はじめに
こんにちは。
前回に引き続き、SparkInternalsを訳していきます。
前回と同じく以後は下記の判例となります。
SparkInternals訳文
コメント
SparkInternals
cache and checkpoint
cache(またはpersist)はHadoop MapReduceには存在しない、Spark固有の重要な要素となる。この機能によって、SparkはDataの再利用が可能になり、インタラクティブな機械学習アルゴリズム、インタラクティブなデータ解析といったユースケースにおいて大きく高速化に貢献している。Hadoop MapReduceのジョブと異なり、SparkのLogicalPlan/PhysicalPlanは巨大化し、処理の連鎖も大きく、RDDに対する計算時間も長くなる。もし、不幸にもエラーや例外がTask実行中に発生した場合、処理の連鎖の全体を再実行する必要が出た場合、計算ロスのコストはかなり大きいものとなる。従って、時間がかかるRDDに対する処理についてはcheckpointが必要となる。この対応によって、仮に下流のRDDで何かしら問題が発生した場合でも、チェックポイントとして保存したRDDからデータを復元することで処理を継続することが可能となる。
cache()
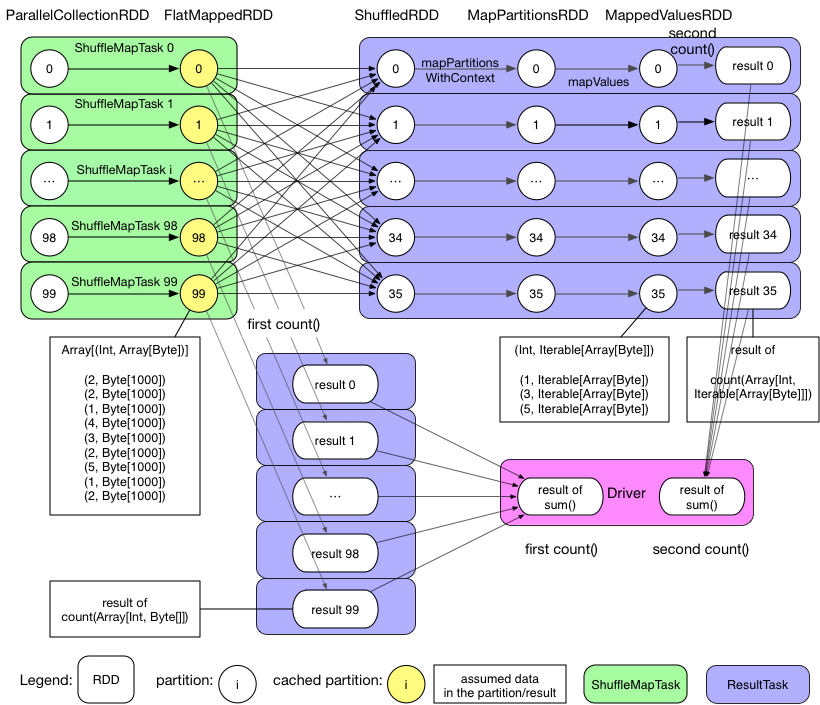
まずはOverview章でのGroupByTestを例として見てみると、FlatMappedRDDがキャッシュされているため、Job 1(second count())はFlatMappedRDDから再開してデータを処理することが出来る。そのため、cache()が同一アプリケーションにおいて同一データが異なるJobが取得する際に再取得を可能としていることがわかる。
Logical plan:
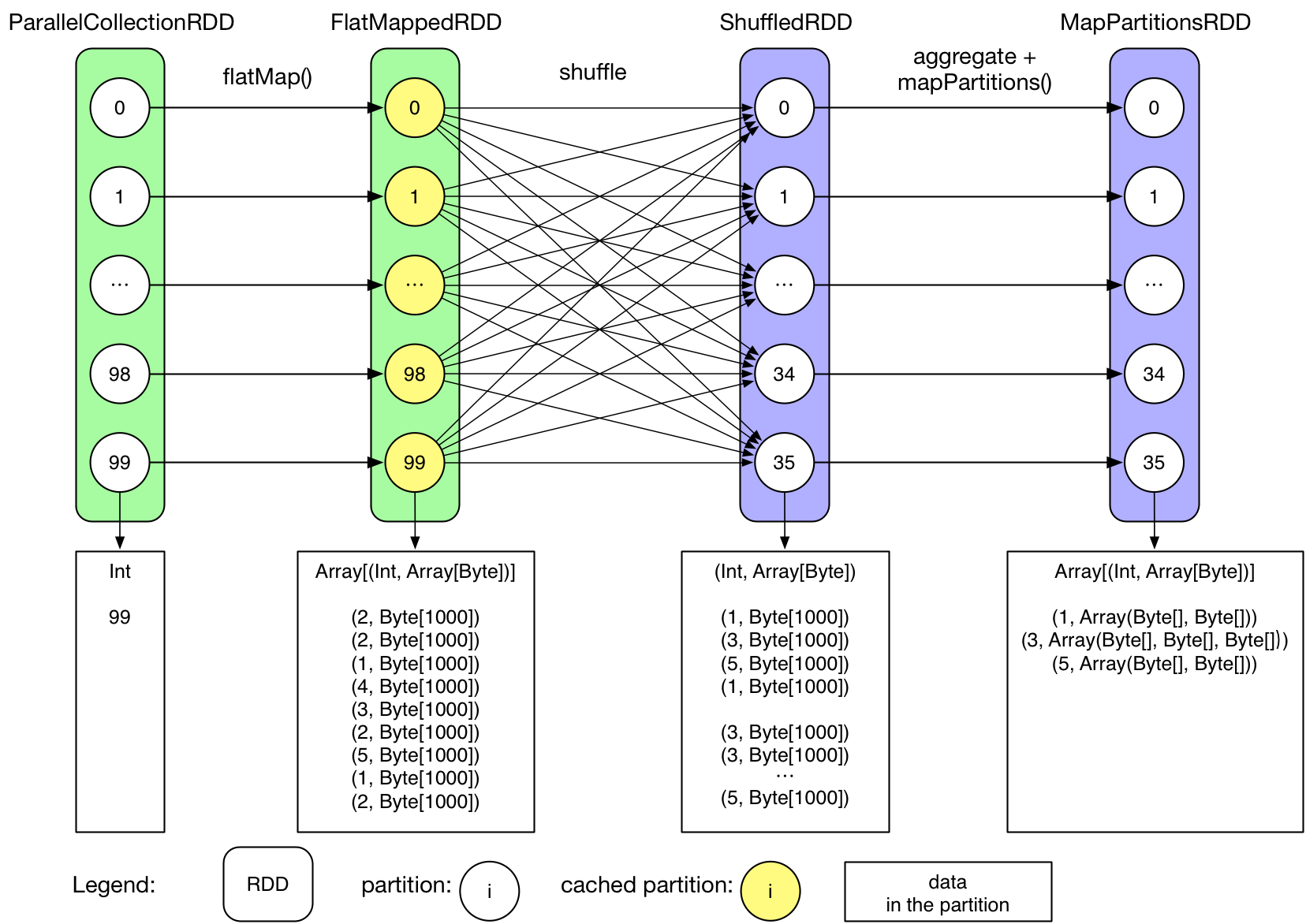
Physical plan:
Q: どのような種類のRDDをキャッシュする必要があるのか?
繰り返し使用され、かつそこまで大きくないRDD
Q: どうすればRDDをキャッシュするのか?
Driverプログラムでrdd.cache()を実行するのみでユーザがアクセス可能なRDD(transformation()で生成されるRDD)についてはキャッシュ可能。但し、reduceByKey()中のShuffledRDD, MapPartitionsRDDのように、Sparkが内部的に生成するRDDについてはキャッシュすることが出来ない。
Q: どのようにSparkはRDDをキャッシュするのか?
推測を行うことが出来るだけだが、直観的に思いつくものとして、TaskがRDDの最初のRecordを取得したタイミングで該当のRDDをキャッシュすべきかどうかの確認を行う、もしキャッシュするべきRDDであった場合は最初のRecordと以後のRecordをblockManagerのmemoryStoreに送信する、というものがある。もしmemoryStoreが全レコードを保持することが出来ない場合は、diskStoreが代わりに使用される。
**実際の実装は推測した内容と似ているが、違う点として以下がある。
SparkはRDDをキャッシュすべきか否かを最初のPartitionを計算する前に判定する。もしRDDがキャッシュするべきRDDであった場合、Partitionを計算後、メモリ上に保持される。cacheはメモリ上に保持する場合のみ使用され、checkpointはディスク上にも保持する動作となる。
rdd.cache()を実行後、rddはpersistRDDで、storageLevelとしてMEMORY_ONLYを保持するRDDとなる。persistRDDであること自体がDriverプログラムに対して該当RDDを保存する必要がある旨の通知となる。
上記の流れは下記のソースコードとなっている。
rdd.iterator()
=> SparkEnv.get.cacheManager.getOrCompute(thisRDD, split, context, storageLevel)
=> key = RDDBlockId(rdd.id, split.index)
=> blockManager.get(key)
=> computedValues = rdd.computeOrReadCheckpoint(split, context)
if (isCheckpointed) firstParent[T].iterator(split, context)
else compute(split, context)
=> elements = new ArrayBuffer[Any]
=> elements ++= computedValues
=> updatedBlocks = blockManager.put(key, elements, tellMaster = true)
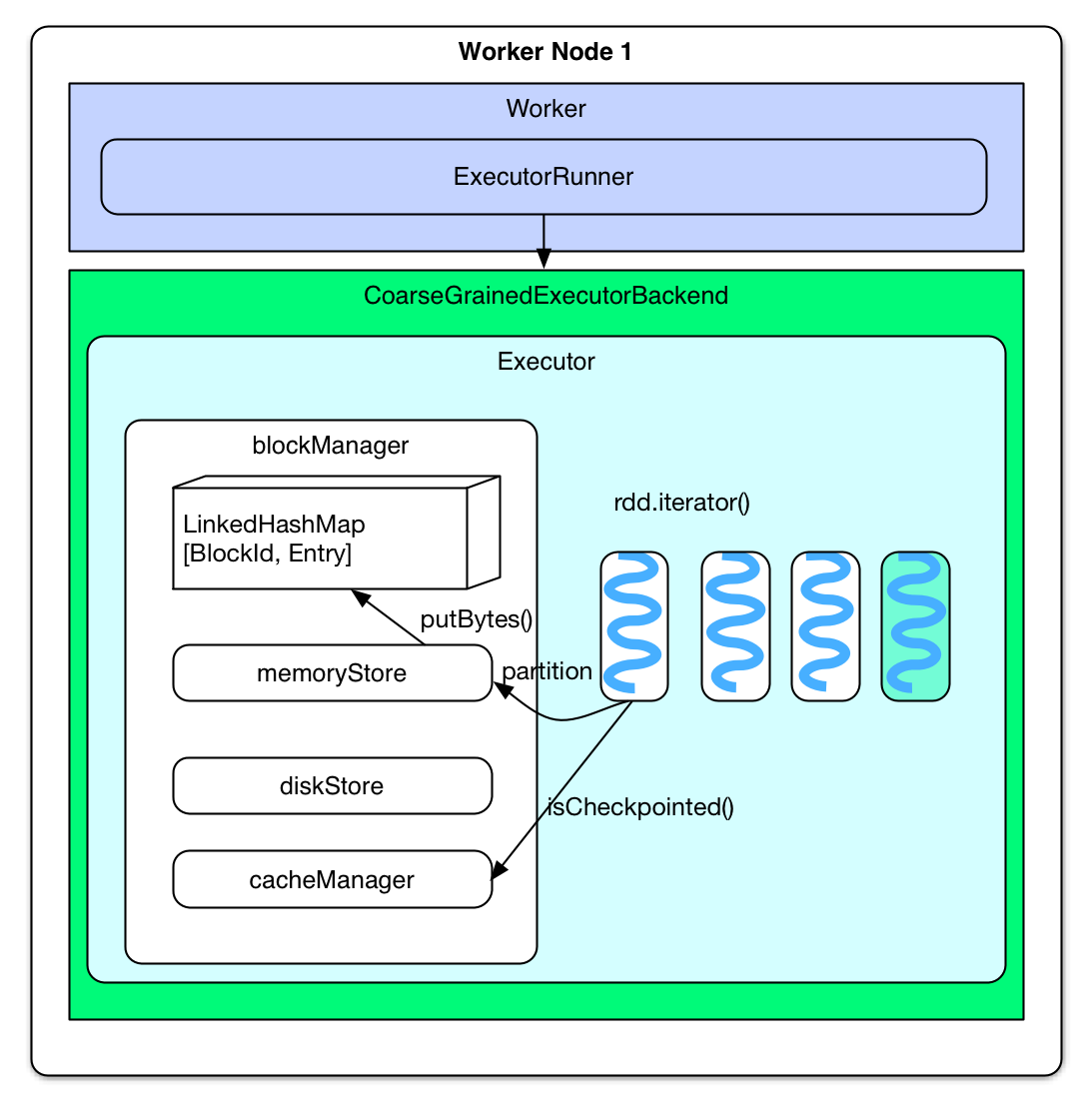
rddにおいて、rdd.iterator()がPartitionを計算するために呼ばれたタイミングでblockIdが該当Partitionをキャッシュするか示すために使用され、blockIdがRDDBlockIdの型だった場合、memoryStoreにおいてTaskの実行結果を保持するblockIdとは別のものとして扱われる。加えて、blockManger中のPartitionは既にチェックポイントとして保持されていないかの確認も行われる。もし保持されていた場合、既に該当Taskが実行されている旨の通知が行われ、該当Partitionに対して必要ないことがわかる。ArrayBufferのelementsとして該当チェックポイントのPartitionが保持する各Recordを取得可能だが、取得できない場合は該当Partitionが初回計算であることがわかり、結果をelementsとして保持する。最終的に、elementsはblockManagerにキャッシュ化のために登録される。
blockManagerはelements (partition)をmemoryStoreにLinkedHashMap[BlockId, Entry]として保持する。もし該当PartitionがmemoryStoreの容量(ヒープの60%)より大きい場合、データを保持できない旨の応答のみを返す。サイズ的に保存可能であった場合、memoryStoreは事前にキャッシュされていたRDD Partitionを新規Partitionの保存領域を確保するために削除する。もし削除された結果生成された領域が十分なサイズを保持していた場合、新規PartitionはLinkedHashMapに登録される。もしサイズが不足していた場合、最大サイズでそもそも足りなかった場合と同様にデータを保持できない旨の応答のみを返す。ここで留意すべきは、新規Partitionが所属するRDDのPartitionは予め保持されていたとしても削除されないこと。理想的にははじめにキャッシュされたRDDははじめに削除されるという動作となる。
Q: どのようにキャッシュされたRDDを読むのか?
キャッシュされたRDDが以降のJobにおいて再計算されたタイミングで、TaskはblockManagerのmemoryStoreからデータを取得して使用する。具体的にはRDD Partitionの計算タイミング(rdd.iterator()実行時)において、blockManager に対して該当Partitionがキャッシュされているかの確認を行う。もしローカルにキャッシュされていた場合、blockManager.getLocal() を用いてmemoryStoreからデータの取得を行う。もし別ノードにキャッシュされていた場合、blockManager.getRemote()が実行され、下記のような動作となる。
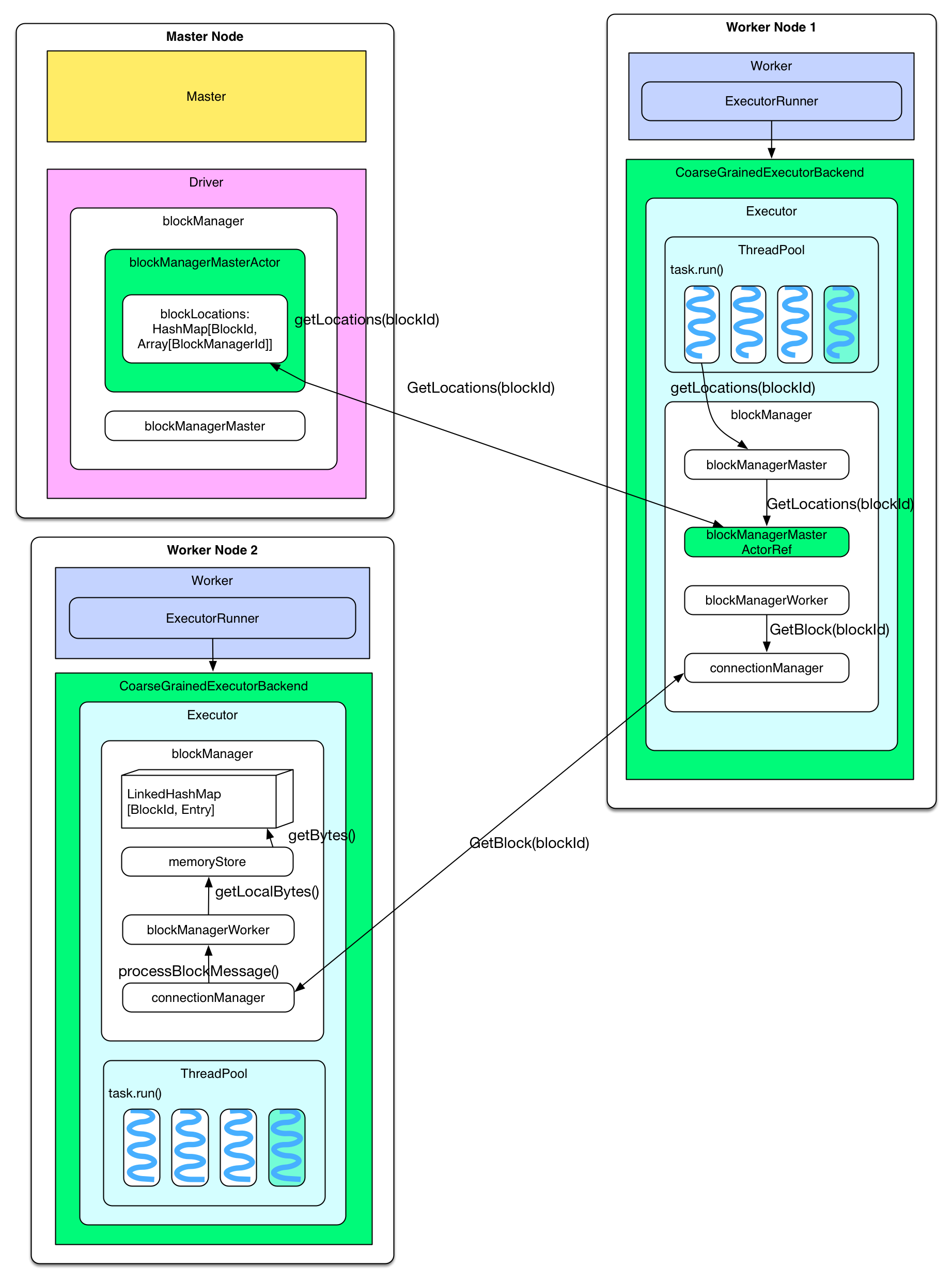
キャッシュされたPartitionの保存場所
各ノードのblockManagerがPartitionをキャッシュしたタイミングでMasterノードのblockManagerMasterActorに対してキャッシュした旨の通知を行う。通知された情報はblockMangerMasterActorの保持するblockLocations: HashMapに保持される。TaskがキャッシュされたRDDを必要とした場合、blockManagerMaster.getLocations(blockId)リクエストをDriverプログラムに対して送信し、Partitionの保存場所を取得する。その際、DriverプログラムはblockLocations`から保存場所を取得し、返す。
古いPartitionが破棄された場合場所が取得できないことになりますが、これは破棄したタイミングで同様にBlockManagerMasterに対して通知しているのでしょうか?
別ノードにキャッシュされたParititionの読み込み
キャッシュされたPartitionの場所情報を受信後、getBlock(blockId)リクエストをconnectionManagerを介して対象ノードに送信する。対象ノードはローカルのblockManager中のmemoryStoreからPartitionを取得し、返す。
ここで取得されるPartitionのサイズは相応に大きくなるはずですので、相応のサイズの応答が返される形になりますね。
Checkpoint
Q: どのような種類のRDDをチェックポイント化する必要があるのか?
- 処理に長時間がかかる場合
- 処理の連鎖が非常に長い場合
- 多くのRDDから依存されている場合
実際の所、ShuffleMapTaskの出力をローカルディスクに保存することはcheckpointでもある。但し、これはPartition単位の保存であって、RDD単位の保存ではない。
Q: どのタイミングでチェックポイント化が行われるのか?
既に記述されたように、全Partitionは算出されたタイミングでキャッシュする必要がある場合はメモリ上にキャッシュされる。だが、checkpointは異なる原理によって扱われる。代わりにcheckpointは該当Jobの終了まで待ち、checkpoint化を行うためのJobを生成する。もし異なる原理によって動作するなら、rdd.checkpoint()の前にrdd.cache()を実行していた場合、チェックポイント化するRDDは2回算出されるのかという疑問が生じる。このようなケースにおいては、後段のrdd.checkpoint()においてはRDDの再算出は行われない。代わりに、キャッシュからデータを読み込む。実際、Sparkはrdd.persist(StorageLevel.DISK_ONLY)メソッドを提供しており、初回計算時にディスク上に保持することが可能になっている。しかしながら、このpersistとcheckpointは異なる動作となる。それについては後述する。
Q: どのようにチェックポイント化の処理は実装されているのか?
下記のような流れで行われる。
RDDは[ Initialized --> marked for checkpointing --> checkpointing in progress --> checkpointed ]という流れで状態遷移を行い、最終的にcheckpointedという状態になる。
Initialized
Driverプログラムにおいてrdd.checkpoint()実行後、、RDDはRDDCheckpointDataで管理されるようになる。そのタイミングでユーザはチェックポイント化されたRDDを保持するためのHDFS上のパスを指定する必要がある。
marked for checkpointing
初期化後、RDDCheckpointDataはRDDに対してMarkedForCheckpointとマークする。
checkpointing in progress
Job実行が終了したタイミングで、finalRdd.doCheckpoint()が実行される。finalRDDは処理の連鎖を遡っていき、チェックポイント化が必要なRDDを見つけたタイミングでRDDはCheckpointingInProgressとしてマークされる。そのタイミングでHDFSへの書込み設定を保持するore-site.xml等の設定が他ノードのblockManagerに対してもブロードキャストされ、チェックポイント化のための下記のJobが起動される。
rdd.context.runJob(rdd, CheckpointRDD.writeToFile(path.toString, broadcastedConf))
checkpointed
チェックポイント化Job終了後、該当RDDの依存要素を削除し、該当RDDのステータスをcheckpointedとする。その後、該当のcheckpointRDDを親とするRDDに対して補助依存に追加し、親がcheckpointRDDであることを設定する。The checkpointRDDがそれ以後に使用された場合、チェックポイントとして保存されたファイルからRDD Partitionを生成する。
尚、下記のような興味深い事象もある。
2個のRDDがDriverプログラムにおいてはチェックポイント化する指定が行われている。だが、実際にはresultのみがチェックポイント化に成功する。バグなのか、意図的に下流のRDDのみチェックポイント化されているかはわからない。
これは以降で使用されるかということを考えると、プログラム中で再利用されているわけではないため、下流のRDDのみをチェックポイント化すれば途中経過はいらない、という動作になっているようには見えますね。
val data1 = Array[(Int, Char)]((1, 'a'), (2, 'b'), (3, 'c'),
(4, 'd'), (5, 'e'), (3, 'f'), (2, 'g'), (1, 'h'))
val pairs1 = sc.parallelize(data1, 3)
val data2 = Array[(Int, Char)]((1, 'A'), (2, 'B'), (3, 'C'), (4, 'D'))
val pairs2 = sc.parallelize(data2, 2)
pairs2.checkpoint
val result = pairs1.join(pairs2)
result.checkpoint
Q: どのようにチェックポイント化されたRDDは読み込まれるのか?
runJob()はfinalRDD.partitions()をいくつのTaskが必要になるかを確定させるために実行する。その際、rdd.partitions()はRDDが既にチェックポイント化されているかどうかをRDDCheckpointDataの管理下にあるかどうかで判定する。もしチェックポイント化されていた場合、RDD中のPartitionを(Array[Partition])として返す。rdd.iterator()が該当RDDのPartitionを算出するために呼ばれたタイミングで、 computeOrReadCheckpoint(split: Partition)も実行され、該当RDDがチェックポイント化されていないかを確認する。もしチェックポイント化されていた場合、親RDDのiterator()はCheckpointRDD.iterator()として実行される。CheckpointRDDはRDD Partitionを生成するためにファイルを読み込む。これがCheckpointRDDがチェックポイント化されたRDDとして補助的な依存として追加される理由となる。
このあたりはCheckpointRDDがどのように同一性の判定が行われるかも気になりますが、あまりチェックポイント化について情報がないのも事実ですね。
Q: cacheとcheckpointの違いはどこにあるのか?
Tathagata Das氏からの回答は下記の通り。
cacheとcheckpointの重要な違いとして、cacheはRDDをメモリ(またはDisk)に保持しているものの、RDD処理の連鎖が再実行されたタイミングで、ノード障害が発生してキャッシュしたRDDが失われていた場合、再算出が必要になるというものがある。checkpointはRDDをHDFS上にファイルとして保存し、それまでの処理の連鎖を破棄することが可能となる。これは長い処理の連鎖を途中で切り捨て、信頼性のあるHDFS上にデータを保持することでレプリケーションによる耐障害性確保が可能となることを示している。
さらに、rdd.persist(StorageLevel.DISK_ONLY)についてもcheckpointとは異なる。これまで記述してきたように、rdd.persist(StorageLevel.DISK_ONLY)はRDD Partitionをディスク上に保存し、保存されたPartitionはblockManagerによって管理される。Driverプログラムが終了したタイミングで、CoarseGrainedExecutorBackendの停止に伴いblockManagerも停止する。そのため、ディスク上に保存されたRDDも削除される。(blockManagerで管理されたローカルファイルは終了時に削除される)しかし、checkpointはファイルをHDFS、またはローカルディスクに永続化する。手動で明確に削除されない限り、ディスク上に保持され、次のDriverプログラムで使用することも可能になる。
おそらく、Driverプログラムを跨いでRDDを共有可能になる、いうのが最大の違いになるのだと思いますが、当然ながら次のDriverプログラムでのチェックポイントファイルの読み方が気になる所ですね。
まとめ
Hadoop MapReduceにおいてJobを実行する際、データを各Task、Job終了時にHDFSに確保する。Task実行時、それらのデータはメモリとディスクの間でスワップし続ける。Hadoop MapReduceにおける問題点はエラー発生時にデータの算出が必要になることで、Shuffleが途中で停止し、ディスク上に半分しか保存できなかったケースにおいて、保存されたデータについても再算出が必要になってしまう。Sparkの利点としては、エラー発生時にチェックポイントから処理を再開できるということであるが、チェックポイント化をすることによってJobを追加で実行する必要が出てくるというデメリットもある。
Example
package internals
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object groupByKeyTest {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("GroupByKey").setMaster("local")
val sc = new SparkContext(conf)
sc.setCheckpointDir("/Users/xulijie/Documents/data/checkpoint")
val data = Array[(Int, Char)]((1, 'a'), (2, 'b'),
(3, 'c'), (4, 'd'),
(5, 'e'), (3, 'f'),
(2, 'g'), (1, 'h')
)
val pairs = sc.parallelize(data, 3)
pairs.checkpoint
pairs.count
val result = pairs.groupByKey(2)
result.foreachWith(i => i)((x, i) => println("[PartitionIndex " + i + "] " + x))
println(result.toDebugString)
}
}
最後に
キャッシュと、チェックポイントの違いについて書かれた章でしたが、チェックポイントは相当長いアプリケーションになるか、またはアプリケーションを跨いで使用しない限り利点はそれほど活かせない、ということになりそうですね。
後は、アプリケーションを跨いでチェックポイントを使用するための具体的な実装方法ですが、こちらは後で調べてみるとします。
今回で残りは1章となったため、次回がSparkInternalsとしては最終回となりそうですね。