背景
仕事でビッグデータの処理を行なっているときに、
処理が遅く困っていて犯人探しをしていて気がついたのですが、
pandasライブラリの__idxmax()__の処理が遅いことに気づきました。
もちろん、maxと比べて、そのmax値のindexを返す処理が入るので、遅くなるのは当然なのですが、
実際どのくらい遅いのか検証して見ました。
前提知識
pandasの__max()__と__idxmax()__の処理は以下の通りです。
import pandas as pd
import numpy as np
# 0以上100未満のランダムな整数の10×5のデータフレームを生成
data = np.random.randint(0,100,[10,5])
df = pd.DataFrame(data,
index=['A','B','C','D','E','F','G','H','I','J'],
columns=['a','b','c','d','e'])
print(df)
print(df.max())
print(df.idxmax())
 |
 |
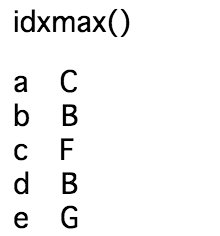 |
__max()__はcolumnごとに最大値を返し、
__idxmax()__はcolumnごとに最大値のindexを返す
という関数です。
では、データフレームを大きくして、処理時間を計測してみましょう。
max()とidxmax()の処理時間測定
import pandas as pd
import numpy as np
import time
arr = np.random.randint(0,100,[10**5,10**4],dtype='int8')
df = pd.DataFrame(arr, dtype='int8')
df.info()
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 100000 entries, 0 to 99999
# Columns: 10000 entries, 0 to 9999
# dtypes: int8(10000)
# memory usage: 953.7 MB
ts = time.time()
df.max()
te =time.time()
print('max()_time:',te-ts)
# max()_time: 10.67
ts = time.time()
df.idxmax()
te =time.time()
print('idxmax()_time:',te-ts)
# idxmax()_time: 19.08
上記の実験は、
およそ1GBのデータフレームに対して、
__max()__と__idxmax()__の処理時間を測定した結果です。
__idxmax()__が
19.08 ÷ 10.67 = 1.78倍
処理が遅いことがわかりました。
ちなみにマシンスペックは
MacBookPro 2018モデル、プロセッサ:2.3 GHz Intel Core i5、 メモリ:8 GB 2133 MHz LPDDR3
です
(会社のWindowsPCでは6倍の時間の差があったのですが。。)
もっと早くできないのか、調べるべくidxmax()の関数の中身をみてみましょう。
idxmax()のソースコード
import inspect
print(inspect.getsource(pd.DataFrame.idxmax))
こちらを実行して、帰ってきたソースコードが以下になります。
def idxmax(self, axis=0, skipna=True):
"""
Return index of first occurrence of maximum over requested axis.
NA/null values are excluded.
Parameters
----------
axis : {0 or 'index', 1 or 'columns'}, default 0
0 or 'index' for row-wise, 1 or 'columns' for column-wise
skipna : boolean, default True
Exclude NA/null values. If an entire row/column is NA, the result
will be NA.
Returns
-------
idxmax : Series
Raises
------
ValueError
* If the row/column is empty
See Also
--------
Series.idxmax
Notes
-----
This method is the DataFrame version of ``ndarray.argmax``.
"""
axis = self._get_axis_number(axis)
indices = nanops.nanargmax(self.values, axis=axis, skipna=skipna)
index = self._get_axis(axis)
result = [index[i] if i >= 0 else np.nan for i in indices]
return Series(result, index=self._get_agg_axis(axis))
ndarrayの__argmax()__関数のデータフレーム版と書かれています。
もちろん予想通りでしたので、では__max()__と__argmax()__の処理の時間を比較したいと思います。
max()とidxmax()の処理時間測定
ts = time.time()
_max = np.max(arr,axis=0)
te =time.time()
print('max()_time:',te-ts)
# max()_time: 0.85
ts = time.time()
_argmax = np.argmax(arr,axis=0)
te =time.time()
print('argmax()_time:',te-ts)
# argmax()_time: 13.70
結果は、__argmax()__が
13.70 ÷ 0.85 = 16.11倍
処理が遅いことがわかりました。
考察
・両者とも、データフレームの時より処理が早くなっていること
・maxはidxmaxに比べて、ndarrayの時の処理速度が圧倒的に早くなっていること
がわかりました。
原因として、
idxmaxは同じ最大値があった場合、最初のデータのインデックスのみ返す、という処理になっているから、
その分処理時間が時長しているような気がします。
データフレームの乱数の範囲やサイズを変化させると、この倍率もかなり変わっていくと思われるので、
定量的な話は難しいですが、
一つ言えることは、データフレーム特有の処理(__groupby__など)を使用しないのであれば、
むやみにデータフレーム化しない方がいいですね。