みなさんAWSで並列分散処理をやっていますか!!
例えば

のようにEC2+SQSのJob Observeパターンを使ったり
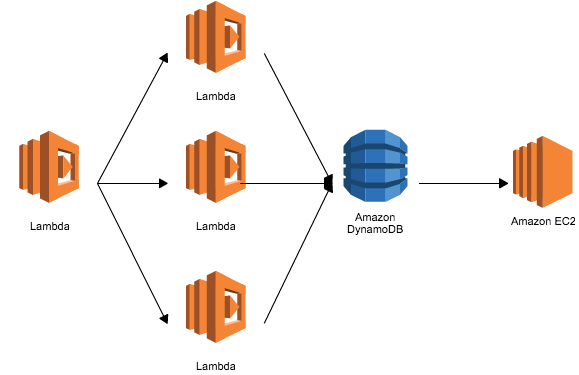
のようにLambdaを多段実行してるとか、いろいろな方法があると思います。
しかし、どの方法もデメリットがあって、EC2のリソースを使い切れなかったり、失敗時の処理がしにくかったり、並列分散処理の終了判定が難しかったりと、実装していくのに一工夫が必要なことが多いですよね。
そこで、今回はStep Functionsを使ってお手軽並列処理を実現してみます。
Step FunctionsのParallel
見出しを見て「お、もしかしてStep Functionには並列分散処理する機能あるの?」と思った方。そんなうまい話はありません。
Step FunctionsのParallelは複数のタスクを並列に呼び出すための仕組みで、単一のタスクを並列に呼び出す機能はないようです。
とはいえ、同一のタスクを複数定義しそれをParallelに定義して並列で呼び出すことはできるので、固定長のデータを並列分散処理するように定義することはできます。
exports.handler = (event, context, callback) => {
callback(null, [1, 2, 3]);
};
exports.handler = (event, context, callback) => {
callback(null, event + 1);
};
{
"Comment": "An example.",
"StartAt": "Lambda1",
"States": {
"Lambda1": {
"Type": "Task",
"Resource": "arn:aws:lambda:REGION:ACCOUNT_ID:function:Lambda1",
"Next": "Parallel"
},
"Parallel": {
"Type": "Parallel",
"Branches": [
{
"StartAt": "Lambda2_1",
"States": {
"Lambda2_1": {
"Type": "Task",
"Resource": "arn:aws:lambda:REGION:ACCOUNT_ID:function:Lambda2",
"End": true
}
}
},
{
"StartAt": "Lambda2_2",
"States": {
"Lambda2_2": {
"Type": "Task",
"Resource": "arn:aws:lambda:REGION:ACCOUNT_ID:function:Lambda2",
"End": true
}
}
},
{
"StartAt": "Lambda2_3",
"States": {
"Lambda2_3": {
"Type": "Task",
"Resource": "arn:aws:lambda:REGION:ACCOUNT_ID:function:Lambda2",
"End": true
}
}
}
],
"End": true
}
}
}
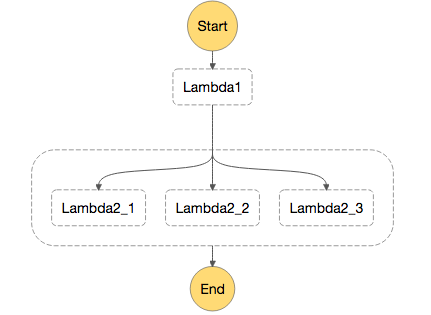
しかし、長さが動的だったり、数千、数万の量になるようなものだと必要な分タスクを定義するのが難しく、あまりスマートとは言えません。
そこで、Step Functionsで呼び出されるLambdaからStep Functionsを動的に生成して、データの長さに依存せずに実行できる仕組みを作成します。
Step Functionsでデータの長さに依存しない並列分散処理
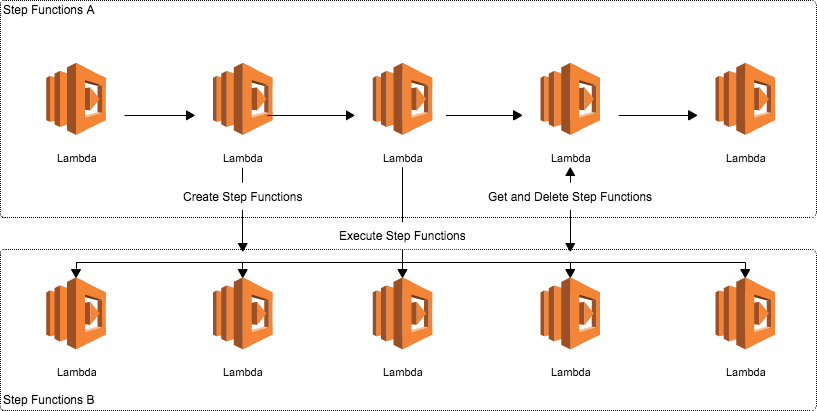
構成としては上記のようになります。
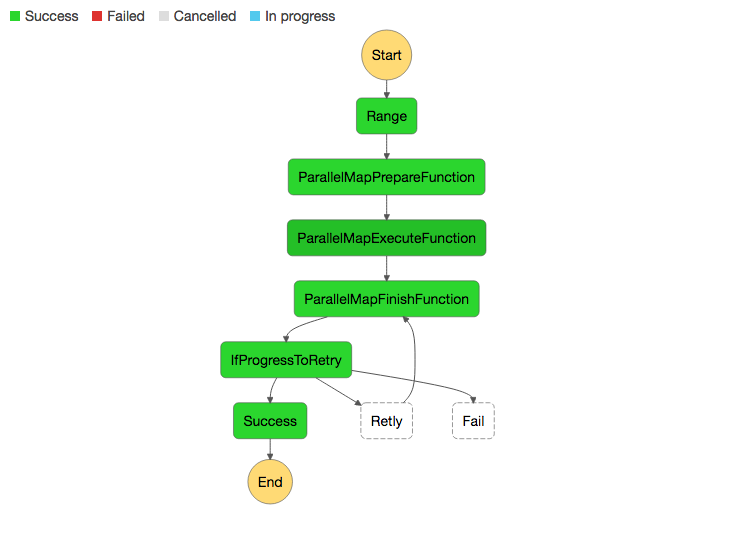
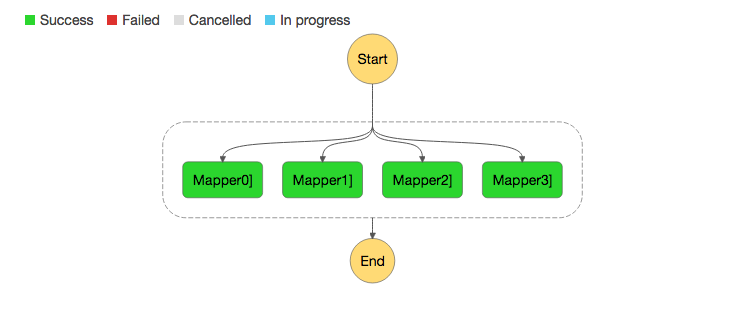
最終的に出来上がるStep Functionsのフロー図が上記です。
フロー図をベースに解説していきます。
Range, Mapper
Rangeは配列を返す開始点のLambdaで、Mapperは並列処理を行うLambdaです。
/* @flow */
'use strict';
let _ = require('lodash');
exports.handler = (
event/*: mixed */,
context/*: LambdaContext */,
callback/*: LambdaCallback */) => {
if (typeof event !== 'number') {
throw new TypeError(`Invalid arguments: '${JSON.stringify(event)}' is not a number.`);
}
callback(null, _.range(1, event));
};
/* @flow */
'use strict';
exports.handler = (
event/*: mixed */,
context/*: LambdaContext */,
callback/*: LambdaCallback */) => {
if (typeof event !== 'number') {
throw new TypeError(`Invalid arguments: '${JSON.stringify(event)}' is not a number.`);
}
callback(null, event + 1);
};
今回は何の処理は重要ではないので、シンプルな実装にしています。
ParallelMapPrepareFunction
ParallelMapPrepareFunctionはStep Functionsを動的に生成するためのLambdaです。
/* @flow */
'use strict';
let _ = require('lodash');
let AWS = require('aws-sdk');
let uuid = require('node-uuid');
let sf = new AWS.StepFunctions();
exports.handler = (
event/*: mixed */,
context/*: LambdaContext */,
callback/*: LambdaCallback */) => {
Promise.resolve().then(() => {
if (typeof process.env.MAPPER_FUNCTION_ARN !== 'string') {
throw new TypeError(`Undefined environment: 'MAPPER_FUNCTION_ARN'`);
}
if (!Array.isArray(event)) {
throw new TypeError(`Input values is not array`);
}
return {
mapperFunctionArn: process.env.MAPPER_FUNCTION_ARN,
values: event
};
}).then((data) => {
return {
name: `pm-${uuid.v4()}`,
roleArn: 'arn:aws:iam::xxxx:role/service-role/StatesExecutionRole-us-east-1',
definition: JSON.stringify({
Comment: `Pallarel map for ${context.functionName}`,
StartAt: `Parallel`,
States: {
Parallel: {
Type: `Parallel`,
Branches: _.range(0, data.values.length).map((i) => {
var branch = {StartAt: `Mapper${i}]`, States: {}};
branch.States[`Mapper${i}]`] = {
Type: 'Task',
InputPath: `$[${i}]`,
Resource: data.mapperFunctionArn,
End: true
};
return branch;
}),
End: true
}
}
})
}
}).then((params) => {
return new Promise((resolve, reject) => {
console.log('StateFunctions::CreateStateMachine', params);
sf.createStateMachine(params, (err, data) => err ? reject(err) : resolve(data));
});
}).then((response) => {
callback(null, {values: event, stateMachineArn: response.stateMachineArn});
}).catch((err/*: Error | mixed */) => {
if (err instanceof Error) {
callback(err);
} else {
callback(new Error(err));
}
});
};
前処理のRangeで渡された配列の長さだけ、Step Functionsのタスクを定義して作成をします。
今のところ1,000並列まで作りましたが、今回の内容ならサイズ制限にはかからないようです。
ParallelMapExecuteFunction
ParallelMapExecuteFunctionは作成したStep Functionsを実行するためのLambdaです。
/* @flow */
'use strict';
let AWS = require('aws-sdk');
let sf = new AWS.StepFunctions();
exports.handler = (
event/*: mixed */,
context/*: LambdaContext */,
callback/*: LambdaCallback */) => {
Promise.resolve().then(() => {
if (!event) {
throw new TypeError(`Input value is empty`);
}
if (typeof event.stateMachineArn !== 'string') {
throw new TypeError(`event.stateMachineArn is not string`);
}
if (!Array.isArray(event.values)) {
throw new TypeError(`event.values is not Array`);
}
return {
stateMachineArn: event.stateMachineArn,
input: JSON.stringify(event.values)
};
}).then((params) => {
return new Promise((resolve, reject) => {
console.log('StateFunctions::StartExecution', params);
sf.startExecution(params, (err, data) => err ? reject(err) : resolve(data));
});
}).then((response) => {
callback(null, response.executionArn);
}).catch((err/*: Error | mixed */) => {
if (err instanceof Error) {
callback(err);
} else {
callback(new Error(err));
}
});
};
ParallelMapFinishFunction
ParallelMapFinishFunctionはStep Functionsの状態を取得し、もし完了していれば作成したStep Functionsを削除するLambdaです。
/* @flow */
'use strict';
let AWS = require('aws-sdk');
let sf = new AWS.StepFunctions();
exports.handler = (
event/*: mixed */,
context/*: LambdaContext */,
callback/*: LambdaCallback */) => {
Promise.resolve().then(() => {
if (typeof event !== 'string') {
throw new TypeError(`Input value is not string`);
}
return {
executionArn: event
}
}).then((params) => {
return new Promise((resolve, reject) => {
console.log('StateFunctions::DescribeExecution', params);
sf.describeExecution(params, (err, data) => err ? reject(err) : resolve(data));
});
}).then((response) => {
if (response.status !== 'SUCCEEDED') {
return response;
}
return new Promise((resolve, reject) => {
let params = {
stateMachineArn: response.stateMachineArn
};
console.log('StateFunctions::DeleteStateMachine', params);
// sf.deleteStateMachine(params, (err, data) => err ? reject(err) : resolve(response));
resolve(response)
});
}).then((response) => {
callback(null, {status: response.status, values: response.output ? JSON.parse(response.output) : null, executionArn: event});
}).catch((err/*: Error | mixed */) => {
if (err instanceof Error) {
callback(err);
} else {
callback(new Error(err));
}
});
};
Step Functionsの実行が成功したのか失敗したのか、まだ実行中なのかに合わせて制御するのはStep Functions側で行っています。
今回は中途半端に成功時の処理を入れていますが、状態の取得とStep Functionsの削除するLambdaを分けて、状態制御をStep Functions側に切り出しても良いかもしれません。
IfProgressToRetry、Success、Fail、Retly
IfProgressToRetryはParallelMapFinishFunctionの実行結果を受けて成功、失敗、処理をします。
ここはStep Functionsで定義してして制御するようにしています。
"IfProgressToRetry": {
"Type": "Choice",
"Choices": [
{
"StringEquals": "SUCCEEDED",
"Variable": "$.status",
"Next": "Success"
},
{
"StringEquals": "RUNNING",
"Variable": "$.status",
"Next": "Retly"
}
],
"Default": "Fail"
},
"Retly": {
"Type": "Pass",
"OutputPath": "$.executionArn",
"Next": "ParallelMapFinishFunction"
},
"Success": {
"Type": "Pass",
"OutputPath": "$.values",
"End": true
},
"Fail": {
"Type": "Fail"
}
個人的に今回やっていて重要だと感じたのは、今回のようにリトライする仕組みを作るときは条件に一致したときのみリトライするようにした方が良さそうです。
一度あったのですが、Defaultをリトライにするとプログラムバグなどで無限ループになってしまって焦ってしまいました。
(LambdaとStep Functionsでクラウド破産する気はないですけど、やっぱり怖いので気をつけた方が無難だと思います)
Step Functionsの定義
最終的にできたStep Functionsの定義はこちらです。
{
"States": {
"ParallelMapFinishFunction": {
"Type": "Task",
"Next": "IfProgressToRetry",
"Resource": "arn:aws:lambda:us-east-1:xxxx:function:ParallelMapFinishFunction"
},
"IfProgressToRetry": {
"Type": "Choice",
"Choices": [
{
"StringEquals": "SUCCEEDED",
"Variable": "$.status",
"Next": "Success"
},
{
"StringEquals": "RUNNING",
"Variable": "$.status",
"Next": "Retly"
}
],
"Default": "Fail"
},
"Range": {
"Type": "Task",
"Next": "ParallelMapPrepareFunction",
"Resource": "arn:aws:lambda:us-east-1:xxxx:function:RangeFunction"
},
"ParallelMapExecuteFunction": {
"Type": "Task",
"Next": "ParallelMapFinishFunction",
"Resource": "arn:aws:lambda:us-east-1:xxxx:function:ParallelMapExecuteFunction"
},
"Retly": {
"Type": "Pass",
"OutputPath": "$.executionArn",
"Next": "ParallelMapFinishFunction"
},
"Success": {
"Type": "Pass",
"OutputPath": "$.values",
"End": true
},
"ParallelMapPrepareFunction": {
"Type": "Task",
"Next": "ParallelMapExecuteFunction",
"Resource": "arn:aws:lambda:us-east-1:xxxx:function:ParallelMapPrepareFunction"
},
"Fail": {
"Type": "Fail"
}
},
"Comment": "AAA",
"StartAt": "Range"
}
今回は省略しましたが書き込みの発生するようなリトライするようにしておけば、ネットワークエラーなど一時的な障害にも対応できるようになります。
メリット
- Lambdaのコードをシンプルに保てる(※ 重要)
- Mapperで1データを処理するコードを書けば良い
- 失敗時のリトライや終了処理はStep Functionsで定義できるのでコードにする必要がない
- Lambdaを使うためリソースを使い切ることを考えなくて良い
- EC2ではコスパを考えてリソースを使い切れるように頑張る必要があったが、その考慮は不要
- 制御のためのAWSリソースが不要になる
- リトライを考慮してSNSやSQSをはさまなくて良い
- 終了処理をするためにDynamoDBやS3などに処理結果を保存しなくてよくなった
- 終了判定の考慮も不要に
- お財布に優しい(たぶん)
- 100万回実行してもStep Functionsの費用は$50ぐらい
- Lambdaの1処理あたり$0.000001667換算で$166.7ぐらい
- 合計で$200ちょいで100万回実行できちゃう
- 何か想定してない要因はありそうな気はする
デメリット
- Step Functions的に動的に作成→実行→削除がお作法的によろしいかわからない(重要)
- ParallelMap部分の実装が面倒臭い
- 1データの大きさや件数によってはStep Functionsの生成部分で失敗しそう
- 100件のインクリメントするだけのMapperで起動から完了までに8sの時間がかかる
- 件数や処理によってはそこそこ時間かかるかも
- ウォームアップ的なことすれば何とかなる?
- リアルタイム系の処理には向かない
- 件数や処理によってはそこそこ時間かかるかも
- Step Functionsの制限、Lambdaの制限と何かしらひっかかりそう
- Step Functionsは変更不可なので何かしらのアップデート方針を考える必要がある
他にも実運用をすると何かひっかかりそうなところはありそうだなとは感じています。(誰か人柱お願いします)
おわりに
Step Functionsがきたことでこれまで使ってきたパターンを変更したり、実現することが難しかったことができるようになってきました。
こういった分散並列処理がデフォルトでサポートしてもらえると、さらにシンプルなサーバレース構成を作れるので次のアップデートには期待したいですね!