1.はじめに
・上の記事でYOLO v1の仕組みとYOLO v2の改良点ついて簡単に理解しました。
・今回は次のバージョンであるYOLO v3に加えられた改良点を簡単にまとめてみたいと思います。
2.YOLO v3の変化
・YOLO v2の論文発表から約一年半後、2018年にYOLO v3の論文が発表されました。
・v1、v2の制作者であるJoseph Redmon氏の最後のバージョンです。
2.1.v2とv3の「精度と速度」比較の図
縦軸:上に行くほど物体検出の精度が高い
横軸:左に行くほど物体検出の速度が速い
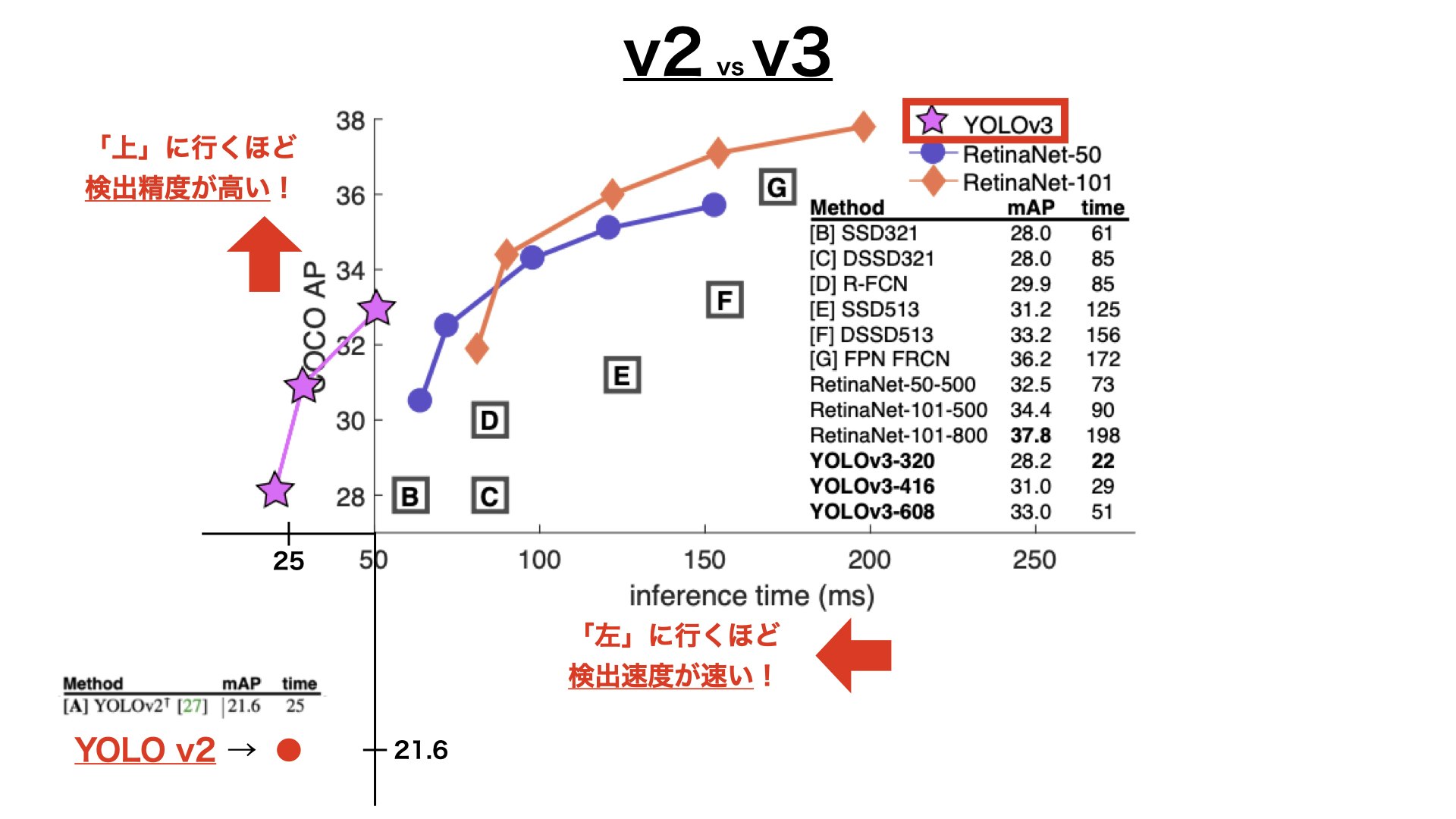
・YOLOv3-320←この「320」の部分は入力画像のサイズであり、サイズが大きくなるほど検出速度が下がることを意味します。
3.具体的な改良点
・YOLO v3では大きく分けて2つの改良点があります。
◎モデル構造の変更
◎3つのスケールでの物体予測
3.1.モデル構造の変更
YOLO v2では、、、
Darknet-19というオリジナルの構造を作って使いました。
YOLO v3では、、、
Darknet-53というさらに複雑なの構造のモデルを作って使いました。

・「19」や「53」という数字は層の深さ(どれだけの層が重なっているか)を表しています。
要は、
分析する層をたくさん増やして、「より精度の高い」学習ができる「モデルの構造」を作ったよ
ということです。

・FPS(モデルの速さを確認する値)YOLO v2と比べて下がっています。
3.1.1.Top-1、Top-5って何?
モデルの物体検出精度を評価する値
・値が高いほど、モデルの物体検出精度が「良い」を意味します。


・Top-1もTop-5も正解が多いほど、値が高くなります。
3.2.3つのスケールでの物体予測
YOLO v1では、、、
一つの画像に対して、7×7の小さな正方形に分けて各小さな正方形を分析していました。
YOLO v2では、、、
一つの画像に対して、13×13の小さな正方形に分けて各小さな正方形を分析していました。
・YOLO v3では、、、
一つの画像に対して、13×13、26×26、52×52の3つのスケールで、それぞれ各小さな正方形を分析しています。

・13×13では大きな物体を検出し、26×26では中くらいの物体を検出し、52×52では小さな物体を検出します。
・それぞれの小さな正方形に3個のバウンディングボックスをk-means法で形と大きさを決めて配置しています。((13×13)+(26×26)+(52×52))×3個=10647個のバウンディングボックスを予測している。→つまり、計算がいっぱいで速度が遅くなってる。)
・配置されるバウンディングボックスの3個のサイズはk-means法によりそれぞれ以下のように決まっています。
| スケールのサイズ | k-means法で決められた3個のアンカーボックスのサイズ |
|---|---|
| 13×13 | (10×13),(16×30),(33×23) |
| 26×26 | (30×61),(62×45),(59×119) |
| 52×52 | (116×90),(156×198),(373×326) |
・このような色々なスケールの物体を検出できるネットワークを
FPN(Feature Pyramid Networks)
と言います。

・小さなスケールの部分で小さな物体を検出し、中くらいのスケールの部分で中くらいの物体を検出し、大きなスケールの部分で大きな物体を検出し、それぞれを結合しています。
YOLOシリーズ各バージョンの簡単な違いについてのまとめ
参考サイト
・YOLO v3論文
・FPN論文