業務でデータ解析する時にPythonとPandasを使うと凄く楽だな~と思ったので、よく使う機能を備忘録的にまとめてみる
準備
インストール
とりあえずPandasがないと始まらないので、インストールする。
pip install pandas
僕は使っていないが、Anacondaだと最初から入っているらしい。
インポート
Pythonコード中に下記の通りインポートする。
import pandas as pd
慣例的にpdという名前で置換するらしい。
csvから読み込み
以下のようなcsvファイルを作ってインポートしてみる。
| Time | col1 | col2 | col3 |
|---|---|---|---|
| 12:00:00 | 0 | A | 123 |
| 12:05:00 | 0 | AA | 456 |
| 12:10:00 | 1 | AB | 789 |
| 12:15:00 | 1 | BB | 111 |
| 12:20:00 | 0 | C | 222 |
| 12:25:00 | 0 | D | 333 |
read_csv()という関数にcsvへのパスを渡すだけでデータフレームのインスタンスを返してくれる。
df = pd.read_csv("csvへのパス")
例のcsvをカレントにhoge.csvという名前で保存したとすると、以下のようになる
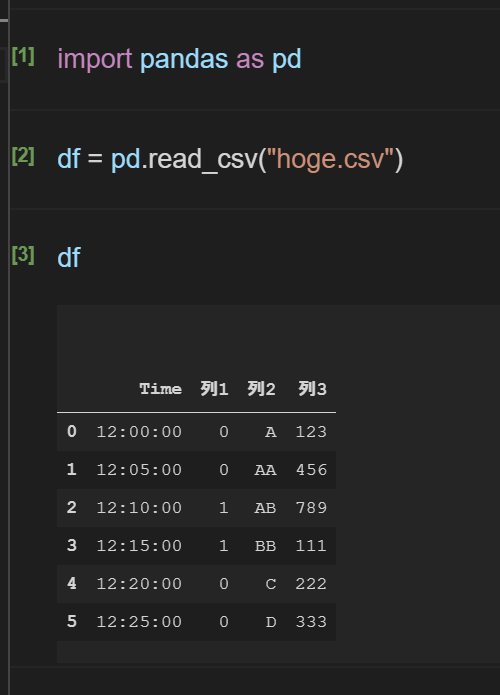
ここで、csvファイルの文字コードがutf-8以外だと、デフォルトではエラーになる。
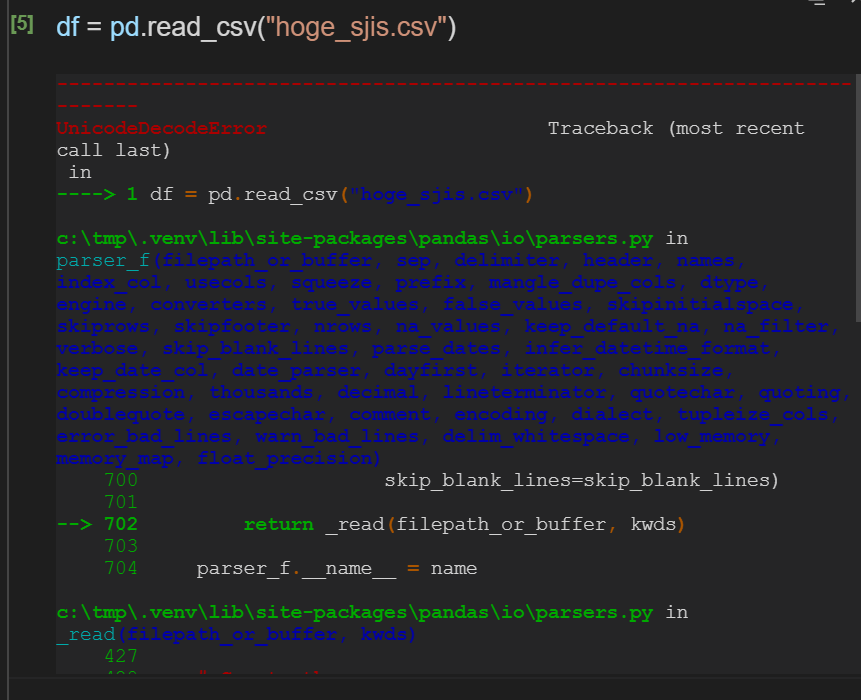
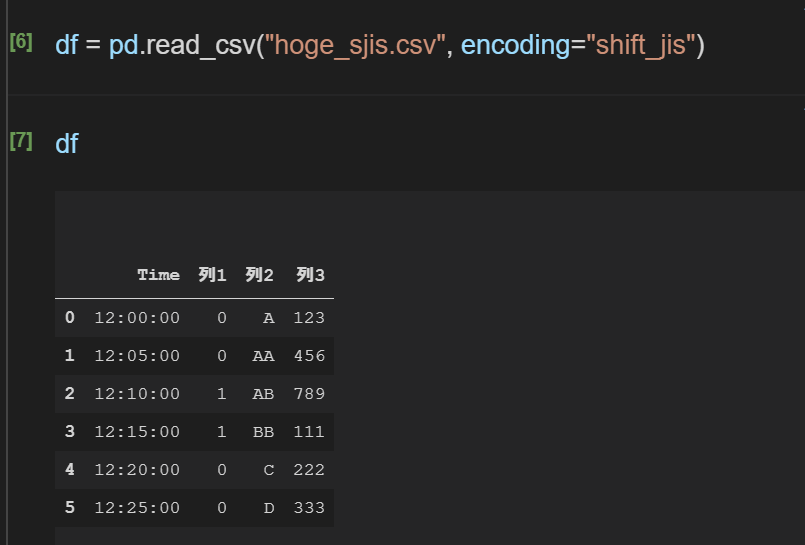
こういう場合は、ファイルの文字コードに合わせて引数encodingに指定すると読めるようになる。
df = read_csv("csvへのパス", encoding="文字コード")
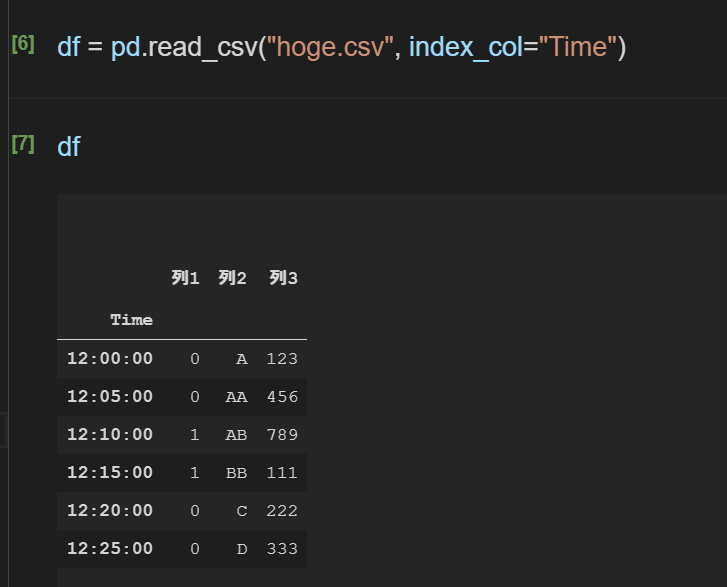
行をインデックスに指定して読み込み
何も指定せずread_csvで読み込むと、行番号を自動的に連番で振ってくれるが、csvファイル中に行のインデックスに該当する列がある場合は、それを指定することもできる。
df = read_csv("csvへのパス", index_col="インデックスにする列名")
固有のIDやログファイルの時刻列等、指定できると便利なシチュエーションは結構ある。
任意のヘッダを設定して読み込み
何も指定せずread_csvで読み込むと、1行目をヘッダとして読み込まれるが、ファイルにヘッダ行がない場合やファイルのヘッダと異なるヘッダ名にしたい時は、それを指定することもできる。
ヘッダ行を指定する場合
あまりないシチュエーションだが、ファイルの先頭以外にヘッダ行がある場合(2行目以前が不良行)は、引数headerにヘッダの行番号を指定すると、指定行をヘッダとして以降の行を読み込む。
df = read_csv("csvへのパス", header=行番号)
ヘッダ行がない場合
シチュエーション的にはこちらのほうが多い。ファイル中にデータ行しかない場合は、引数headerにNoneを設定するとヘッダなしで読み込む。
df = read_csv("csvへのパス", header=None)
この場合は、自動的にヘッダに連番を振ってくれる。
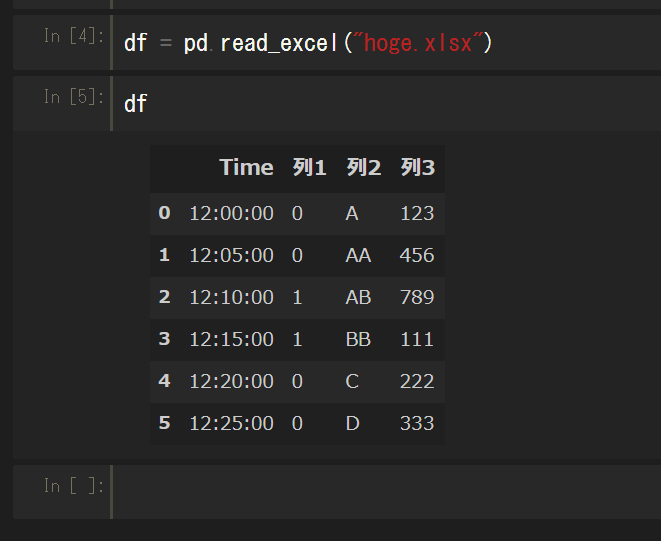
Excelファイルの読み込み
read_csvのようにExcelファイルxls,xlsxも読み込める。
df = read_excel("xlsx/xlsへのパス")
ただしxlrdという別のモジュールが必要なので、インストールしていないと下記のようなエラーが出る。
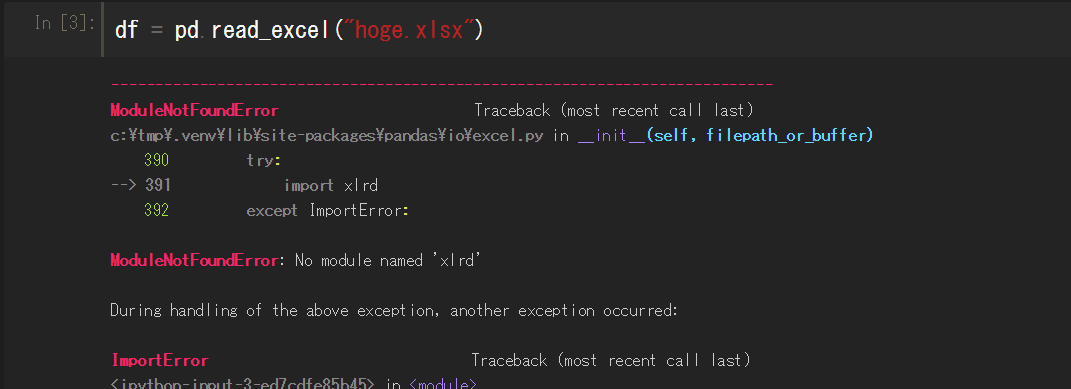
この場合は普通にxlrdをインストールすればよい。
pip install xlrd
シートの指定
オプション引数のsheet_nameにシート名orシート番号を指定することで、読み込むシートを指定できる。
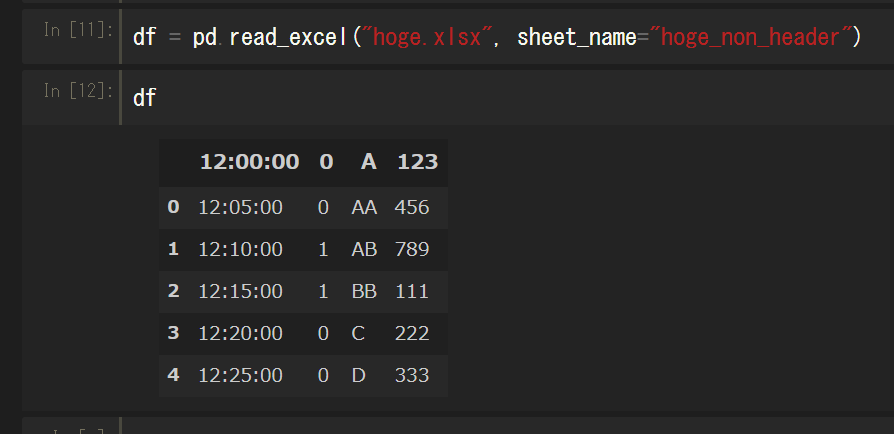
ちなみに、未指定だと自動的に1シート目になる。
他のよく使うオプション
ヘッダ指定
read_csv同様、ヘッダを指定できる。
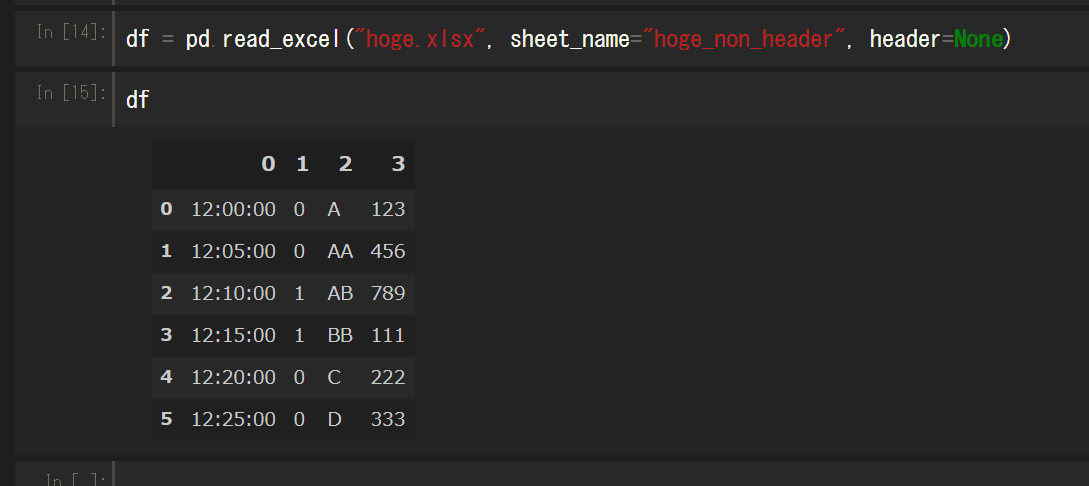
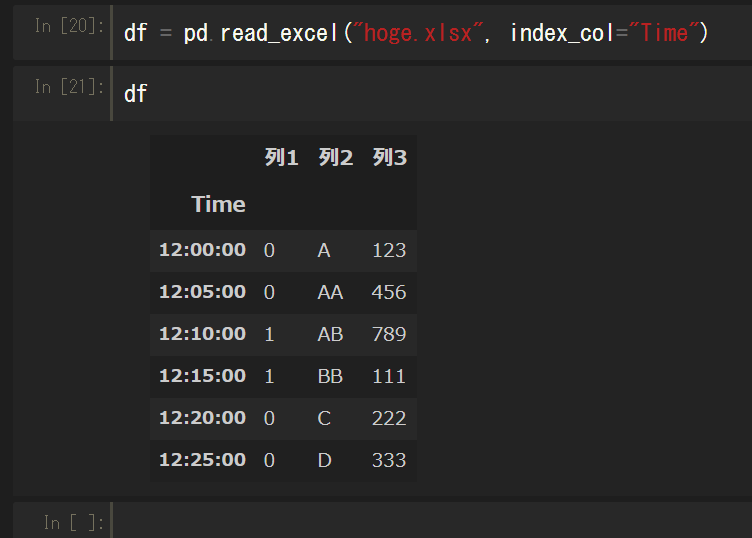
インデックス指定
インデックスもread_csv同様に指定できる。
データ抽出
所定の列だけ抽出
データフレームから列を指定して抽出するには、データフレーム名[列名]で指定すればよい。
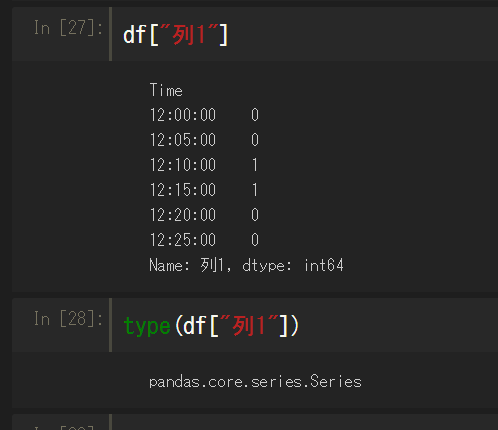
1列だけなので、DataFrameからSeriesに自動で変換される。
列名の指定にリスト形式で複数の列を指定することもできる。
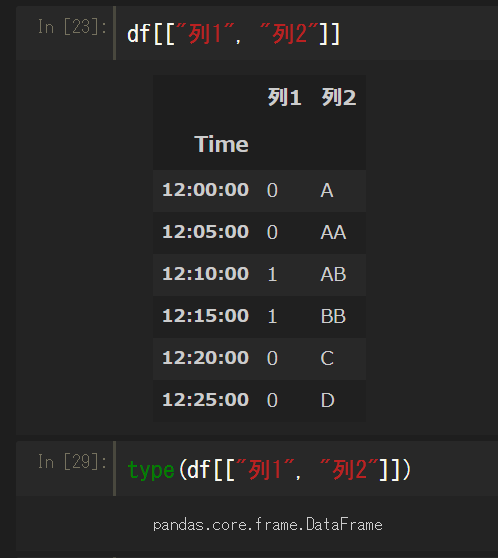
この場合は複数列なので、DataFrameのままになる。
所定の行だけ抽出
データフレームから行を指定して抽出するには、データフレーム名.loc[インデックス]で指定すればよい。
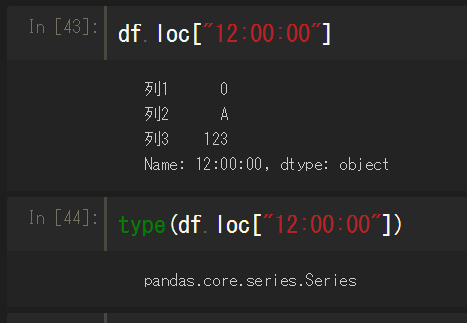
1行だけなので、DataFrameからSeriesに自動で変換される。
列同様、リスト形式で複数の行を指定することもできる。
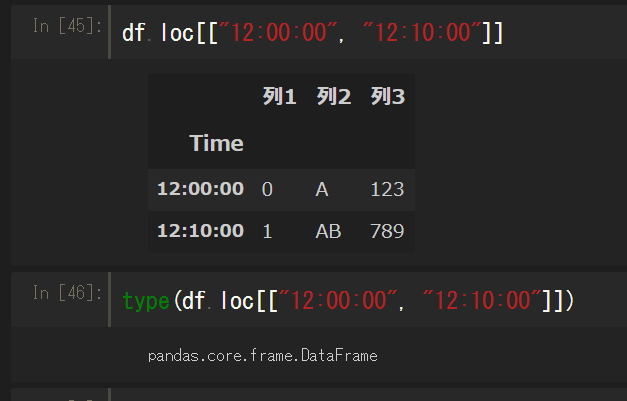
この場合は複数列なので、DataFrameのままになる。
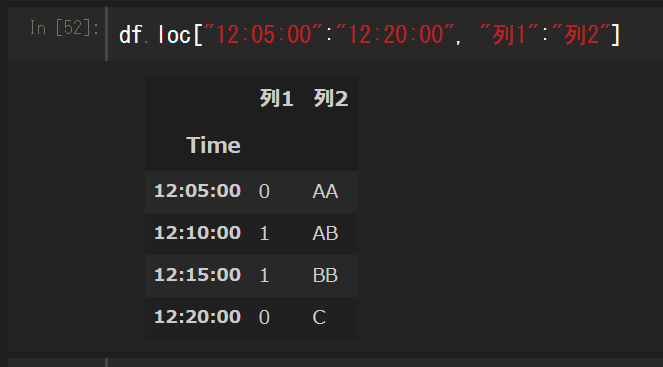
行も列も指定して抽出
行指定と同じ、データフレーム名.loc[抽出行インデックス, 列名]で行も列も自由に取れる。標準のリスト同様にスライスも指定できるのでインデックスとカラムを把握していれば、範囲指定抽出は簡単にできる。
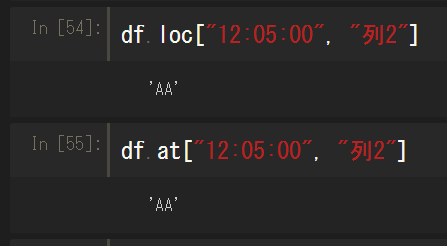
行・列を1つずつ指定すると、インデックス名・カラム名にかぶりがない限り、該当データ1件を取り出せる。この用途の場合はデータフレーム名.at[抽出行インデックス, 列名]という指定方法もあり、.atの方が処理が早いらしい。
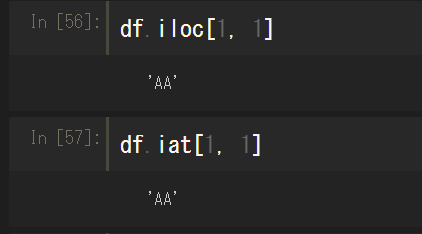
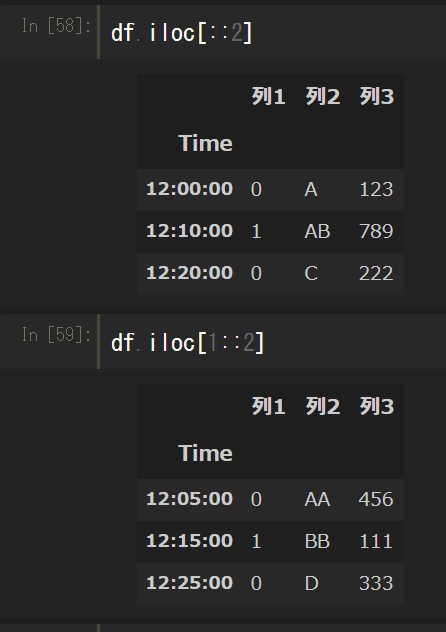
行名・列名ではなく、行番・列番で指定することもできる。この場合は.locや.atにiをつけて.ilocや.iatで指定する。
通常のスライスが使えるので、.ilocを利用すると偶数行・奇数行の抽出が簡単にできる。
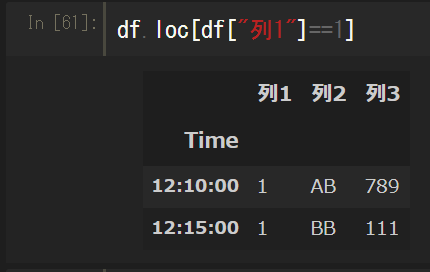
条件を指定して抽出
.locにbool値のリストを渡すと、Trueの行や列だけを抽出することができる。これを利用して、データフレームやシリーズの条件を.loc内に記述すると条件抽出ができる。
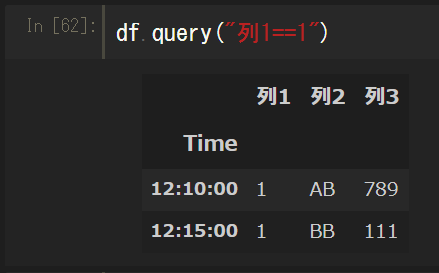
データフレームには、query()というメソッドもあり、引数に条件を文字列で渡すことでも抽出が可能。
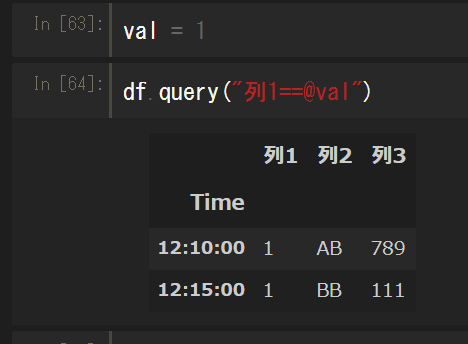
変数値を使う場合は、条件分中に@をつけることで参照できる。
終わりに
外部モジュールを積極使用しすぎると、PythonのバージョンUP等で不具合が出たりする可能性があるので、外部モジュールをむやみに使わないポリシーでやっていた。しかし、自作クラスなどでPython上だけでいくら頑張っても、工数面でもパフォーマンス面でもPandasにかなわないので、Pandasのような超有名どころの外部モジュールは使っちゃったほうがいいかなぁと思った次第。