March 11, 2021追記:
ResearchGateに同じ内容の英語版を投稿しました。Link, DOI: 10.13140/RG.2.2.36274.32964
March 12, 2021追記:
Linux (Ubuntu 20.10)でも正しく日本語が表示できることを確認しました(Octave 5.2.10, PTB3.0.17)。
下記サンプルプログラムの10行目のフォント指定を変更する必要があります。NotoSansCJK-Regularなどお使いのシステムにインストールされている日本語対応フォントを指定してください。
はじめに
日本語を用いた心理言語学実験では当然のことながら日本語が呈示できる実験環境が必要です。近年ものすごい勢いで広まっているPsychoPyなどと比べるとPsychtoolbox(PTB)では日本語の呈示に苦労します。PTBをMATLAB上で動作させる場合にはそんなに苦労なく、PsychDemos内のDrawFormattedTextDemo.mやDrawHighQualityUnicodeTextDemo.mを見れば、何とか動きます。また、日本のPTBユーザーが必ずお世話になる「Psychtoolboxをがんばる」でも「日本語の呈示」というTipsが公開されていて、MATLAB+PTBの環境であれば特に問題はありません(図1)。しかし、OctaveでPTBを動かすとなるとそう簡単にはいきませんでした。
たとえば、MATLAB+PTBで「日本語」と表示できるプログラムをOctave+PTBで実行すると、図2のような文字化けが起こります。

図1. MATLAB + PTBで「日本語」を表示させた場合
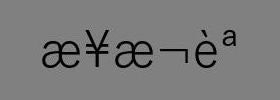
図2. 図1と同じコードで「日本語」をOctave + PTBで表示させた場合
この文字化けを解決できれば、日本語を使った心理言語学実験をPTBで行う場合にOctaveで容易に実施でき、学生にも使わせやすくなります。この報告では、この問題を解決する手順を紹介します。
環境
- Windows 10 pro (20H2)
- Octave 6.1.0
- Psychtoolbox 3.0.17
サンプルスクリプト
1 function DisplayJapaneseTextDemoOnOctave
2
3 Screen('Preferece', 'SkipSyncTests', 1);
4 HideCursor
5
6 % Prepare screen
7 scrnNum = max(Screen('Screens'));
8 mainWindow = Screen('OpenWindow', scrnNum, [128 128 128]);
9 Screen('TextSize', mainWindow, 50);
10 Screen('TextFont', mainWindow, 'Yu Gothic');
11
12 % Display "日本語でこんにちは" ("Hello in Japanese") 3 seconds
13 JpText = '日本語でこんにちは';
14 DispText = double(typecast(unicode2native(JpText, 'utf-16le'), 'uint16'));
15 DrawFormattedText(mainWindow, DispText, 'center', 'center', [0 0 0]);
16 Screen('Flip', mainWindow);
17 WaitSecs(3);
18 Screen('FillRect', mainWindow);
19
20 % Close screen
21 Screen('CloseAll')
22 ShowCursor
解説
PTBがインストールされたOctaveで上記スクリプトを実行すると、「日本語でこんにちは」が黒文字&グレー背景で3秒間呈示されます。ポイントは14行目です。MATLABユーザーの方はこの14行目を下のように書き換えれば、同じように動きます。
14 DispText = double(native2unicode(JpText));
OctaveとMATLABの違いは両者の文字コードの違いに原因があるようです。MATLABではUTF-16が、OctaveではUTF-8がそれぞれ標準で使われており、この違いのせいで文字列をコードに変換する際に異なる値が出力され、結果としてOctaveでは文字化けが起こるということのようです。そこで、Octave版のコードでは、いったんUTF-16(little endian)に変換し、それをdouble()で10進数の数値文字参照に変換するというプロセスをとっています。MATLAB版ではUTF-16への変換が必要ないので、文字列を直接double()で数値文字参照に変換しています。
今回はWindowsでの動作報告ですが、MacOSやLinuxでも基本的にはうまく動くはずです。MacOSとWindowsで14行目が同じ数値を出力することは確認しています。また、日本語以外にも中国語や韓国語などの非ASCII文字でも同じように動くことが期待されます。10行目で使用フォントを游ゴシックと指定しているので、ここをMacOS, Linuxでも使えるフォント、簡体字対応フォント、ハングル対応フォントで指定すれば良いだろうと思います。
PTBにはIsOctave()という関数が用意され、PTBがOctave上で動作しているのか、MATLAB上で動作しているのかを判定することができます。このIsOctave()関数を使えば、1つのスクリプトファイルでOctaveでもMATLABでも動作させることができると思います。上記サンプルの13, 14行目を下記に入れ替えればOKです。
JpText = '日本語でこんにちは';
%MATLABの場合
if IsOctave == 0
DispText = double(native2unicode(JpText));
%Octaveの場合
elseif IsOctave == 1
DispText = double(typecast(unicode2native(JpText, 'utf-16le'), 'uint16'));
end
===以下省略===
謝辞
Octaveでの10進数数値文字参照変換についてMATLAB、Octaveのユーザーフォーラムからは親切なアドバイスをいただきました。特にOctave Discourseのmmuetzel氏からはtypecast()を使った変換方法を教えていただき、問題が一気に解決に向かいました。ここに記して感謝申し上げます。