf
>>> float("-inf") # 負の無限大も可能
# -inf
>>> float("INF") # 大文字/小文字は問わない
# inf
>>> float("nan") # "nan"で非数
# nan
>>> float("NAN") # 大文字/小文字は問わない
# nan
complex
複素数を扱う型。コンプレックスと読む。
実部と虚部を別々に管理できる。
電子回路設計の支援アプリなんかで、インピーダンスの計算する時とか便利。
リテラル値の書き方
リテラルの数値の末尾にj若しくはJをつけるとcomplexとして扱われる。
jをつけた数値は虚部として使われる。
>>> type(2j) # 整数リテラル
# <class 'complex'>
>>> type(2.3j) # 少数リテラル
# <class 'complex'>
>>> type(2.3J) # Jは大文字でもよい
# <class 'complex'>
リテラルで実部ごと書くときは、普通に+/-でつなぐだけ。
>>> 1.2+3.4j # 実部と虚部をまとめて記述
# (1.2+3.4j)
>>> type(1.2+3.4j) # ちゃんとcomplexとして扱われる
# <class 'complex'>
>>> 1.2-3.4j # '-'で繋いでもいい
# (1.2-3.4j)
実部と虚部を単独で扱う
complexのオブジェクトに対して、実部だけ取り出したいときは.real、虚部だけ取り出したい時は.imagを末尾につける。
>>> x = 1.2+3.4j
>>> x.real # 実部だけ取り出す
# 1.2
>>> x.imag # 虚部だけ取り出す
# 3.4
取り出された値の型はcomplexではなく、floatになる。
>>> x = 1.2+3.4j
>>> type(x)
# <class 'complex'>
>>> type(x.real)
# <class 'float'>
>>> type(x.imag)
# <class 'float'>
>>> x = 1+2j
# <class 'complex'>
>>> type(x.real)
# <class 'float'>
>>> type(x.imag)
# <class 'float'>
complex(実部, 虚部)としてインスタンスを作ることもできる。
>>> complex(1.2, 3.4)
# (1.2+3.4j)
虚部を省略して書いた場合でも、虚部が0jのcomplexが返ってくる。
>>> complex(1.2)
# (1.2+0j)
他の型からの変換(キャスト)
文字列から変換できる。
>>> complex("1.2+3j")
# (1.2+3j)
>>> complex("1.2-3j") # 実部と虚部の間は'-'でもいい
# (1.2-3j)
虚部を負数にしたい時に"実数+-虚数"という記述はエラーになる。
>>> complex("1.2+-3j")
# Traceback (most recent call last):
# File "<stdin>", line 1, in <module>
# ValueError: complex() arg is a malformed string
各部の数値と+/-符号の間に空白スペースがあってはいけない。
>>> complex("1.2 + 3j")
# Traceback (most recent call last):
# File "<stdin>", line 1, in <module>
# ValueError: complex() arg is a malformed string
str->float変換で、例外的に変換できるパターンはcomplexでも同様。
>>> complex(" 12.3+45j ") # 数値部以外の空白スペース
# (12.3+45j)
>>> complex("-1.2+3j") # 数値の先頭に符号
# (-1.2+3j)
>>> complex("12.3+4_567j") # 数値の桁間にアンダースコア
# (12.3+4567j)
>>> complex("1.2e3+4E-2j") # 指数表記のeとE
(1200+0.04j)
文字列型
| 種類 | 概要 |
|---|---|
| str | 文字列 |
str
文字列を扱う型。ストリング若しくはストラと読む。
他言語では"単一文字はcharなど"の場合があるが、pythonでは文字と文字列の区別はなく、strがすべて包括する。
リテラル値の書き方
"(ダブルクォーテーション)若しくは'(シングルクォーテーション)で囲んだ範囲はstrとして扱われる。
>>> type("abcd")
# <class 'str'>
>>> type('abcd') # `'`でも同じ
# <class 'str'>
"/'どちらでもリテラル文字列の範囲を表すが、始めと終わりの記号は統一でないといけない。
>>> type("abcd') # 始めが`"`,終わりが`'`
File "<stdin>", line 1
type("abcd')
^
SyntaxError: EOL while scanning string literal
2つの記号をネストして囲うことは可能。
その場合は、内側の記号は文字列の1部とみなされる。
>>> type("ab'cd'ef")
# <class 'str'>
>>> "ab'cd'ef" # `'`が文字列の1部
# "ab'cd'ef"
>>> 'ab"cd"ef' # `"`が文字列の1部
# 'ab"cd"ef'
"/'を文字列の1部に含みたい場合は、\(バックスラッシュ)でエスケープして文字列中に入れる。
>>> "ab\"cd\"ef\"gh"
# 'ab"cd"ef"gh'
>>> 'ab\'cd\'ef\'gh'
# "ab'cd'ef'gh"
\を純粋に含めた文字列としたい場合は、リテラル文字列の接頭辞にrをつければいい。
標準で\をデリミタに使っている、Windows系のパスとかを扱うときに、知っていると重宝する。
>>> "C:\WorkSpace\tmp\hoge.txt" # `\t`がタブとして解釈されている
# 'C:\\WorkSpace\tmp\\hoge.txt'
>>> r"C:\WorkSpace\tmp\hoge.txt" # すべての`\`がエスケープされている
# 'C:\\WorkSpace\\tmp\\hoge.txt'
他の型からの変換(キャスト)
strは基本的に変換できないオブジェクトはない。
>>> str(10)
# '10'
>>> str(1.23)
# '1.23'
>>> str([1, 2, 3])
# `[1, 2, 3]`
ただし、変換される形式がどうであるかはまちまち。
__str__(),__repr__()メソッドを未定義のクラスの場合は、インスタンスのIDが表示される。
>>> class Hoge:
... pass
...
>>> str(Hoge())
# '<__main__.Hoge object at 0x00000123456789AB>'
__str__メソッドをオーバーライドすれば、任意の形式にできるので、特に問題ではない。
>>> class Hoge:
... def __str__(self):
... return "hoge"
...
>>> str(Hoge())
# 'hoge'
シーケンス型
| 種類 | 概要 |
|---|---|
| list | 変更可能な配列 |
| tuple | 変更不能な配列 |
| range | 規則的な数値範囲の配列 |
list
内容が変更可能(ミュータブルな配列を扱う型。リストと読む。
要素の挿入・削除やソートといった機能のメソッドも持っている。
書き方(インスタンスの作り方)
[と]とで囲うように書くと、listとして認識される。
>>> type([])
# <class 'list'>
>>> []
# []
[と]の間に書いた要素はリストの要素として扱われる。
複数の要素を入れるときは、,を区切りとして書くことができる。
他言語では、"配列の要素の型"を統一しないといけないのもあるが、pythonの場合は異なる型でも同じ配列にできる。
>>> [1,2,3]
# [1, 2, 3]
>>> [1,2.3,"45"] # 要素の型は統一しなくてもいい
# [1, 2.3, '45']
,の前後には空白スペースがいくつあっても問題ないが、慣例的に,の前は空白なし、後ろは1つの空白を開けてから記述が見通しがいいとされる。
>>> [1 ,2.3, 45 ] # 適当に空白あっても認識する
# [1, 2.3, 45]
>>> [1, 2.3, 45] # 慣例的にはこの書き方がよいとされる
# [1, 2.3, 45]
空のリストを作る時はlist()で作ってもいい。
名前がズバリなので、こっちのほうが見通しはいい感じもするが、タイプ数的には[]のほうが楽なのでどちらがいいかは好みによる。
>>> []
# []
>>> list() # これでも同じ
# []
多次元配列はlistにlistを入れる。
>>> [[1, 2], [3, 4]] # 2次元配列
# [[1, 2], [3, 4]]
>>> [[[1, 2], [3, 4]], [[5, 6], [7, 8]]] # 3次元配列
# [[[1, 2], [3, 4]], [[5, 6], [7, 8]]]
同一次元のlistの要素数が違っても問題ない。
>>> [[1, 2], [3, 4, 5]] # 0番目の要素は2つ、1番目(0始まり)の要素は3つ
# [[1, 2], [3, 4, 5]]
特定要素の参照・追加
listの要素参照方法は、tupleやrangeの要素参照方法と全く同じなので、それらを読んでいるなら読み飛ばして問題ない。
単一要素の参照
list型のオブジェクトの末尾に、[参照したい要素のインデックス]をつければ、その要素を参照できる。
なお、インデックスは先頭を0として数える。
>>> [1, 2, 3][0]
# 1
>>> [1, 2, 3][1]
# 2
listの要素数を超えたインデックスの指定はできない。
>>> [1, 2, 3][100]
# Traceback (most recent call last):
# File "<stdin>", line 1, in <module>
# IndexError: list index out of range
インデックスを負数で表すと末尾から逆順に参照できる。
ただし、末尾からの場合は-1から数える。
任意要素の参照という目的より、"要素数不定のlistで末尾要素を取りたい"というシチュエーションで重宝する。
>>> [1, 2, 3][-1] # 逆順の先頭
# 3
>>> [1, 2, 3][-3] # 逆順での順番指定もできる
# 1
>>> [1, 2, 3][-100] # 逆順でも要素数を超える指定はできない
# Traceback (most recent call last):
# File "<stdin>", line 1, in <module>
# IndexError: list index out of range
複数要素の参照(スライス)
[i:j]と書くと、"i番目の要素からj番目の要素まで"の部分配列を取り出せる。
なお、i番目の要素は含み、j番目の要素は含まれない。
>>> [1, 2, 3, 4, 5][1:4]
# [2, 3, 4]
j=i+1だと取得する要素は1つだが、[i]とは違い要素が1つのlistが返ってくる。
>>> [1, 2, 3, 4, 5][1:2] # [1:2]だと2番目(0始まり)の要素だけのlist
# [2]
>>> type([1, 2, 3, 4, 5][1:2])
# <class 'list'>
>>> [1, 2, 3, 4, 5][1] # [1]だと2番目(0始まり)の要素そのもの
# 2
>>> type([1, 2, 3, 4, 5][1])
# <class 'int'>
i$\ge$jの関係でもエラーにはならず、空のlistが返ってくる。
>>> [1, 2, 3, 4, 5][2:2] # iとjが等しい場合
# []
>>> [1, 2, 3, 4, 5][3:1] # i>jの場合
# []
i番目から末尾までの指定は[i:]と省略して表記できる。
同様に、先頭からj番目までの指定は[:j]と表記できる。
>>> [1, 2, 3, 4, 5][1:] # 1番目(0始まり)から末尾
# [2, 3, 4, 5]
>>> [1, 2, 3, 4, 5][:4] # 先頭から4番目(0始まり)まで
# [1, 2, 3, 4]
逆順インデックスでの指定もできるが、直観的にわかりにくいわりに利点が薄いので、基本は使わないほうが無難。
ただし、要素数不定のlistで"末尾からi個分"という指定をしたい時は、直観的にもわかりやすいので例外的に使ってもいいと思う。
>>> [1, 2, 3, 4, 5][-4:-1] # 逆順の4番目(1始まり)から逆順の1番目(1始まり)まで
# [2, 3, 4]
>>> [1, 2, 3, 4, 5][-3:] # 末尾から3つ分
# [3, 4, 5]
[i:j:k]と書くと、"i番目の要素からj番目の要素までをk個毎"の部分配列を取得できる。
jを省略してiとk組合せで、"i番目を起点にkの倍数毎に抽出した配列"を取得するのに便利(偶数番目要素と奇数番目要素への仕分けなど)
>>> [1, 2, 3, 4, 5][1:4:2] # 1番目(0始まり)から4番目(0始まり)までを2つ毎
# [2, 4]
>>> [1, 2, 3, 4, 5][1:4:1] # kが1なら[1:4]と同じ
# [2, 3, 4]
>>> [1, 2, 3, 4, 5][::2] # 偶数番目(0始まり数え)のみ抽出
# [1, 3, 5]
>>> [1, 2, 3, 4, 5][1::2] # 奇数番目(0始まり数え)のみ抽出
# [2, 4]
kに負数を書くと、逆順のlistが戻ってくる。
一応、iとjも指定できるが、基準のlistは逆順で考えつつ、iとjの値は元の順で考えないといけないのでかなりややこしい。
"kだけ指定で逆順listを取得する"程度の使い方にとどめるのが無難。
>>> [1, 2, 3, 4, 5][::-1] # 逆順に取得(実用的)
# [5, 4, 3, 2, 1]
>>> [1, 2, 3, 4, 5][::-2] # 偶数番目(0始まり数え)のみ抽出(これはまだマシ)
# [5, 3, 1]
>>> [1, 2, 3, 4, 5][-2::-2] # 奇数番目(0始まり数え)のみ抽出(-2番目(1始まり)を基準に逆順に2つ毎...ややこしい)
# [4, 2]
単一要素の追加
append(x)メソッドで末尾に要素xを追加できる。
>>> hoge = [1, 2, 3] # [1, 2, 3]というリストを"hoge"という名前で作る
>>> hoge
# [1, 2, 3]
>>> hoge.append(4) # 末尾に4を追加
>>> hoge
# [1, 2, 3, 4]
任意の場所iに要素xを追加したい時はinsert(i, x)メソッドを使う。
iは逆順指定でもいい。
>>> hoge = [1, 2, 3] # [1, 2, 3]というリストを"hoge"という名前で作る
>>> hoge
# [1, 2, 3]
>>> hoge.insert(2, 4) # 2番目(0始まり)に4を追加
>>> hoge
# [1, 2, 4, 3]
>>> hoge.insert(-2, 5) # 逆順の指定でもいい
>>> hoge
# [1, 2, 5, 4, 3]
なお、iは要素数の範囲を指定していたら自動的に末尾になる(逆順指定なら先頭)。
単にappendメソッドの代わりとして使うのはもちろんのこと、一応"i番目までは元の順序で、それ以降は逆順"という処理をトリッキーに書けたりするが、どちらにしても可読性はよくないので控えたほうがいい。
>>> hoge = [1, 2, 3]
>>> hoge.insert(100, 4) # 上の行でhogeが3要素であることを認識していないと、"10番目(0始まり)に挿入したい"という意図に見える
>>> hoge
# [1, 2, 3, 4]
>>> hoge = [1, 2, 3]
>>> hoge.append(4) # この行だけで"末尾に追加したい"という意図がわかる
複数要素の追加
extend(x)メソッドで、末尾にシーケンス型オブジェクトxに含まれる全要素を追加できる。
>>> hoge = [1, 2, 3]
>>> hoge
# [1, 2, 3]
>>> hoge.extend([4, 5]) # 末尾に4, 5を追加
>>> hoge
# [1, 2, 3, 4, 5]
xがシーケンス型のオブジェクト以外だとエラーになる。
>>> hoge.extend(1) # intとかは指定できない
# Traceback (most recent call last):
# File "<stdin>", line 1, in <module>
# TypeError: 'int' object is not iterable
任意の場所iにシーケンス型オブジェクトxに含まれる全要素を追加したい時は、追加先のlistインスタンス[i:i] = xと書けばいい。
iは逆順指定でもいい。
>>> hoge = [1, 2, 3]
>>> hoge[2:2] = [4, 5] # 2番目(0始まり)に4, 5を追加
>>> hoge
# [1, 2, 4, 5, 3]
>>> hoge = [1, 2, 3]
>>> hoge[-1:-1] = [4, 5] # 逆順で指定してもいい
>>> hoge
# [1, 2, 4, 5, 3]
iで指定する値は、追加先のlistインスタンスの要素数を超えていても自動的に末尾になる。
ただ、単一要素を追加するinsertメソッド同様、可読性はよくないので控えたほうがいい。
>>> hoge = [1, 2, 3]
>>> hoge[10:10] = [4, 5] # 上の行でhogeが3要素であることを認識していないと、"10番目(0始まり)に挿入したい"という意図に見える
>>> hoge
# [1, 2, 3, 4, 5]
>>> hoge = [1, 2, 3]
>>> hoge.extend([4, 5]) # この行だけで"末尾に追加したい"という意図がわかる
>>> hoge
# [1, 2, 3, 4, 5]
tuple
内容が変更不可能(イミュータブル)な配列を扱う型。タプルと読む。
書き方(インスタンスの作り方)
(と)とで囲うように書くと、tupleとして認識される。
>>> type(())
# <class 'tuple'>
>>> ()
# ()
↓↓↓19'9/9修正:コメントでご指摘いただきました。ありがとうございます。↓↓↓
(と)の間に書いた要素はtupleの要素として扱われる。
複数の要素を入れるときは、,を区切りとして書く。
,で繋いだ複数の要素はtupleとして認識される。
>>> a = 1, 2, 3
>>> type(a)
# <class 'tuple'>
↑↑↑修正終わり↑↑↑
他言語では、"配列の要素の型"を統一しないといけないのもあるが、pythonの場合は異なる型でも同じ配列にできる。
>>> (1,2,3)
# (1, 2, 3)
>>> (1,2.3,"45") # 要素の型は統一しなくてもいい
# (1, 2.3, '45')
list同様、,の前後には空白スペースがいくつあっても問題ないが、慣例的に,の前は空白なし、後ろは1つの空白を開けてから記述が見通しがいいとされる。
>>> (1 ,2.3, 45 ) # 適当に空白あっても認識する
# (1, 2.3, 45)
>>> (1, 2.3, 45) # 慣例的にはこの書き方がよいとされる
# (1, 2.3, 45)
listは要素が1つなら,があっても無くてもlistとして認識されたが、tupleの場合は要素が1つでも,をつけないと、その要素の型で認識されてしまう。
>>> [1,] # 要素1つのlistとして認識される
# [1]
>>> type([1,])
# <class 'list'>
>>> (1,) # 要素1つのtupleとして認識される
# (1,)
>>> type((1,))
# <class 'tuple'>
>>> [1] # 要素1つのlistとして認識される([1,]と同じ)
# [1]
>>> type([1])
# <class 'list'>
>>> (1) # ただのint型として認識される
# 1
>>> type((1))
# <class 'int'>
一応、tuple()で空のタプルを作れる。
ただ、listと違い変更できないので、(たぶん)使い道はない。
>>> tuple()
# ()
多次元配列はtupleにtupleを入れる。
>>> ((1, 2), (3, 4)) # 2次元配列
# ((1, 2), (3, 4))
>>> (((1, 2), (3, 4)), ((5, 6), (7, 8))) # 3次元配列
# (((1, 2), (3, 4)), ((5, 6), (7, 8)))
同一次元のtupleの要素数が違っても問題ない。
>>> ((1, 2), (3, 4, 5)) # 0番目の要素は2つ、1番目(0始まり)の要素は3つ
((1, 2), (3, 4, 5))
特定要素の参照
tupleの要素参照方法は、listやrangeの要素参照方法と全く同じなので、それらを読んでいるなら読み飛ばして問題ない。
(順番に読んでいる人 -> 次へ)
単一要素の参照
tuple型のオブジェクトの末尾に、[参照したい要素のインデックス]をつければ、その要素を参照できる。
なお、インデックスは先頭を0として数える。
>>> (1, 2, 3)[0]
# 1
>>> (1, 2, 3)[1]
# 2
tupleの要素数を超えたインデックスの指定はできない。
>>> (1, 2, 3)[100]
# Traceback (most recent call last):
# File "<stdin>", line 1, in <module>
# IndexError: tuple index out of range
インデックスを負数で表すと末尾から逆順に参照できる。
ただし、末尾からの場合は-1から数える。
任意要素の参照という目的より、"要素数不定のtupleで末尾要素を取りたい"というシチュエーションで重宝する。
>>> (1, 2, 3)[-1] # 逆順の先頭
# 3
>>> (1, 2, 3)[-3] # 逆順での順番指定もできる
# 1
>>> (1, 2, 3)[-100] # 逆順でも要素数を超える指定はできない
# Traceback (most recent call last):
# File "<stdin>", line 1, in <module>
# IndexError: tuple index out of range
複数要素の参照(スライス)
[i:j]と書くと、"i番目の要素からj番目の要素まで"の部分配列を取り出せる。
なお、i番目の要素は含み、j番目の要素は含まれない。
>>> (1, 2, 3, 4, 5)[1:4]
# (2, 3, 4)
j=i+1だと取得する要素は1つだが、[i]とは違い要素が1つのtupleが返ってくる。
>>> (1, 2, 3, 4, 5)[1:2] # [1:2]だと2番目(0始まり)の要素だけのtuple
# (2,)
>>> type((1, 2, 3, 4, 5)[1:2])
# <class 'tuple'>
>>> (1, 2, 3, 4, 5)[1] # [1]だと2番目(0始まり)の要素そのもの
# 2
>>> type((1, 2, 3, 4, 5)[1])
# <class 'int'>
i$\ge$jの関係でもエラーにはならず、空のtupleが返ってくる。
>>> (1, 2, 3, 4, 5)[2:2] # iとjが等しい場合
# ()
>>> (1, 2, 3, 4, 5)[3:1] # i>jの場合
# ()
i番目から末尾までの指定は[i:]と省略して表記できる。
同様に、先頭からj番目までの指定は[:j]と表記できる。
>>> (1, 2, 3, 4, 5)[1:] # 1番目(0始まり)から末尾
# (2, 3, 4, 5)
>>> (1, 2, 3, 4, 5)[:4] # 先頭から4番目(0始まり)まで
# (1, 2, 3, 4)
逆順インデックスでの指定もできるが、直観的にわかりにくいわりに利点が薄いので、基本は使わないほうが無難。
ただし、要素数不定のtupleで"末尾からi個分"という指定をしたい時は、直観的にもわかりやすいので例外的に使ってもいいと思う。
>>> (1, 2, 3, 4, 5)[-4:-1] # 逆順の4番目から逆順の1番目まで
# (2, 3, 4)
>>> (1, 2, 3, 4, 5)[-3:] # 末尾から3つ分
# (3, 4, 5)
[i:j:k]と書くと、"i番目の要素からj番目の要素までをk個毎"の部分配列を取得できる。
jを省略してiとk組合せで、"i番目を起点にkの倍数毎に抽出した配列"を取得するのに便利(偶数番目要素と奇数番目要素への仕分けなど)
>>> (1, 2, 3, 4, 5)[1:4:2] # 1番目(0始まり)から4番目(0始まり)までを2つ毎
# (2, 4)
>>> (1, 2, 3, 4, 5)[1:4:1] # kが1なら[1:4]と同じ
# (2, 3, 4)
>>> (1, 2, 3, 4, 5)[::2] # 偶数番目(0始まり数え)のみ抽出
# (1, 3, 5)
>>> (1, 2, 3, 4, 5)[1::2] # 奇数番目(0始まり数え)のみ抽出
# (2, 4)
kに負数を書くと、逆順のtupleが戻ってくる。
一応、iとjも指定できるが、基準のtupleは逆順で考えつつ、iとjの値は元の順で考えないといけないのでかなりややこしい。
"kだけ指定で逆順tupleを取得する"程度の使い方にとどめるのが無難。
>>> (1, 2, 3, 4, 5)[::-1] # 逆順に取得(実用的)
# (5, 4, 3, 2, 1)
>>> (1, 2, 3, 4, 5)[::-2] # 偶数番目(0始まり数え)のみ抽出(これはまだマシ)
# (5, 3, 1)
>>> (1, 2, 3, 4, 5)[-2::-2] # 奇数(0始まり数え)番目のみ抽出(-2番目を基準に逆順に2つ毎...ややこしい)
# (4, 2)
range
内容が変更不可能(イミュータブル)な、連続する整数要素の配列を扱う型。レンジと読む。
回数を指定しての繰り返し処理条件などに使える。
listやtupleで同様の配列を作るより、"広範囲の配列を短い構文で定義"でき、"所要するメモリも少ない"。
なお、rangeは出力の見た目がわかりにくいので、実行例にはtupleに変換した出力を併記しておく。
書き方(インスタンスの作り方)
range(stop)で0から整数stopまでのrangeが作成できる。
要素にstopは含まれない。
>>> type(range(10))
# <class 'range'>
>>> range(10)
# range(0, 10)
>>> tuple(range(10))
# (0, 1, 2, 3, 4, 5, 6, 7, 8, 9)
0以外から始まるようにしたい場合は、range(start, stop)とすると"startからstopまで"として作成できる。
要素にstartは含み、stopは含まない。
>>> range(5, 10) # 5から10で作る
# range(5, 10)
>>> tuple(range(5, 10))
# (5, 6, 7, 8, 9)
start,stopは負数でもいい。
>>> range(-5, 5) # -5から+5まで
# range(-5, 5)
>>> tuple(range(-5, 5))
# (-5, -4, -3, -2, -1, 0, 1, 2, 3, 4)
start$\ge$stopの場合でも作成はできる。
ただし、"要素は空"の扱いになる。
>>> range(5, 1) # インスタンス自体は作れる
# range(5, 1)
>>> tuple(range(5, 1)) # 要素を取ろうとすると空っぽ
# ()
>>> range(5, 5) # start=stopでも同じ
# range(5, 5)
>>> tuple(range(5, 5))
# ()
range(start, stop, step)とすると、"startからstopまでstep毎"として作成できる。
>>> range(1, 10, 2) # 1から10まで2つ毎で作る
# range(1, 10, 2)
>>> tuple(range(1, 10, 2)) # 出力の見た目にわからないので、tupleとして表示してみる
# (1, 3, 5, 7, 9)
stepに負の値を指定すると"startからstopまで降順"になる。
ただし、"startからstopまで降順"なので、今までと逆にstart$\gt$stopが有用になり、start$\le$stopだと"要素が空"の扱いになる。
>>> range(10, 0, -1) # 10から0まで降順
# range(10, 0, -1)
>>> tuple(range(10, 0, -1))
# (10, 9, 8, 7, 6, 5, 4, 3, 2, 1)
>>> range(10, 0, -2) # 負数でもstep値の大きさは有効
# range(10, 0, -2)
>>> tuple(range(10, 0, -2))
# (10, 8, 6, 4, 2)
>>> range(-1, -10, -1) # start,stopに負数があっても同じ
# range(-1, -10, -1)
>>> tuple(range(-1, -10, -1))
# (-1, -2, -3, -4, -5, -6, -7, -8, -9)
>>> range(1, 10, -1) # stepが正数の時に有効だった、start < stopの関係は逆に無効(空扱い)になる
range(1, 10, -1)
>>> tuple(range(1, 10, -1))
()
なお、rangeは"連続する整数"を扱うものなので、int以外の型は使えない。
たとえ、"少数部が0のfloat"や"整数文字列のstr"だとしてもエラーになる。
>>> range(1.2) # int以外は使えない
# Traceback (most recent call last):
# File "<stdin>", line 1, in <module>
# TypeError: 'float' object cannot be interpreted as an integer
>>> range(1.0, 10.0) # 小数部が0でもintでない限りはダメ
# Traceback (most recent call last):
# File "<stdin>", line 1, in <module>
# TypeError: 'float' object cannot be interpreted as an integer
>>> range("1", "10") # 整数文字列も同様に使えない
# Traceback (most recent call last):
# File "<stdin>", line 1, in <module>
# TypeError: 'str' object cannot be interpreted as an integer
特定要素の参照
rangeの要素参照方法は、listやtupleの要素参照方法と全く同じなので、それらを読んでいるなら読み飛ばして問題ない。
(順番に読んでいる人 -> 次へ)
単一要素の参照
range型のオブジェクトの末尾に、[参照したい要素のインデックス]をつければ、その要素を参照できる。
なお、インデックスは先頭を0として数える。
>>> range(1, 10)[0]
# 1
>>> range(1, 10)[5]
# 6
rangeの要素数を超えたインデックスの指定はできない。
>>> range(1, 10)[100]
# Traceback (most recent call last):
# File "<stdin>", line 1, in <module>
# IndexError: range object index out of range
インデックスを負数で表すと末尾から逆順に参照できる。
ただし、末尾からの場合は-1から数える。
>>> range(1, 10)[-1] # 逆順の先頭
# 9
>>> range(1, 10)[-3] # 逆順での順番指定もできる
# 7
>>> range(1, 10)[-100]
# Traceback (most recent call last):
# File "<stdin>", line 1, in <module>
# IndexError: range object index out of range
複数要素の参照(スライス)
[i:j]と書くと、"i番目の要素からj番目の要素まで"の部分配列を取り出せる。
なお、i番目の要素は含み、j番目の要素は含まれない。
>>> range(1, 10)[1:4]
# range(2, 5)
>>> tuple(range(1, 10)[1:4])
# (2, 3, 4)
j=i+1だと取得する要素は1つだが、[i]とは違い要素が1つのrangeが返ってくる。
>>> range(1, 10)[1:2] # [1:2]だと2番目(0始まり)の要素だけのrange
# range(2, 3)
>>> tuple(range(1, 10)[1:2])
# (2,)
>>> type(range(1, 10)[1:2])
# <class 'range'>
>>> range(1, 10)[1] # [1]だと2番目(0始まり)の要素そのもの
# 2
>>> type(range(1, 10)[1])
# <class 'int'>
i$\ge$jの関係でもエラーにはならず、空のrangeが返ってくる。
>>> range(1, 10)[2:2] # iとjが等しい場合
# range(3, 3)
>>> tuple(range(1, 10)[2:2])
# ()
>>> range(1, 10)[3:1] # i>jの場合
# range(4, 2)
>>> tuple(range(1, 10)[3:1])
# ()
i番目から末尾までの指定は[i:]と省略して表記できる。
同様に、先頭からj番目までの指定は[:j]と表記できる。
>>> range(1, 10)[1:] # 1番目(0始まり)から末尾
# range(2, 10)
>>> tuple(range(1, 10)[1:])
# (2, 3, 4, 5, 6, 7, 8, 9)
>>> range(1, 10)[:4] # 先頭から4番目(0始まり)まで
# range(1, 5)
>>> tuple(range(1, 10)[:4])
# (1, 2, 3, 4)
逆順インデックスでの指定もできるが、直観的にわかりにくいわりに利点が薄いので、基本は使わないほうが無難。
ただし、要素数不定のrangeで"末尾からi個分"という指定をしたい時は、直観的にもわかりやすいので例外的に使ってもいいと思う。
>>> range(1, 10)[-4:-1] # 逆順の4番目から逆順の1番目まで
# range(6, 9)
>>> tuple(range(1, 10)[-4:-1])
# (6, 7, 8)
>>> range(1, 10)[-3:] # 末尾から3つ分
# range(7, 10)
>>> tuple(range(1, 10)[-3:])
# (7, 8, 9)
[i:j:k]と書くと、"i番目の要素からj番目の要素までをk個毎"の部分配列を取得できる。
jを省略してiとk組合せで、"i番目を起点にkの倍数毎に抽出した配列"を取得するのに便利(偶数番目要素と奇数番目要素への仕分けなど)
>>> range(1, 10)[1:4:2] # 1番目(0始まり)から4番目(0始まり)までを2つ毎
# range(2, 5, 2)
>>> tuple(range(1, 10)[1:4:2])
# (2, 4)
>>> range(1, 10)[1:4:1] # kが1なら[1:4]と同じ
# range(2, 5)
>>> tuple(range(1, 10)[1:4:1])
# (2, 3, 4)
>>> range(1, 10)[::2] # 偶数番目(0始まり数え)のみ抽出
# range(1, 10, 2)
>>> tuple(range(1, 10)[::2])
# (1, 3, 5, 7, 9)
>>> range(1, 10)[1::2] # 奇数番目(0始まり数え)のみ抽出
# range(2, 10, 2)
>>> tuple(range(1, 10)[1::2])
# (2, 4, 6, 8)
kに負数を書くと、逆順のrangeが戻ってくる。
一応、iとjも指定できるが、基準のrangeは逆順で考えつつ、iとjの値は元の順で考えないといけないのでかなりややこしい。
"kだけ指定で逆順rangeを取得する"程度の使い方にとどめるのが無難。
>>> range(1, 10)[::-1] # 逆順に取得(実用的)
# range(9, 0, -1)
>>> tuple(range(1, 10)[::-1])
# (9, 8, 7, 6, 5, 4, 3, 2, 1)
>>> range(1, 10)[::-2] # 偶数番目(0始まり数え)のみ抽出(これはまだマシ)
# range(9, 0, -2)
>>> tuple(range(1, 10)[::-2])
# (9, 7, 5, 3, 1)
>>> range(1, 10)[-2::-2] # 奇数(0始まり数え)番目のみ抽出(-2番目を基準に逆順に2つ毎...ややこしい)
# range(8, 0, -2)
>>> tuple(range(1, 10)[-2::-2])
# (8, 6, 4, 2)
その他
| 種類 | 概要 |
|---|---|
| set | 集合 |
| dict | 辞書 |
| bool | 論理値(ブール値) |
set
集合を扱う型。セットと読む。
書き方(インスタンスの作り方)
{と}とで囲うように書くと、setとして認識される。
ただし、間に何も要素を書かない場合、空集合ではなくdictと認識される。
>>> type({1})
# <class 'set'>
>>> {1}
# {1}
>>> type({}) # 要素が空だとdict扱い
# <class 'dict'>
空集合を作りたい時は、set()と書けばいい。
>>> type(set())
# <class 'set'>
>>> set()
# set()
{と}の間に書いた要素は集合の要素として扱われる。
複数の要素を入れるときは、,を区切りとして書くことができる。
集合なので、重複する要素を指定しても1つだけ登録され、エラーにはならない。
>>> {1, 2, 3}
# {1, 2, 3}
>>> {1, 2, 3, 2} # 重複要素を渡しても1つしか入らない
# {1, 2, 3}
,の前後には空白スペースがいくつあっても問題ないが、慣例的に,の前は空白なし、後ろは1つの空白を開けてから記述が見通しがいいとされる。
>>> {1 ,2.3, 45 } # 適当に空白あっても認識する
# {1, 2.3, 45}
>>> {1, 2.3, 45} # 慣例的にはこの書き方がよいとされる
# {1, 2.3, 45}
要素の取り出し
集合から要素を取り出すのは、pop()メソッドを使う。
pop()で取り出した要素は元の集合から削除される。
setに順序の概念はないので、取り出す順番の指定はできない。
>>> s = {1, 2, 3} # 先頭から要素を取り出す。
>>> s.pop()
# 1
>>> s # 元の集合からは削除される
# {2, 3}
forループで順次要素を取り出すこともできる。
この方法で取り出した場合は、元の集合もそのまま。
>>> s = {1, 2, 3}
>>> for i in s: # sを順次取得
... print(i)
...
# 1
# 2
# 3
>>> s # 取得後でもsはそのまま
{1, 2, 3}
要素の削除・追加
単一要素の削除・追加
要素elemを削除したい時は、remove(elem)かdiscard(elem)を使う。
remove(elem)はelemが集合に含まれないときKeyErrorとなるが、discard(elem)は無視するという違いがある。
どちらを使うかは、シチュエーションによりけり。
>>> s = {1, 2, 3}
>>> s.remove(2) # 要素2を削除
>>> s
# {1, 3}
>>> s.remove(4) # 存在しない要素の指定はエラー
# Traceback (most recent call last):
# File "<stdin>", line 1, in <module>
# KeyError: 4
>>> s = {1, 2, 3}
>>> s.discard(2) # 存在する要素を指定した挙動はremoveと同じ
>>> s
# {1, 3}
>>> s.discard(4) # 存在しない要素の指定でもエラーは出ない
# 何も起きない
集合に要素elemを追加するときは、add(elem)メソッドを使う。
要素elemが既に集合に含まれている場合は、単に無視される。
>>> s = {1, 2, 3}
>>> s.add(4) # 要素4を追加
>>> s
# {1, 2, 3, 4}
>>> s.add(2) # 既存の要素を追加しても無視される
>>> s
{1, 2, 3, 4}
複数要素の削除・追加
集合Aに含まれる要素から、集合B,Cに含まれる要素を除く場合は、difference_update(*others)メソッドを使う。
*othersで与える集合は単数でも複数でもいい。
※ 数式やベン図でいうとこんな条件
$A \setminus (B \cup C)$
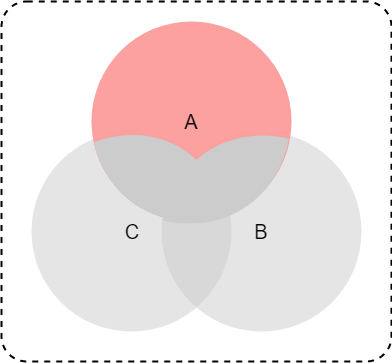
>>> a = {1, 2, 3}
>>> b = {3, 4, 5}
>>> c = {4, 5, 6}
>>> a.difference_update(b, c) # 集合Aから集合B,Cに共通する要素を削除
>>> a
# {1, 2}
>>> b.difference_update(c) # 渡す集合は1つでもいい
>>> b
# {3}
渡す集合は、集合といいつつsetでなくてもシーケンス型なら受け付ける。
intとかの単数オブジェクトはダメ。
>>> a = {1, 2, 3}
>>> a.difference_update([2, 2, 3, 4, 5, 5]) # listでもいい
>>> a
# {1}
>>> a.difference_update(1) # さすがにintはダメ
# Traceback (most recent call last):
# File "<stdin>", line 1, in <module>
# TypeError: 'int' object is not iterable
集合AまたはBにのみ含まれる集合を取得したい場合は、symmetric_difference_update(other)メソッドを使う。
このメソッドでは、渡せる集合は1つだけ。
シーケンス型なら良いのと、intなどの単数形オブジェクトがダメなのは同じ。
※ 数式やベン図でいうとこんな条件
$(A \cap \overline{B}) \cup (\overline{A} \cap B)$
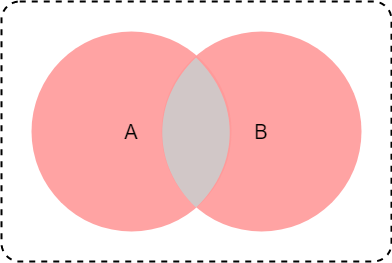
>>> a = {1, 2, 3}
>>> b = {2, 3, 4, 5}
>>> a.symmetric_difference_update(b) # 集合AとBに共通しない要素のみを取得
>>> a
# {1, 4, 5}
>>> a = {1, 2, 3}
>>> a.symmetric_difference_update([2, 3, 4, 5]) # listでもいい
>>> a
# {1, 4, 5}
>>> a.symmetric_difference_update(1) # intはダメ
# Traceback (most recent call last):
# File "<stdin>", line 1, in <module>
# TypeError: 'int' object is not iterable
集合AとB,Cに共通する要素のみを取得したい時は、intersection_update(*others)メソッドを使う。
*othersは単数でも複数でもいい。
これも他のメソッド同様、シーケンス型なら受け付け、intなどの単数型はダメ。
※ 数式やベン図でいうとこんな条件
$A \cap B \cap C$
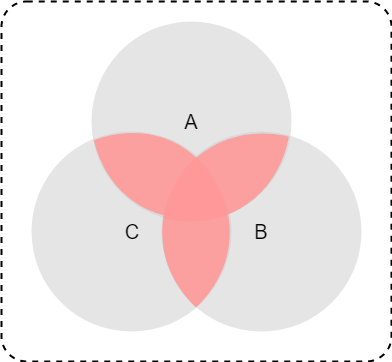
>>> a = {1, 2, 3}
>>> b = {3, 4, 5}
>>> c = {1 ,3, 5, 7, 9}
>>> a.intersection_update(b, c) # 集合A,B,Cすべてに共通する要素のみ取得
>>> a
# {3}
>>> b.intersection_update(c) # 渡す集合は1つでもいい
>>> b
# {3, 5}
>>> a = {1, 2, 3}
>>> a.intersection_update([1, 3, 5, 3, 1]) # listでもいい
>>> a
# {1, 3}
>>> a.intersection_update(1) # intはダメ
# Traceback (most recent call last):
# File "<stdin>", line 1, in <module>
# TypeError: 'int' object is not iterable
集合AとB,Cいづれかに属する要素を取得したい時は、update(*others)メソッドを使う。
*othersは単数でも複数でもいい。
これも他のメソッド同様、シーケンス型なら受け付け、intなどの単数型はダメ。
※ 数式やベン図でいうとこんな条件
$A \cup B \cup C$
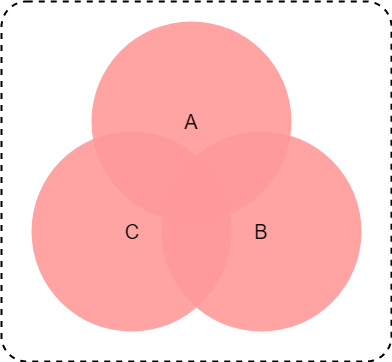
>>> a = {1, 2, 3}
>>> b = {3, 4, 5}
>>> c = {1 ,3, 5, 7, 9}
>>> a.update(b, c) # 集合AにBとCの要素を追加
>>> a
# {1, 2, 3, 4, 5, 7, 9}
>>> b.update(c) # 渡す集合は1つでもいい
>>> b
# {1, 3, 4, 5, 7, 9}
>>> a = {1, 2, 3}
>>> a.update([3, 4, 5]) # listでもいい
>>> a
# {1, 2, 3, 4, 5}
>>> a.update(6) # intはダメ
# Traceback (most recent call last):
# File "<stdin>", line 1, in <module>
# TypeError: 'int' object is not iterable
他の型からの変換(キャスト)
シーケンス型から変換できる。
変換元のシーケンス型オブジェクトに、重複要素があっても1つだけに処理される。
listとかで重複要素を削除するために、一旦setにしてlistに戻すというのにも使える。
>>> set([1, 2, 3]) # listから変換
# {1, 2, 3}
>>> set((1, 2, 3)) # tupleでもいい
# {1, 2, 3}
>>> set(range(10)) # rangeでもいい
# {0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
>>> set([1, 2, 3, 2, 3]) # 元のオブジェクトに重複要素があってもいい
# {1, 2, 3}
intなどの単体オブジェクトだと、"1要素の集合"になるわけではなくエラーになる。
>>> set(1) # intはダメ
# Traceback (most recent call last):
# File "<stdin>", line 1, in <module>
# TypeError: 'int' object is not iterable
dict
辞書を扱う型。ディクト若しくはディクショナリと読む。
キーになる要素と値になる要素を組でもつことができ、任意の文字列やtupleとも要素を対応付けられる。
書き方(インスタンスの作り方)
キーkと値要素vを、{と}とで囲うようにk:v書くと、dictとして認識される。
setでも触れたが、例外的に{}と間に何も書かなければ空のdictになる。
>>> type({"hoge":1})
# <class 'dict'>
>>> {"hoge":1}
# {'hoge': 1}
>>> type({}) # 空で書くとsetではなくdict認識
# <class 'dict'>
>>> {}
# {}
複数の要素を入れるときは、,を区切りとして書くことができる。
キーと要素は必ず必要なので、どちらかを省略するようなことはできない。
>>> {'A': 1, 'B': 2, 'C': 3}
# {'A': 1, 'B': 2, 'C': 3}
>>> {'A': 1, 'B': , 'C': 3} # キーのみの登録はできない
# File "<stdin>", line 1
# {'A': 1, 'B': , 'C': 3}
# ^
# SyntaxError: invalid syntax
>>> {'A': 1, : 2, 'C': 3} # 要素のみの登録もできない
# File "<stdin>", line 1
# {'A': 1, : 2, 'C': 3}
# ^
# SyntaxError: invalid syntax
,や:の前後には空白スペースがいくつあっても問題ないが、慣例的に,,:ともに前は空白なし、後ろは1つの空白を開けてから記述が見通しがいいとされる。
>>> { 'A' :1 , 'B':2, 'C': 3 } # 適当に空白あっても認識する
# {'A': 1, 'B': 2, 'C': 3}
>>> {'A': 1, 'B': 2, 'C': 3} # 慣例的にはこの書き方がよいとされる
# {'A': 1, 'B': 2, 'C': 3}
特定要素の参照
単一要素の参照
dictの要素にを参照するには、キーkをdictオブジェクトの末尾に[k]と記述して指定する。
{'A': 1, 'B': 2, 'C': 3}
>>> a['B']
# 2
キーに無い要素を指定するとエラーになる。
>>> a = {'A': 1, 'B': 2, 'C': 3}
>>> a['b']
# Traceback (most recent call last):
# File "<stdin>", line 1, in <module>
# KeyError: 'b'
get(k, defalt)メソッドでも、キーkで指定した要素を取得できる。
ただし、こちらはキーに無い要素を指定してもdefaultの値を返し、エラーにならない。
defaultは省略可能で、省略するとNoneになる。
>>> a = {'A': 1, 'B': 2, 'C': 3}
>>> a.get('B', 4) # 存在するキーだと`['B']`で取得するのと同じ
# 2
>>> a.get('b', 4) # 存在しないキーでもエラーにならない
# 4
>>> a.get('b') # defaultを省略するとNone
# 出力なし
複数要素の参照
dictに含まれるすべてのキーを取得する場合、keys()メソッドを使う。
これで戻ってくるのは、dict_keysというオブジェクトで、大本のdictの変化に追従する。
>>> a = {'A': 1, 'B': 2, 'C': 3}
>>> b = a.keys() # aのキー一式を取得
>>> b
# dict_keys(['A', 'B', 'C'])
>>> a.pop('A') # aから'A'を削除
# 1
>>> a
{'B': 2, 'C': 3}
>>> b # aで消したキー'A'がなくなっている
# dict_keys(['B', 'C'])
dictに含まれるすべての値を取得する場合、values()メソッドを使う。
これで戻ってくるのは、dict_valuesというオブジェクトで、大本のdictの変化に追従する。
>>> a = {'A': 1, 'B': 2, 'C': 3}
>>> b = a.values() # aの値一式を取得
>>> b
# dict_values([1, 2, 3])
>>> a.pop('A') # a空'A'を削除
# 1
>>> a
# {'B': 2, 'C': 3}
>>> b # aで消したキー'A'に対応した値1がなくなっている
# dict_values([2, 3])
dictに含まれるすべてのキーと値の組を取得する場合、itemss()メソッドを使う。
これで戻ってくるのは、dict_itemsというオブジェクトで、大本のdictの変化に追従する。
>>> a = {'A': 1, 'B': 2, 'C': 3}
>>> b = a.items() # aのキーと値の組一式を取得
>>> b
# dict_items([('A', 1), ('B', 2), ('C', 3)])
>>> a.pop('A') # a空'A'を削除
# 1
>>> a
# {'B': 2, 'C': 3}
>>> b # aで消したキー'A'と対応した値1の組がなくなっている
# dict_items([('B', 2), ('C', 3)])
dict_keys(),dict_values(),dict_items()ともに、大元のdictの変化に影響されたくないときは、listやtupleに変換すればいい。
>>> a = {'A': 1, 'B': 2, 'C': 3}
>>> b = list(a.keys()) # listとして取得
>>> c = tuple(a.values()) # tupleとして取得
>>> d = list(a.items()) # listとして取得
>>> b
# ['A', 'B', 'C']
>>> c
# (1, 2, 3)
>>> d # itemsの場合は、tupleのlistやtupleになる
# [('A', 1), ('B', 2), ('C', 3)]
>>> a.pop('A') # aから'A'を削除
# 1
>>> a
# {'B': 2, 'C': 3}
>>> b # aで消したキーもそのまま
# ['A', 'B', 'C']
>>> c # aで消したキーもそのまま
# (1, 2, 3)
>>> d # aで消したキーもそのまま
# [('A', 1), ('B', 2), ('C', 3)]
要素の削除・追加
キーkの要素を削除したい時は、pop(k)メソッドを使う。
削除とともに該当要素を返す。
存在しないキーを指定したらエラーになる。
>>> a = {'A': 1, 'B': 2, 'C': 3}
>>> a.pop('A') # 'A'の要素を削除
# 1
>>> a
# {'B': 2, 'C': 3}
>>> a.pop('a') # 存在しないキーはエラー
# Traceback (most recent call last):
# File "<stdin>", line 1, in <module>
# KeyError: 'a'
ただし、pop(k, default)と指定すると、存在しないキーを指定したときにdefaultの値が返ってくる。
当然、この場合はdictの中身は変化しない。
>>> a = {'A': 1, 'B': 2, 'C': 3}
>>> a.pop('a', 4) # 存在しないキーの時はdefault値
# 4
>>> a # 元のdictは変化しない
# {'A': 1, 'B': 2, 'C': 3}
キーkの要素vを追加したい時は、追加したいdict[k] = vと記述すると追加される。
キーkが既に存在している場合は、そのキーに対応する値をvで上書きする。
>>> a = {'A': 1, 'B': 2, 'C': 3}
>>> a
# {'A': 1, 'B': 2, 'C': 3}
>>> a['D'] = 4 # 新しくキー'D'で値4が追加される
>>> a
# {'A': 1, 'B': 2, 'C': 3, 'D': 4}
>>> a['B'] = 5 # 既存のキー'B'を指定すると、対応する値が2->5に上書きされる
>>> a
# {'A': 1, 'B': 5, 'C': 3, 'D': 4}
既存キーの場合に値を上書きしたくない場合は、setdefault(k, default)メソッドを使う。
defaultは省略可能で、省略するとNoneになる。
>>> a = {'A': 1, 'B': 2, 'C': 3}
>>> a.setdefault('D', 4) # 存在しないキーだとdefault値が追加される
# 4
>>> a
# {'A': 1, 'B': 2, 'C': 3, 'D': 4}
>>> a.setdefault('B', 5) # 既存のキーだと既存の対応した値が返ってくる
# 2
>>> a # dictも変化しない
# {'A': 1, 'B': 2, 'C': 3, 'D': 4}
>>> a.setdefault('E') # 省略するとdefaultはNone
>>> a
# {'A': 1, 'B': 2, 'C': 3, 'D': 4, 'E': None}
複数の値を一括して追加するときは、update(other)メソッドを使う。
otherに既存のキーが含まれていると、otherの値で上書きする。
>>> a = {'A': 1, 'B': 2, 'C': 3}
>>> b = {'B': 4, 'D': 5}
>>> a.update(b) # 'B'はaに既存なので2->4に上書き、'D'は存在しないので追加
>>> a
# {'A': 1, 'B': 4, 'C': 3, 'D': 5}
なお、otherは1次元の要素数が2の2次元配列構造であれば、dictでなくてもいい。
この場合、1次元の要素はキー, 値として解釈される。
>>> a = {'A': 1, 'B': 2, 'C': 3}
>>> b = (('B', 4), ('D', 5)) # tupleでもいい
>>> c = [('E', 6), ['F', 1]] # listでもいいし、listとtupleが混ざっててもいい
>>> a.update(b)
>>> a
# {'A': 1, 'B': 4, 'C': 3, 'D': 5}
>>> a.update(c)
>>> a
# {'A': 1, 'B': 4, 'C': 3, 'D': 5, 'E': 6, 'F': 1}
>>> d = (('A', 2, 4), ('G', 9)) # 1次元の要素数が2でないとエラー
>>> a.update(d)
# Traceback (most recent call last):
# File "<stdin>", line 1, in <module>
# ValueError: dictionary update sequence element #0 has length 3; 2 is required
bool
**論理値(True or False)**を扱う型。ブールと読む。
明示的にはフラグ的な振る舞いをさせる変数に使うことが多いが、暗黙的にも各種条件演算の戻り値で頻繁に使っている。
書き方(インスタンスの作り方)
True,Falseと記述すると、boolとして認識される。
名前の通りTrueは真、Falseは偽として扱われる。
>>> type(True)
# <class 'bool'>
>>> True
# True
>>> type(False)
# <class 'bool'>
>>> False
# False
bool()と書いてもFalseになる。
ただ、これは暗黙的にNoneをboolに変換した結果なので、Falseの生成が目的なら素直にFalseと書いたほうが良い。
>>> bool()
# False
他の型からの変換
boolはすべての型から変換可能。
↓↓↓19'9/9修正:コメントでご指摘いただきました。ありがとうございます。↓↓↓
ただし、数値型の0に相当する値とNone以外はTrueとなる。
ただし、数値型の0に相当する値とNone及び、空のシーケンス型とdict以外はTrueとなる。
>>> bool([])
# False
>>> bool([])
# False
>>> bool(())
# False
>>> bool(range(0))
# False
>>> bool(set())
# False
>>> bool({})
# False
↑↑↑修正終わり↑↑↑
>>> bool(1)
# True
>>> bool(0)
# False
>>> bool(0.25) # 少数でも0.0だけがFalse
# True
>>> bool(0.0)
# False
>>> bool(0+0j) # 虚数でも0.0だけがFalse
# False
>>> bool(1j) # 実部が0でも虚部が0でなければTrue
# True
>>> bool("0") # 文字列だと0の文字でもTrue
# True
>>> bool("0.0") # 少数表現でも同じ
# True
>>> bool([0]) # 要素が0だけのlistでもTrue
# True
>>> bool(None) # NoneはFalse扱い
# False