はじめに
皆さん、こんにちは。
この記事はドワンゴ Advent Calendar 2015の13日目の記事です。
注目される可能性も高い機会ですので、Apache NiFiを紹介させていただきます。
日本だと扱っている方が(おそらく)少ない関係上、日本語情報も乏しく、ほぼ全て英語情報というのは寂しい状況ですので。
ですので、もし見て興味がある方が増えればいいなぁと。そんなわけで、お付き合いください。
Apache NiFiとは?
Apache NiFiとは、一言で言うとGUIからフローが定義可能なデータフロー構築ツールです。
下記のようなデータフロー1をGUIから定義し、稼働させることが出来ます。
- ローカルファイルをHDFSに投入
- HTTPリクエストを待ちうけ、結果をファイルに出力
- Syslogを待ちうけ、結果をデータベースに投入
- Twitterからツイートを取得し、Kafkaのようなメッセージバスに投入
似た性質を持つプロダクトとしては、Node-RED、Apache ApexのdtAssemble、Cask Data Application Platform (CDAP)のHydrator等が存在します。
何故GUIからデータフローを定義することが必要なのか?
企業内のデータフローの変化が最近ますます激しくなり、素早く構築することが求められているためです。
データフロー自体が会社のビジネス的に価値を生み出すという会社は一部の会社に限られます。
あくまで、価値はデータフローが通った後のアプリケーションが生み出すものだからです。
その中で、当然ながら試行錯誤が必要となるため、データフローは何回も構築、更新、破棄が繰り返されます。
上記のような状況下でデータフロー構築をプログラムやスクリプトを毎回組んで行っていては、時間が多くかかりますし、ミスによるやり直しも多い。
そのため、最近GUIからデータフローを容易に構築し、試行錯誤が常に可能というプロダクトが登場してきたのだと考えています。
何故その中でApache NiFiがいいのか?
前述のとおり、GUIからデータフローを定義可能なプロダクトは複数あります。
その中から私がNiFiをお勧めする理由は3点です。
- 複数プロセスのクラスタリングによるスケールアウトの機構を保持
- 依存要素が少なく、該当プロダクト単体で使用可能
- 実装言語
1. 複数プロセスのクラスタリングによるスケールアウトの機構を保持している
データフローはシステム間をつなぐことになるため、システムの出力するデータ量次第では1プロセスでは対応できなくなります。
そのため、複数プロセスをクラスタリングすることでスケールアウト出来るということは重要な要件になると思います。
前述のプロダクトの中でクラスタリングによるスケールアウトの機構を持つのはApache NiFi、Apache ApexのdtAssemble、CDAPのHydratorで、残念ながらNode-REDは持っていませんでした。2
2. 依存要素が少なく、該当プロダクト単体で使用可能
システム間をつなぐ・・ということで、データフローは様々なサーバ上に構築することが多いです。
そのため、依存する要素やシステムが少なく、出来れば該当プロダクト単体で使用することが出来るのが理想です。
前述のプロダクトの中でそれを満たすのはApache NiFiとNode-RED。
Apache ApexのdtAssemble、CDAPのHydratorは名前が示すようにあるプロダクト群の一つという位置づけであり、他のプロダクトと組み合わせる必要がありました。
3. 実装言語
最後はかなりヘボい理由になりましたが、実装言語です。
Java、Scala、Groovy、ClojureといったJVM言語でないと個人的に問題発生時にそれなりに追うことは難しい・・・ということでApache NiFi、Apache ApexのdtAssemble、CDAPのHydratorの優先度が高いということになりました。
上記の3つの理由から、Apache NiFiを選んだ形になります。
あとはApache NiFiを開発しているOnyaraが2015年8月にHortonworksに買収され、Hortonworks DataFlowの基となった関係上、この後多少の期間は安定的に開発が続きそう・・という事情もありますが、それはそれで。
Apache NiFiの持つ機能の概要
Apache NiFiの保持する機能の概要は下記の通りです。
派手な機能があるわけではないですが、大規模なデータフロー構築に必要な要素は一通り揃っていると思います。
- WebベースUI
- 設計、制御、フィードバックや監視がシームレスに実行可能
- 高い設定性
- 低レイテンシと高スループットの調整
- メッセージの優先度順位付け
- フローを動作中に変更可能
- 大規模データへの対応
- バックプレッシャー機構
- クラスタリングでスケールアウト
- データ管理の明確化
- データフローをはじめから最後までトラッキング
- 拡張に対して開かれた設計
- 自前でプロセッサを開発可能
- 高速な開発と容易なテストが可能
- セキュア
- SSL、SSH、HTTPS等暗号化方式をサポート
- プラガブルなロールベースの認証/認可
Apache NiFiで実際に構築したデータフローの例
どんなものか説明した後、実際に使ってみます。
起動方法はStarting NiFiを参照してください。
起動後、起動ホストで http://localhost:8080/nifi/ にアクセスすると下記の画面が表示されるため、その上でデータフローを定義します。
実際に定義したものをいくつか挙げてみますね。
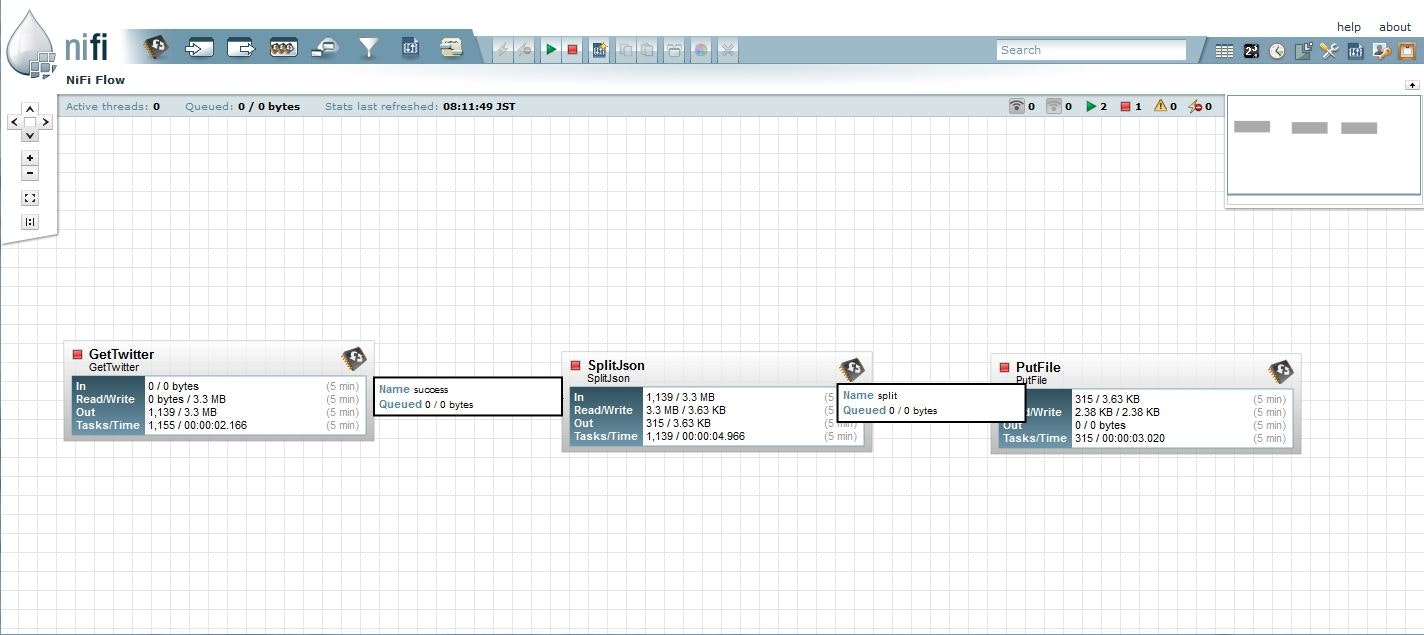
ツイートからHashTagを抽出してファイル出力
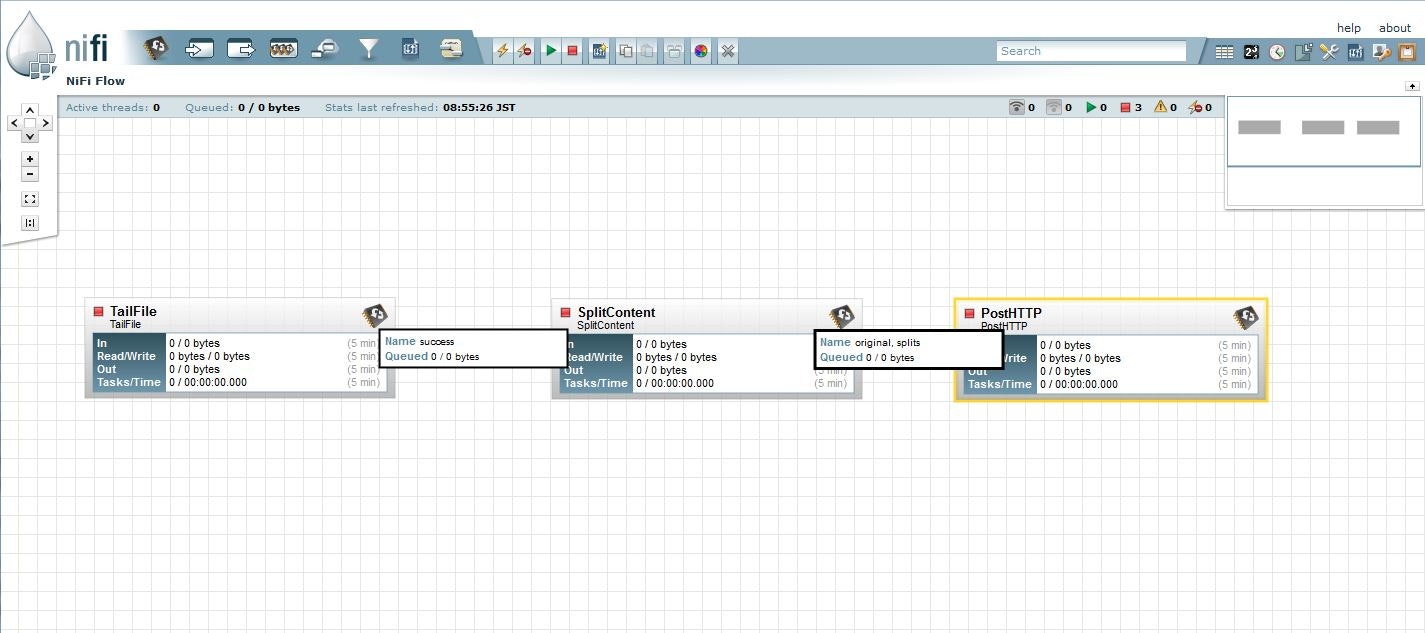
LogをTailして区切り文字で区切った上でHTTPRequest送信
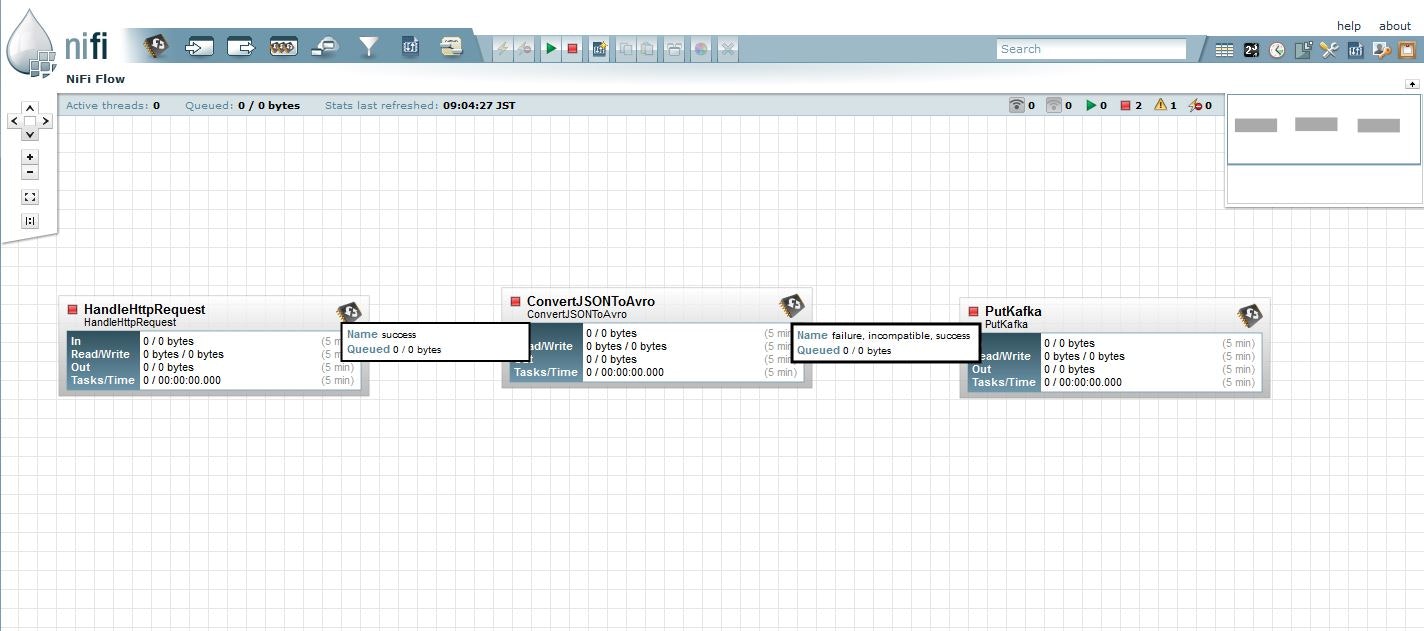
HTTPReqestを受け付け、AvroにシリアライズしてKafkaに投入
HDFSからファイルを取得し、分割してHBaseに投入
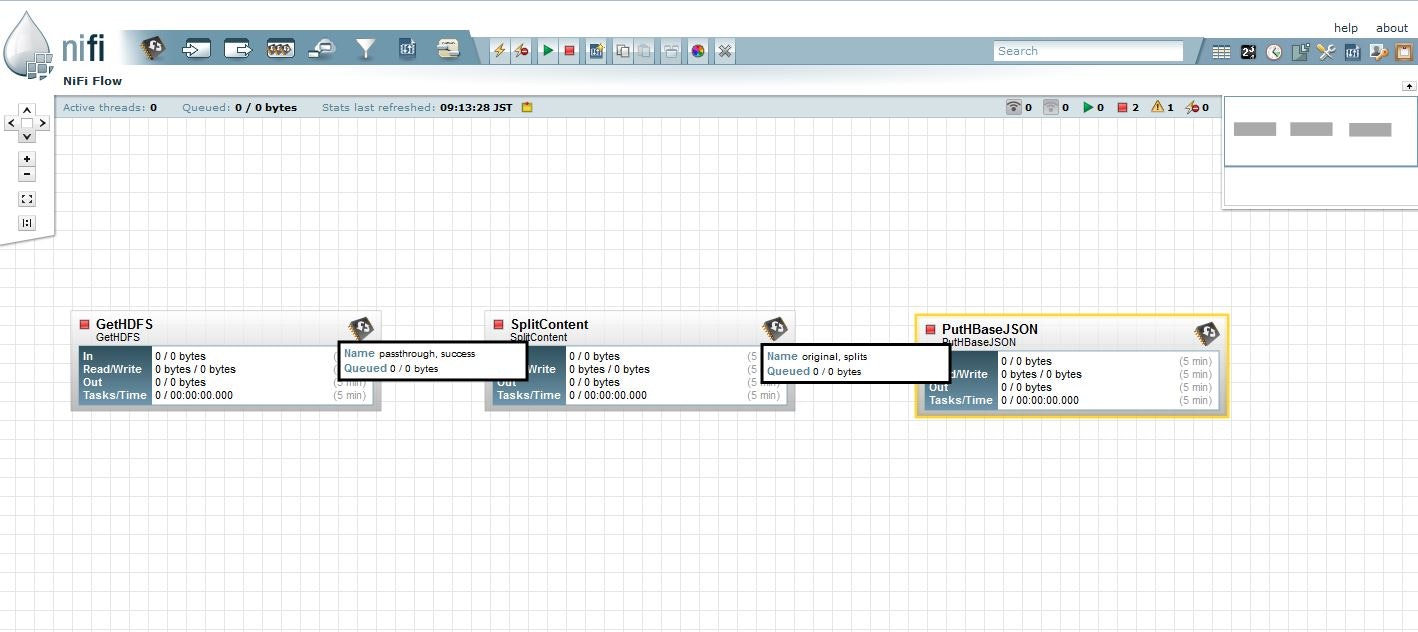
と、こんな感じのデータフローの定義が可能になります。
尚、定義しているものの性質からわかるとは思いますが、Apache NiFiはストリーム処理が基本モデルとなっています。
一応、HDFSからファイルを取得して投入とかもできますが、それも取得したファイルは消すという処理のため、あくまでHDFSもApache NiFiのデータソースとして使用する場合は一時的な保存場所という扱いのようです。
まとめ
このような形で、Apache NiFiを使うことでGUIからデータフローを容易につなげることが出来ます。
システム間のデータフローを構築するのに何かいいものがないかな、と探している方は確認していただけると幸いです。