一度NiFiで基本のデータフローを通すことが出来たので、そもそもNiFiは何ぞや、というのをOvewviewのページを読むことで確認してみます。
尚、全訳ではなく、流れや意味が大体わかればいい、というレベルの荒い訳になります。
下記のページのOverviewから確認しました。
参照:
http://nifi.apache.org/docs.html
Apache NiFiとは?
NiFiはシステム間のデータフロー自動化を行うために構築された。
データフローは様々なコンテキストで使用されるが、NiFiでは自動化され管理されたシステム間の情報やり取りフローを指す。
この問題領域はある企業でシステム間でデータの出力/入力が発生する場合には常時おこる。
解決方法は今まで継続して議論されてきており、そのながれはEnterprise Integration Patterns(EIP)にもみられる。
NiFiは下記のような高レベルのチャレンジも目指して構築されている。
・システム障害への対応
・処理可能な量以上にデータが取得されたケースへの対応
・さまざまなケースの発生(大きい、小さい、データ誤り)への対応
・データフローの高速で柔軟な更新
・システム間の疎な結合の実現
・コンプライアンスとセキュリティの順守
・プロダクション環境で発生する継続的な改善への追従
長年にわたりデータフローはアーキテクチャの中の必要悪としてみなされていた。
だが、今現在データフロー構築は企業の活動を成功させるための必須要素となり、興味深いうえに素早い更新が求められるようになってきている。
例えば、SOA、APIベースのシステム結合、IoT、BigData、あとはMicroServicesなども含まれるだろう。
加えて、今までに比べてより厳しいプライバシー制御やセキュリティ順守が求められることも追い風になっている。
これらの経緯を受けた各企業でのデータフローに求められるニーズやパターンは似通ったものとなってきている。
主な違いは個別の変換処理の複雑さや変化の頻度であるが、それは共通的なコンセプトには影響しない。
NiFiはこのようなデータフローに対する新たなチャレンジに対応するために作られている。
Apache NiFiのコアコンセプト
NiFiの基本的な設計コンセプトはFlow Based Programming(FBP)と関連が強い。
Flow Based Programmingの用語とのマッピングは下表のようになっている。
| NiFi Term | FBP Term | Description |
|---|---|---|
| FlowFile | Information Packet | FlowFileはシステム間を移動する各オブジェクトのことを示している。 NiFiではKeyValueペアで属性文字列を保持している。 |
| FlowFile Processor | Information Packet | EIPにおいてはProcessorとはルーティング、変換、システム仲介を行うものとなっている。 Processorは与えられたFlowFileの属性、およびFlowFileの流れるストリームにアクセスする。 Processorは0から任意の数のFlowFile群を処理単位として認識し、その単位で処理やコミット、ロールバックを可能とする。 |
| Connection | Bounded Buffer | ConnectionはProcessor間の実接続を示す。 Connectionはキューとして動作し、様々な処理を異なるタイミングで差し込むことが可能。 これらのキューは動的な優先度付け機構、バックプレッシャー機構を有する。 |
| Flow Controller | Scheduler | Flow ControllerはNiFi中のプロセス、スレッドの配置や接続関係について統括している。 Flow ControllerはProcessor間のFlowFileのやり取りを容易にするBrokerとして動作する。 |
| Process Group | subnet | Process GroupはプロセスとConnectionの一群を指し、外部からメッセージを受け取るInputPortや出力するOutputPortを有する。 これらの組み合わせによってProcess Groupは新たなコンポーネントの生成も可能になっている。 |
この設計コンセプトはsedaとも似ている。sedaからNiFiは様々な設計に関するアイディアをえている。
例えば下記のような。
- 有向グラフの可視化、管理方法
- データ量が常時変動するデータフローをどう非同期並列に高スループットで処理するか
- 開発者に煩わせることなく如何に並列実行モデルを構築するか
- 疎結合、密結合なコンポーネントが混在する中如何に再利用性が高く、テストしやすい設計にするか
- 接続中のバックプレッシャーや自然な実行再開の方針
- 粒度の大きな例外処理でなく、きめ細やかなエラーハンドリングの実現方針
- プロセスからのデータの入出力フローを理解しやすくトラッキングするか
NiFiのアーキテクチャ
NiFiのプロセスは下図のようなアーキテクチャとなっている。
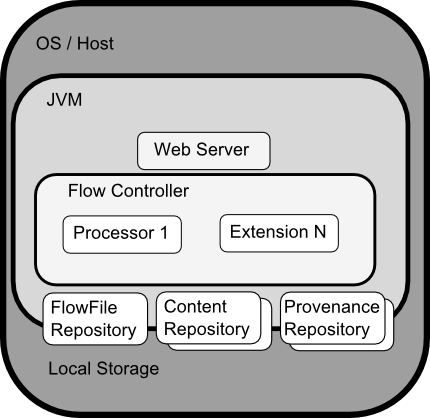
NiFiはホスト上に起動したJVMプロセスの中で動作しており、主要なコンポーネントは下記のような役目を持つ。
- WebServer
NiFiのHTTPベースのコマンド/制御APIのハンドリングを行う。 - Flow Controller
オペレーション上の頭となる。起動しているスレッドの管理と、いつ実行するかの制御を行う。 - Extensions
後述されるNiFiの拡張ポイントで、JVM上で実行される。 - FlowFile Repository
NiFiの現状アクティブなFlow上を流れているFlowFileのトラッキングを行う。プラグイン機構で出力方式を選べるようになっており、デフォルトではWAL方式でローカルストレージに出力する。 - Content Repository
現状流れているFlowFileが保持する実Contentを保持する。プラグイン機構で出力方式を選べるようになっており、デフォルトではシンプルにローカルストレージに出力するのみだが、ストレージの数に応じて分散して出力が可能。 - Provenance Repository
イベントの元データを保持する。出力方式についてはContent Repositoryを同様。
NiFiは単一JVM上だけでなく、複数プロセスにクラスタリングして用いることも可能となっており、構成は下図のとおりとなる。
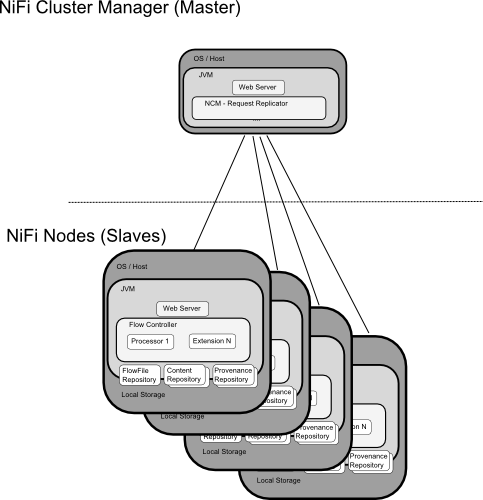
NiFiクラスタは1個以上のNiFi Nodeから構成され、NiFi Cluster Manager(NCM)から制御される。
NCMとNiFi Nodeはシンプルなマスタスレーブ構成となっている。
NCMはクラスタ上に所属するNodeの存在やステータス管理、フロー制御用リクエストのレプリケーションのために存在している。
基本的にNCMはクラスタ内の状態の一貫性を保つための存在であり、マスターがダウンした場合スレーブはそれまで保持していたフローを維持し続ける。
マスターがダウンした際の影響は単純に新たなスレーブの参加と既存のフローの変更が出来ないのみ、となっている。
NiFiのパフォーマンス上の期待/特徴
NiFiの設計方針として、NiFiが動作しているホスト上の性能を使い切るように作られている。
特にCPUとDiskに負荷がかかる処理モデルとなっている。詳細は管理者ガイド参照。
For IO
スループットやレイテンシはシステム構成に大きく依存する。
NiFiのサブシステムのIO部分はプラグイン構成となっており、どのプラグインを利用するかで大きく変動するが、デフォルト構成ではローカルディスクに保持するため、その構成での値について述べる。
大まかに言って、1本のディスクでは50MB/秒程の書込み読込みが可能になっているが、大規模なフローをNiFiで制御する場合100MBかそれ以上のスループットは必要となる。
NiFi自体はディスクの追加でほぼ線形にスループットが向上するため、ディスクを追加してやればいい。
尚、実際にボトルネックとなるのはFlowFile repositoryとProvenance repositoryとなる。
現在パフォーマンステスト用のテンプレートをビルド媒体に含めることを計画中であり、それが完了すればシステム管理者はより容易に構成変更によるインパクトを理解できるようになるだろう。
For CPU
Flow Controllerが各Processorへのスレッドの紐づけを行っている。
各Processorは自前の処理が完了したら即returnしてスレッドを変換する構成となっている。
Flow Controllerは設定に応じてスレッドプールのサイズを調整しているが、当然ながら実際に並列実行できるスレッド数はホストが保持しているコア数や同時稼働しているサービス等に依存する。
ただ、典型的なIOが重いフローにおいてはスレッド数は大目に割り振っておいても基本的には問題ない。
For RAM
NiFiはJVM上で動作しているので、一般的なJVMアプリケーションと同様のGC性質を持つ。
NiFiのKey Feature
メッセージの処理保証
NiFiの基本哲学として、大規模システムへのスケールとメッセージの処理保証は必須となる。
メッセージの処理保証はContent RepositoryのWAL方式の出力によって効果的に達成されている。
同時に、非常に高いトランザクション性能要求、負荷分散、Copy-On-Write、HDDの強みを生かす書込み読込み方針が入れ込まれている。
バックプレッシャー/プレッシャーの解放を伴うデータバッファリング
NiFiはデータのバッファリングをサポートしており、特定容量や保存期間に応じたバックプレッシャーをかけることが可能になっている。
優先度つきキュー
NiFiはデフォルトではキューイングされたデータは古い順に処理するが、新しい順に処理する、データの大きい順に処理するといった優先度付け戦略を保持しており、それは拡張可能。
フロー別のQoS設定
データフローにはデータの欠損を防止することを最優先したいフローや、一定時間内に処理することを最優先したいフローなどが存在する。NiFiはフロー毎にこれらのニーズに寄せた設定が可能になっている。
データの発生元確認
NiFiはデータの発生元を自動的に記録し、システム間のデータフローを通しても利用可能にしている。
これはコンプライアンスやトラブルシューティング、最適化等に用いることができる。
きめ細かい履歴のバッファリング/復旧
NiFiのcontent repositoryは履歴のローリングバッファとして動作する。
データは保存期間が過ぎた場合、処理完了した場合や容量が不足した場合に削除される。
この機能はデータの発生元保持機能と併せてデータの確認や保存、世代ごとのライフサイクル管理に非常に有用となっている。
画面上での制御やコマンド実行
データフローは複雑であるため、可視化することは理解や定義を容易にし、ミスも削減することが出来る。
NiFiでは画面上に可視化するだけでなく画面上の操作をリアルタイムに反映するようになっており、定義してデプロイする、というユースケースに比べて圧倒的に構築が容易になっている。
データフローを変えたなら即それがコンポーネント単位に隔離されて反映されるようになっている。
全体を止めることなくデータのフローを試しながら変えることができる。
セキュリティ
システム間の暗号化
データフローは使いやすいだけでなく、セキュアでないといけない。
NiFiのEntryPointの通信は様々な方式で暗号化が可能になっている。
加えて、NiFi中を流れているContentの暗号化も可能になっている。
ユーザから利用する際の暗号化
NiFiは基本的なアクセス経路の暗号化だけでなく、ユーザごとに可能なオペレーションや見える範囲がプラグイン機構で定義可能になっている。
また、パスワードのような後で見られたくない値を入力する場合、入力した段階でハッシュ化されて保持され、直接は確認できない状態になる。
拡張可能な設計
拡張ポイントの設計
Processors, Controller Services, Reporting Tasks, Prioritizers, Customer User Interfacesといった様々な拡張ポイントを設けている。
クラスローダー隔離
様々なコンポーネントベースのシステムにおいて、依存性の悪夢は皆経験したことがあると思う。
NiFiはExtension毎にクラスローダーを区切るモデルになっており、Extension毎のライブラリ同士の競合を極力減らせるようになっている。
このExtension管理の機構は「NiFi Archives」と呼ばれており、詳細は開発者ガイドに記述されている。
クラスタリング(スケールアウト)
NiFiは複数のノード上にスケールアウトし、性能を高められる構成になっている。
例え1ノードのスループットが100MB/sであったとしても、ノードを重ねればGB単位のスループットを達成できる。
当然その中でノード間のロードバランシングやデータ取得のフェールオーバー機構は興味深い挑戦として立ちはだかってくる。
現状は、非同期型キューイングを行えるKafkaのようなメッセージング基盤と連携することで補足可能となっている。
また、NiFiの保持するSite-to-Siteの機構を用いることで複数のNiFi間の負荷情報を共有してバランシングするという機構もまた有効になると思われる。
まとめ
というわけで、NiFiのOvewviewについて確認してみました。
とりあえず、NiFi上にどういうコンポーネントが存在し、どう動いているかの概要はこれで見えてくる感じでしょうか。
あとは、拡張部分や詳細なチューニングについては今回の内容だとさっぱりですので、それは今後見ていく必要がありそうですね。
次は「Getting Started」を改めて流してどんなウィンドウや機能があるかを試してみるか、あたりでしょうか。