こんにちは。
前回Gearpumpがどういうものか、の概要がわかったので、今回は概要構成を見て行こうと思います。
参照しているのは前回と同じくGearpumpのサイトですが、下記の流れで見ています。
- Gearpump Basic Concepts
- Gearpump Technical Highlights
- Reliable Message Delivery
- Gearpump Performance Report
- Gearpump Internals
Gearpump Basic Concepts
System timestamp and Application timestamp
System timestampはバックエンドのクラスタの時間を示す。Application timestampはメッセージの生成時刻を示す。
例として、IoTのエッジデバイスにおいてデバイスがメッセージを生成したタイミングの時刻がApplication timestampとなる。
バックエンドが受信したタイミングで割り振られる時刻がSystem timestampとなる。
Master, and Worker
Gearpumpはマスタ/スレーブアーキテクチャで構成されている。各クラスタは1個かそれ以上のMasterノードといくつかのWorkerノードで構成される。Workerノードはあるマシンにおけるリソース管理を行い、Masterノードはクラスタ全体のリソースの管理を行う。
Application
Applicationはクラスタ上で並列実行したい単位となる。アプリケーションにも異なるタイプが存在する。例えば、MapReduceアプリケーションとStreamingアプリケーションは異なる型のアプリケーションとなる。GearpumpはStreamingアプリケーションを基本サポートの対象とし、distributedShellのようなカスタム型のアプリケーションを作成するためのテンプレートも提供する。
AppMaster and Executor
Application instanceは実行状態において、1個のAppMasterとExecutorのリストで表すことができる。AppMasterはコマンドとApplication instanceの制御センターとして表すことができる。AppMasterはユーザ、Masterノード、Workerノード、Executorと各種コマンド実行のために通信を行う。各Executorは分散されたApplicationを実行する並列ユニット。典型的にはAppMasterとExecutorはWorkerノード上のJVMプロセスとして起動される。
Application Submission Flow
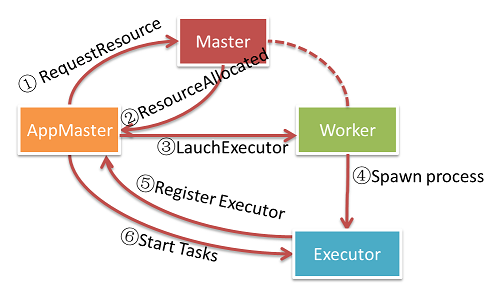
ユーザがApplicationをMasterノードに対して投入した際、Masterノードは利用可能なWorkerノードを探し、AppMasterを起動する。AppMasterは起動後、Masterに対してExecutorを起動するためのリソース(Workerノード)の要求を行う。この時点だとExecutorは単なる空のコンテナの状態で起動される。Executor起動後、AppMasterは実際の計算TaskをExecutorに分配し、並列実行させる。
Application投入にあたり、GearpumpクライアントはDAG内で定義されたコンピューティングを指定し、ActiveなMasterノードに投入する。SubmitApplicationメッセージはMasterに送信後、AppManagerに対して転送される。
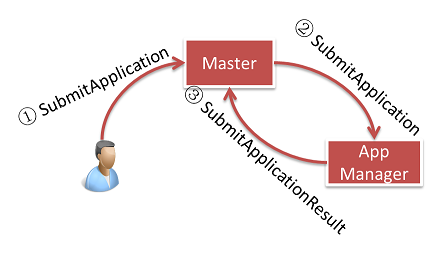
AppManagerは利用可能なWorkerノードを探し、Workerノード上のJVMのサブプロセスとしてAppMasterを起動する。AppMasterはMasterと通信してApplicationで定義されたDAGを割り振るためにリソースを確保する。割り振られたWorkerノードはExecutorを新規JVMプロセスとして起動する。
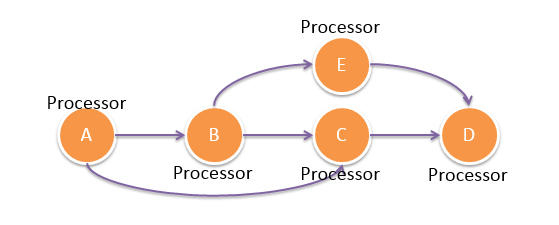
Streaming Topology, Processor, and Task
Streamingアプリケーションにおいて、各アプリケーションはTopology(DAGで記述されたDataFlow)を含む。DAG上の各ノードはProcessorとなる。WordCountを例にとると、WordCountは2個のProcessor、SplitとSumで構成される。Split Processorは各行を単語のリストに分割し、Sum Processorは各単語の発生頻度をまとめる。
アプリケーションはProcessorのDAGであり、各Processorがメッセージを処理する。
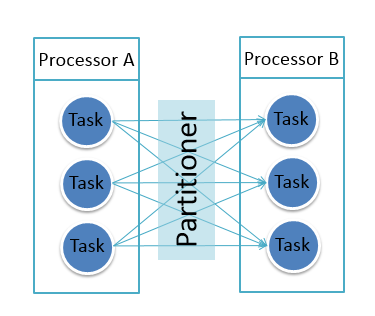
Streaming Task and Partitioner
Streamingアプリケーションにおいて, Taskは並列実行の最小単位となる。実行中、各ProcessorはTaskのリストとして並列化され、異なるTaskは異なるExecutorで実行される。その際、Partitionerを定義することで、上流ProcessorのTaskから下流ProcessorのTaskにメッセージを送信するための分配ルールを示すことができる。
Gearpump Technical Highlights
Actors everywhere
ActorモデルはCarl Hewittによって提案された並行モデル。ActorモデルはあるActor単位で凝集され、外部のActorから隔離されたMicroServiceのようにふるまう。ActorはGearpumpの礎となっており、メッセージ送受信、エラーハンドリング、生存確認といった機能を提供する。GearpumpはActorを様々な機能で使用しており、クラスタ内の全EntityはServicwとして扱うことができる。
Exactly once Message Processing
"Exactly once"は以下のように定義される。
メッセージに伴う作用が出力先か、または履歴中のエラーとして1回だけ処理され、以後の処理には影響を及ぼさない。
詳細は後述されています。
Topology DAG DSL
ユーザはGearpumpに対して演算DAGを投入でき、演算DAGはnodeとedgeのリストを含み、nodeはTaskの集合として並列実行される。Gearpumpは各マシンに各タスク群を自動的に分配する。各TaskはActorとして起動し、長期実行されるMircoServiceとして振る舞う。
Flow control
Gearpumpにはフロー制御機能が組み込まれている。異なるTask間で送受信される全メッセージに対して、上流のTaskが下流のTaskを溢れないようにすることを保証している。
No inherent end to end latency
Gearpumpはメッセージ単位のStreamingエンジンで、それはDAG中の全Taskがメッセージ受信時即時処理し、処理したら下流にメッセージを即時送信するということを示す。Gearpumpはデータが蓄えられていた場合でもバッチ処理は行わない。
High Performance message passing
スマートなバッチ戦略を用いることにより、Gearpumpは小さいサイズのメッセージを送受信するのに非常に効率的となっている。4マシンを用いたあるテストにおいて、クラスタ全体のスループットは100バイトのメッセージを1800万メッセージ/秒となった。
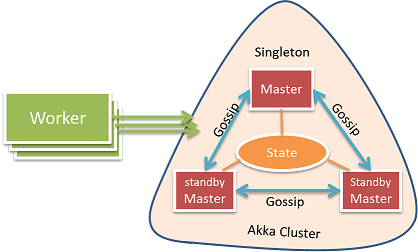
High availability, No single point of failure
Gearpumpは高可用性に配慮した設計となっている。障害としてはメッセージ欠損、Workerノードクラッシュ、Applicationクラッシュ、Masterノードクラッシュ、スプリットブレインを考慮しており、それらの障害が発生した場合に復旧する機構を備えている。
- メッセージ欠損が発生した場合は再実行
- WorkerノードやApplicationクラッシュの場合は新たなマシン上でリスケジュール
Masterの高可用性のために、Akka clusterとCRDTs(conflict free data types)で状態同期をした複数のMasterを用いている。この機構によって、障害発生時もクォラムは存続し、Masterとしての機能は維持される。1Masterノードに障害が発生した場合、Akka Cluster中の他のMasterノードが引き継ぎ、状態を復旧させる。
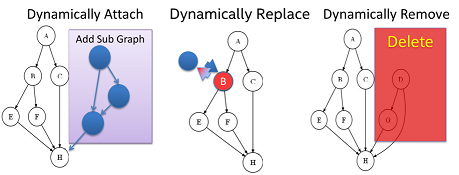
Dynamic Computation DAG
Gearpumpは実行中にTopology全体を再起動しなくてもDAG中のサブグラフを動的に追加、削除、更新を可能にする機能を提供している。
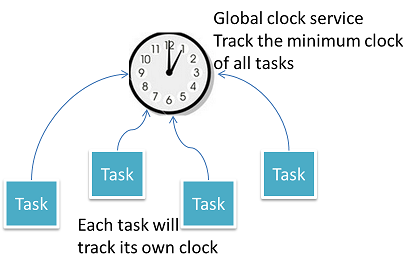
Able to handle out of order messages
スライディングウィンドウの平均のようなWindow Operationはあるタイムウィンドウにおける受信した全メッセージの正確な結果を得るために重要な要素となっている。ただ、その場合遅れて到着したメッセージへの対応はどうなるのか?Gearpumpは全メッセージのtimestampの最低値を常にTrackすることでその問題を解消しており、あるタイムウィンドウ間において処理されたメッセージがすべて処理されているか否かを知ることができる。
Customizable platform
異なるアプリケーションは性能メトリクスについても異なるものが必要となる。(例:スループット、強い結果整合性等)
また、どのようなリソースを必要とするかについても異なってくる。(例:CPUリソース、データ局所性)
Gearpumpは性能メトリクスやリソーススケジューリング戦略をカスタマイズ可能とすることでそれに対応している。
Built-in Dashboard UI
Gearpumpはクラスタの管理と可視化のためにダッシュボードUIを備えている。
ダッシュボードUIはバックエンドとはREST通信で情報のやり取りを行っているため、新たに異なるダッシュボードを作成してそちらで用いることも可能になっている。
Data connectors for Kafka and HDFS
GearpumpはKafkaとHDFSに対するデータコネクタを備えている。
Kafkaコネクタに対してはある特定のTimestamp以降のメッセージ再取得を行うことが可能となっている。
Reliable Message Delivery
What is At Least Once Message Delivery?
メッセージはネットワーク分断などによって欠損する場合がある。
**At Least Once Message Delivery(at least once)**は欠損したメッセージが少なくとも1回Ackが返るように1回以上処理される。
Gearpumpは過去の時刻のメッセージを再取得できるDataSourceに対し、at least onceのモデルを保証する。Gearpumpでは、各メッセージはtimestampでタグ付され、現在処理中のメッセージの中で最も小さいtimestamp(global minimum clock)をTrackingする。メッセージの欠損が発生した場合、Applicationはglobal minimum clockの値を用いて再起動する。DataSourceはglobal minimum clockを用いて再度メッセージの取得が可能であるため、再起動前に処理中だったメッセージはすべて再実行される。Gearpumpにおいてはこの種別のDataSourceをTimeReplayableSourceと呼ぶ。既存のTimeReplayableSourceとしては、KafkaSourceがある。KafkaSourceを用いてGearpumpに対してメッセージを取り込むことで、at least onceなメッセージ処理を可能とする。
What is Exactly Once Message Delivery?
At least onceのモデルはアプリケーションの実行結果の正しさを保証しない。例えば、受信メッセージ数を記録するTaskが存在した場合、メッセージの再実行が行われた場合には重複して処理され、Taskに障害が発生した場合も受信メッセージ数は失われる。
このようなケースにおいては**Exactly Once Message Delivery(exactly once)**という状態がメッセージによって1回だけ更新されるようなモデルが求められる。更に、重複して処理されたメッセージがフィルタリングされ、メモリ上の状態も永続化することが求められる。
Gearpumpにおいては、下記の2つの条件を満たす場合のみ、exactly onceのモデルが使用可能になる。
-
TimeReplayableSourceを用いてデータの取得を行っている - メモリ上の状態値を管理するためにPersistent APIを用いて保存する
Persistent APIを用いることで、ユーザの状態値はGearpumpによって定期的にCheckpoint時刻とともにHDFSなどに保存される。Gearpumpは現在処理中の状態値に対してすべてglobal minimum checkpoint timestampを保存し、永続化する。アプリケーション再起動時、Gearpumpはglobal minimum checkpoint clockから状態を復元し、復元した値を用いてメッセージの再実行を行う。それによって、全「状態値」が一度だけ更新されることを保証する。
Persistent API
Persistent APIはPersistentTaskとPersistentStateで構成される。
下記にこれらを用いて入力メッセージ数を保存する例を示す。
class CountProcessor(taskContext: TaskContext, conf: UserConfig)
extends PersistentTask[Long](taskContext, conf) {
override def persistentState: PersistentState[Long] = {
import com.twitter.algebird.Monoid.longMonoid
new NonWindowState[Long](new AlgebirdMonoid(longMonoid), new ChillSerializer[Long])
}
override def processMessage(state: PersistentState[Long], message: Message): Unit = {
state.update(message.timestamp, 1L)
}
}
CountProcessorはカスタマイズされたPersistentStateを生成する。PersistentStateはPersistentTaskによって管理され、processMessageメソッドを継承し、新規メッセージによる状態更新の動作を定義する。 (上記事例においては新規メッセージのカウントは1となり、それが既存の値に追加される。
Gearpumpは下記の2つのStateを提供している。
- NonWindowState - 時間と関係ない、または時間以外の区切りで区切られるState
- WindowState - TimeWindowによって区切られたState
これらは下記のようなモノイド則を満たすStateとして示される。
- +のような結合法則を満たす演算子を持つ
- 0のような基準値を持つ
上記の例においては、便利なモノイド群を提供しているライブラリ、Twitter's AlgebirdからlongMonoidを使用している。
Gearpump Performance Report
Performance Evaluation
Gearpumpの性能について、SOL(Gearpumpのサンプルプロジェクト参照)と呼ばれる非常にシンプルな構造を持つマイクロベンチマークを用い、主に2つの側面であるThroughputとLatencyに焦点をあてて示す。
SOLStreamProducerはメッセージをSOLStreamProcessorに絶えず送信し、SOLStreamProcessorは何もしない構成となっている。
4ノードのクラスタ(10GbEネットワーク)を用意し、確認を行った。
各ノードのハード構成は下記の通り。
Processor: 32 core Intel(R) Xeon(R) CPU E5-2690 2.90GHz
Memory: 64GB
Throughput
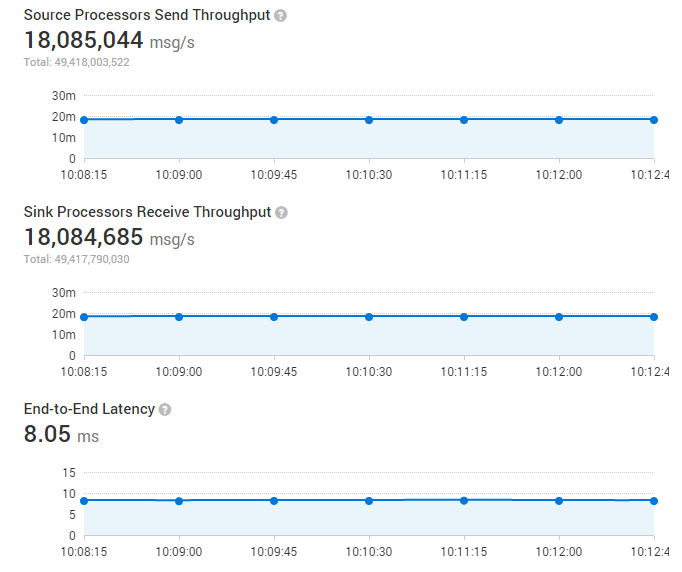
検証において、スループットの上限を確認しようとしたところ、48SOLStreamProducerと48SOLStreamProcessorを起動した所で下記に示されるとおり、クラスタ全体で1800万メッセージ/秒に達した。(各メッセージは100バイト)
Latency
最大スループット状態になった際に、2Task間の平均Latencyは8msとなった。
Fault Recovery time
障害、例えばExecutorのダウンが検知された場合、Gearpumpはリソースを再割り当てしてアプリケーションを再起動する。
アプリケーション再起動には10秒かかった。
How to setup the benchmark environment?
Prepare the env
-
4ノード(10GbEネットワーク)のGearpumpクラスタを各ノードにおいて各々4Workerを起動する構成で構築した。テスト環境においては各マシンは64GBのメモリとIntel(R) Xeon(R) 32-core processor E5-2690 2.90GHzの構成。Gearpump上でメトリクスを有効化した状態で実施する。
-
下記のコマンドで48 StreamProducersと48 StreamProcessorsを有するSOLアプリケーションを投入。
bin/gear app -jar ./examples/sol-$VERSION-assembly.jar -streamProducer 48 -streamProcessor 48
- Gearpumpのダッシュボードを起動し、http://【起動ホスト】:8090/に接続する。Applicationsタブに切り替えるとApplicationの詳細が確認可能となる。
Gearpump Internals
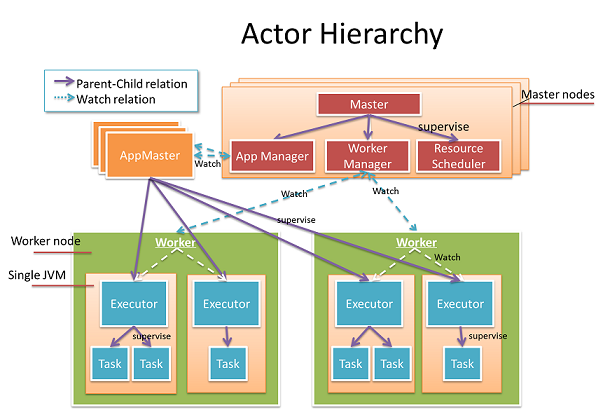
Actor Hiearachy?
上記の図の中のすべてはActorとなっている。
Actor群は2つのカテゴリ、Cluster ActorsとApplication Actorsに分けることができる。
Cluster Actors
Worker: 物理Workerマシンにマッピングされる。Workerはローカルマシンのリソース管理とメトリクス報告を担当する。
Master: Clusterの心臓部にあたり、Worker、リソース、Applicationの管理を行う。主要な機能は3個の子Actor、AppManager、WorkerManager、ResourceSchedulerに移譲される。
Application Actors:
AppMaster: WorkerへのTask割り振り、Applicationの状態管理を担当する。異なるApplicationは異なるAppMasterを保持し、互いに独立している。
Executor: AppMasterの子にあたり、JVMプロセスを表す。Taskのライフサイクル管理とTaskに障害発生時の復旧を担当する。
Task: Executorの子にあたり、実処理を行う。全TaskActorは各自グローバルなユニークアドレスを保持する。あるTask Actorは他のTask Actorに送信することができる。この機構により、コンピューテーションDAGを如何に分散させるか、について大きな柔軟性を得ている。
DAGの全ActorはActorのSupervisorと共に組み込まれており、SupervisorはActorのモニタリングとエラーの正しいハンドリングを行う。Masterにおいて、リスクのあるジョブは隔離されて子Actorに移譲することで頑健性を確保している。アプリケーションにおいて、追加中間レイヤ"Executor"が作成され、このレイヤによってきめ細かい扱いとTask障害時の早期の復旧が可能になっている。MasterはAppMasterとWorkerのライフサイクルを障害対応のために監視するが、これらのライフサイクルはSupervisorによって行われ、Masterに紐づけられているわけではない。そのため、Master自身が障害が発生した場合も他に影響を与えることはない。いくつかのMaster ActorがAkka clusterによって構成され、Masterの状態はゴシッププロトコルを用いてCRDTによって同期されるため、障害に対する単一障害点は存在しない構成になる。このような階層化された設計に依り、高い可用性を達成している。
Application Clock and Global Clock Service
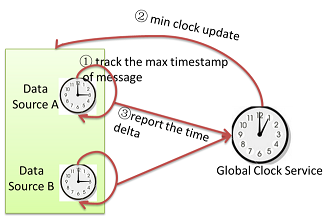
Global clock serviceはシステム中で処理中のメッセージの中で最も小さなtimestampをトラックする。各TaskはTask自身の最小クロックをGlobal clock serviceに通知しする。各Taskの最小クロックは下記の中で最小のものが使用される。
- Inbox中に存在する処理待ちメッセージの中で最小のTimestampを持つメッセージのTimestamp
- 送信したメッセージの中で、Ackが返ってきていないメッセージの中の最小のTimestampを持つメッセージのTimestamp。もしメッセージの欠損が発生した場合、最小クロックは進めない。
- Taskが保持する「状態」の中での最小クロック。もし状態が複数の入力メッセージによって積算される場合、最小クロックの値は最後に積算されたメッセージのtimestampによって決まる。「状態」のクロックは状態をスナップショットとして保存するか、メッセージがTimeWindowの範囲からフェードアウトした場合に更新される。
Global clock serviceは全Taskの最小クロックを効率的にトラックし、全体としての最小クロックを維持する。Global minimum clock valueは単調に増加するのみの存在で、それはDataSource中のこの値よりも前の時刻を持つメッセージは全て処理完了していることを示す。メッセージ欠損、またはTask障害が発生した場合、Global minimum clockは停止する。
How do we optimize the message passing performance?
Streamingアプリケーションにおいて、メッセージの送受信のパフォーマンスは非常に重要な要素となる。例えば、あるStreaming基盤が毎秒何百万ものメッセージをミリ秒レベルのレイテンシで処理しなければならないケースを考える。高スループット、低レイテンシを達成するのは簡単なことではない。
Gearpumpにおける挑戦の過程を如何に示す。
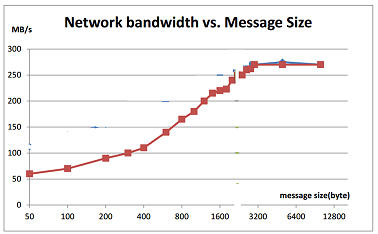
First Challenge: Network is not efficient for small messages
Streaming処理において、典型的なメッセージのサイズは非常に小さく、走行車のGPSデータのように1メッセージあたり100バイト未満ということも普通にある。だが、ネットワークの効率性は小さいメッセージを送信する場合、非常に悪い。下記のグラフからわかるように、メッセージサイズが50バイトの場合、ネットワーク帯域の20%しか使用することが出来ない。
どのようにスループットを改善すればいいのだろうか。
Second Challenge: Message overhead is too big
各メッセージを2Actor間で送受信する場合、メッセージにはSenderとReceiverのPathが含まれる。ネットワークを介して送信する場合、このActorPathによるオーバーヘッドの影響は大きい。例えば、下記のActorPathは200バイトを超過してしまう。
akka.tcp://system1@192.168.1.53:51582/remote/akka.tcp/2120193a-e10b-474e-bccb-8ebc4b3a0247@192.168.1.53:48948/remote/akka.tcp/system2@192.168.1.54:43676/user/master/Worker1/app_0_executor_0/group_1_task_0#-768886794
How do we solve this?
我々はGearpumpにおいてカスタマイズしたNetty転送レイヤの開発をAkka Extensionを用いて行った。下記の図のように、Netty ClientはActorPathをTaskIdに翻訳し、Netty Serverにおいてそれを復元する。TaskIdのみがネットワーク上を通過し、サイズは10バイト程に抑えることが出来、オーバーヘッドを最小化する。異なるNetty Client Actorsはお互いに隔離されており、互いにブロックすることはない。
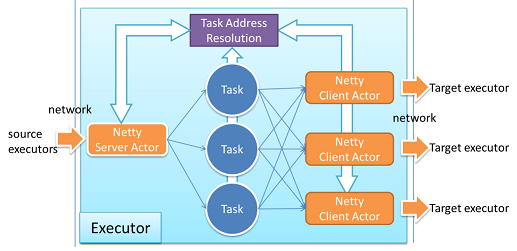
パフォーマンスを引き出すために効率的なバッチ化は重要なキーファクターとなる。我々は複数のメッセージをバッチ化し、ネットワーク上に送信している。バッチサイズは固定化されておらず、ネットワークの状態に応じて動的に調整される。ネットワークが利用可能な状態においては送信待ちのメッセージを特に待つことなしに送信する。そうでない場合はメッセージをバッチ化し、一定時間後にそのバッチを送信するようトリガーを仕掛ける。
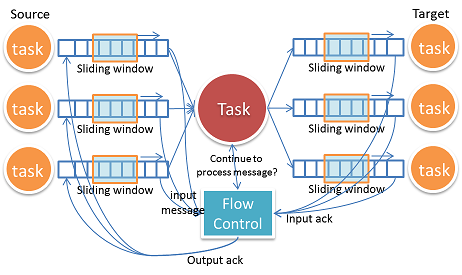
How do we do flow Control?
フロー制御がない状態ではあるTaskは大量メッセージが他のTaskから送信されてきた場合にOOMEをおこしてあふれてしまう。典型的なフロー制御はTCPのようなSlidingWindowを使用し、送信元と送信先は互いにブロックすることなく実行することが出来る。
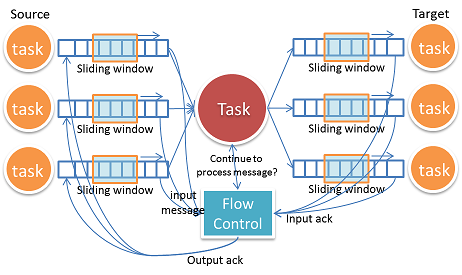
Gearpumpにおいて抱えていた問題で困難な点として、あるTaskは複数の入力Taskと出力Taskを持つということ。
下流から上流へのバックプレッシャーを伝播させるために入力と出力は連動させる必要がある。加えて、フロー制御は障害発生のことも考慮する必要があり、メッセージ欠損が発生した場合に復旧する機構も必要となる。
更なる挑戦として、フロー制御のためのメッセージによるオーバーヘッドの増大がある。もし各メッセージに対してAckを返していた場合、システム上を大量のAckメッセージが飛び交うこととなり、Streamingのパフォーマンスを減衰させてしまう。最終的に採用したアプローチは明示的なAckリクエストメッセージを用いるというもの。対象TaskはAckリクエストメッセージを受信した場合のみAckを返し、送信元はAckリクエストを必要なケースにのみ送信する。このアプローチにおいて、オーバーヘッドを多く削減することが出来た。
How do we detect message loss?
例えば、Web adsにおいては全クリックをカウントする必要があり、ミスカウントをしたくない。Streaming基盤においてはどのメッセージが欠損したかを効果的にトラックする必要があり、可能な限り早く復旧させる必要がある。
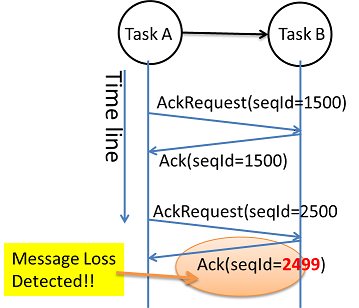
我々はフロー制御メッセージをAckリクエストとAckに用い、メッセージ欠損を検出している。対象Taskは前回のAckリクエストを受信してから何個のメッセージを受信したかをカウントし、送信元に返す。送信元はその値を確認することで、メッセージの欠損が発生しているかを検出する。
上記は単純化したイラストで、実際のケースはより複雑だが、ゾンビ化したTaskや処理中の古いメッセージに対応する必要がある。
How Gearpump know what messages to replay?
アプリケーションによってはメッセージの欠損が許されず、再実行すべきものがある。例えば、送金処理において、銀行はSMSで検証コードを利用者に送信する。このメッセージが欠損した場合、システム側は送金を継続するために再実行する必要がある。
我々はsource end message storageとtime stamp based replayのアプローチをとっている。
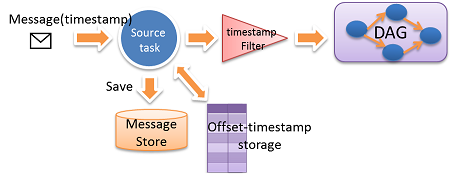
全メッセージはイミュータブルであり、Timestampでタグ付される。このTimestampはおおよそインクリメンタルであるものと仮定する。(多少の前後は許容する)
Gearpumpにおいてはメッセージを再取得可能なDataSource(例:Kafka)から取得するか、そうでない場合はカスタマイズ可能なDataSourceのmessage storeに保存することで、メッセージの再実行を保証する。送信元Taskが下流にメッセージを送信したタイミングで、TimestampとメッセージのOffsetがoffset-timestamp storageに定期的に保存される。復旧を行う際ははじめにoffset-timestamp storageからtimestampとoffsetの取得を行い、その値を用いてMessageStoreからデータを取得することでメッセージの再実行を行う。Timestampフィルタはメッセージが厳密な時間オーダーになっていない場合でも前後したメッセージを除去し、不要な再実行を抑止する。
Master High Availability
分散Streamingシステムにおいて、システムの各部分は常に障害が発生しえる。そのため、システムは様々なケースのエラーに対して対応し、復旧する必要がある。
GearpumpではMasterの高可用性確保のためにAkka clusteringを使用している。このClusterはいくつかのMasterで構成される。(Workerは含まれない)Clusteringの機能により、Masterのクラッシュを容易に検知し、対応することが可能となっている。Masterの状態はakka-data-replicationを用いて全Masterにレプリケーションされており、あるMasterがクラッシュしても他のMasterが状態を取得し、元のMasterを引き継ぐことが可能となっている。Masterの状態は全アプリケーションの投入情報を含んでいる。もしあるアプリケーションが停止した場合、Masterノードは投入情報を用いてアプリケーションを復元することが可能となっている。CRDT LWWMap (last writer wins map)をこの状態を示すために用いている。状態自体は分散ノード情報を競合なしに網羅できるHashMapとなっている。データの強一貫性を確保するために、Masterの状態読み書きはMasterノード間のクォラムを取得した上で行われる。
How we do handle failures?
Akkaの強力なActor管理機能によって、我々はレジリエントなシステムを容易に構築できている。GearpumpではアプリケーションごとにAppMasterインスタンスを保持し、完全に互いに隔離されている。各アプリケーションには管理ツリーが存在し、AppMaster->Executor->Taskという順になっている。この管理階層構成によってゾンビプロセスの恐怖から解放される。例えば、AppMasterを停止する場合、Akkaの管理機能によって管理階層全体が終了したのを確認した上で停止される。
以下に複数の起こり得る障害シナリオについて記述する。
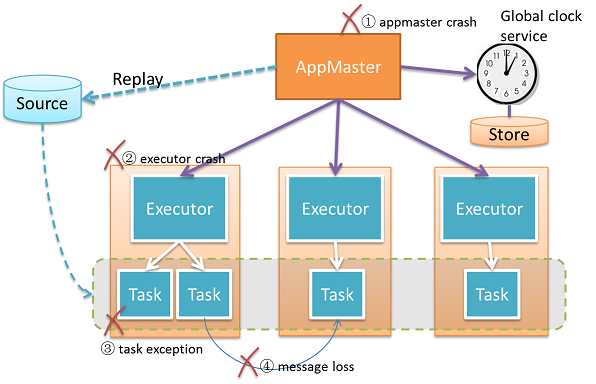
What happen when Master Crash?
Masterがクラッシュした場合、Standby Masterに通知され、Masterの状態を復旧した上で制御を引き継ぐ。WorkerとAppMasterにも通知され、新規Active Master探索プロセスを開始し、解決完了するまでそれを継続する。AppMasterとWorkerが新規Masterを検出できず、タイムアウトした場合、自分自身を停止させる。
What happen When worker crash?
Workerがクラッシュした場合、Masterに対して通知され、該当Workerに対する新規処理割り当てを停止する。クラッシュしたWorker上のExecutorは停止され、AppMasterはExecutorクラッシュ発生時のように対応する。What happen when executor crash?
What happen when AppMaster Crash?
AppMasterがクラッシュした場合、Masterが新規AppMasterを生成するためのリソースを他の場所から確保し、起動する、起動後、AppMasterはアプリケーションの復旧処理を行う。Streaming処理において、最新の最小クロックや他の状態をディスクからロードし、MasterにExecutor開始のためのリソース要求を送信し、得たリソースを用いてTask群をロードした最小クロックを用いて復旧させる。
What happen when executor crash?
Executorがクラッシュした場合、上位のAppMasterに通知され、新規Executorを起動するためのリソースをMasterから受け取り、クラッシュしたExecutorが実行していたTaskを割り振る。
What happen when task crash?
Taskが例外を投げた場合、上位のExecutorに通知され、Taskが再起動される。
"at least once"モードが有効化されていた場合、本障害はメッセージ欠損に伴う再実行を起動する。はじめにAppMasterは最新の最小クロックをglobal clock service(global clock serviceクラッシュ時ClockStorageから)から取得し、AppMasterは全TaskActorを新たなTask状態とともに再起動する。その結果、DataSourceとTask群は指定された最小クロックを用いてメッセージの再処理を行う。
AppMasterが実行する再起動はTaskの障害でも発生しえる・・ように読めますが、それだと結構影響大きそうな。ただ、高速で処理しているので障害発生時は影響大きいものの、早期に復旧するというアプローチの方が正しい気もします。
How exactly once work?
ある種のアプリケーションにおいては"exactly once"のメッセージ処理モデルは非常に重要となる。例えば、リアルタイム支払いシステムにおいて重複して支払いを行ってはならない。"exactly once"メッセージ処理モデルのゴールは「エラーを蓄積せず、今日のエラーが明日まで蓄積されることもない。」を保証することにある。
アプリケーション開発者に対してわかるように説明すると、我々は分散トランザクションを同期させるためにGlobal Clockを用いている。我々はDataSourceから取得した全メッセージがユニークなTimestampを持つことを保証する。このTimestampはメッセージ本体の一部として保持するか、Streamingシステムに投入されたタイミングでシステムクロックに後付される。このGlobal Synchronized Clockを用いることで、同一のTimestampを用いて全Taskを協調させることが可能となっている。
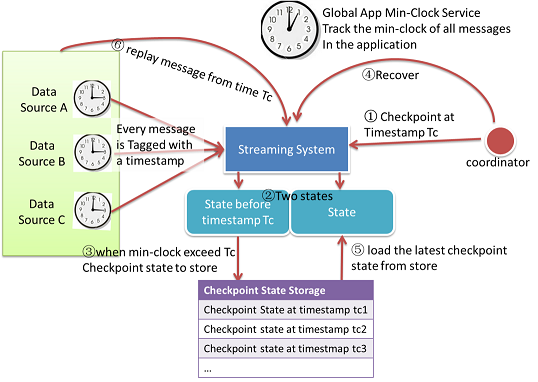
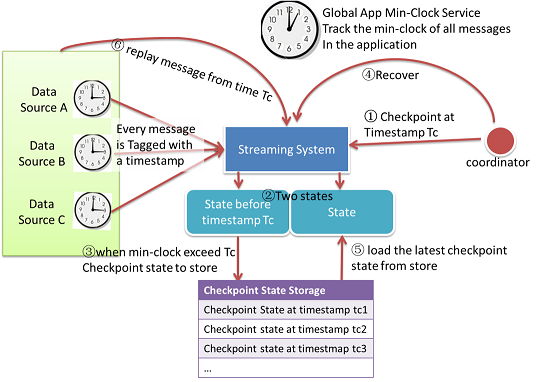
状態のチェックポイント取得フロー:
- CoordinatorがStreamingシステムに対してTimestasmp Tcでチェックポイントを取得するよう通知
- アプリケーション中の各Taskでは「CheckPoint State」と「Current State」の2個の値を保持する。「CheckPoint State」は前回のTimestamp Tcのみを保持し、「Current State」は全情報を保持する。
- 「Global minimum clock」がTcよりも大きい場合、Tcよりも古い値を持つ全メッセージが処理されたことを示す。「CheckPoint State」は変更されるため、変更後「CheckPoint State」をストレージに保存する。
- メッセージ欠損が発生した場合、復旧プロセスを開始する。
- 復旧のために、ストレージから最新の「CheckPoint State」を読み出し、アプリケーションの状態に設定する。
- DataSourceは「CheckPoint Timestamp」からメッセージを再取得して実行する。
チェックポイントを取得する間隔はGlobal Clock Serviceによって動的に決められる。各DataSourceは取得したメッセージの最大Timestampを記録する。最小クロック更新メッセージ受信時、DataSourceは最大Timestampとの差分をGlobal Clock Serviceに返信する。最大Timestamp差分はアプリケーション状態の間隔の上限を示す。チェックポイント取得間隔は最大Timestamp差分よりも大きくなる。
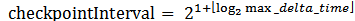
チェックポイント取得間隔がGlobal Clock Serviceによって各Taskに通知された後、各Taskは全体の同期を待たずに次のチェックポイントのTimestampを計算する。
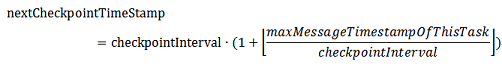
各Taskは「CheckPoint State」と「Current State」を保持するが、下記のコードのように状態値は更新される。
TaskState(stateStore, initialTimeStamp):
currentState = stateStore.load(initialTimeStamp)
checkpointState = currentState.clone
checkpointTimestamp = nextCheckpointTimeStamp(initialTimeStamp)
onMessage(msg):
if (msg.timestamp < checkpointTimestamp):
checkpointState.updateMessage(msg)
currentState.updateMessage(msg)
maxClock = max(maxClock, msg.timeStamp)
onMinClock(minClock):
if (minClock > checkpointTimestamp):
stateStore.persist(checkpointState)
checkpointTimeStamp = nextCheckpointTimeStamp(maxClock)
checkpointState = currentState.clone
onNewCheckpointInterval(newStep):
step = newStep
nextCheckpointTimeStamp(timestamp):
checkpointTimestamp = (1 + timestamp/step) * step
List 1: Task Transactional State Implementation
見た感じ、メッセージのTimestampによってメッセージが一意に絞れることと、モノイドの実装よりTimestamp別に状態が保持されることから、GearpumpのState自体が重複値の除去機構を備えていることになり、それによってExactly onceを満たしているようです。
ただ、Gearpump自体はあくまで実行エンジンであり、結果の出力を他のシステムに行うことが必要になります。それが必要になった途端Exactly onceとはいかなくなると思われます。
Intervalの合間にExecutorがクラッシュしたらそれまでにExecutor中のTaskが外部に送信してきたメッセージはトレースできなくなるわけですし。ただ、Timestampで一意に特定できるという性質から、重複メッセージを除去するのはやりやすい構成とはなりそうです。
What is dynamic graph, and how it works?
DAGは動的に更新可能となっている。動的にグラフ要素を追加、削除、更新を行うことが出来る。
At least once message delivery and Kafka
The Kafka source example project and tutorials can be found at:
この文書では、どのようにat least onceのモデルを達成するかについて記述する。
WordCountExampleを図に示すと下記のようになる。source tree
How the kafka WordCount DAG looks like:
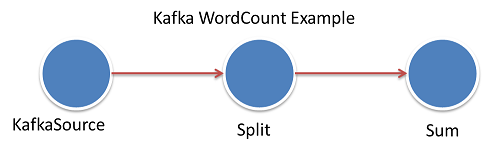
- KafkaStreamProducer(or KafkaSource)がKafka queueからメッセージを取得
- Splitが文章を単語に分割
- Sumが各単語の出現数を集計
How to read data from Kafka
KafkaSourceを使用している。使用方法は下記のアドレスを参照。
Connect with Kafka source
注意すべき点として、StartTimestampをKafkaSourceに設定し、この値をKafka queueからメッセージを取得する際にこのTimestamp値以上の値を保持する最も小さいTimestampのメッセージから取得を開始する。
What happen where there is Task crash or message loss?
メッセージ欠損が発生した場合、AppMasterはGlobal Clock Serviceを停止し、Global minimum timestampが固定される。その後、KafkaSource Taskを再開し、再開時にKafkaSourceがGlobal minimum timestampをAppMasterから取得し、メッセージの取得開始に利用する。
What method KafkaSource used to read messages from a start timestamp? As we know Kafka queue doesn't expose the timestamp information.
Kafka queueは各Partitionに対してOffsetの情報しか公開しない。KafkaSourceはKafka OffsetとApplication Timestampをマッピングして保持しているため、TimestampからKafka Offsetを指定してメッセージを取得することが出来、Kafkaからメッセージを再取得することが可能になる。
Application timestampとOffsetのマッピングは分散ファイルシステムか、Kafka topicとして保持される。
最後に
ここまでGearpumpの概要ドキュメントを読んできましたが、最も気になっていたExactly onceについてはTimestampの割り振りからくる性質によってGearpump内部で保持する状態としては見たせそう、という確認結果となりました。
ただ、外部に結果を出力するケースは重複処理が発生しえるので、結果格納先で何かしらの重複除去処理は必要そう、というのが現状の考えではあります。ただ、Timestampでメッセージを一意に識別できるため、格納先で重複除去する機構も作りやすい仕組みにはなっていますね。
ここまででGearpumpの概要が見えてきたため、次回以降は実際に動かす流れにし、どのようなものかを見ていきます。