参考動画
・上の動画を参考にして、Pythonで深層学習の実装をしてみます。
・ライブラリはKerasを使用します。
データの取得
import numpy as np
import matplotlib.pyplot as plt
from keras.datasets import imdb
from keras.preprocessing.text import Tokenizer
from keras import models
from keras import layers
from keras.callbacks import EarlyStopping
from sklearn.model_selection import train_test_split
#データの呼び出し
#imdbは映画のレビュー文を集めてそれが肯定的か否定的か評価するデータ
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb.npz
16384/17464789 [..............................] - ET
499712/17464789 [..............................] - ET
1064960/17464789 [>.............................] - ET
1490944/17464789 [=>............................] - ET
2228224/17464789 [==>...........................] - ET
2834432/17464789 [===>..........................] - ET
3407872/17464789 [====>.........................] - ET
4046848/17464789 [=====>........................] - ET
4571136/17464789 [======>.......................] - ET
5210112/17464789 [=======>......................] - ET
5701632/17464789 [========>.....................] - ET
6373376/17464789 [=========>....................] - ET
7028736/17464789 [===========>..................] - ET
7520256/17464789 [===========>..................] - ET
8126464/17464789 [============>.................] - ET
8781824/17464789 [==============>...............] - ET
9338880/17464789 [===============>..............] - ET
9879552/17464789 [===============>..............] - ET
10567680/17464789 [=================>............] - ET
11141120/17464789 [==================>...........] - ET
11829248/17464789 [===================>..........] - ET
12369920/17464789 [====================>.........] - ET
12943360/17464789 [=====================>........] - ET
13533184/17464789 [======================>.......] - ET
14155776/17464789 [=======================>......] - ET
14811136/17464789 [========================>.....] - ET
15351808/17464789 [=========================>....] - ET
15892480/17464789 [==========================>...] - ET
16547840/17464789 [===========================>..] - ET
17154048/17464789 [============================>.] - ET
17465344/17464789 [==============================] - 2s 0us/step
17473536/17464789 [==============================] - 2s 0us/step
print(train_data.shape)
(25000,)
データの確認
print(train_data[0],train_labels[0])
#各番号それぞれ一つの単語を意味する
[1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65, 458, 4468, 66, 3941, 4, 173, 36, 256, 5, 25, 100, 43, 838, 112,
50, 670, 2, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167,
2, 336, 385, 39, 4, 172, 4536, 1111, 17, 546, 38, 13, 447, 4, 192, 50, 16, 6, 147, 2025, 19, 14, 22, 4, 1920,
4613, 469, 4, 22, 71, 87, 12, 16, 43, 530, 38, 76, 15,
13, 1247, 4, 22, 17, 515, 17, 12, 16, 626, 18, 2, 5, 62, 386, 12, 8, 316, 8, 106, 5, 4, 2223, 5244, 16, 480, 66, 3785, 33, 4, 130, 12, 16, 38, 619, 5, 25, 124, 51, 36, 135, 48, 25, 1415, 33, 6, 22, 12, 215, 28, 77, 52, 5, 14, 407, 16, 82, 2, 8, 4, 107, 117, 5952, 15, 256, 4, 2, 7, 3766, 5, 723, 36, 71, 43, 530, 476, 26, 400, 317, 46, 7, 4, 2, 1029, 13, 104, 88, 4, 381, 15, 297, 98,
32, 2071, 56, 26, 141, 6, 194, 7486, 18, 4, 226, 22, 21, 134, 476, 26, 480, 5, 144, 30, 5535, 18, 51, 36, 28,
224, 92, 25, 104, 4, 226, 65, 16, 38, 1334, 88, 12, 16, 283, 5, 16, 4472, 113, 103, 32, 15, 16, 5345, 19, 178, 32]
#1:肯定的、0:否定的
1
データをワンホットベクトル(文章を0か1で表したベクトル)の行列に直す
tokenizer = Tokenizer(num_words=10000)
X_train = tokenizer.sequences_to_matrix(train_data, mode='binary')
X_test = tokenizer.sequences_to_matrix(train_data, mode='binary')
print(X_train.shape)
(25000, 10000)
ラベルもnumpy配列に変換
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(train_labels).astype('float32')
トレーニングデータを更にトレーニングと検証に分割
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.1, random_state=0)
モデル作成
model = models.Sequential()
model.add(layers.Dense(32, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
#モデルの内容を表示
print(model.summary())
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape
Param #
=================================================================
dense (Dense) (None, 32)
320032
dense_1 (Dense) (None, 16)
528
dense_2 (Dense) (None, 1)
17
=================================================================
Total params: 320,577
Trainable params: 320,577
Non-trainable params: 0
_________________________________________________________________
学習処理の内容
model.compile(optimizer='Adam', loss = 'binary_crossentropy', metrics=['accuracy'])
学習の実行
history = model.fit(x=X_train, y=y_train, epochs=20, batch_size=512, verbose=1, validation_data=(X_val,y_val))
historyの中身を確認
history_dict = history.history
print(history_dict.keys())
dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])
正確度と損失の可視化
#正確度の可視化
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
epochs = range(1, len(acc)+1)
plt.figure(figsize=(12, 8))
plt.plot(epochs, acc, label='acc')
plt.plot(epochs, val_acc, label='val_acc')
plt.ylim((0,1))
plt.legend(loc='best')
plt.show()
#損失の可視化
acc = history_dict['loss']
val_acc = history_dict['val_loss']
epochs = range(1, len(acc)+1)
plt.figure(figsize=(12, 8))
plt.plot(epochs, acc, label='loss')
plt.plot(epochs, val_acc, label='val_loss')
plt.ylim((0,1))
plt.legend(loc='best')
plt.show()
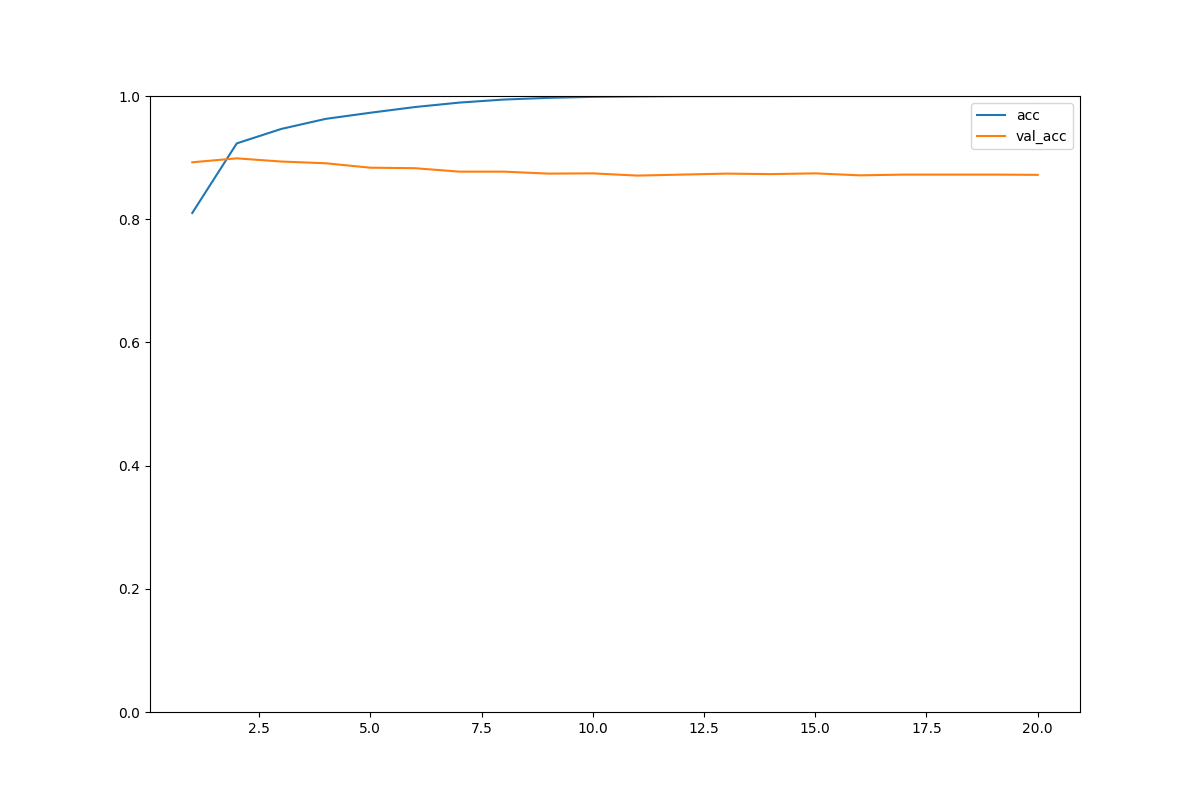
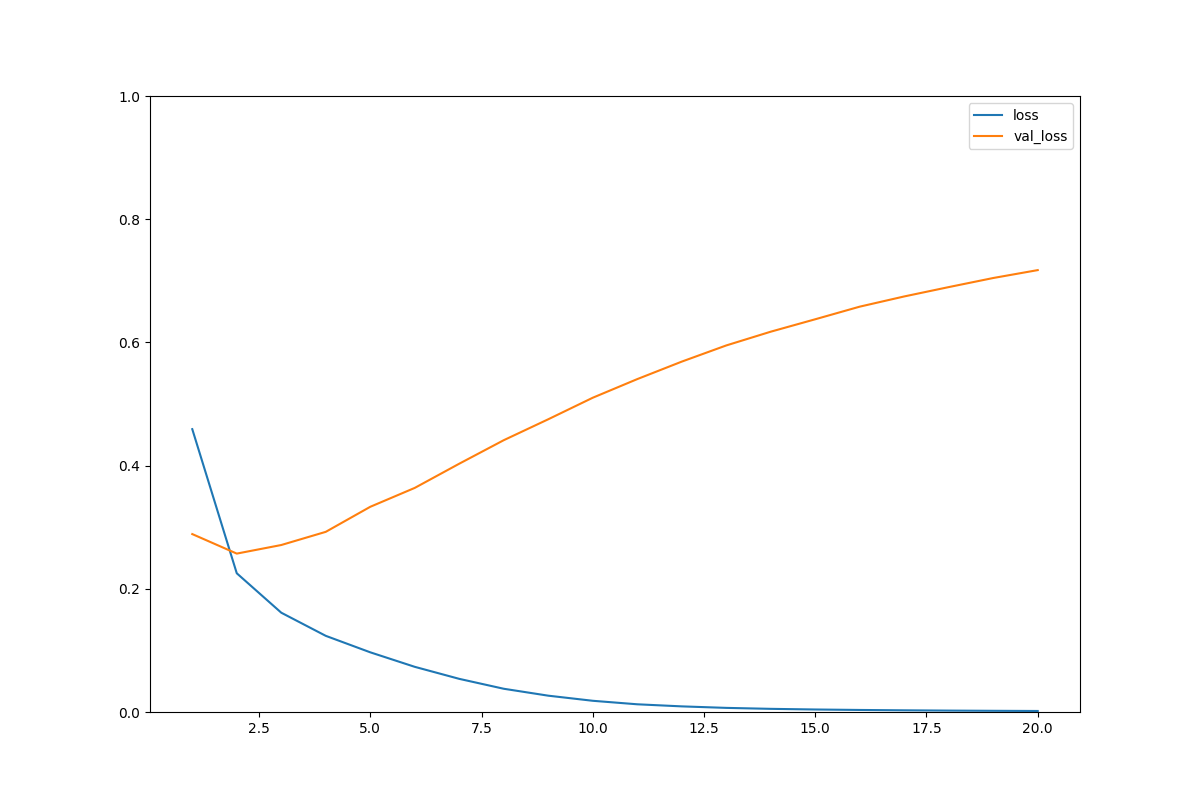
・普通のaccとlossはいい感じだけどval(検証用)にはしっかり反映されていない。
→過学習
→モデルが複雑すぎ。
・accもlossも早い段階で結果が頭打ちになる。
→アーリーストップを加える
アーリーストップを加える
#アーリーストップを加える
callbacks = [EarlyStopping(monitor='val_accuracy', patience=3)]
#学習の実行
history1 = model.fit(x=X_train, y=y_train, epochs=20, batch_size=512,
verbose=1, callbacks=callbacks, validation_data=(X_val,y_val))
テストセットを使ってスコアを見る
score = model.evaluate(X_test, y_test)
print("Test set loss: {}, Test set acc: {}".format(score[0], score[1]))
Test set loss: 0.08818113058805466, Test set acc: 0.977400004863739
アーリーストップを加えた後の学習状況
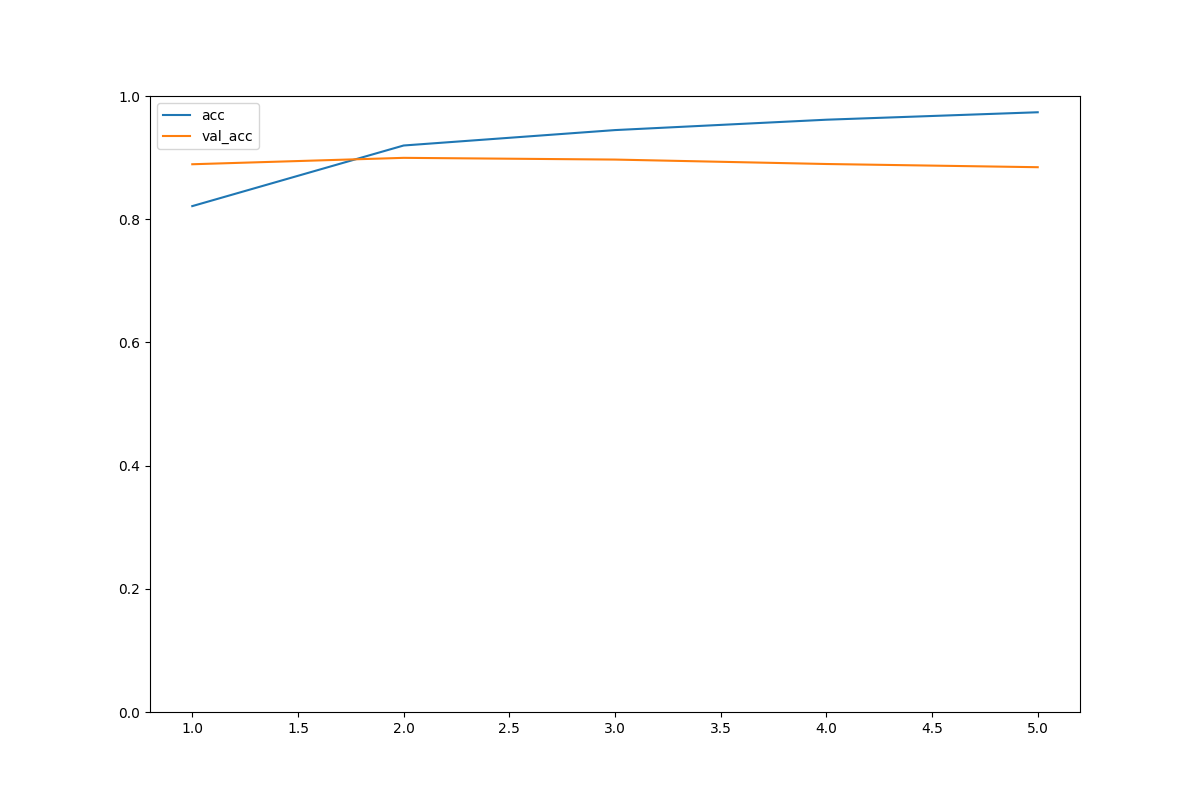
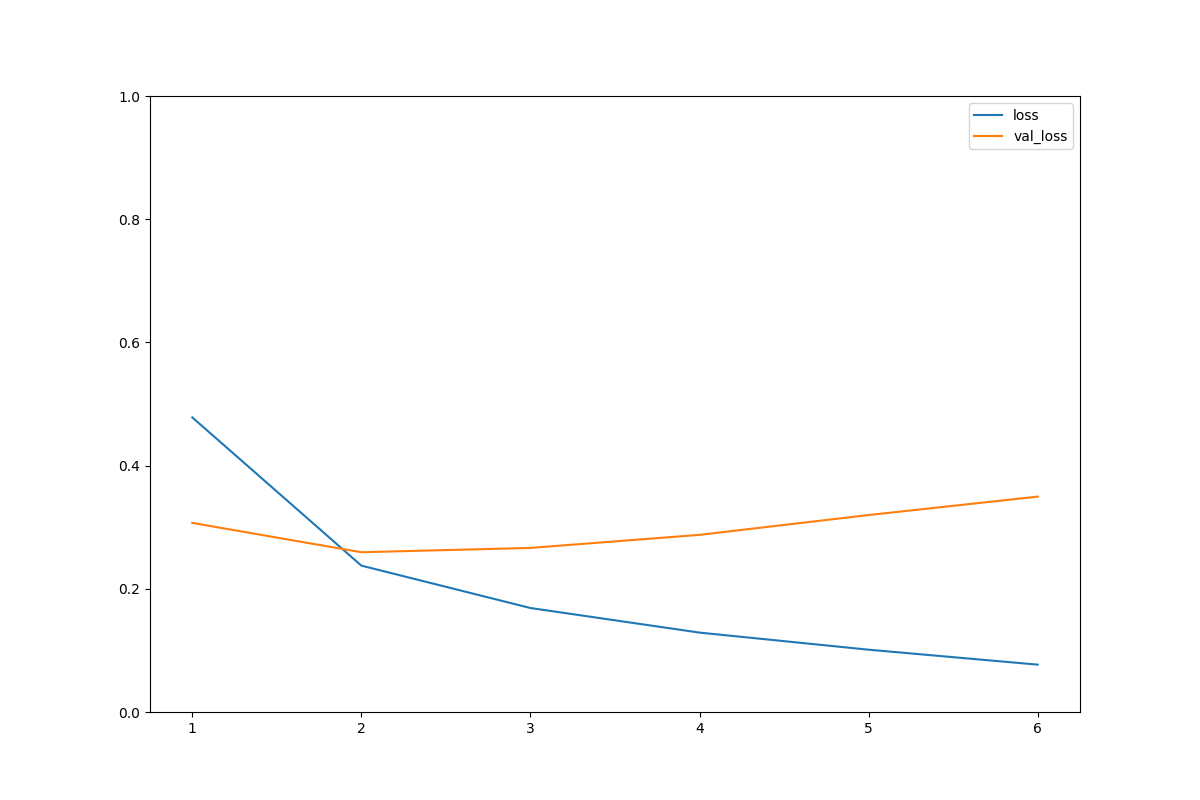
epochs=5くらいですでに評価は頭打ち。
モデルを改善してみる
model2 = models.Sequential()
model2.add(layers.Dense(1, activation='relu', input_shape=(10000,)))
#model.add(layers.Dense(16, activation='relu'))
#model.add(layers.Dense(1, activation='sigmoid'))
model2.compile(optimizer='Adam', loss = 'binary_crossentropy', metrics=['accuracy'])
#学習の実行
history2 = model2.fit(x=X_train, y=y_train, epochs=20, batch_size=512,
verbose=1, callbacks=callbacks, validation_data=(X_val,y_val))
#テストセットを使ってスコアを見る
score = model2.evaluate(X_test, y_test)
print("Test set loss: {}, Test set acc: {}".format(score[0], score[1]))
Test set loss: 0.20287659764289856, Test set acc: 0.9389600157737732
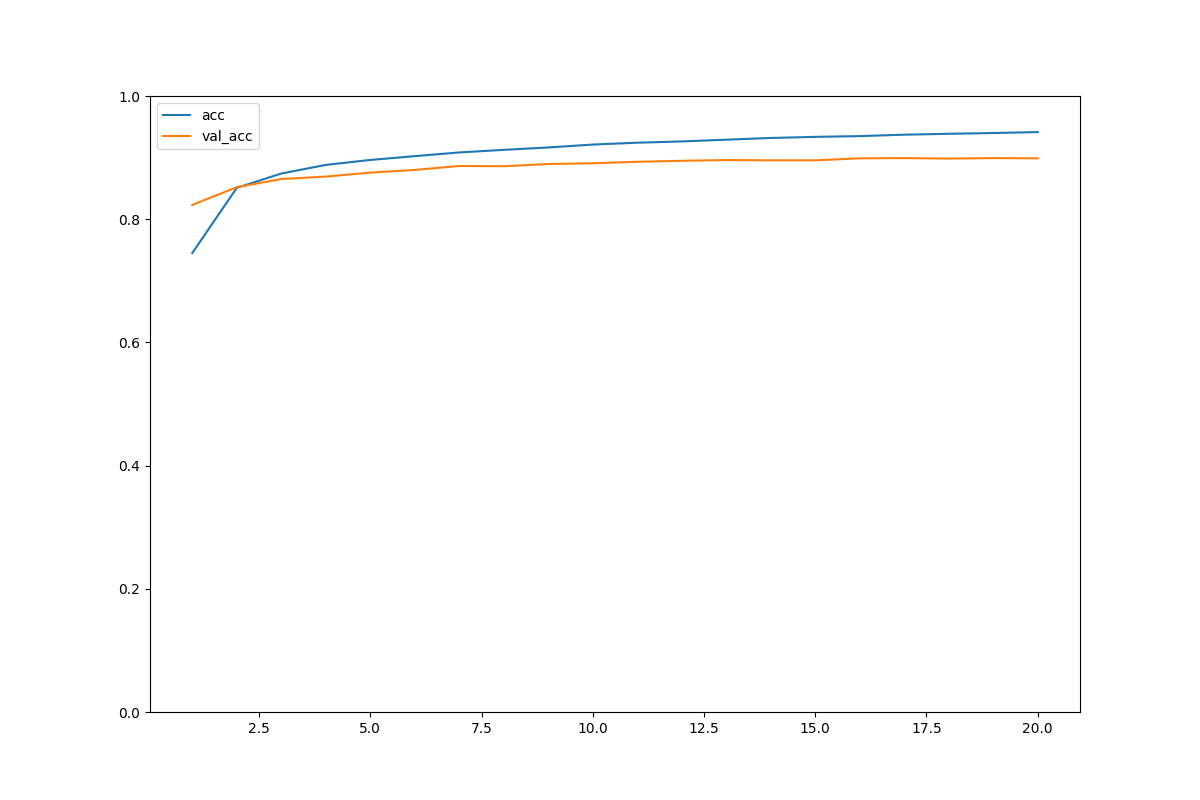
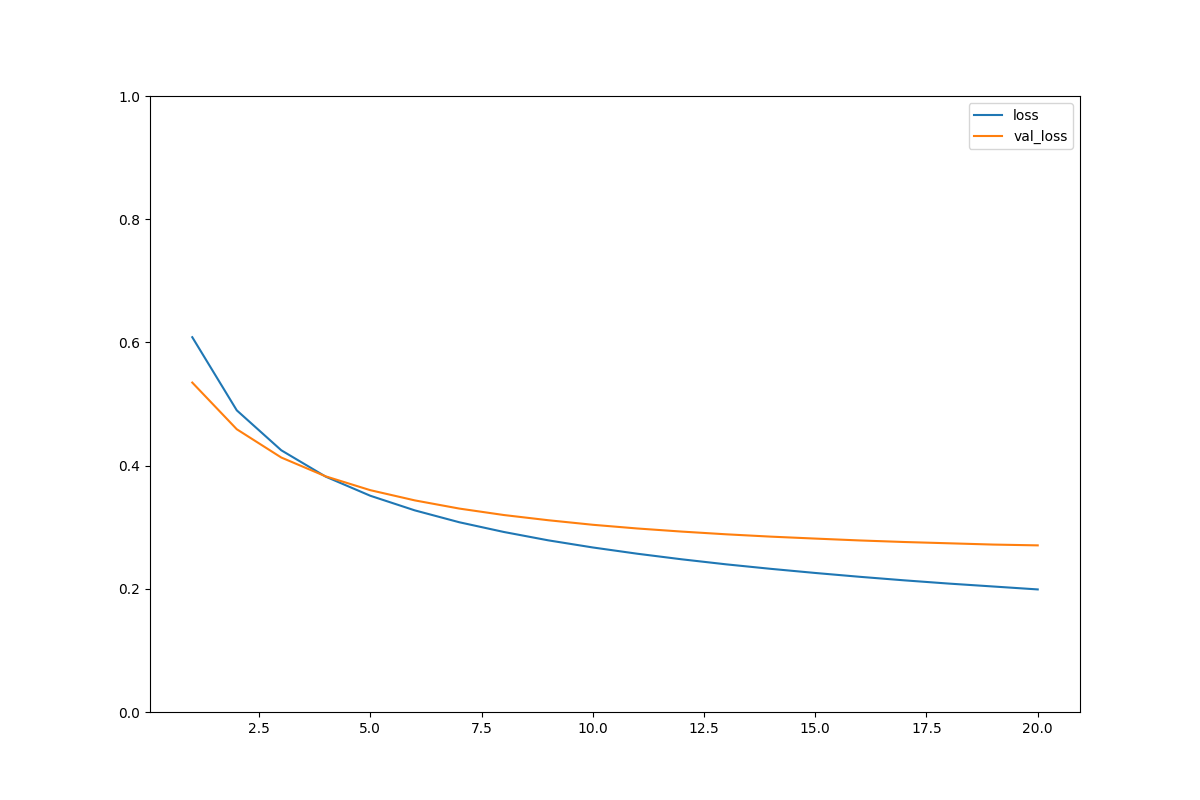
過学習は発生していない。
しかし、損失は前のモデルの方が少ない?