1 分類の評価方法
分類において、学習雨済みモデルを評価する指標で、代表的なものが以下の4つです。
- Accuracy(正解率)
- Precision(適合率)
- Recall(再現率)
- F1score(F値)
2 混合行列
上記の指標を理解するのに、混合行列と呼ばれる表が使用されます。
がんの診断をした結果、それが正しかったかどうかを表した表を例にしてみるとこんな感じになります。(図1)
| 図1 |
|---|
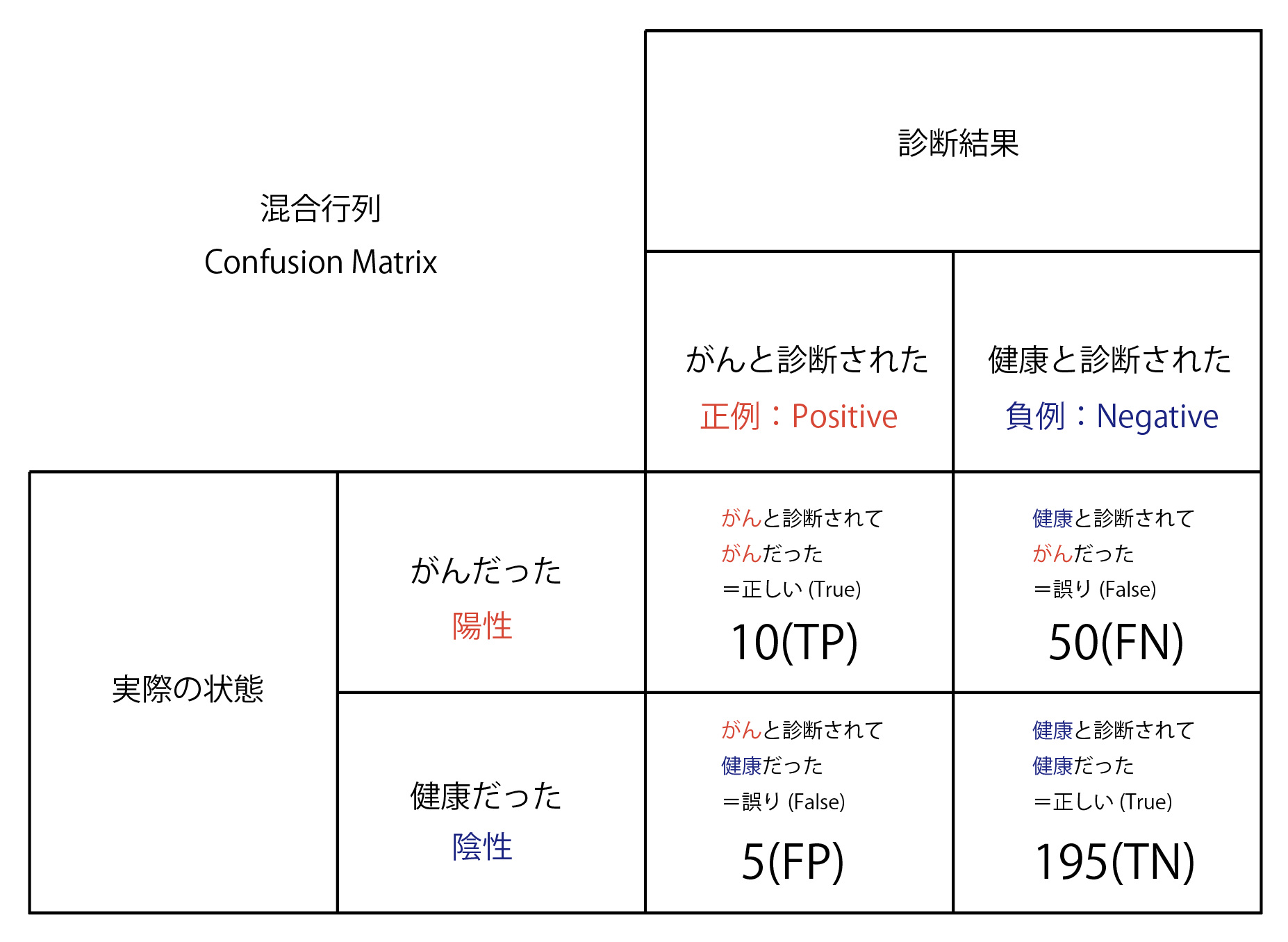 |
- TP (True Positive、真陽性):予測値を正例として、その予測が正しい場合の数
- FP (False Positive、偽陽性):予測値を正例として、その予測が誤りの場合の数
- TN (True Negative、真陰性):予測値を負例として、その予測が正しい場合の数
- FN (False Negative、偽陰性):予測値を負例として、その予測が誤りの場合の数
3 Accuracy(正解率)
Accuracyの式は以下。
Accuracy=\frac{TP+TN}{TP+FP+TN+FN}
正しく予測できたものの数を、全ての数で割ると正解率がでてきます。簡単ですね。
4 Precision(適合率)
Precisionの式は以下。
Precision=\frac{TP}{TP+FP}
正例(がん)と予測したもののうち、本当にがんだった数の割合を表します。
Precisionを高くするということは、誤診を少なくすることを意味します。
これが低いと、「あのお医者さん、めっちゃがんって診断するけど、外れること多いからあんまり当てにならんで。」と言われます。
高いと、「あのお医者さんががんと言ったら、がんだ。間違いない。」と言われます。
がんではない人をがんだと誤診したくないときは、これを高めたほうがいいでしょう。
5 Recall(再現率)
Recallの式は以下。
Recall=\frac{TP}{TP+FN}
陽性(がんがある人)のうち、がんだと正しく診断された割合を表します。
Recallを高くするということは、がんの人の見落としを少なくすることを意味します。
低いと、「あのがん検診では、健康と言われても本当はがんかもしれないから当てにならんで。」と言われます。
高いと、「あのがん検診では、がんと言われても健康な時もあるし、健康って言われたら大体健康やから安心や。」と言われます。
がんの見逃しをどうしても避けたいとき、これが高いほうがいいでしょう。
6 F1score(F値)
F1scoreの式は以下。
F1score=\frac{2\times Recall \times Precision}{Recall + Precision}
RecallとPrecisionは、どちらかを上げようとすると、もう一方が下がってしまう関係にあります。
両者のバランスをとるために調和平均で計算される指標がF値です。