元ネタ
記事の中では、以下のように書かれています。
“私”を歌うのが中島さんで“あなた”を歌うのがユーミン。
“夜”“泣く”“嘘”を歌うのが中島さんで、
“朝”“愛”“好き”を歌うのがユーミンなんです。
確かに、そんな気がします。
あまり詳しくない私にはそうおもいます。
元記事のダブルクォーテーションの気持ち悪さ以外は、すんなりですね。
せやろか?
でも少しキャッチーすぎる気がします。
本当にそうなのか、少し分析して、自分なりのコピーをつけてみます。
せっかくなので、普段使わない、ライブラリのお勉強も兼ねてやってみます。
どう進めるか
- スクレイピングして
- 形態素解析して
- いい感じに出力する
これなら、IT業界の隅っこで体育座りをしている、私にもできるかもしれません。
いい感じのライブラリを作ってくれる人に感謝です。
スクレイピングして
スクレイピングはいつもお世話になっている、beautiful soupです。
さくっと歌詞をスクレイピングしますが、少し気になることがあります。
著作権です。
歌詞の著作権について
ふむふむ、データ分析に使うぐらいなら問題なそうです。
ただ、歌詞を垂れ流すと問題です。
最近gitに挙げることが多いですが、うっかりscraping後の元データを上げたりすると、
↓にエントリーすることになりそうなので気を付けます。
https://qiita.com/advent-calendar/2020/yarakashi-production
形態素解析して
今までMeCab使うことが多かったのですが、ここぞとばかりに、普段からストックして気になっていた、
GINZAを早速つかってみます。
日本語NLPライブラリGiNZAのすゝめ
さっそく横道にそれて 依存構造解析・可視化をしてみます。
なぜなら仕事でほとんど使わなからです、こういうの憧れます・・・・・・
ワイ「ユーザー辞書、手で作るの苦しいです。サンタマリア」
ある晩象は象小屋で、三把の藁をたべながら、十日の月を仰あおぎ見て、
「苦しいです。サンタマリア。」と云ったということだ。
出典:青空文庫 オツベルと象 宮沢賢治
象の渾身の一言もこんな感じで可視化できます。

なにこれ?3行っすか?
nlp = spacy.load('ja_ginza')
doc = nlp('ある晩象は象小屋で、三把の藁をたべながら、十日の月を仰あおぎ見て、「苦しいです。サンタマリア。」と云ったということだ。')
displacy.serve(doc, style='dep')
形態素解析に戻る
サラリーマンとしては象に激しく同情しますが、涙をぬぐってGINZAでの作業を進めます。
形態素解析でやりたいこと、品詞と基本型に戻すところです。
そもそも元ネタは歌詞なので、名詞だけでもいいかと思ってやってみましたが、あまりに寂しかったので
名詞、形容詞、動詞で、取得したワードは基本型に戻します。
def make_words_list(text: str) -> list:
rs = []
doc = nlp(text)
for sent in doc.sents:
for token in sent:
tag = token.tag_.split('-')[0]
if tag in ['名詞','形容詞','動詞']:
# if tag in ['名詞']:
rs.append(token.lemma_)
return rs
上記のようにspaCyも素晴らしいですが、日本語周りを整備してくれるGINZAの人たちに感謝です。
DataFrameの状態
ポイントはPandasのデータフレームというところです。
この後 nlplot を使っていい感じの可視化をしますがDataSeries直渡しができるので、非常に気持ちがいいです。
割愛してしまいましたが、titleとlyricsはscrapingで取得している状態です。
| title | lyrics | words |
|---|---|---|
| やさしさに... | いいかんじの詩 | [単語1,単語2,単語3] |
| ひこうき... | いいかんじの詩 | [単語4,単語5,単語6] |
いい感じに出力する
可視化について考えてみる
今回はnlplotを使ってみます。
これも前から気になっていたのですが、いままで使う機会もなかったので、これを機にやってみます。
- N-gram bar chart
- N-gram tree Map
- wordcloud
- co-occurrence networks 共起ネットワーク
- sunburst chart
特に3-5はいままでやったことがなく、気になります。
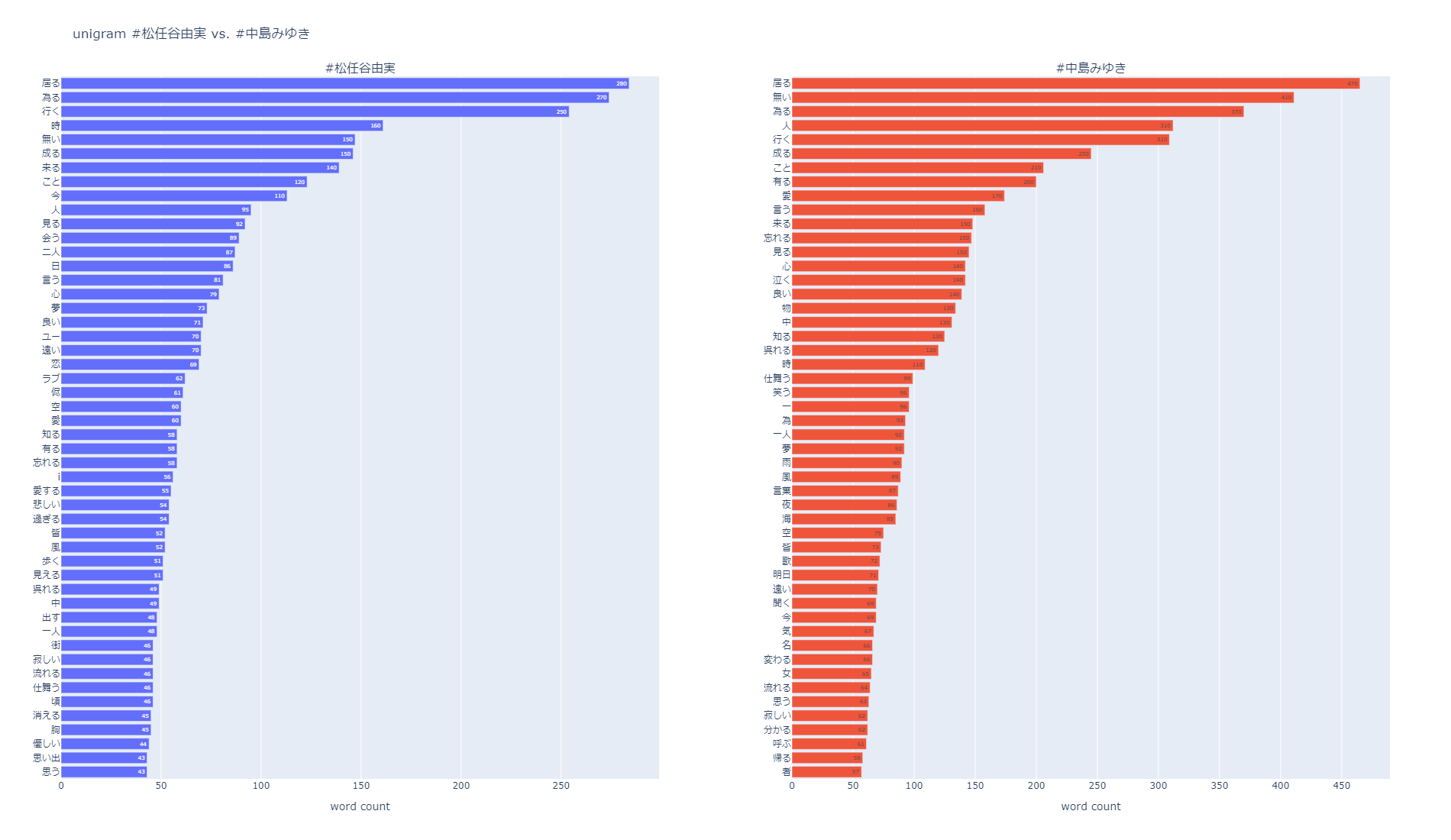
N-gram bar chart
おぉー、いいですね!
きれいにでてます。pyplotでブラウザに表示されるので、インタラクティブ性もあります。
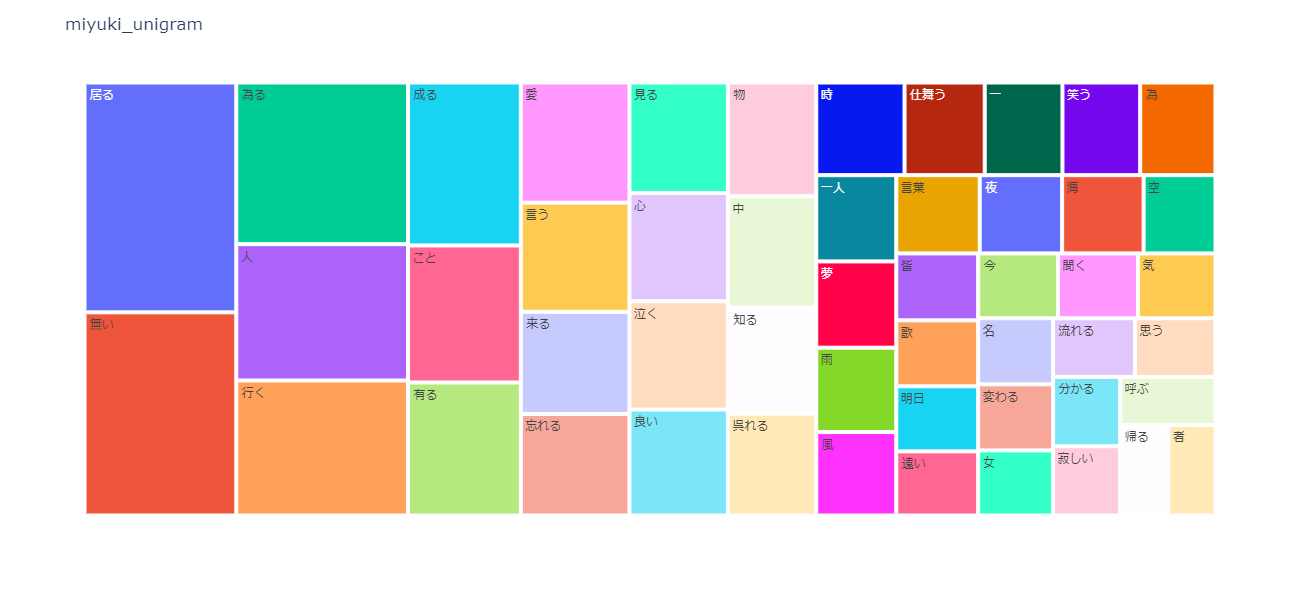
N-gram tree Map
bar chartよりも派手ですね。細かい数値というより、ざっくりした雰囲気を見たいときはこれがいいですね。
プレゼンの閑話休題的や章表紙的な使い方がいいかもしれません

wordcloud
ワードクラウドにするとこんな感じですね
ワードクラウドってある程度、長い単語がないと見栄えがしないんですね。
松任谷由美

中島みゆき

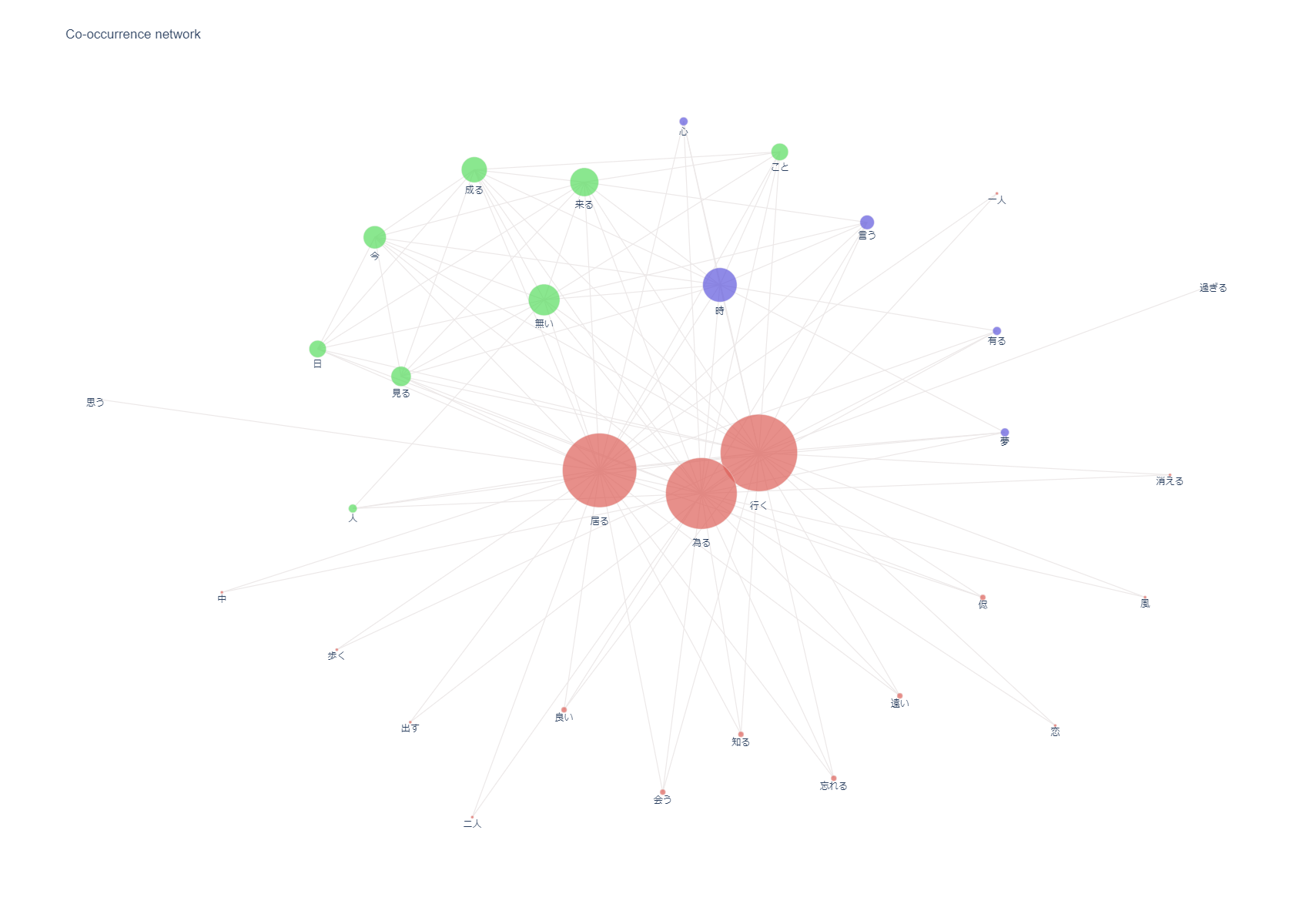
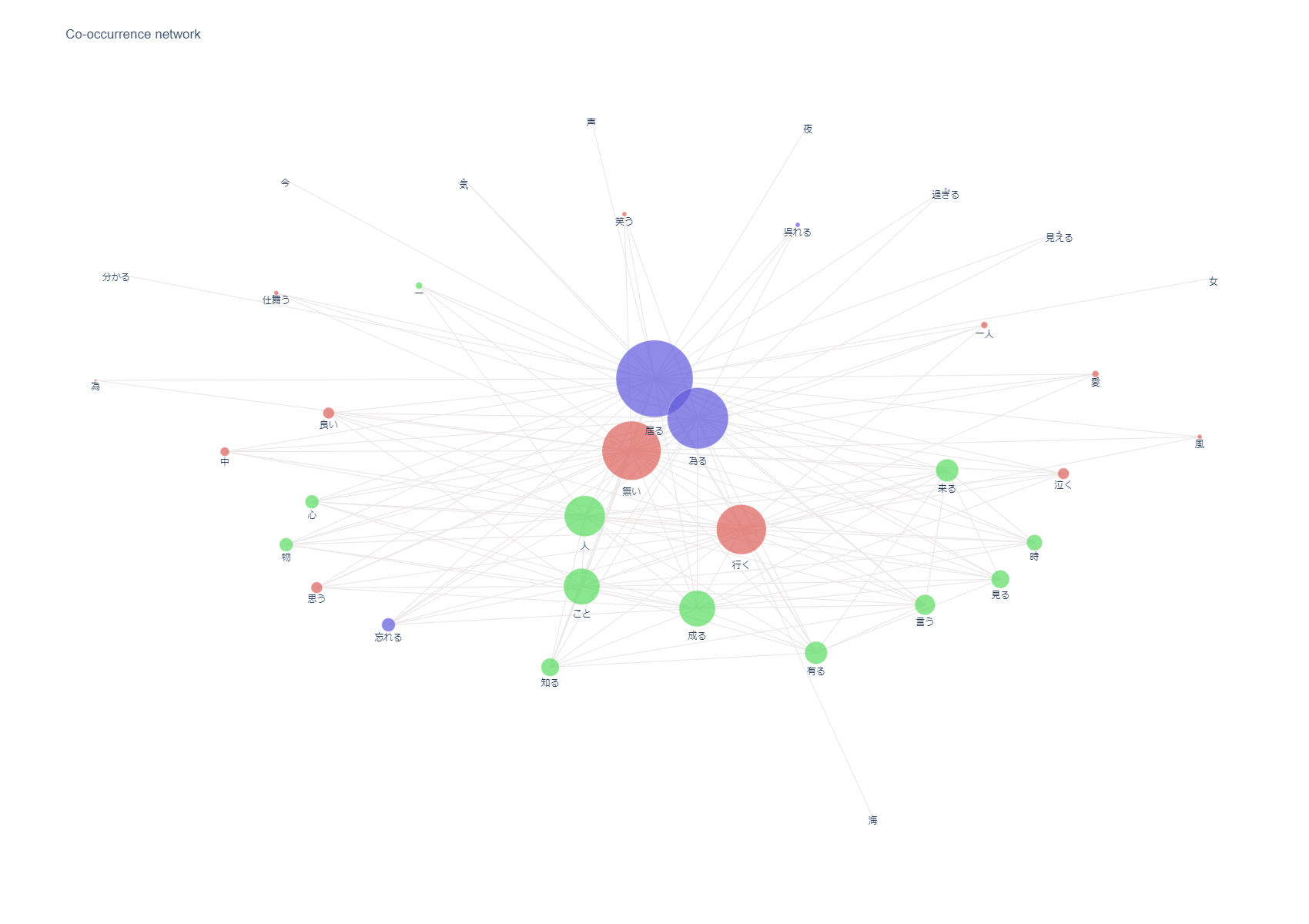
co-occurrence networks 共起ネットワーク
こちらもpyplotでブラウザに表示されるので、インタラクティブ性もあります。
今回のようなワード間の関連性をみるなら、共起ネットワークは面白いですね。
なによりも、簡単に作れるのが、うれしいですね。
松任谷由美
中島みゆき
sunburst chart
これもすごいですね、かなりきれいに出力されています。
見方もそうなんですが、もう少し強いメッセージ性があれば、いいんですが、私の手落ちですね。
ストップワード入れればよかった。。。
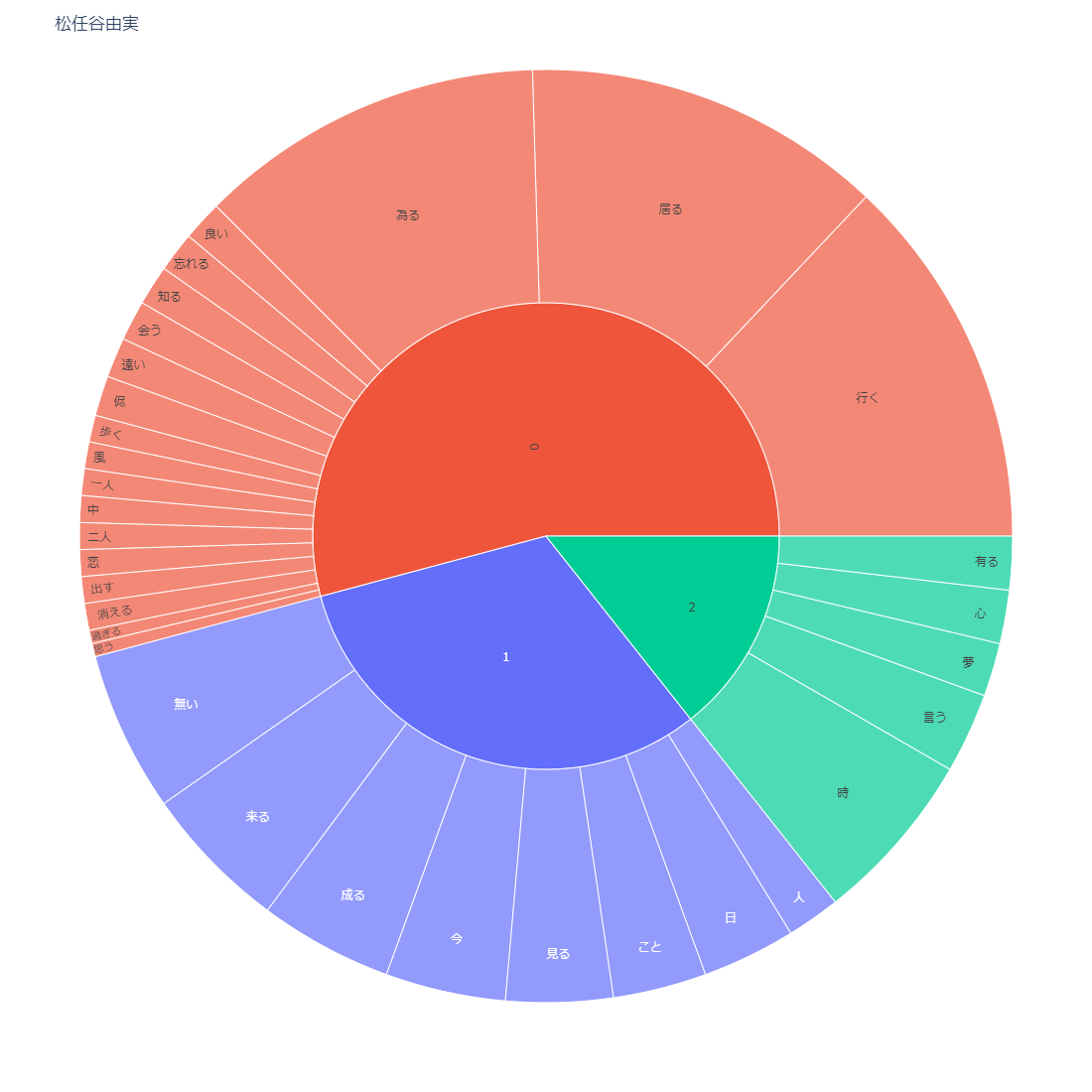
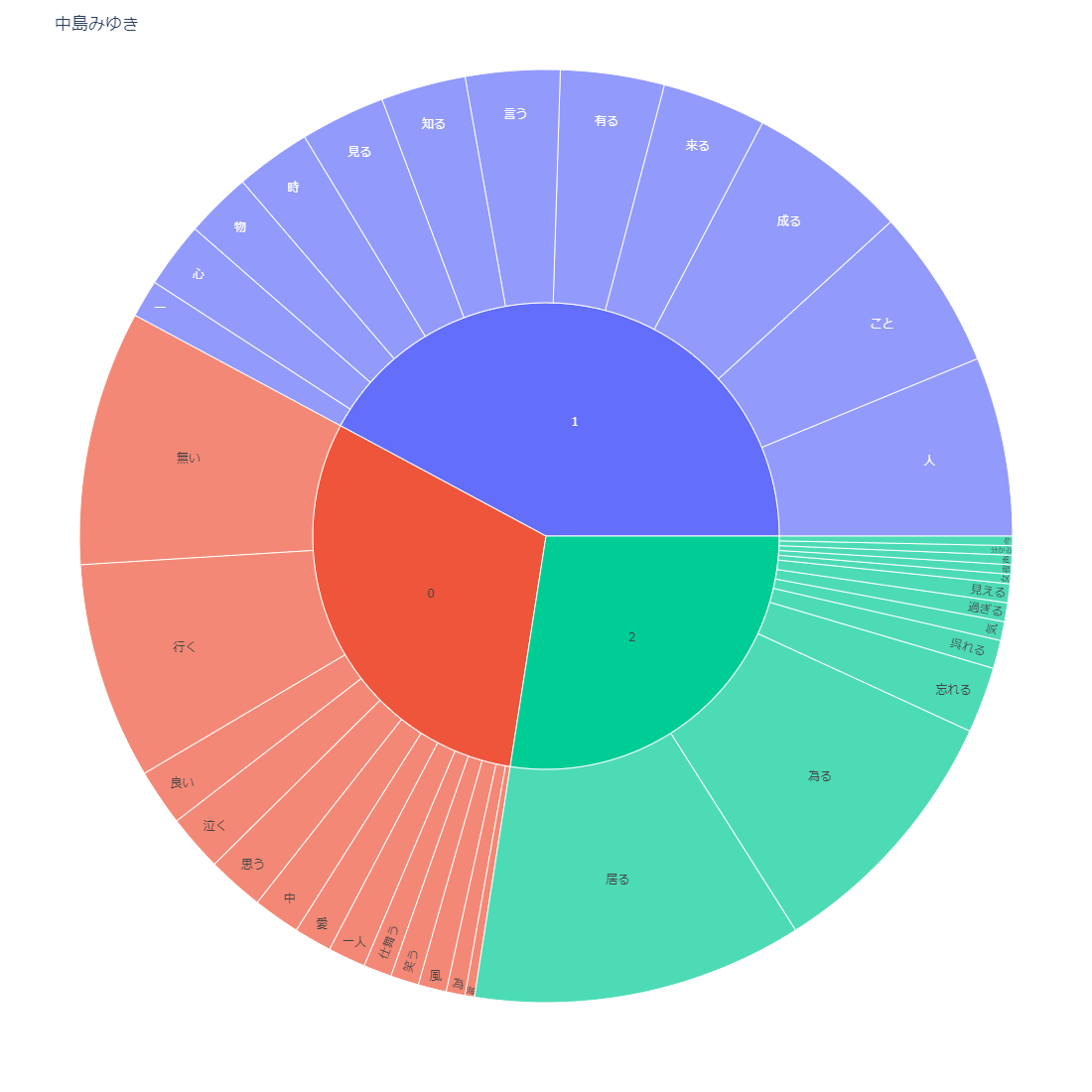
私がコピーをつけるとしたら
「ユーミンは時間を歌い、中島みゆきは場所を歌う。」 です。
分析してみて驚いたのですが、上位の単語は結構同じですよね。
っということは、件数が少ないものの方が、特徴がでている可能性がありますので、少なめの件数のものを見てみます。
ユーミンは動詞が多く、中島みゆきは名詞が多い傾向がありそうです。
そして中島みゆきは、「空」や「海」などの自然に関するワード、ユーミンは「二人」や「ユー」などの人称に関するワードが多い気がします
分析者について
年齢はユーミン世代より少し下で、「みちょぱ」と「ゆきぽよ」の区別がつかない年齢
松任谷由実さんについて
・埠頭を渡る風
・リフレインが叫んでる
が好きで
埠頭を渡る風は基準ピッチより高めの450Hzでチューニングされているという話もあります。
あのすっきりした感じは自然言語の分析ではなく、音声系の分析をかければなにかでるのかもしれませんね。
中島みゆきさんについて
・ファイト!
・浅い眠り
が好きです。たくさんのアーティスに楽曲の提供もしておられます。
github