前回の要約、【要約】The world beyond batch: Streaming 101の元記事の続きである、The world beyond batch: Streaming 102を意訳要約したものになります。
前回と同じく、一気に読んで訳したものですので、相応に粗く、用語の統一も多分ずれがあり、流れがわかればいい内容となっていますので、その前提で。
ただ、コメントは歓迎します。ここにまとめた私自身も理解できていない点が多々あると思いますので。
以後の内容はオライリーの記事のライセンスより、CC BY-NC-SA 1.0になります。
The world beyond batch: Streaming 102
導入
もし前の記事(Streaming 101)を読んでいないなら、まず読むことをお勧めする。
以後の内容を論じる上での前提事項を説明しているし、そこで述べられた内容について相応に理解していることを前提として、本記事は書かれているから。
また、本記事の一部ではアニメーションを使用しているため、もし印刷して読もうと考えている場合にはそれについて留意いただきたい。
でははじめよう。
簡単に要約すると、前回私は3つの内容について焦点を当てていた。
1つ目は「技術定義」。"ストリーム処理"についてどういうものを意図するか、明確に定義した。
2つ目は「バッチ VS ストリーム」。2つのシステムの比較を行い、「正確性」と「時間について推測可能なツールであること」の2要素が揃えば、ストリーム処理システムがバッチ処理システムの純粋な上位互換になり得ることを説明した。
3つ目は「データ処理パターン」。バッチ処理システム、ストリーム処理システムを用いて無限のデータ、有限のデータを処理する際の共通的なパターンについて説明した。
この記事においては、前回説明したデータ処理パターンについてより詳細かつ明確に踏み込んだ上で、更にその先に焦点を当てたい。
この記事の骨子は下記の2つの章からなる。
- Streaming 101 振り返り
Streaming 101で紹介したコンセプトについて振り返り、実例について概要を示す。
- Streaming 102
Streaming 101の内容を受け、無限のデータを扱う上で重要な要素となる追加の概念について詳細を動作例を基に説明する。
この記事を一通り読むことで、頑強なout-of-orderなデータ処理に必要となる主要な原則や概念の基本についておさえることができる。
この概念をおさえたストリーム処理は伝統的なバッチ処理を超えるツールとなり得る。
具体的にどのように構成をすればいいかを示すために、Google Cloud DataflowのSDKのコードと、概念を示すアニメーションを用いる。
SparkやStormといった他のシステムに通じている方もいる中でGoogle Cloud Dataflowを用いる理由は、概念を示すために十分な表現力をもつシステムが現状存在しないため。
ただ、徐々に他のプロダクトもこの方向に向かいつつあるのはいい傾向だと感じる。
さらに、GoogleからはApache Beamというプロダクトをdata Artisans、Cloudera、Talendといった会社と共に公開し、これを用いることでよりオープンなコミュニティとエコシステムの上でこのような頑強なout-of-orderなデータ処理が可能になるだろう。
でははじめよう。
前回の概要と今後の流れ
Streaming 101で、はじめにいくつかの用語の定義を明確にしている。
有限のデータと無限のデータの違いについて明確にしている。
有限のデータソースは有限のサイズのデータを保持し、しばしば「バッチ」データとして扱われる。
無限のデータソースは無限のデータを有しており、しばしば「ストリーム」データとして扱われる。
まずはこういった形で有限だからバッチ、無限だからストリームという形で紐づけるのはミスリーディングになるので、そうではないことを示している。
その後、バッチ処理エンジンとストリーム処理エンジンの違いについても述べた。
バッチ処理エンジンは有限のサイズのデータのみを念頭に置いた設計になっており、ストリーム処理エンジンは有限のデータに加えて無限のデータに対しても考慮した設計となっている。
ここではバッチ処理、ストリーム処理は実際にそれを実行する実行エンジンにのみ紐づけて考えてほしい旨を記述している。
この定義の後、無限のデータを扱う上で2つの基本かつ重要な概念について説明している。
1つ目として、Event Time(いつそのイベントが発生したかを示す時刻)とProcessing Time(いつ対象のデータを処理したかを示す時刻)の区別がある。
もし実際にイベントが発生した時刻を基にした厳密な解析をしたい場合、Event Timeに基づいて処理を行う必要があり、Processing Timeを用いては解析に支障が出る、
2つ目として、Windowing(データを一時的な区切りを用いて分割すること)について説明した。
これは無限に発生し続け、終了しないデータソースからのデータを処理するにあたり、共通的なアプローチのうちの一つ。
基本的な例として、Windowingには固定長WindowとSlidingWindowがあることを示し、より複雑な形式のWindowingとして、Session(Windowサイズはデータによって決定し、アクセスがない時間が一定時間に達したらWindowが区切られる方式)と用途について示した。
これらの2つの考えに加えて、下記の3つについて掘り下げる。
Watermarks
WatermarkはEvent Timeベースでどこまで処理が完了したかを示す概念。
WatermarkがXの値を取った場合、「Event TimeがXより小さいデータは全て観測されている。」ことを示す。
つまりはWatermarkは無限のデータを観測している状態において、どこまで進んだかを示すメトリクスとして動作する。
Triggers
Triggerはウィンドウ出力をどのタイミングで実体化するかをいくつかの外部の状況を基準に宣言するためのメカニズム。
Triggerはいつ出力値が実体化するべきかについて柔軟性を実現する。
また、Trigger機構によってウィンドウ出力がデータが更新される毎に複数回出力するということも可能になる。
これによって、上流からのデータが変化したり、Watermarkより遅れたデータが到着した際に、投機的な出力を行える。
(実際のところ、モバイルの環境下においては、電波圏外から戻るなど、端末が記録したデータが実際に到着するまでに大きく遅れることは頻繁に発生する。)
Accumulation
Accumulationモードは同一ウィンドウ内で複数の結果が算出された場合の関係性や動作を定めるもの。これらの結果は完全に切り離されて用いられるケースもあるかもしれない。(例:セッション生存期間を超えたアクセス同士の関連など)違うモードでは、異なるセマンティクスを保持し、計算方法も変わってくるだろう。
最後に、これらの概念の関係を理解しやすくするために、ある4つの質問について再度確認してみる。これらは無限のデータを処理するあらゆるシステムで絡んでくる問いだと考えるため。
- What results are calculated?
この質問に対しては、データパイプライン上にどのような変換が存在するかが回答になる。
これには合計やグラフ生成、機械学習モデル訓練等が含まれる。
それは伝統的なバッチ処理でも同様に回答が可能。
- Where in event time are results calculated?
この質問に対しては、データパイプライン上のEvent Time Windowingの使い方が回答になる。
これにはStreaming 101で挙げられているWindowingの種別(固定長、スライディング、Session)、Windowingに関係ないユースケース(Streaming 101の時間非依存化参照、伝統的なバッチ処理もこちらに帰結することが多い)や、より複雑なWindowing、時間制限オークションといったものが含まれる。
また、これにはシステムへの到着時刻をEvent Timeとして割り振る場合、Processing Time Windowingも同様に含まれることに留意いただきたい。
- When in processing time are results materialized?
この質問に対しては、WatermarkとTriggerの使い方が回答となる。
これには無数のバリエーションが存在するが、最も共通的なパターンとしては、Watermarkを与えられたWindowの処理が完了した時点とし、Triggerを早期結果出力(投機的に発生したり、部分的な結果であってもWindowingの処理が完了する前に出力するなど)、遅延結果出力(このケースにおいては、Watermarkはどこまで処理したかの見積もりでしかなく、Watermark完了後もデータが到着するケースはある。)に用いるもの。
- How do refinements of results relate?
この質問に対しては、どのようなAccumulation方式・・・廃棄(結果が独立し、排他的な場合)、積算(遅延到着した場合、前の値に追加)、積算+後退(積算値への追加と、その前に出力した結果の見直し)を使用するかが回答となる。
これらの質問についてはこの記事の後でより詳細に掘り下げる。
また、以後はどの質問に紐づいた内容なのか、What / Where / When / How のように文字に色を付けて判別する。
Streaming 101 振り返り
はじめに、Streaming 101で示されたコンセプトを振り返ろう。
だが、今回は例と共に先ほどの質問と共に併せて説明するため、より深く掘り下げられるはずだ。
- What transformations
伝統的なバッチ処理にこの「What results are calculated?」という質問を適用した場合、答えは「変換」となるだろう。
たとえ、読者の多くは既に古典的なバッチに精通しているとしても、まずは我々はこのことについて説明する。
まずはこれが土台となり、その先に様々な概念を追加していく形となるため。
この節においては、一つの例、10個の値で構成されるキーつき整数の合計を算出する処理を以て説明する。
もし、読者がもう少し現実的な例に落とし込みたい場合、モバイルゲームの独立したスコア群を元に合計のスコアを算出する例を考えればいい。
また、利用料を監視して支払いを算出するケースでもいい。
これらの例に対して、Dataflow Java SDKの擬似コード片を組み込み、よりデータパイプラインの定義を明確にする。
擬似コードからは具体的な入出力ソースといった詳細は省き、単純な名称を用いることで例を明確にしている。
そういった要素を除けばこの後説明するコードは実際のDataflow Java SDKのものとなっている。
興味がある方のために、実際のコードの例のリンクを後で示そう。
もし読者が多少なりともSpark StreamingやFlinkを知っている場合、Dataflowのコードが何をしているかの意味を捉える上で助けとなるだろう。
はじめにDataflowを理解するための2つの基本的な概念について説明する。
- PCollections
これはデータセット(巨大なものにもなり得る)を示しており、並列の変換を通して生成されるものでもある。
- PTransforms
これはPCollectionsに適用することで、新たなPCollectionsを生成する変換を示す。
PTransformsは要素単位の変換だったり、複数の要素を統合するものだったり、または他のPTransformsの組み合わせだったりする。
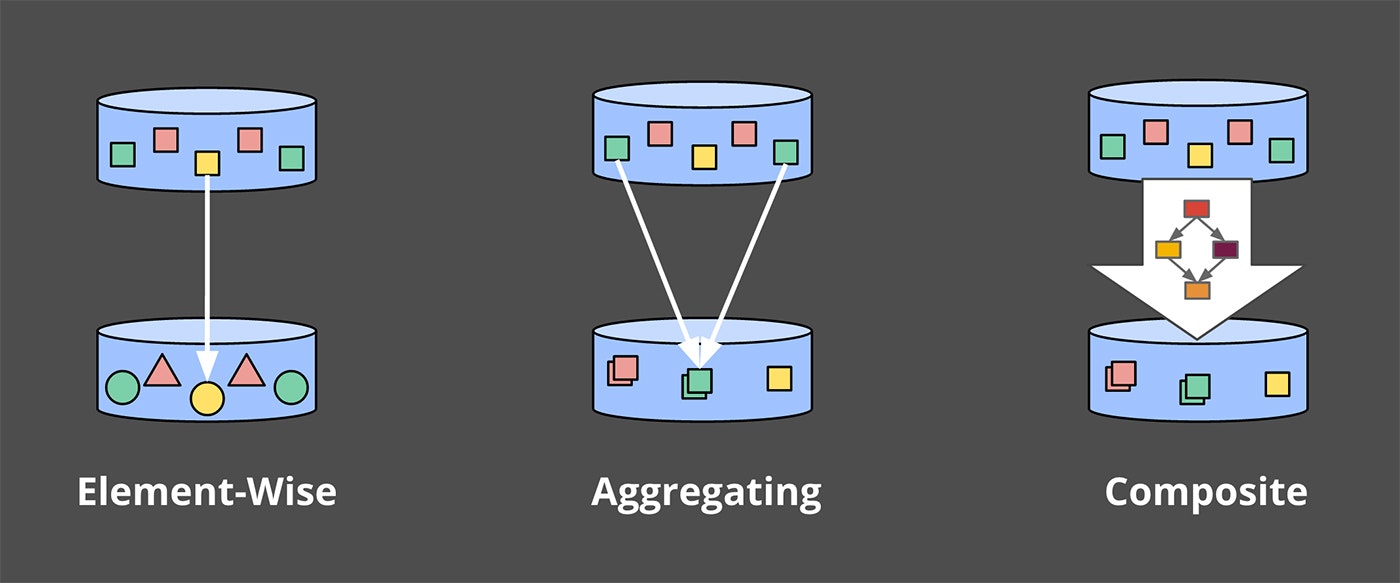
Figure 1 代表的な変換
もし読んでいて混乱するようだったり、リファレンスを確認したい場合はDataflow Java SDK docsを確認してほしい。
この例の目的は、"input"という名称の PCollection<KV<String, Integer>> (文字列のkey、数値のvalueで構成された PCollection であり、例えば文字列はチーム名称、数値はチームに対応した点数となる。)。
実際のデータパイプラインにおいては、"input" は入力ソースログを読み込んだ生レコード PCollection をパースし、変換して生成される。
以後の例ではこういったパースの過程は含まれるものの、入力元については省略する。
このようにして、パイプラインにおいてデータを読み込み、チームとスコアにパースし、チーム毎の合計点数を算出する。
そのコードは下記のように記述される。
PCollection<String> raw = IO.read(...);
PCollection<KV<String, Integer>> input = raw.apply(ParDo.of(new ParseFn());
PCollection<KV<String, Integer>> scores = input.apply(Sum.integersPerKey());
Listing 1. Summation pipeline
今後示す例において、コード片を説明した後に実際のデータに対してそのデータ解析パイプラインを流した場合どうなるか、についてアニメーションも併せて示す。
今回では、あるキーに対して10個のデータが存在する場合の例について示す。
当然ながら、実際の例においてはこの処理は複数のマシン上で並列で実行されるが、アニメーションについてはそういったことはせず、シンプルな構成として示す。
各アニメーションでは入出力データは2つの軸を保持する。
Event Time(X軸)とProcessing Time(Y軸)となる。
そのため、実際のデータパイプラインの処理の進捗は図の下から上にあがっていく形になる(アニメーションにおいては、白い線を参照)。
入力値は丸で囲まれた数値に示されており、グレーから色が変わったタイミングでそのデータがデータパイプライン上で観測・解析されたことを示す。
データパイプラインがある値を観測した段階で、それまで観測した値を基に積算を行い、最終的に結果として出力する。
アニメーションでは灰色のエリア(観測&計算が完了したエリア)の上部に積算値として表示されている。
Listing 1で示したパイプラインでは伝統的なバッチ処理と同様に見えるだろう。
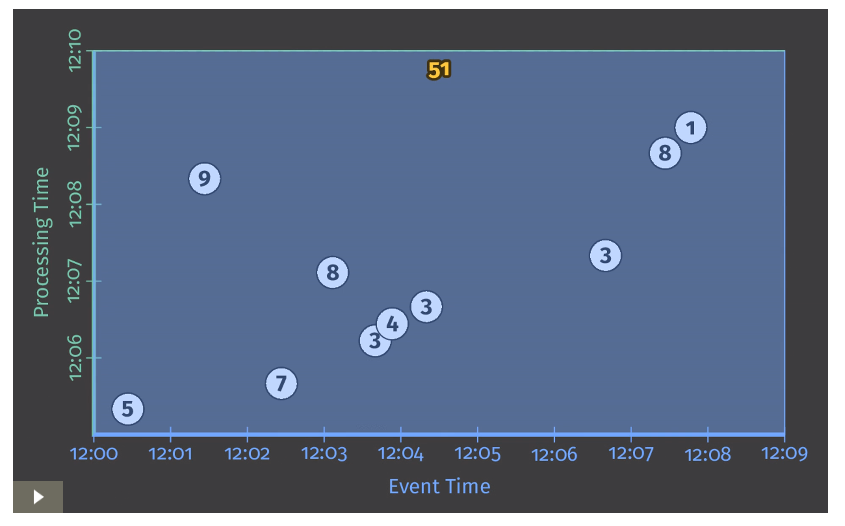
Figure 2 Classic batch processing
以後、左下に矢印のついている画像についてはアニメーションは元記事を参照
今回のケースにおいてはバッチパイプラインであるため、全入力値を受け取ってから状態の算出を行う。
(画面上部まで白い線が達した状態を指す。)
その結果、単一の出力51のみを得る。
この例においては、全時間の合計値の算出のみを行っており、Window演算などは適用されていない。
結果、出力を算出する際の長方形はX軸全体をカバーしている。
しかしながら、無限のデータソースから発生するデータを処理したい場合、伝統的なバッチ処理では不十分となる。
何故なら、発生すると思われる全データが到達することは決してなく、全体の量を用いて処理することは出来ないため。
WindowingについてはStreaming 101で説明したかった概念だが、ここで次の質問が出てくる。
Where in event time are results calculated?
これを基に再度Windowingを振り返ってみよう。
- Where : windowing
既に示されているように、Windowingはデータソースを一時的な領域に区切って処理するものとなる。
共通的なWindow分割方式はFixed Windowing、Sliding Windowing、Session Windowingとなる。
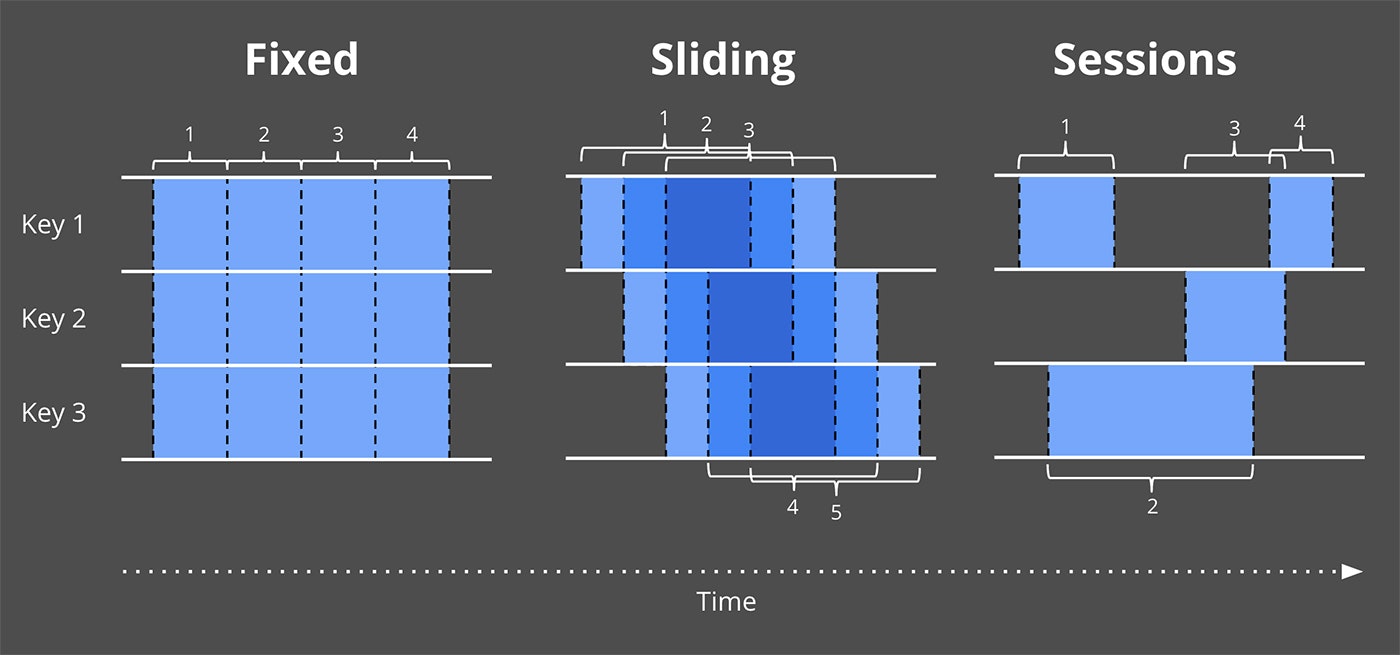
Figure 3 Example windowing strategies
実際にどのようにWindowingが処理されるかを深く理解するために、整数の合計値パイプラインを2分毎のFixed Windowに区切る場合を考えてみよう。
Dataflow SDKにおいては、2分毎のFixed Windowに区切ることは Window.into transformで可能となる。
PCollection<KV<String, Integer>> scores = input
.apply(Window.into(FixedWindows.of(Duration.standardMinutes(2))))
.apply(Sum.integersPerKey());
Listing 2. Windowed summation code.
Dataflowはバッチ、ストリーム両方を統合したモデルを提供しており、バッチはストリームのサブセットであることを思い出そう。
そのため、まずは初めはこのパイプラインをバッチエンジンで実行することを考えた方がより単純になる。
その後、ストリーム処理で実行することを考えれば何が差分か明確に比較ができるだろう。
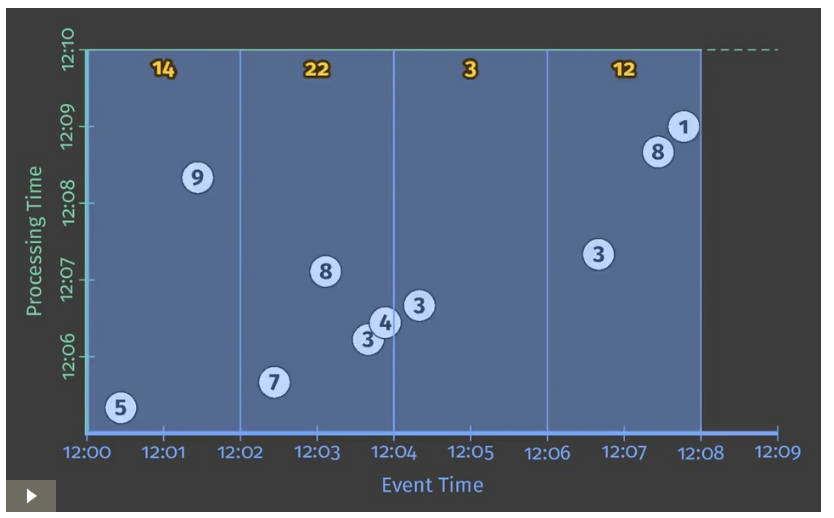
Figure 4 Windowed summation on a batch engine
従来通り、入力値は全データが入力されるまで蓄積され、その後出力が行われる。
この場合、出力値として2分ごとのWindowに区切られた4つの値が得られる。
ここで、Streaming 101で触れられていた2つのコンセプト「Event TimeとProcessing Timeの関係」「Windowing」について思い返そう。
この先に進むにあたり、上記に「Watermarks」「Triggers」「Accumulation」を追加して考えよう。
上記すべてを含めた状態で考えることこそが、Streaming 102となる。
Streaming 102
ここまではWindow化されたパイプラインをバッチ処理エンジン上で実行することについて見てきた。
だが、理想的にはこれらの結果はより低レイテンシで得たいし、無限のデータに対して親和性高く扱いたいだろう。
バッチ処理からストリーム処理エンジンに移行するのは正しい一歩だが、バッチ処理エンジンは各Windowのデータが終了したことを前提に処理を行っていた。
ストリーム処理に移行することによってそれがなくなるため、無限のデータを処理する際にWatermarksという概念が必要になる。
- When watermarks
Watermarksは「When in processing time are results materialized?」という質問に対して、半分の回答となる。
WatermarksはEventTime領域において、入力の完了度合いを示す一時的な概念となる。
言い換えれば、これはEventTimeに関連したシステムの処理進捗度合いを示す。
Streaming 101にあった図(Watermarkを追記)を振り返る。
これは主な実システムの分散データ処理システムにおいて汎用的に生じるEventTimeとProcesingTimeのずれを示したもの。

Figure 5. Event time progress, skew, and watermarks.
上記の中の部分にひかれている赤い線が実際にWatermarkを示したものとなる。
WatermarkはEventTimeに対するProcessingTimeの進捗を示す。
概念的に、Watermarkは関数として考えることができる。つまり、 $F(P) -> E$という形でProcessingTimeを指定するとEventTimeを返す。
(更に明確に言うと、関数の入力は実際の上流から流れてくるデータそのものであり、Watermarkはその値をどこまで観察して処理したかということになる。
ただ、ここでは単純化のためEventTimeに対するProcessingTimeの進捗として進める。)
EventTimeの視点で見ると、Eはシステムはそれまで入力して処理したデータの中で、これ以上EventTimeの小さいデータは全て処理したはずだと考える値となる。
この値はあくまでシステムがそう考えているだけで、実際の値は不明となる。
Watermarkの種別として、完璧な場合(Perfect Watermark)は完全な保証、ヒューリスティックな値(Heuristic Watermark)の場合は推測となる。
- Perfect Watermark
- 入力データに対して完全な情報を取得できる場合にのみ、構築可能。
- このようなケースにおいては、データは遅れることはなく、早く到着するか、または時間通り到着する。
- Heuristic Watermark
- ほとんどの分散システムにおいて、入力データに対する完全な情報を取得するのは現実的ではない。
- そういったケースにおける次善策はHeuristic Watermarkの提供となる。
- その場合、入力データに対する情報(パーティション、内部ソート、ファイル数など)を基に出来るだけ正確な値を求める形になる。
- 多くのケースにおいては、このようなWatermarkはかなり正確な予測が可能。
- しかしながら、こういったWatermarkは時には誤ることもあり、データの遅れを招く。
- そのため、この後こういった遅れたデータに対応するための概念としてTriggersを扱う。
Watermarkについての議論は興味深く、困難なものとなる。
このWatermarkの調整についての議論については今後の記事をお待ちいただきたい。
この記事においては、Watermarkの役目と欠点について概要を掴むために、ストリーム処理上でいつ出力をするか決定するためにWatermarkを用いるListing2のWindowingパイプラインの2つの事例を示す。

Figure 6. Windowed summation on a streaming engine with perfect (left) and heuristic (right) watermarks.
上記の両ケースにおいて、WindowはWatermarkがWindowの終了時刻に到達したタイミングで出力している。
この2つの事例の大きな違いは、Heuristic Watermarkの方は「9」のデータについてWatermarkの算出に誤っており、このデータの存在によって両ケースのWatermarkの値は大きく変わってしまうこと。
この事例より、Watermarkは完全性に対する概念の他に、2つの欠点があることがわかる。
その2点について示す。
- Too slow
- 両種別のWatermarkにおいて、現状処理されていないデータが存在することにより、遅れが発生する。この遅れはそのまま出力の遅れに直結する。
- このことは左の図で9が遅れて到着することにより、対象のWindow出力が遅れることからわかる。既に、それ以後のWindowでデータがそろっているにも関わらず。
- 2つ目のWindowについては最初のデータが到着してから7分近く経過してから結果が出力されることになってしまう。
- 対して、この事例におけるHeuristic Watermarkはそこまで影響を受けることはない。だが、影響を受けないわけではない。
- ここでの重要なポイントは下記。
- Watermarkが完全性に対して有用な性質を提供し続ける限り、遅れという視点では理想的な結果にはならない。仮に必要なメトリクスを出力するダッシュボードが存在し、時間か日でWindow分割された事例を考えてみよう。
- この場合、今のWindowの値を見る際に、対象の時間帯が全て終了してから初めて結果が見れるというのは使いにくいはずだ。
- これがこのようなシステムを伝統的なバッチシステムで処理する際の課題の一つであり、その代わりに、該当の時間帯のデータを入力データが到着する度に更新し、最終的に完全な値になるというのはより優れたシステムとなるだろう。
- Too fast
- Heuristic Watermarkが実際にあるべき状態より先に進んでしまった場合、遅れデータが発生する可能性がある。
- これは実際に右の事例を見ていただければわかるだろう。WatermarkがはじめのWindowのデータが全て到着する前に進んでしまっているため、本来出力される14でなく、5が出力されてしまっている。
- この問題点は深刻なものであり、実際のところ、Heuristic Watermarkを決定すると、時々誤りは発生する。その結果、正確性を重視する場合は注意が必要になる。
Streaming 101において、無限のデータストリームに対する堅牢なOut-of-order処理を構築するためには完全性の概念が問題になることを記述した。
これらの2つの欠点、早すぎることと遅すぎることの事象がこの根本問題となる。
完全性を重視する場合、完全性と低レイテンシを容易に実現することは出来ない。
この課題に対応するためにTriggerが存在する。
- When The wonderful thing about triggers, is triggers are wonderful things!
TriggersはWhen in processing time are results materialized? に対する回答の後半となる。
Triggersを用いた場合、Windowの出力タイミングはそのデータを処理したタイミングに出力すべき、となる。
各Windowに対応する出力は半透明の矩形として記述される。
Triggerを実行する際のシグナルの例は下記の通り。
-
Watermark progress (i.e., event time progress
- これは暗黙的な事例であれば、Figure 6で述べられているが、WatermarkがWindowの最後まで来た段階で出力すべきというもの。
- 別の使用方法としては、Windowの有効期間を超過したらGCを起動しようというもので、これも後で振り返る。
-
Processing time progress
- これはProcessingtimeは常に一定ペースで進捗するため、定期的な実行には適している。
-
Element counts
- これはWindowで一定の有限個数のデータを処理したタイミングで実行するのに有効
-
Punctuations
- またはデータに依存したTriggerとなる。これは特定のデータ(ファイルや行の区切り)を検出した場合に出力を行うということ。
これらのシンプルなTriggerに追加して、より複雑な複合Trigger実行ロジックを作成することも可能。
複合Triggerの例は下記の通り。
-
Repetitions
- 特にProcessingTimeTrigerと組み合わせることで定期的な更新をすることに適する。
-
Conjunctions(AND)
- 子Triggerがすべて実行したタイミングで実行される。
- 例えば、WatermarkがWindow終了を過ぎ、かつ区切りのレコードを受信した場合など
-
Disjunctions(OR)
- 子Triggerのいずれかが実行したタイミングで実行される。
- 例えば、WatermarkがWindow終了を過ぎるか、または区切りのレコードを受信した場合など
-
Sequences
- あらかじめ定義された子Triggerが一定個所まで実行されたタイミングで実行される。
Triggersの概念をもう少し明確化してみよう。
これはFigure6、Listing2に対して、デフォルトの暗黙的なTriggerを追加したもの。
PCollection<KV<String, Integer>> scores = input
.apply(Window.into(FixedWindows.of(Duration.standardMinutes(2)))
.triggering(AtWatermark()))
.apply(Sum.integersPerKey());
Listing 3. Explicit default trigger
Triggersが実際のところ何を提供しなければならないか、を考えると、Too slowなケースとToo fastのケースにおいて発生する問題にどう対処できるかが浮かぶ。
両ケースにおいて、本質的に提供したいのは、Windowの終了時刻を過ぎる前、または後にWindowに対して何かしらの、一定ルールに従ったソートと、更新手段を提供すること。
(さらに、その更新時にウィンドウの終端を通過した旨の通知を受け取りたい。)
そのため、我々は繰り返しのTriggerに対して何かしらのソートが欲しくなる。
ただ、そこで生じる疑問として、「何を繰り返すのか?」がある。
Too slowなケースへの対処(早期に投機的な結果出力を提供)において、我々はWindow出力のために何かしらの出力基準を設定する必要がある。(出力時、データが実際は完全でないことが明確だとしても。)
例えば、Processing Timeが一定時間進んだタイミングで出力する方式は実際のWindowに対して観察されたデータ量に依存することがないため、比較的適切な対処となる。
最悪なケースであっても、定期的なTrigger実行による定常化された出力を得ることができる。
Too fastなケースへの対処(Heuristic Watermark使用時に遅れデータの反映を提供)の場合、まずはHeuristic Watermarkに相応の正確性があるとする。
この場合、遅れデータがそう頻繁に発生することはないと思われるため、すぐに出力結果を修正してしまうというアプローチでいいと思われる。
結果、遅れデータを受信したタイミングで、出力を更新しても想定した頻度であれば特に性能的に大きな影響は出さないとなるだろう。
ただ、これはあくまで例であり、実際のシステムに応じて適切に調整は必要。
その上で、実際にシステムを構築する際にはこれまで出てきた複数のTriggersである、early、on-time、lateを組み合わせる必要が出てくる。
Cloud Dataflowではこの組みあわせをSequence TriggerとOrFinally Triggerによって実現可能。
これは親Triggerに子Triggerを設定し、子Trigger発火時に親Triggerも終了するもの。
PCollection<KV<String, Integer>> scores = input
.apply(Window.into(FixedWindows.of(Duration.standardMinutes(2)))
.triggering(Sequence(
Repeat(AtPeriod(Duration.standardMinutes(1)))
.OrFinally(AtWatermark()),
Repeat(AtCount(1))))
.apply(Sum.integersPerKey());
Listing 4. Manually specified early and late firings
しかし、上記はいまいち長ったらしい。
加えて、このrepeated-early、on-time、repated-late発火パターンは非常に共通的なものとなる。
そのため、Cloud Dataflowでは追加API(意味論としては同じ)を設け、これらのパターンをより明確に、シンプルに記述可能としている。
PCollection<KV<String, Integer>> scores = input
.apply(Window.into(FixedWindows.of(Duration.standardMinutes(2)))
.triggering(
AtWatermark()
.withEarlyFirings(AtPeriod(Duration.standardMinutes(1)))
.withLateFirings(AtCount(1))))
.apply(Sum.integersPerKey());
Listing 5. Early and late firings via the early/late API
このListing 4かListing 5をストリーム処理基盤で実行した場合、下記のように動作する。

Figure 7. Windowed summation on a streaming engine with early and late firings.
上記を見ると、Figure 6のものに比べて2つの明確な改善がみられる。
Watermarks too slowなケースが2個目のWindowで発生する場合:[12:02, 12:04)
この方式を取ることによって、早期の更新を1分毎に実行することが可能。
この違いはPerfect watermarkのケースで大きく表れ、元々7分近く遅延していたものが4分の時点で早期出力される。
また、Heuristic watermarkのケースでも改善が現れる。
両バージョンで、時間経過に伴って7>14>22と出力の更新が行われ、毎回のデータ更新から遅延が小さく更新され続ける。
Heuristic watermarks too fastなケースが1個目のWindowで発生する場合:[12:00, 12:02)
今回のケースにおいて9のデータが遅れデータとして到着した場合、出力結果が14に更新される。
この新たなTrigger群を導入したことによって生じる興味深い副作用として、出力パターンが両ケースで効果的に正規化される。
Figure 6の時点だと両ケースの出力に大きな違いがあるが、Figure 7になると両ケースでかなり共通のものとなる。
ただ、この事例において未だ残っている大きな違いは、Windowの生存期間。
Perfect watermarkのケースでは、Watermarkが過ぎた時点でWindowに対してデータが到着することはなく、内部状態をその時点で破棄することができる。
対して、Heuristic watermarksのケースでは遅れデータが到着した時のためにWindowの内部状態を保持し続ける必要がある。
しかし、現状構築できるシステムにおいて、Windowをどれだけの期間保持すればいいかを決める有効な手段は存在しない。
そのために、allowed lateness(許容遅れ値)という概念が必要となる。
- When : allowed lateness (i.e., garbage collection)
先ほどの問い(How do refinements of results relate?)に戻る前に、実用的な長時間動作するout-of-orderなストリーム処理システムにおけるGarbage collectionについて考えてみよう。
Figure 7のHeuristic watermarksのケースでは各Windowに対する内部状態値が例の間ずっと保持されている。
これはいつ到着するかわからない遅れデータが到着した際に適切に対応するために必要なものとなる。
だが、この状態値を実行時間が完了するまで無期限に保持し続けるのは、無限のデータソースを扱うと考える以上、現実的ではない。
最終的にはディスクやメモリから内部状態を削除する必要がある。
結果として、実世界においてout-of-orderな処理システムは何かしらの形でWindowの生存期間を区切る必要が出てくる。
一つの明確な方式として、システムに対して許容遅れ値を規定する方式がある。
これは許容される遅れ期間の間に到着したデータは処理するが、その期間を過ぎたデータについては単純に破棄するというもの。
一度個々のデータに対してどれだけの遅れを許容するかを決めれば、Windowの生存期間と、どれだけの期間維持する必要があるかが明確にできる。
もちろん、そうすることによってシステムのリソースの無駄を防ぐことが可能となる。
Allowed latenessとWatermarkの連携は微妙にわかりにくいため、例を用いて説明する。
Listing 5/Figure 7のHeuristic watermarksのケースに、許容遅れ値を1分として設定するケースを考えてみよう。
(なお、この1分とするのは図中でわかりやすくするためであり、現実のシステムにおいてはもっと大きな値にする必要が出てくるだろう。)
PCollection<KV<String, Integer>> scores = input
.apply(Window.into(FixedWindows.of(Duration.standardMinutes(2)))
.triggering(
AtWatermark()
.withEarlyFirings(AtPeriod(Duration.standardMinutes(1)))
.withLateFirings(AtCount(1)))
.withAllowedLateness(Duration.standardMinutes(1)))
.apply(Sum.integersPerKey());
Listing 6. Early and late firings with allowed lateness
このパイプラインを実行すると、Figure 8のように動作する。
許容遅れ値の概念を加えたことによる変化は下記のようになる。

Figure 8. Windowed summation on a streaming engine with early and late firings and allowed lateness
現状のProcessingTimeを示す白い太線に対して、EventTimeに対する許容遅れ値を生存期間内のWindowに対応させて表示している。
Watermarkが遅れ許容値を過ぎると、該当のWindowはクローズされる。これは該当Windowの状態を破棄することを示す。
その遅れ許容値を白い点線での時刻範囲として示している。
遅れ許容値をWatermarkと対比するために、短い点線で時間地点を示している。
この図でのみ、1個目のWindowに追加の遅れデータである6を追加している。
6は遅れデータではあるものの、遅れ許容値の範囲に収まっている。そのため、1個目のWindowの出力値は6が到着した段階で11に更新される。
ただ、9は遅れ許容値を超過しているため、単純に破棄される。
更に、遅れ許容値について2つ補足する。
当然のことではあるが、もしPerfect Watermarkが使用可能な場合、遅れデータを扱う必要はないため、遅れ許容値は0秒が最適となる。
これについてはFigure 7を参照してほしい。
Heuristic watermarks環境下での遅れ許容値の必要性について、注目すべき一つの例外として、全時間を通して有限の個数に対する統計を取得するケースがある。
(例えば、サイト訪問者のブラウザ別の総数)
その場合、生存期間内のWindowの数は有限個となる。
その数が管理可能なレベルな値であれば、Windowの生存期間を遅れ許容値を用いて区切る必要はなくなる。
では、4つ目、最後の質問に移ろう。
- How : accumulation
(※ここでのペインとは、あるWindowに対する結果算出のスナップショットのようなものを示す。図中では半透明の枠。)
TriggerがあるWindowに対してペインを更新して用いるために使用される場合、最後の問いに直面することになる。
How do refinements of results relate?
これまで見てきた例においては、ペインは遅れデータが到着する度に、前のペインを基に更新されてきた。
しかしながら、実際には遅れデータが到着した時にとり得る累積計算方式としては代表的なものとして下記の3つがある。
-
Discarding
- ペインが具体化した時に保持した状態は破棄される。これはつまり、連続したペインは前のペインの状態とは無関係に決定されるということ。
- このモードは下流のシステムが自前で何かしらの累積計算の機構を保持している場合に有用。例えば、ペインが前回との差分を送信することで、外部システムはその値を合計して最終結果とするなど。
-
Accumulating
- Figure7において、ペインが具体化した場合にはその状態はそのまま保持され、追加の入力があった場合、既存の状態に対して累算する形を取っていた。
- これは、連続したペインは前のペインを基に更新されるということ。
- このモードは新しい結果で古い結果を上書きすればいいケースにおいて有用。例えば、BigTableのようなKVSに結果を出力するケースなど。
-
Accumulating & retracting
- これは累算のモードに似ているが、新たなペインを生成する時には前回の値を基にした相殺するための差分値(後退値)を出力するというもの。
- 後退(前の値と今回の値を基にした結果)の方式で基本的な考え方として、「以前は結果をXとしたが、それは間違っていた。Xの代わりにYで更新するよ。」となる。
- この方式は下記の2つのケースのような場合に有効となる。
- 下流のシステムが違う軸でデータを再グルーピングする場合、新しい値が古い値とは違うキーに紐づいて更新される場合がある。その場合、後退値があれば対応可能。このケースにおいては、新しい値は単純に古い値を上書きするという形にはならず、古いグループから古い値を取り除き、新しいグループに移す必要がある。
- 動的Window(セッションなど)を使用する場合、新しい値は単に前の値を更新するだけでなく、前のWindowの値を統合するケースが発生する。このケースにおいては、単に古い値を新しい値で置き換えるだけでは対応が困難で、特定の古いWindowを新しいWindowと再統合するためにこういった対処が必要となる。
複数のモードを比較することで、各モードの違いを明確にする。
Figure 7の2つ目のWindow([12:02, 12:04))を考えてみよう。
下記の表は、3つの累算モードでどのような結果になるかを示したもの。
尚、Figure 7の動作中においてはAccumlatingのモードを使用している。

Table 1. Comparing accumulation modes using the second window from Figure 7.
-
Discarding
- 各ペインは到着した値を現在の値として使用している。そのため、最終的な出力値は合計値とは異なる。
- しかし、このペインの出力値を全て合計した場合、実際の合計値と同じ22となる。
- そのため、下流のシステムが自前で合計やソートを行う機構を持つ場合、この方式が有用となる。
-
Accumulating
- 各ペインはそれまでに到着した値の総計地となる。そのため、最終的な出力値が合計値となる。
- もし各ペインの出力値を合計していった場合、1ペイン目と2ペイン目出力時の値が重複カウントされ、結果は51となってしまう。
-
Accumulating & retracting
- 各ペインは出力値と、前のペインの値を基にした後退値が併せて出力される。
- そのため、最終的な値と、あとは各ペインの出力値を合計した場合、両方正しい結果となる。
実際にDiscardingモードとする場合、コードを下記のようにする。
PCollection<KV<String, Integer>> scores = input
.apply(Window.into(FixedWindows.of(Duration.standardMinutes(2)))
.triggering(
AtWatermark()
.withEarlyFirings(AtPeriod(Duration.standardMinutes(1)))
.withLateFirings(AtCount(1)))
.discardingFiredPanes())
.apply(Sum.integersPerKey());
Listing 7. Discarding mode version of early/late firings
同様の入力データを基にHeuristic watermarksのDiscardingモードで実行した場合、結果はFigure 9のようになる。

Figure 9. Discarding mode version of early/late firings on a streaming engine.
図の構成自体はFigure 7と同じだが、ペインを出力した段階で内部値がクリアされる。
そのため、ペインの出力値は前のペインの出力値とは独立した値となる。
Accumulating & retractingモードで実行したい場合、同様に下記のように修正すればいい。
(ただ、この後退値モードは現状Google Cloud Dataflowでは開発中であり、API名称なども変わる可能性がある。)
PCollection<KV<String, Integer>> scores = input
.apply(Window.into(FixedWindows.of(Duration.standardMinutes(2)))
.triggering(
AtWatermark()
.withEarlyFirings(AtPeriod(Duration.standardMinutes(1)))
.withLateFirings(AtCount(1)))
.accumulatingAndRetractingFiredPanes())
.apply(Sum.integersPerKey());
Listing 8. Accumulating & retracting mode version of early/late firings
同様の入力データを基にHeuristic watermarksのAccumulating & retractingモードで実行した場合、結果はFigure 10のようになる。

Figure 10. Accumulating & retracting mode version of early/late firings on a streaming engine
図の構成自体は同じだが、出力値の形式が合計値と後退値の2つの出力を取るようになっている。
これらの3つのモードを並べて比較するとFigure 11のようになる。

Figure 11. Side-by-side comparison of accumulation modes: discarding (left), accumulating (center), and accumulating & retracting (right).
図からわかるように、図の左側のモードから、より保存領域や計算コストがかかるようになっている。
(discarding, accumulating, accumulating & retractingの順)
そのため、どのモードを選択するかについて考えると、正確性、遅延、コストという新たなトレードオフの軸が発生する。
中間まとめ
このように、挙げられた4つの問いについて答えてきた。
- What results are calculated? > Answered via transformations.
- Where in event time are results calculated? > Answered via windowing.
- When in processing time are results materialized? > Answered via watermarks and triggers.
- How do refinements of results relate? > Answered via accumulation modes.
しかし、現状1つの形式のWindow方式:EventTimeベースの固定長Windowについてしか見ていない。
Streaming 101であったように、Window方式は複数存在する。
この後、ProcessingTimeベースの固定長Window、Sessionについて見ていこう。
When/Where: Processing-time windows
ProcessingTimeベースのWindowは下記の2つの理由で重要なものとなる。
- QPS等の使用量のモニタリングを行う等のユースケースにおいては、発生した時刻より、観測した時刻をベースに解析を行いたい。そのため、ProcessingTimeベースのWindowは非常に適した用途となる。
- ユーザの振る舞い解析のような、Eventが発生した時刻が重要なユースケースにおいては、ProcessingTimeベースのWindowは誤ったアプローチであり、これを認識できることは大切。
上記のように、ProcessingTimeベースのWindowと、EventTimeベースのWindowの違いを明確に理解することに意味はあり、現状主流となっているのはProcessingTimeベースであることからも重要。
この記事で示されたように、第一級の概念としてのWindowは厳密にEventTimeベースのものであり、ProcessingTimeのWindowを実現するための手法として、下記2つがある。
-
Triggers
- EventTimeを無視(例えば、EventTime全域にまたがるグローバルWindowを使用するなど)し、ProcessingTimeの軸上の一定間隔でスナップショットを提供するパターン
-
Ingress time
- データが到着したタイミングでEventTimeの値として、その時点の時刻を割り振り、その値を用いてEventTimeベースのWindowを行うパターン。これは現状のSpark Streaming等で採用されている方式。
この2方式は多段パイプラインの場合は若干異なるものの、多かれ少なかれ類似の性質を持つ。
Triggersの場合、各StageはProcessingTimeベースの独立したWindowに分割される。
例えば、Window XのあるStageにおけるデータは、Window X-1やWindowX+1の次のStageで終わる可能性がある。
Ingress timeの場合、一度WindowXに前提が置かれた場合、その前提はWatermark(Dataflowの場合)やMicroBatch境界(Spark Streamingの場合)で区切られたStageを跨いでパイプラインが継続する限り続くケースが多い。
ただ、これまで指摘してきたように、ProcessingTimeベースのWindowの大きな欠点として、Window中のデータがデータの到着順の変化によって変化しえるということ。
この問題点についてより詳細に見ていくにあたり、下記の3つのケースを追ってみよう。
- Event-time windowing
- Processing-time windowing via triggers
- Processing-time windowing via ingress time
各ケース毎に2種類のデータ入力を用いて確認を行う。
この2種類のデータは全体のデータとしては同一ではあるもの、到着順が異なるものとなる。
Figure 12の白い丸で示されたタイミングのデータ到着、紫の丸で示されたタイミングのデータ到着で2種類のデータが存在する。

Figure 12. Shifting input observation order in processing time, holding values and event times constant
Event-time windowing
まずベースラインを確立するために、Heuristic watermarkを用いたEventTimeベースの固定長Windowのケースを見てみよう。
これはListing 5/Figure 7のコードのToo early/Too lateへの対応をそのまま用いている。
左側の図はこれまで見てきたものと同じで、右側の図が到着順序を変えたものとなる。
重要なことは、全体の図を見ると異なる個所も多々あるものの(これは到着順が異なるので当然そうなる)、最終的な出力結果は同一で、14、22、3、12となるということ。

Figure 13. Event-time windowing over two different processing-time orderings of the same inputs.
Processing-time windowing via triggers
では、ここから上述されたProcessingTimeベースの処理方式と比較していこう。
1個目はTrigger方式となる。
ProcessingTimeベースのWindowを実際に構築するにあたり、下記3つの要素に気を配る必要がある。
-
Windowing:
- この方式においては、グローバルEventTimeWindowを用い、その上でProcessingTimeWindowを用いてペインを構築する。
-
Triggering:
- ProcessingTimeで一定間隔ごとにTriggerを実行し、Trigger毎に出力を行う。
-
Accumulation:
- discardingのモードを使用し、ペイン出力時にデータを破棄することで各ペイン間のデータは独立したものとする。
上記の処理はListing 9のように記述される。
ここで注意すべき点として、GlobalなWindowはデフォルトstrategyである関係上、特にコード中にはstrategyを記述していないということ。
PCollection<KV<String, Integer>> scores = input
.apply(Window.triggering(
Repeatedly(AtPeriod(Duration.standardMinutes(2))))
.discardingFiredPanes())
.apply(Sum.integersPerKey());
Listing 9. Processing-time windowing via repeated, discarding panes of a global event-time window.
このコードを2つの到着順序の違う入力データに適用した場合、結果はFigure 14のようになる。

Figure 14. Processing-time “windowing” via triggers, over two different processing-time orderings of the same inputs.
ここで興味深い点は下記の通り。
- ProcessingTimeWindowをEventTimeペインとして適用した結果、"Window"はProcessingTime軸で線引きされ、X軸の横幅の代わりにY軸の縦幅として記述される。
- ProcessingTimeWindowは入力データの到着順によって影響されるため、各出力Windowの結果はデータの発生順序が同じだったとしても、到着順によって変動する。左の図では出力は12、21、18となり、右の図では7、36、4となる。
Processing-time windowing via ingress time
最後にEventTimeを到着した時刻として割り振ってProcessingTimeWindowを行うケースを確認する。
同様に、下記の4つの要素に留意する。
-
Time-shifting:
- データが到着したタイミングで、EventTimeはデータの到着時刻で上書きされる。
- (※尚、元記事記述時点で実際はDataflowの標準APIでこのような動作をするAPIは存在しない。)
- Google Cloud Pub/Subにおいては、timestampLabelの設定フィールドを空にしてメッセージを投入すればいい。
-
Windowing:
- EventTimeベースの固定長Windowを使用
-
Triggering:
- 到着時刻の設定によって、このケースではPerfect Watermarkを算出することが可能となる。そのため、WatermarkがWindowの最後を通過したタイミングで1回のみのTrigger実行で対応可能
-
Accumulation mode:
- 各Window毎に1回の出力のみを実行すればいいため、累算のモードを考える必要はない。
実コードは下記のようになる。(と思われる。)
PCollection<String> raw = IO.read().withIngressTimeAsTimestamp();
PCollection<KV<String, Integer>> input = raw.apply(ParDo.of(new ParseFn());
PCollection<KV<String, Integer>> scores = input
.apply(Window.into(FixedWindows.of(Duration.standardMinutes(2))))
.apply(Sum.integersPerKey());
Listing 10. Explicit default trigger.
上記のパイプラインを実行した結果の動作はFigure 15のようになる。
データが到着したタイミングで、EventTimeは到着時刻に更新される(つまり、到着したタイミングのProcessingTimeとなる)その結果、右側の理想的なWatermark上にデータは配置される形になる。

Figure 15. Processing-time windowing via the use of ingress time, over two different processing-time orderings of the same inputs.
Figure 15の興味深い点は下記がある。
- 他のProcessingTimeベースのWindowの例と同じく、出力結果は入力値とEventTimeが一定であっても、到着順序の変化によって変わる。
- 他の例とは異なり、WindowはEventTimeドメイン(つまりX軸)で区切られたものとなる。しかしながら、これは本当のEventTimeWindowではない。これは単にProcessingTimeをEventTimeドメインの値としてマッピングしているだけであることに注意。
- と言いつつも、Watermarkのおかげで、Triggerは前のProcessingTimeの例と同様の時間に発火することが明確。更に、出力値も予想の通り、左の図では出力は12、21、18となり、右の図では7、36、4となる。
- Perfect Watermarkが到着時刻の適用により使用可能となるため、実際のWatermarkは理想的なWatermarkと一致し、右側の理想的な直線と同一となる。
このようにProcessingTimeベースのWindowの実現方法について複数の異なる方式を見てきているが、
ここで改めて強調したい点は、前回の投稿でも説明しているが、EventTimeWindowは早い/遅れ許容値の範囲に収まっている限り、データの到着順序によって最終結果は左右されないということ。
ProcessingTimeWindowではそうではない。
もし実際に発生した時刻を重視する処理を行うケースにおいては、EventTimeベースのWindowを使用する必要があり、そうでない場合、そもそも無意味な結果しか得ることができないということ。
Where: session windows
これから私が興味深いと思っている事象:動的でデータに依存して変動するWindow、Sessionについて説明する。
Sessionは活動の間隔に応じて区切られる、特殊な形態のWindowとなる。
Sessionは特定のユーザの特定の時間帯における活動を関連付けた形で見ることができるため、データ分析においては有用なものとなる。
Session内の活動の関連付けを可能とし、その長さや活動によってどれだけ関係あるものかの推測も可能となる。
Windowの視点で、Sessionは特に下記2つの観点において興味深い。
- SessionはDataDrivenWindowの事例であり、Windowの場所やサイズはデータ自体をそのまま示したものとなり、事前に定義された固定長WindowやSlidingWindowと比べてデータを表すものとなる。
- Sessionは位置が固定されていないWindowの事例であり、Windowの配置はデータ全体を基に決まるのではなく、データのサブセット(例えば、特定のユーザ)を基に決められる。これは位置がデータ全体を基に固定されたWindowである、固定長WindowやSlidingWindowと対照的。
いくつかのユースケースにおいては、事前に共通の識別子を指定することにより、あるSessionを特定することが可能。(例えば、ビデオプレイヤーが送信するHeartBeatにサービス品質情報を載せる等。このHeartBeatは視聴開始時に割り振られる識別子でSessionとしてまとめることができる)
ただ、今回のSessionはよりシンプルに、Keyのグルーピングのみで構築可能なものとする。
しかしながら、より汎用的なケース(実際のセッションの特定情報を事前に知らないなど)を実現するためには、あるSessionの時間内のデータの場所も含めて構築する必要がある。特に、out-of-orderなデータを扱う際には複雑化する。
汎用的なSessionのサポートを提供する際に鍵となるのは、完全なSessionWindowを構成するのは、より小さな、重なったWindow群だということ。
このWindow群は各々1レコードを保持し、各レコードの間隔はSessionTimeout時間以内に収まっている。
そのため、仮にそのSessionの構成レコードをout-of-orderな状態で受信したとしても、最終的なSessionは重なったWindow群を到着するごとにマージすることで構成することができる。

Figure 16. Unmerged proto-session windows, and the resultant merged sessions.
ここで、Listing 8で早期到着データと遅れデータに対応した後退値モードのWindow構築コードをSession化したものを見てみよう。
PCollection<KV<String, Integer>> scores = input
.apply(Window.into(Sessions.withGapDuration(Duration.standardMinutes(1)))
.triggering(
AtWatermark()
.withEarlyFirings(AtPeriod(Duration.standardMinutes(1)))
.withLateFirings(AtCount(1)))
.accumulatingAndRetractingFiredPanes())
.apply(Sum.integersPerKey());
Listing 11. Early and late firings with session windows and retractions.
上記のコードをStreaming処理基盤で実行すると、下記のようになる。

Figure 17. Early and late firings with sessions windows and retractions on a streaming engine.
上記の図からわかることは多々あるが、それを挙げていこう。
- 値が5である最初のレコードを受信したタイミングで、Sessionの持続時間、EventTime1分の幅を持つ仮セッションWindowを構築する。その後、Sessionが開始してからEventTime上で重なるWindowが到着した場合、同一のSessionとして扱い、該当のWindowをマージする。
- 次に、値が7であるレコードを受信したタイミングにおいて、同様にSessionの持続時間、EventTime1分の幅を持つ仮セッションWindowを構築する。ただし、これは値5のWindowとは重ならないため、Sessionとしてマージは行わない。
- Watermarkが初めのWindowの最後まで来たタイミングで、値が5の状態で出力される。同様に、2つ目のWindowも12:06でEarly状態でデータが認識され、値が7の状態で出力される。
- その後、値が3,4,3であるレコードが到着する。これらの仮Sessionは重なっているため、すべてマージされ、12:07にEarly状態で出力タイミングが来た際に値が10として出力される。
- その後、値が8のデータが到着した段階で、値が7のデータで作成された仮Sessionと、あとは値が10で出力された仮Sessionと重なる。そのため、この3つのSessionはマージされ、値が25の状態となる。このSessionの出力タイミングが来た段階で、もともとの値が7のSessionと10のSessionは後退値として消去され、値が25のSessionが出力される。
- 同様に、値が9のレコードが到着したタイミングで値が5の仮Sessionと値が25の仮Sessionとマージされ、値が39のSessionに統合される。2つの仮Sessionの後退値による除去と、値が39のSessionの出力はLateTriggerによりデータが到着したタイミングで即処理される。
これはかなり複雑な処理ではあるものの、ストリーム処理のパラダイム上ではパーツの組み合わせで容易に記述することができる。
そのため、ストリーム処理のユーザはデータを使える形に整形することよりも、ビジネスロジックに集中した開発を行うことが可能になる。
もしこのことが信じられない場合、SparkStreamingによるSession構成処理の開発方法についてみていただきたい。ただ、この記事自体はそういった概念の詳細について触れているわけではないし、Spark自体も汎用的な処理が開発可能であり、別にこの概念に特化しているわけではないことに注意。
ただ、この記事の内容では投機的な遅れデータへのTriggerや、後退値による更新についても触れられていない。
It’s the end of the blog as we know it, and I feel fine
これで、この記事で説明する事例は以上。
この記事を読むことで、読者は堅牢なストリーム処理の基礎概念についてご理解いただけたと思う。
最後に、この記事で描いてきたことについてまとめよう。
初めに、下記のような概念について説明した。
-
Event-time versus Processing-time
- イベントが発生した時刻そのものと、データがシステム側に到着した時刻という大きな違いがある。
-
Windowing
- 無限のデータを処理する際に、一時的な区切りを加えて処理可能にする汎用的な概念。
- ProcessingTimeベースかEventTimeベースかがあるが、Dataflowの文脈ではEventTimeベースのもののみをさす。
-
Watermarks
- Out-of-orderな無限のデータを処理する際の完全性を扱う際に、EventTime上どこまで処理が進んでいるかを示すための有用な概念。
-
Triggers
- Out-of-orderな無限のデータを処理する際に出力タイミングを制御するための機構。
-
Accumulation
- あるWindowに対して出力が複数回行われる場合における、前回のデータとの累算の方式。
その次に、上記の概念を実際にシステムを構築上で考えなければいけない質問に対する回答として紐づけた。
- What results are calculated? > transformations
- Where in event time are results calculated? > windowing
- When in processing time are results materialized? > watermarks+triggers
- How do refinements of results relate? > accumulation
それらの合間で、実際に概念や質問で出てきたモデルを実際のDataflowに適用してストリーム処理を駆動させるとどうなるか、についてを示してきた。
最後に、ストリーム処理が柔軟にさまざまなモデルに対応可能ということを、これまで触れてきた主な処理モデルを一覧化して振り返ろう。
なお、これはすべて同じ入力データに対するモデル構築のバリエーションとなる。
ストリーム処理は正確性や遅延、計算をトレードオフにかけながら、その中で様々な落としどころを見出すことができる。

Figure 18. Nine variations in output over the same input set.
これまで読んでくれてありがとう。また今度!
著者: Tyler Akidau
本投稿: kimutansk

長かったですが、これでようやくストリーム処理を構築する上で、
そもそもどのようなモデルなのか、ということについての基礎概念について若干おさえられたのではないかと思います。
あとは、これを実際にどうやって具体化して構築するかですが、それはまた別の機会に。