はじめに
本記事はJDLA E資格の認定プログラム「ラビット・チャレンジ」における深層学習day3のレポート記事です。
本記事では以下の7つの項目について、要点をまとめています。
- 再起型ニューラルネットワークの概念
- LSTM
- GRU
- 双方向RNN
- Seq2Seq
- Word2vec
- Attention Mechanism
1. 再起型ニューラルネットワークの概念
概要
Recurrent Neural Network(RNN)
再帰型ニューラルネットワーク(Recurrent Neural Network:RNN)は、時系列データの扱いを得意とするニューラルネットワークです。
時系列データとは時間的順序を追って一定間隔ごとに観察され、なおかつ相互に統計的依存関係が認められるデータ系列のことであり、音声データやテキスト(自然言語)データなどがあります。
RNNの構造は下図のようになります。
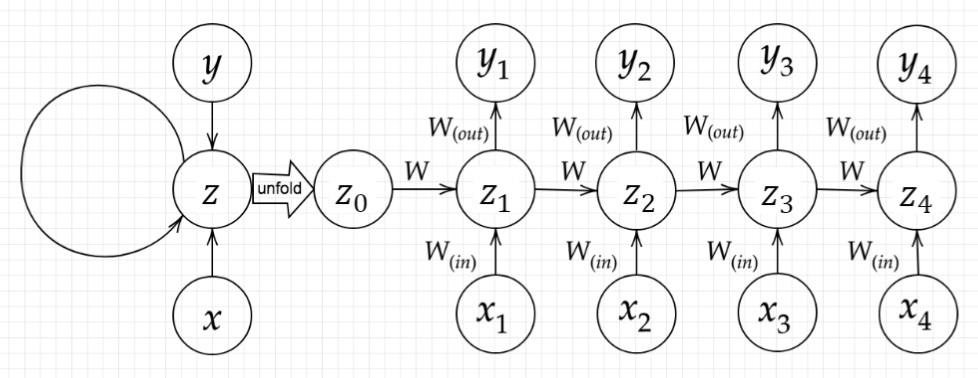
順伝播を式で表すと次のようになります。
\begin{align}
\boldsymbol{u}^t=&\boldsymbol{W}_{(in)}x^t+\boldsymbol{W}z^{t-1}+b\\
\boldsymbol{z}^t=&f(\boldsymbol{u}^t)=f\left(\boldsymbol{W}_{(in)}x^t+\boldsymbol{W}z^{t-1}+b\right)\\
\boldsymbol{v}^t=&\boldsymbol{W}_{(out)}\boldsymbol{z}^t+c\\
\boldsymbol{y}^t=&g(\boldsymbol{v}^t)=g\left(\boldsymbol{W}_{(out)}\boldsymbol{z}^t+c\right)
\end{align}
ここで、$b$、$c$はバイアス、$f(x)$、$g(x)$は活性化関数を表す。
RNNは時系列データを扱うため、初期の状態と過去の時間$t−1$の状態を保持し、次の時間$t$の状態を求める再帰的構造が必要になります。それを実現しているのが$\boldsymbol{z}$にあるループ構造です。
Backpropagation Through Time(BPTT)
RNNにおけるパラメータ調整方法の一種で誤差逆伝播を用います。
【重み】
\frac{\partial E}{\partial W_{(in)}}=\frac{\partial E}{\partial u^{t}}
\left[
\frac{\partial u^{t}}{\partial W_{(in)}}
\right]^{T}=
\delta^{t}[x^{t}]^{T}
\frac{\partial E}{\partial W_{(out)}}=\frac{\partial E}{\partial v^{t}}
\left[
\frac{\partial v^{t}}{\partial W_{(out)}}
\right]^{T}=
\delta^{out, t}[z^{t}]^{T}
\frac{\partial E}{\partial W}=\frac{\partial E}{\partial u^{t}}
\left[
\frac{\partial u^{t}}{\partial W}
\right]^{T}=
\delta^{t}[z^{t-1}]^{T}
【バイアス】
\frac{\partial E}{\partial b}=\frac{\partial E}{\partial u^{t}}
\frac{\partial u^{t}}{\partial b}=\delta^{t}
\frac{\partial E}{\partial c}=\frac{\partial E}{\partial v^{t}}
\frac{\partial v^{t}}{\partial c}=\delta^{out, t}
パラメータの更新
【重み】
W_{(in)}^{t+1}=W_{(in)}^{t}-\epsilon\frac{\partial E}{\partial W_{(in)}}=W_{(in)}^{t}-\epsilon\sum_{z=0}^{T_{t}}{\delta^{t-z}[x^{t-z}]^{T}}
W_{(out)}^{t+1}=W_{(out)}^{t}-\epsilon\frac{\partial E}{\partial W_{(out)}}=W_{(out)}^{t}-\epsilon \delta^{out,t}[x^{t}]^{T}
W^{t+1}=W^{t}-\epsilon\frac{\partial E}{\partial W}=W^{t}-\epsilon\sum_{z=0}^{T_{t}}{\delta^{t-z}[x^{t-z-1}]^{T}}
【バイアス】
b^{t+1}=b^{t}-\epsilon\frac{\partial E}{\partial b}=b^{t}-\epsilon\sum_{z=0}^{T_{t}}{\delta^{t-z}}
c^{t+1}=c^{t}-\epsilon\frac{\partial E}{\partial c}=c^{t}-\epsilon \delta^{out,t}
コード実装
バイナリー加算をRNNで学習するプログラムを実装しました。
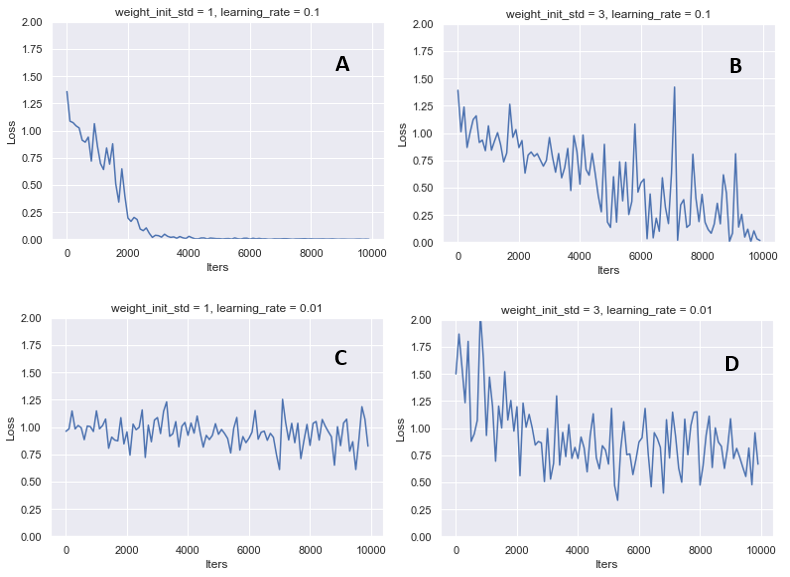
A (weight_init_std=1, learning_rate=0.01)の結果から、イテレーション回数が増えていくにつれて学習が進み、バイナリー加算の精度が高くなっていること分かる。weght_init_std=3としたBでは、学習は進むもののAほど安定していないことが分かります。このことから、初期値の設定が学習に深く関わるという事が見て取れます。
また、learning_rate = 0.01としたCでは学習が進んでいないことが分かります。学習率を小さくしたことで、学習の進みが悪くなってしまったと判断できます。
重みの初期値をXavierやHeに変更してみます。
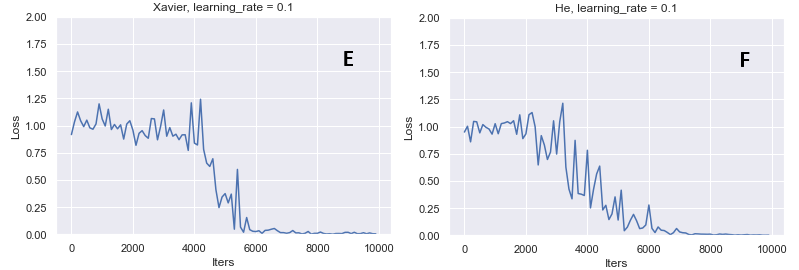
今回に関しては、XavierとHeの初期値による学習は比較的近い傾向にあります。
また、ランダム関数を用いているAの方が、学習の進みが良いことが分かります。
続いて、中間層の活性化関数をsigmoidからReLUに変更してみます。
他の学習条件はA(weight_init_std=1, learning_rate=0.01)を用います。
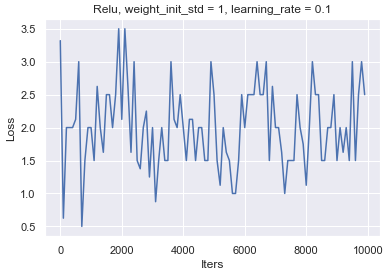
学習が収束せず、Lossも振動してしまっています。
適材適所な活性化関数を選択する必要があることが分かりました。
確認テスト
確認テスト1
サイズ5×5の入力画像を、サイズ3×3のフィルタで畳み込んだ時の出力画像のサイズを答えよ。
なおストライドは2、パディングは1とする。
解答:3×3
縦:
$$
\frac{5 + 2 ×1 -3}{2} + 1 = 3
$$
高さ:
$$
\frac{5 + 2×1 -3}{2} + 1 = 3
$$
確認テスト2
RNNネットワークには大きく分けて3つの重みがある。1つは入力から現在の中間層を定義する際にかけられる重み、1つは中間層から出力を定義する際にかけられる重みである。残りひとつの重みについて説明せよ。
解答:前の中間層($t-1$)から現在の中間層($t$)を定義する際にかけられる重み
確認テスト3
連鎖律の原理を使い、dz/dxを求めよ
\begin{align}
z=t^2\\
t=x+y
\end{align}
解答:
$$\frac{dx}{dx}=\frac{dx}{dt}\frac{dt}{dx}=2t\times1=2(x+y)$$
確認テスト4
下図の$y_{1}$を数式で表わせ。
中間層の出力にシグモイド関数$g(x)$を作用させよ。
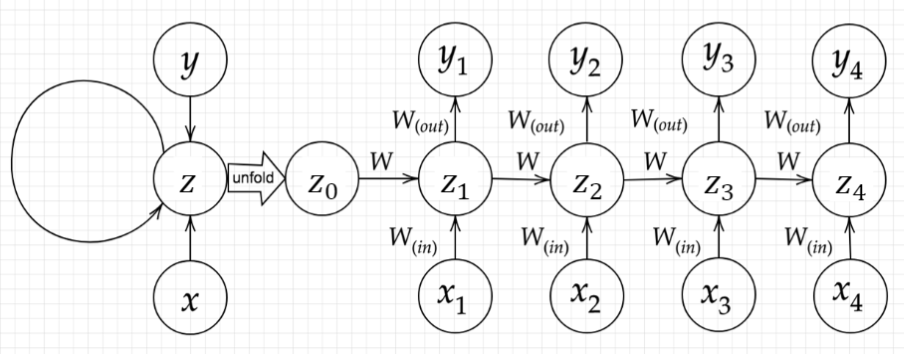
解答:
z_{1}= f(z_{0}W+x_{1}W{in}+b)
y_{1}= g(z_{1}W{out}+c)
2. LSTM(Long Short Term Memory)
概要
RNNでは時系列を過去に遡るほど勾配が消失していくため、長い時系列の学習が困難という問題があります。
活性化関数や重みの初期化方法を工夫することでRNNではこの問題に対処していますが、ニューラルネットワークの構造自体を変えて、勾配消失問題を解決したものがLSTMになります。
LSTMはRNNの中間層のユニットを、LSTM blockと呼ばれるメモリと3つのゲートを持つブロックに置き換えることで実現しています。
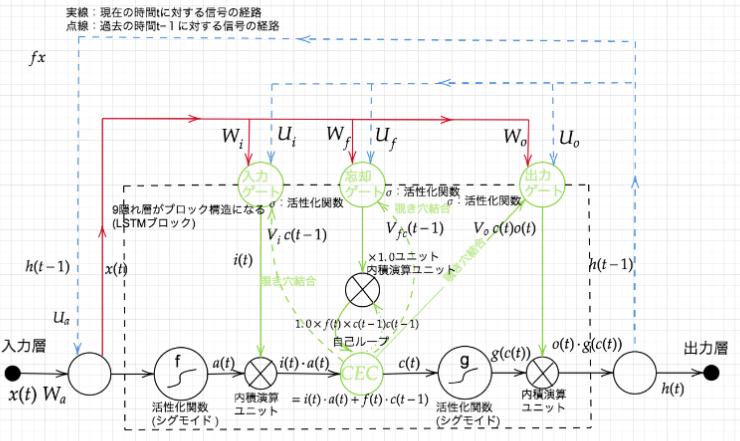
-
CEC
記憶セルのことです。時刻$t$におけるLSTMの記憶が格納されており、この部分に過去から時刻$t$までにおいて必要な情報が格納されています。 -
入力ゲート
入力ゲートは、$a(t)$の各要素が新たに追加する情報としてどれだけ価値があるかを判断します。この入力ゲートによって、追加する情報の取捨選択を行います。別の見方をすると、入力ゲートによって重みづけされた情報が新たに追加されることになります。 -
出力ゲート
出力ゲートは、$g(c(t))$の各要素が次時刻の隠れ状態$h(t)$としてどれだけ重要かという事を調整します。 -
忘却ゲート
記憶セルであるCECに対して、不要な記憶を忘れさせるための役割をするゲートです。
ゲートという言葉を多用してきましたが、イメージとしては水をどのくらいの量流すかをコントロールするものです。水門のような蛇口のようなものでしょうか。ゲートの開き具合は$0.0~1.0$までの実数で表されます。そしてその数値によって、次へ水を流す量をコントロールします。実際にはこの数値も重みパラメータとして、学習データによって更新されていきます。
sigmoid関数が活性化関数として使われていますが、sigmoid関数の出力は$0.0~1.0$の実数を取るので、まさにゲートの開き具合を求めているということが分かります。
確認テスト
以下の文章にLSTMに入力し空欄に当てはまる単語を予測したいとする。文中の「とても」という言葉は空欄の予測において無くなっても影響を及ぼさないと考えられる。このような場合、どのゲートが作用すると考えられるか。
「映画面白かったね。ところで、とてもお腹が空いたから何か____。」
解答:忘却ゲート
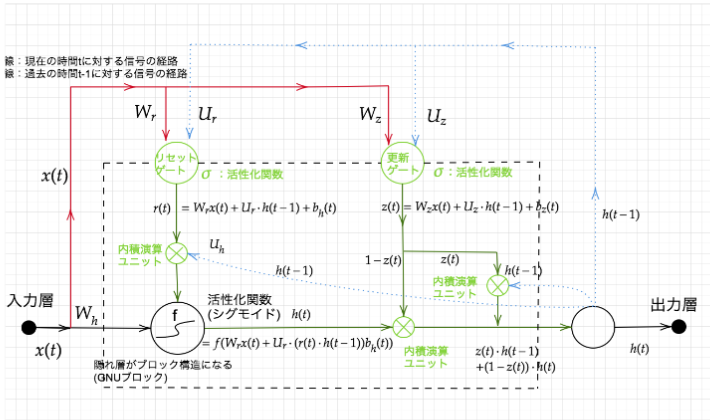
3. GRU
概要
LSTMではパラメータ数が多いため、計算負荷が大きいという課題があります。
GRUではパラメータを大幅に削減して、LSTMと同等またはそれ以上の精度を実現しています。
確認テスト
確認テスト1
LSTMとCECが抱える問題について、それぞれ簡潔に述べよ。
解答:
LSTMは多くのパラメータを持つため、複雑で計算負荷が大きくなってしまうこと。
CEC自体には学習機能がなく、周りに学習能力のあるゲート(入力ゲート、出力ゲート、忘却ゲート)が必要であること。
確認テスト2
LSTMとGRUの違いを簡潔に説明せよ。
解答:
LSTMはCEC、入力ゲート、出力ゲート、忘却ゲートを持ちパラメータが多いため計算負荷が大きい。
一方で、GRUはリセットゲート、更新ゲートを持ちパラメータが少ないため計算コストがLSTMよりも小さい。
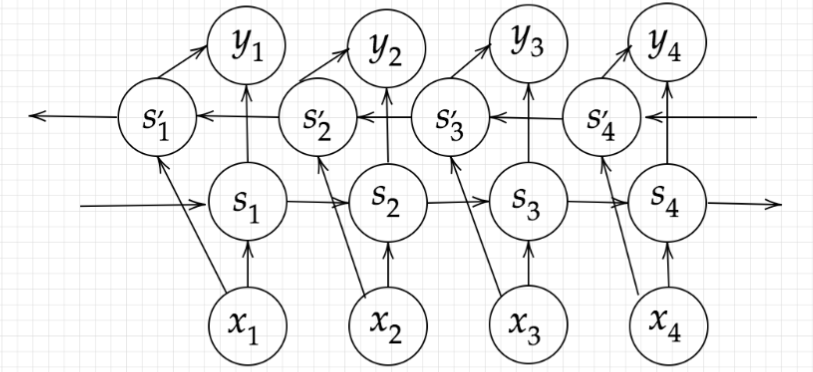
4. 双方向RNN
RNNは過去の情報を保持することで時系列データの学習を実現していました。双方向RNNの場合は、過去の情報に加えて未来の情報も加味させるモデルです。
例えば、文章中のある単語の次にくる単語は何かを予測させようとしたとき、単語より前の情報だけでなく、後の情報も加味して学習すると精度は向上しそうですよね。双方向RNNは、文章の推敲や機械翻訳等で実用されています。
5. seq2seq
Encoder-Decoderモデルの1つで、ある時系列データ(例えば英語の文章)の入力から、別の時系列データ(例えば日本語の文章)を出力するネットワークです。以下のように英文を日本語に変換(翻訳)するようなタスクで利用することができます。
I have a pen. ----→ 私はペンを持っています。
Seq2Seqは、翻訳以外にも、文章の要約や機械対話にも活用できます。
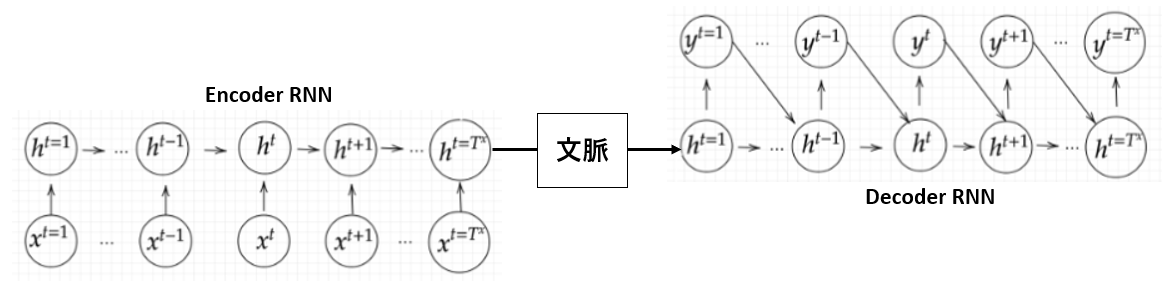
上図はSeq2Seqのネットワーク概略図です。
Seq2Seqでは、通常RNN層(今回はLSTM)を利用します。また、入力を圧縮するencoderと出力を展開するdecoderからなるニューラルネットワークモデルを定義します。
各項目について説明していきます。
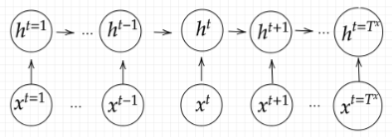
Encoder RNN
まず、Encoder RNNへ入力するデータについて説明します。
入力データである文章を単語等のトークン毎に分割しIDを付与します(Talking)。そしてそのIDから、トークンを表す分散表現ベクトルを作成します(Embeding)。このベクトルデータがRNNの入力となります。
Encoder RNNでは、この入力データから文の意味を集約します。最終的な出力では、元々の文章全体の意味が一つのベクトル表現として出てきます。
処理手順としては以下のようになります。
- vec1をRNNに入力し、hidden stateを出力。このhidden stateと次の入力vec2をRNNに入力してhidden stateを出力。という流れを繰り返す。
- 最後のvecを入れたときのhidden stateをfinal stateとしてとっておく。
このfinal stateがthought vectorと呼ばれ、入力した文の意味を表すベクトルとなる。
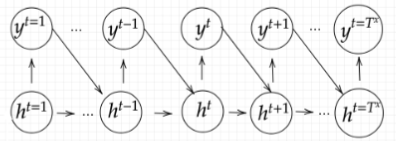
Decoder RNN
Decoder RNNではEncoder RNNで解釈した意味を入力して、何か別の形として出力させます。
処理手順としては以下のようになります。
- RNNのfinal state(thought vector)から、各tokenの生成確率を出力していく。final stateをDecoder RNNのinitial stateとして設定し、Embeddingを入力する。(Decoder RNN)
- 生成確率にもとづいてtokenをランダムに選ぶ。(サンプリング)
- 2で選ばれたtokenをEmbeddingしてDecoder RNNへの次の入力とする。(Embedding)
- 1~3を繰り返し、2で得られたtokenを文字列に直す。(Detokenize)
以上、seq2seqの説明となります。
続いて、Seq2Seqの発展形や、関連技術について簡単にまとめていきます。
HRED
Seq2seqでは一文の一問一答しかできず、会話の文脈をくみ取る様な応答はできませんでした。
HREDではSeq2seqの構造に、Context RNNという、Encoderのまとめた各文章の系列を、これまでの会話コンテキスト全体を表すベクトルに変換する構造を加えることによって、文脈の意味をくみ取った応答ができるようになりました。
しかし、HREDは確率的な多様性が字面にしかないため、会話の「流れ」のような多様性はありません。
同じコンテキスト(発話リスト)を与えられても、答えの内容が毎回会話の流れとして同じものしか出せないという課題があります。また、HREDは短く情報量に乏しい答えを多くする傾向にあります。
例えば、「うん」「そうだね」のような、短く情報量に乏しい答えを多く出力します。
これらの課題に対して、VAEの潜在変数の概念を追加することにより多様性を改善させたネットワークをVHREDといいます。
オートエンコーダ(Auto Encoder)
教師なし学習の一つです。学習時の入力データは訓練データのみで教師データは利用しません。
入力データから潜在変数zに変換するニューラルネットワークがEncoderであり、
潜在変数zを入力として元画像を復元するニューラルネットワークがDecoderです。
zの次元が入力データより小さい場合、次元削減をしているとみなせます。
例えば、MNISTデータセットを用いた場合、$28×28$の数字画像を入力して潜在変数に変換し、同じ画像を出力するようなニューラルネットワークになります。
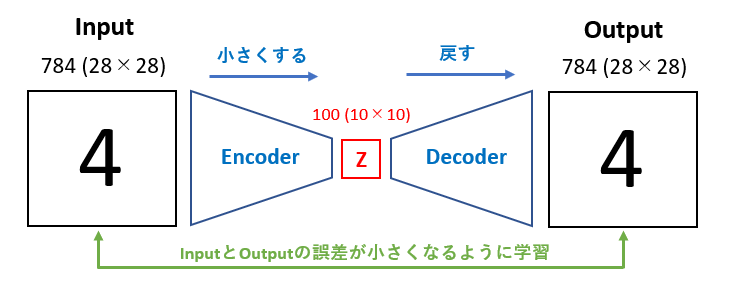
VAE
通常のオートエンコーダーの場合、何かしらのデータを潜在変数zにを押し込めているものの、その構造がどのような状態かはわかりません。VAEはこの潜在変数zに確率分布z∼N(0,1)を仮定して正則化したものです。
つまりVAEは、データを潜在変数zの確率分布という構造に押し込めることを可能にします。
確認テスト
確認テスト1
下記の選択肢から、seq2seqについて説明しているものを選べ。
(1)時刻に関して順方向と逆方向のRNNを構成し、それら2つの中間層表現を特徴量として利用するものである。
(2)RNNを用いたEncoder-Decoderモデルの一種であり、機械翻訳などのモデルに使われる。
(3)構文木などの木構造に対して、隣接単語から表現ベクトル(フレーズ)を作るという演算を再帰的に行い(重みは共通)、文全体の表現ベクトルを得るニューラルネットワークである。
(4)RNNの一種であり、単純なRNNにおいて問題となる勾配消失問題をCECとゲートの概念を導入することで解決したものである。
解答:(2)
確認テスト2
seq2seqとHRED、HREDとVHREDの違いを簡潔に述べよ。
解答:
seq2seqは、一文の一問一答に対して処理できるモデルです。
HREDは一問一答ではなく、今までの会話の文脈から答えを導き出せるようにしたモデルです。
HREDは会話の流れのような多様性はなく、情報量の乏しいな短い応答しかできないという課題がありました。
VHREDはこの課題を、VAEの潜在変数の概念を追加することにより多様性を改善させたモデルです。
6. Word2Vec
Word2Vecは推論ベースの手法であり、シンプルな2層のニューラルネットワークで構成されます。
学習データからボキャブラリーを作成し、各単語をone-hotベクトルにして入力し単語分散表現を得ることができます。
Word2Vecには、skip-gramモデルとCBOWモデルがあり、CBOWモデルは複数の単語(コンテキスト)から一つの単語(ターゲット)を推測します。skip-gramモデルは逆に、一つの単語から複数の単語を推測します。word2Vecは重みの再学習ができるため、単語の分散表現の更新や追加が効率的に行えます。
7. Attention Mechanism
概要
Seq2Seqは文章の単語数に関わらず、常に固定次元ベクトルで入力しなければならないため、長い文章への対応が難しいという課題があります。
そこで、文章が長くなるほどそのシーケンスの内部表現の次元も大きくなっていく仕組みが必要になります。
Attention Mechanismとは、「入力と出力のどの単語が関連しているのか」の関連度を学習する仕組みのことです。
ソフトマックス関数等で確率分布を得て、重み付き平均を得る手法をSoft Attentionといいます。
Soft Attentionのように重み付け平均せず、重みが最大となるValueを取り出したり、重み行列を確率分布とみなして抽出する手法をHard Attentionといいます。
確認テスト
RNNとWord2vec、Seq2SeqとSeq2Seq+Attentionの違いを簡潔に述べよ。
解答:
RNNは時系列データを処理するのに適したネットワークです。
Word2Vecは単語の分散表現ベクトルを得る手法のことです。
Seq2Seqは一つの時系列データから別の時系列データを得るネットワークです。
Attentionは時系列データの中身のそれぞれの関係性に重みをつける手法のことです。
参考にした書籍
本記事を作成するにあたって以下の書籍を参考にしました。
特に、LSTMの入力ゲートや出力ゲート、忘却ゲート、CECの理解に役立ちました。