本記事の内容は筆者の理解に基づいており、誤りが含まれる可能性があります。
内容に関してご指摘があれば、ぜひコメントでお知らせください。
はじめに
決定木をつかった学習のチュートリアル
kaggleのTitanicを参考にしています。
https://www.kaggle.com/competitions/titanic
学習用データと予測用データを作る
train.csv作成
write_train.py
import csv
header = ["Name", "Sex", "Age", "Sleep"]
rows = [
["Sato", "male", "10", "1"],
["Suzuki", "female", "30", "0"],
["Yamamoto","male", "89", "1"],
]
with open('train.csv', 'w', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(header)
writer.writerows(rows)
test.csv作成
write_test.py
iimport csv
header = ["Name", "Sex", "Age"]
rows = [
["Nakano", "female", "10"],
["Takahasi", "female", "60"],
["Mori", "male", "50"],
]
with open('test.csv', 'w', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(header)
writer.writerows(rows)
おまけ
インデントは必ずタブ
Makefile
all: train.csv test.csv
train.csv: write_train.py
python3 write_train.py
test.csv: write_test.py
python3 write_test.py
clear:
rm -rf *.csv
Notebook環境で実施
jupyter Notebookを使いました。
必要なライブラリとcsvを取得
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
train = pd.read_csv("/user/path/to/train.csv")
test = pd.read_csv("/user/path/to/test.csv")
# 最後に使う
Sex = np.array(test["Sex"]).astype(str)
性別をmale=0, female=1に置き換える
train.loc[train["Sex"] == "male", "Sex"] = 0
train.loc[train["Sex"] == "female", "Sex"] = 1
test.loc[test["Sex"] == "male", "Sex"] = 0
test.loc[test["Sex"] == "female", "Sex"] = 1
決定木を使って予測
from sklearn import tree
# 「train」の目的変数と説明変数の値を取得
target = train["Sleep"].values
train_features = train[["Sex"]].values
# 決定木の作成
my_tree = tree.DecisionTreeClassifier()
my_tree = my_tree.fit(train_features, target)
# 「test」の説明変数の値を取得
test_features = test[["Sex"]].values
prediction = my_tree.predict(test_features)
予測結果
# 「test」のNameを取得
name = np.array(test["Name"]).astype(str)
# Sleep列に書き出す
solution = pd.DataFrame({"Sex":Sex,"Sleep":prediction}, index=name)
# 「ans.csv」に書き出す
solution.to_csv("ans.csv", index_label = "Name")
# 表示
ans = pd.read_csv("./ans.csv")
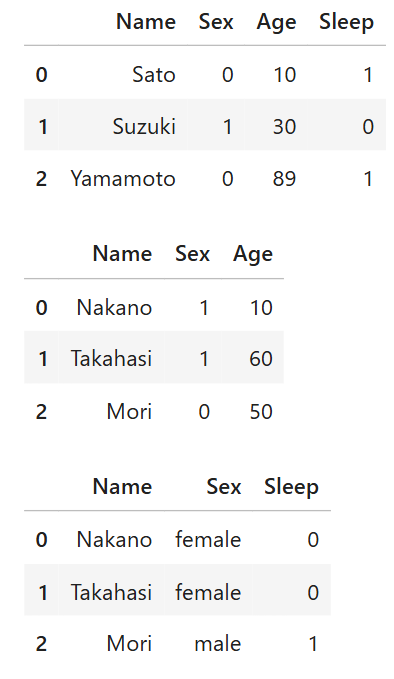
display(train)
display(test)
display(ans)
よって、男性が1、女性が0という学習データ通りの結果となった
test.csvを少し変えてみる
test_1.csv
Name,Sex,Age
Nakano,male,10
Takahasi,female,30
Mori,male,89
結果は
プログラム
test_1 = pd.read_csv("/user/path/to/test_1.csv")
Sex = np.array(test_1["Sex"]).astype(str)
test_1.loc[test_1["Sex"] == "male", "Sex"] = 0
test_1.loc[test_1["Sex"] == "female", "Sex"] = 1
test_1_features = test_1[["Sex"]].values
prediction = my_tree.predict(test_1_features)
name = np.array(test_1["Name"]).astype(str)
solution = pd.DataFrame({"Sex":Sex,"Sleep":prediction}, index=name)
solution.to_csv("ans.csv", index_label = "Name")
ans = pd.read_csv("./ans.csv")
display(ans)
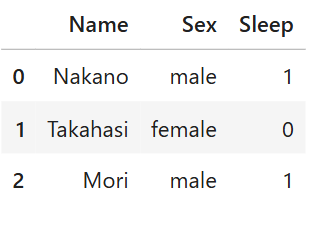
maleのみ1ですね!よって、学習はしっかりできています!
おわりに
今回は性別のみ説明変数としましたが、年齢などを考慮するとより複雑な予測が可能です!
なにが予測したいものに影響を与えているか見極めて、予測することが大事ってことが分かりました!