はじめに
Azure Machine Learningで自動的にモデルが作れるらしい。
そこで化合物の予測モデルの精度で勝負を挑んでみた。
対象データ
この分野では実験から得られる教師データは少な目で、化学構造から得られる説明変数(記述子)は数千から場合によっては数万となるのが1つの特徴である。
精度が出やすいデータの場合、予測方法が優れているかどうか分かりにくいため、データ数が少なく、精度がやや低目のデータとして「化学のためのPythonによるデータ解析・機械学習入門」の6章の、データ数 114 件、 R^2 が 0.7 程度の以下データを選定した。
比較方法
比較方法は以下の通りとした。
- 構築するモデルは、データに含まれるpIC50を目的変数とする回帰モデルとし、評価指標は R^2とする。
- 114件のデータを学習データとテストデータの比率が8対2になるように分け、学習データでモデルを作成し、テストデータでの精度で勝負する
- RDKitとMordredの記述子計算を行ったもののうち、計算できなかった記述子を除外した1498個の記述子計算結果を説明変数とする。
- すなわち 91 行 x 1498 列 の学習データを用いて、23件のテストデータのR^2の指標をAzureと勝負する。
自マシンの環境
自マシンの環境は以下の通りである。
- OS Windows 10
- RDKit 2020.09.3
- mordred 1.2.0
学習データの準備
今回のAzuruとの闘いに用いる学習データの準備作業について説明する。
インストールしたRDKit、Mordred等をインポートする
import numpy as np
import pandas as pd
from rdkit import rdBase, Chem
from rdkit.Chem import AllChem, Descriptors
from rdkit.ML.Descriptors import MoleculeDescriptors
from mordred import Calculator, descriptors
import mordred
続いてファイルを読み込む。
import codecs
with codecs.open('../datas/raw/molecules_with_pIC50.csv', 'r', 'utf-8', 'ignore') as f:
df = pd.read_csv(f)
SMILESを取り出しリストに格納する。
smiles_list = df["SMILES"].values
mols = []
for i, smiles in enumerate(smiles_list):
mol = Chem.MolFromSmiles(smiles)
if mol:
mols.append(mol)
else:
print("{0} th mol is not valid".format(i))
RDKitの記述子計算を行う
descriptor_names = [descriptor_name[0] for descriptor_name in Descriptors._descList]
descriptor_calculator = MoleculeDescriptors.MolecularDescriptorCalculator(descriptor_names)
rdkit_descriptors_results = [descriptor_calculator.CalcDescriptors(mol) for mol in mols]
df_rdkit = pd.DataFrame(rdkit_descriptors_results, columns = descriptor_names, index=names_list)
# nullが含まれる列を除外
df_rdkit = df_rdkit[df_rdkit.columns[~df_rdkit.isnull().any()]]
Mordred記述子の計算を行う
mordred_calculator = Calculator(descriptors, ignore_3D=True)
df_mordred = mordred_calculator.pandas(pd.Series(mols, index=names_list))
# 各列の数値型への変換
for column in df_mordred.columns:
if df_mordred[column].dtypes == object:
df_mordred[column] = df_mordred[column].values.astype(np.float32)
# nullが含まれる列を除外
df_mordred = df_mordred[df_mordred.columns[~df_mordred.isnull().any()]]
最後にRDKitとMordredの列を1つのデータフレームにまとめ、目的変数tを1列目に統合する。
目的変数を統合するのは、Azureで学習させる際に1つのファイルにまとまっていた方が都合がよさそうだったためである。
RDKitとMordredのプレフィックスをつけているのは、記述子名がバッティングすることを防止するためである。
for df_tmp, prefix in zip([df_rdkit, df_mordred], ["RDkit.", "Mordred."]):
columns_new = [(prefix + column_tmp) for column_tmp in df_tmp.columns]
df_tmp.columns = columns_new
df_all = pd.concat([df_rdkit, df_mordred], axis=1)
# 目的変数を統合
df_all.insert(0, "t", df["pIC50"].values)
最後に学習データとテストデータに分割し、それぞれファイルに保存する。
分割の再現性を考慮し、random_stateを設定している。
from sklearn.model_selection import train_test_split
df_train, df_test = train_test_split(df_all, test_size=0.2, shuffle=True, random_state=43)
df_train.to_csv("../results/train.csv")
df_test.to_csv("../results/test.csv")
train.csv が目的変数と説明変数の格納された学習データであり、以下では本ファイルをベースに人手、Azureでそれぞれモデルを構築していく。
人手によるモデル作成
まず、人手でのモデル作成を行う
データの準備
まず学習データ、テストデータそれぞれPandas データフレームに読み込み、説明変数と目的変数に分離する。
# 説明変数
df_train_X = df_train.iloc[:, 1:]
df_test_X = df_test.iloc[:, 1:]
# 目的変数
train_t = df_train.iloc[:, 0].values
test_t = df_test.iloc[:, 0].values
特徴選択
続いて不要な説明変数を除去していこう。
まず分散0の説明変数を除去する。
from sklearn.feature_selection import VarianceThreshold
tmp_values = df_train_X.values
select = VarianceThreshold()
tmp_values = select.fit_transform(tmp_values)
df_train_X_vt = df_train_X[df_train_X.columns[select.get_support()]]
次に9割が同じ値になる記述子も除去する。
st_threshold = 0.9
selected = []
for column in df_train_X_vt.columns:
value_counts = df_train_X_vt[column].value_counts(sort=True)
score = value_counts.values[0]/len(df_train_X_vt[column].values)
if score < st_threshold:
selected.append(column)
df_train_X_st = df_train_X_vt[selected]
続いてPandasを活用し相関の高い特徴を除去する(改良)にしたがって相関係数が0.95以上の説明変数の組がある場合、どちらかを除去する。
以降、学習データが df_train_X_ct、テストデータが df_test_X_ct というDataFrameに格納された前提で進める。
オートスケーリング
続いてオートスケーリングする。
from sklearn import preprocessing
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
train_X_scaled = ss.fit_transform(df_train_X_ct.values)
test_X_scaled = ss.transform(df_test_X_ct.values)
ハイパーパラメータチューニング
今回は、LightGBMのを用いることとし、Optunaでハイパーパラメータチューニングを行う。
データが少ないため n_estimator, max_depth, num_leaves あたりを控え目に設定したのが唯一の工夫点である**(笑)**。
また、モデルの再現性を考慮し、LGBMRegressorにはandom_stateを設定している。
import optuna
from sklearn.model_selection import cross_val_score
from lightgbm import LGBMRegressor
def objective(trial, x, t, cv):
# 1. ハイパーパラメータごとに探索範囲を指定
n_estimaters = trial.suggest_int('n_estimators', 1, 100)
max_depth = trial.suggest_int('max_depth', 1, 10)
num_leaves = trial.suggest_int('num_leaves', 2, 10)
min_child_weight = trial.suggest_loguniform("min_child_weight", 0.1, 10)
subsample = trial.suggest_uniform("subsample",0.55, 0.95)
colsample_bytree = trial.suggest_uniform("subsample",0.55, 0.95)
# 2. 学習に使用するアルゴリズムを指定
estimator = LGBMRegressor(
n_estimators=n_estimaters,
max_depth=max_depth,
num_leaves=num_leaves,
min_child_weight=min_child_weight,
subsample=subsample,
colsample_bytree= colsample_bytree,
random_state=43
)
# 3. 学習の実行、検証結果の表示
print('Current_params : ', trial.params)
r2 = cross_val_score(estimator, x, t, cv=cv, scoring="r2").mean()
return r2
# study オブジェクトの作成(最大化)
study = optuna.create_study(direction='maximize')
# 10分割交差検証によるチューニング
cv = 10
study.optimize(lambda trial: objective(trial, train_X_scaled, train_t, cv), n_trials=50)
結果
Optunaで得られたハイパーパラメータでクロスバリデーション、テストデータでの予測実測プロットを描こう。
%matplotlib inline
import matplotlib.pyplot as plt
from sklearn.model_selection import cross_val_predict
from sklearn.metrics import r2_score
# 予測値を算出
train_y = best_model.predict(train_X_scaled)
train_y_in_cv = cross_val_predict(best_model, train_X_scaled, train_t, cv=10)
test_y = best_model.predict(test_X_scaled)
fig = plt.figure(figsize=(18.0, 5.0))
ax_cv = fig.add_subplot(132)
ax_cv.set_title("Q2")
ax_cv.set_xlabel('pred')
ax_cv.set_ylabel('exp')
ax_ext = fig.add_subplot(133)
ax_ext.set_title("External Validation")
ax_ext.set_xlabel('pred')
ax_ext.set_ylabel('exp')
ax_cv.scatter(train_y_in_cv, train_t)
ax_ext.scatter(test_y, test_t)
lims = [
np.min([ax_inner.get_xlim(), ax_inner.get_ylim()]), # min of both axes
np.max([ax_inner.get_xlim(), ax_inner.get_ylim()]), # max of both axes
]
ax_cv.plot(lims, lims, 'k-', alpha=0.75, zorder=0)
ax_ext.plot(lims, lims, 'k-', alpha=0.75, zorder=0)
ax_cv.text(0.0, 0.0, '$R^{2}$=' + str(round(r2_score(train_t, train_y_in_cv), 3)))
ax_ext.text(0.0, 0.0, '$R^{2}$=' + str(round(r2_score(test_t, test_y), 3)))
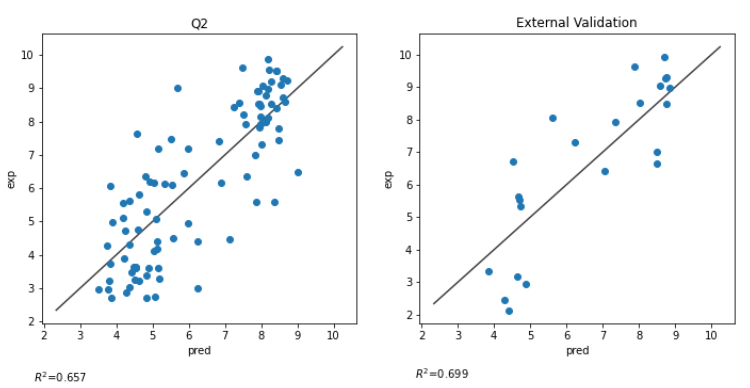
結果は、クロスバリデーション精度 0.657, テストデータでの精度 0.699 となった。
参考した本では SVRで0.74程度の精度となっており、それに比べると今一つであるが、データが少なくデータ分割の仕方によってもかなりブレがあるのでこれを最終版とする。
Azureによるモデル作成
続いてAzureでモデルを行う。
ワークスペースの作成
Azureポータルにログインし「機械学習」を選択しよう。

続いて「Machine Learningワークスペース」の作成をクリックしよう。
続いて必要な情報を入力し、「確認および作成」をクリックしよう。
続いて「作成」ボタンをクリックしよう。
するとデプロイが始まるのでしばらく待とう。
自動MLによるモデル構築
続いて「スタジオの起動」をクリックしよう。
続いて「自動ML」の「今すぐ開始」をクリックしよう。
続いて「新しい自動MLの実行」をクリックしよう。
続いて「データセットの作成」をクリックしよう。
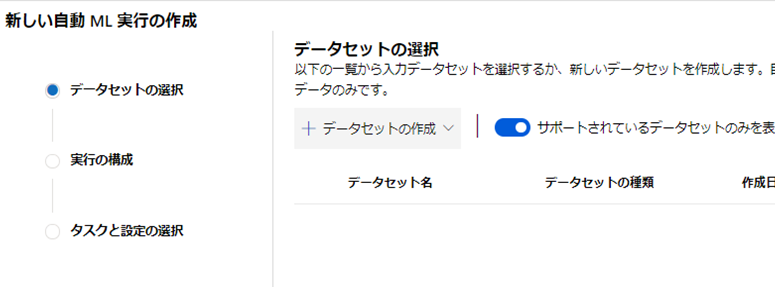
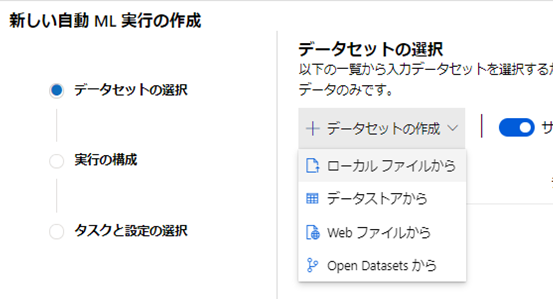
続いて「ローカルファイルから」を選択しよう。
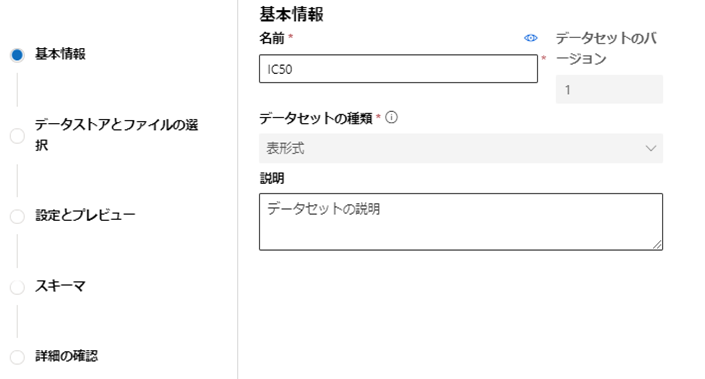
続いてデータセットの基本情報を入力し「次へ」をクリックしよう。
続いてファイルのアップロードをクリックしよう。
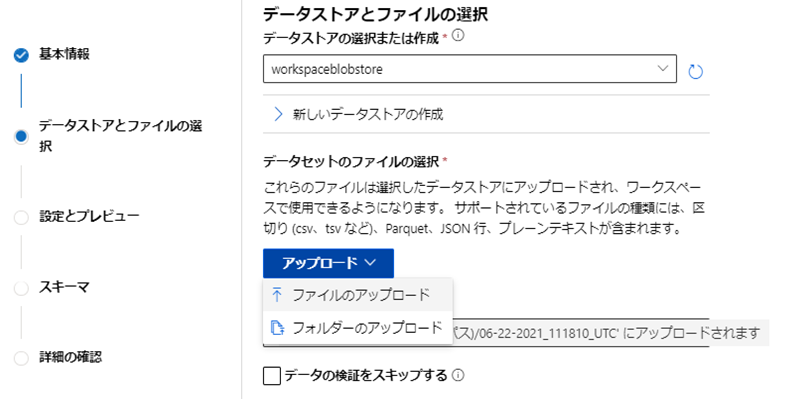
続いてファイルの区切り記号として「コンマ」を選択し「次へ」をクリックしよう。
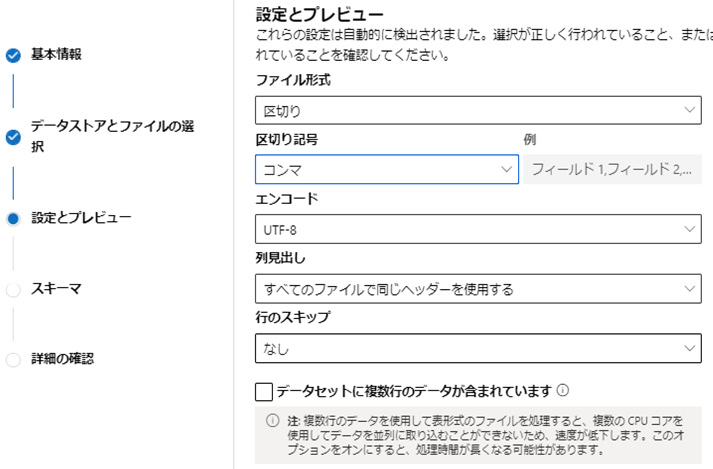
1列目と2列目に余分なカラムが追加されているので、「含める」をオフにし「次へ」をクリックしよう。
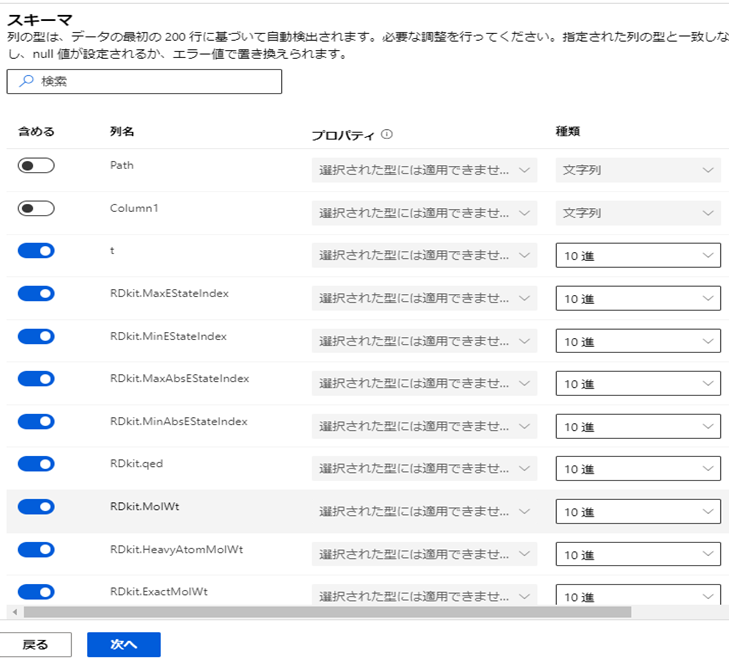
確認して「作成」をクリックしよう。
続いて「コンピューティングクラスタ」の仮想マシンを選択し「次へ」をクリックしよう。
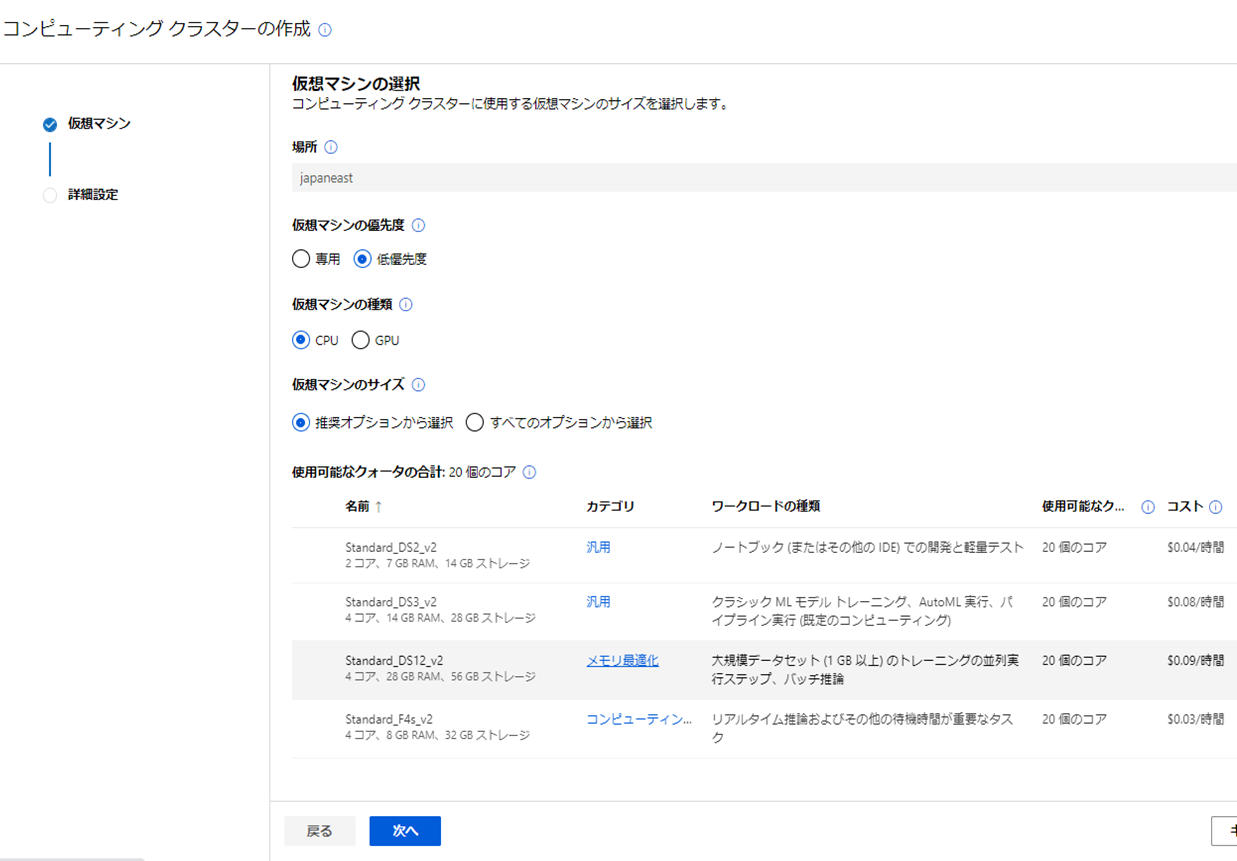
必要な情報を入れて「作成」をクリックしよう。
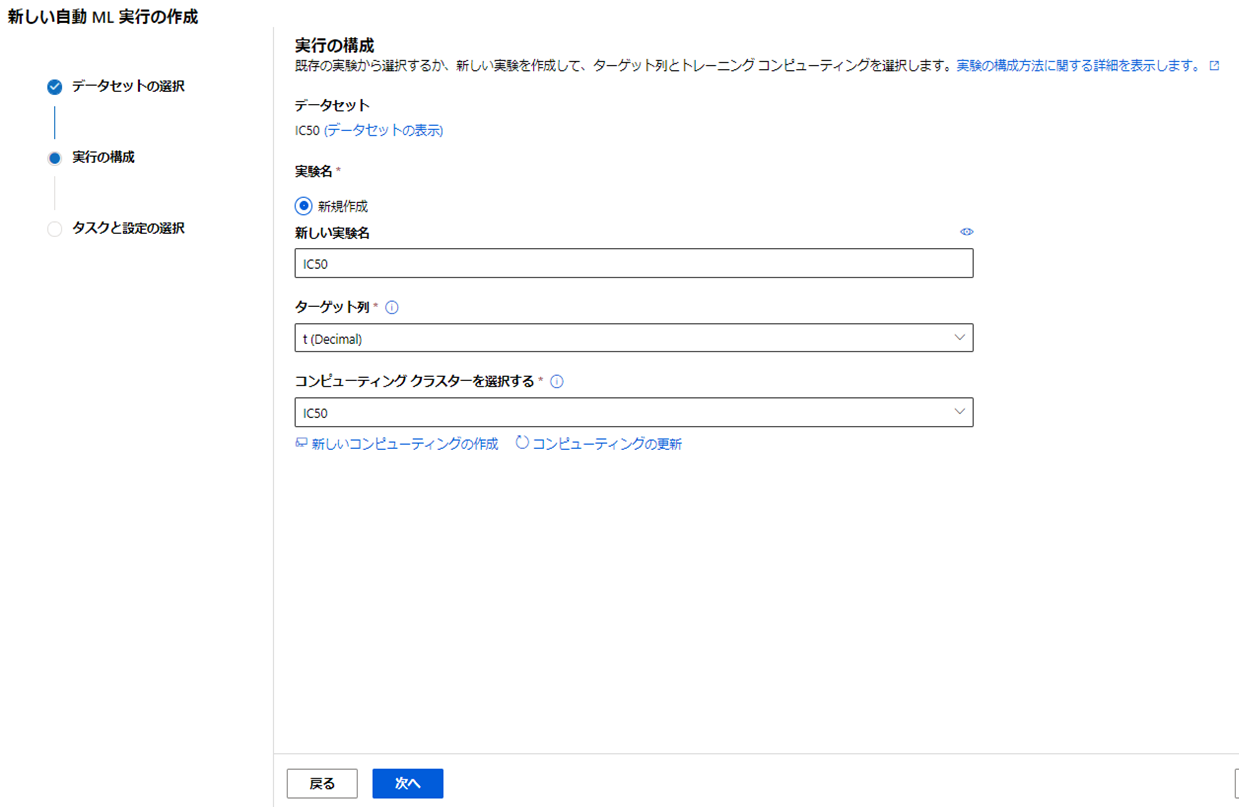
実験名、ターゲット列(今回は目的変数t)、コンピューティングクラスタを選択し「次へ」をクリックしよう。
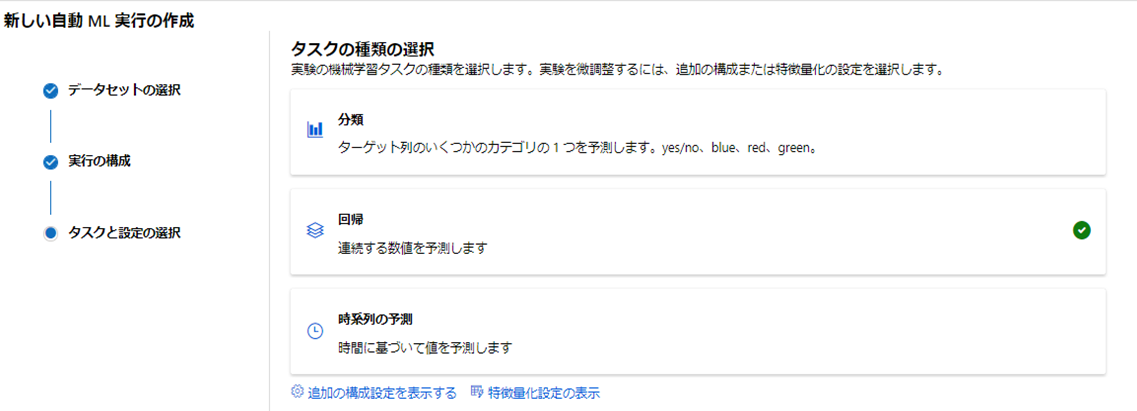
タスクの種類として「回帰」を選択し「終了」をクリックしよう。
するとモデルの実行が開始されるのでしばらく待とう。今回のデータは完了まで約3時間かかった。
モデルのデプロイ
モデルの作成が完了すると「完了」状態になり最終の精度などが見れる。「実行1」をクリックしよう。
今回一番精度が高かったモデルはR^2 0.577の精度であり、学習はまずまずうまくいっているようである。
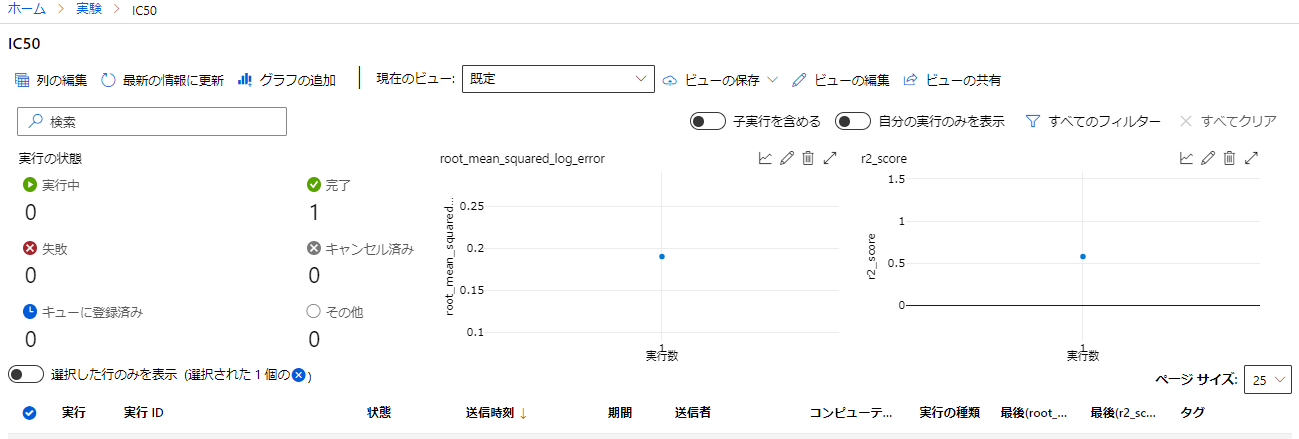
モデルタブを選択すると精度の高い順にモデルが表示されるためデプロイしたいモデルを選択しよう。
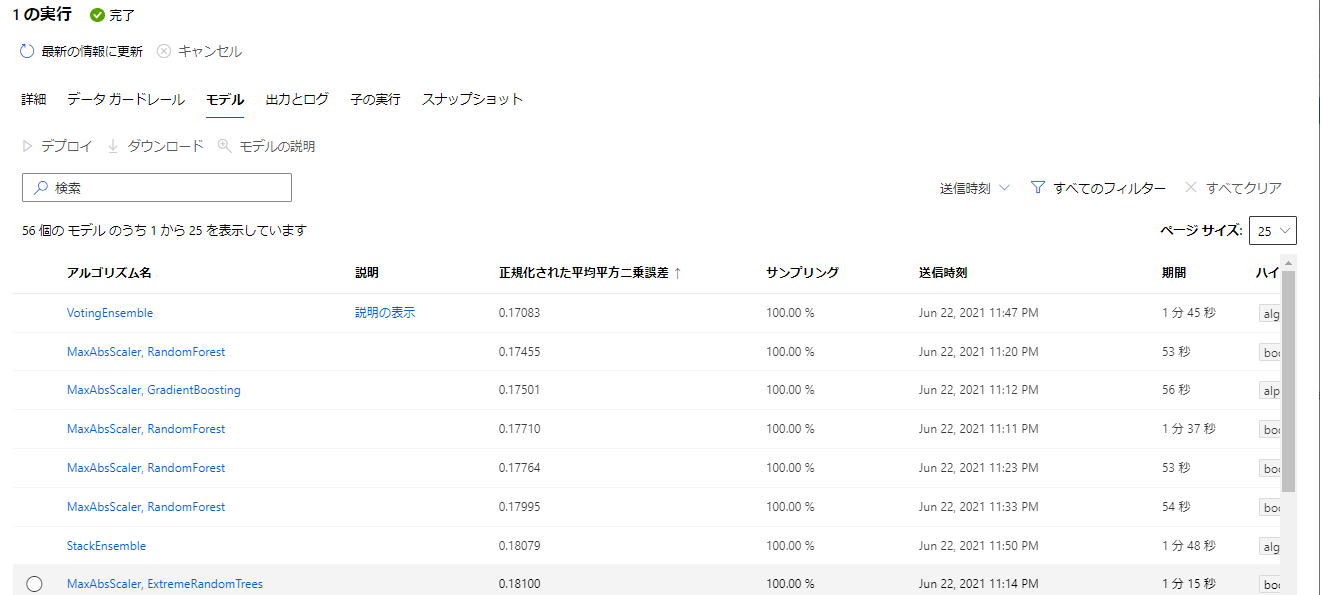
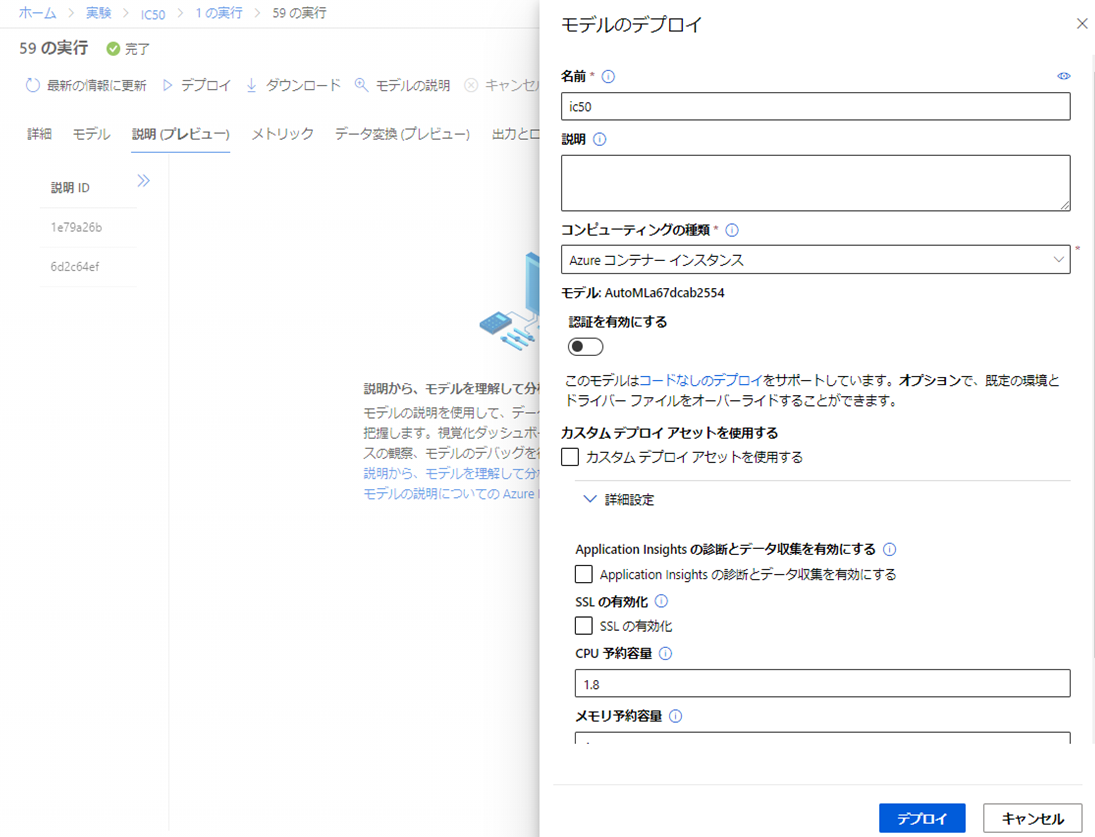
デプロイタブを選択後、右側出てくるパネルに必要な情報を入力し「デプロイ」をクリックしよう。
なお、今回コンピューティングの種類として「Azure コンテナーインスタンス」を選択した。
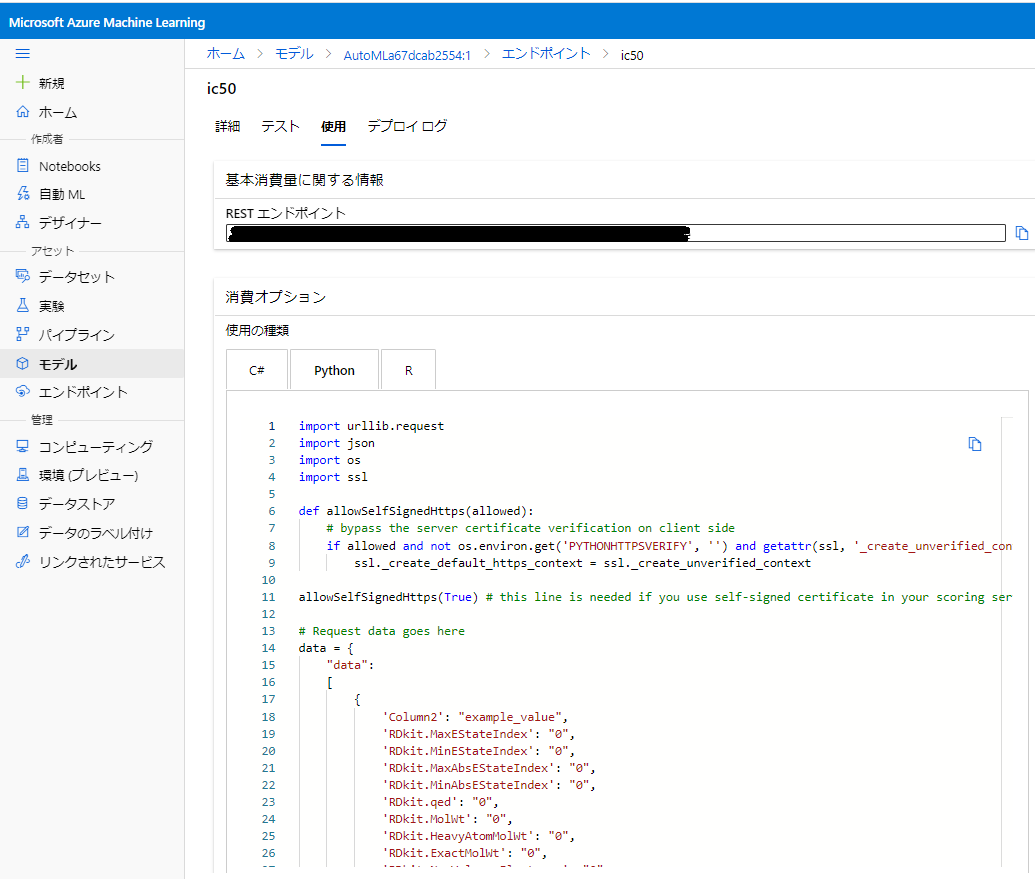
デプロイモデルを用いたテストデータの予測
左メニューから「モデル」⇒モデル名⇒「エンドポイント」⇒名前と選択していき、「使用」タブをクリックすると、ローカル上で予測を実行するためのPythonコードが表示されるためこれをコピペして保存しよう。
保存したPythonコードを以下のように修正する。URLはXXXに置き換えている。修正のポイントは以下の通りである。
- 'Column2' という余計な説明変数が追加されているのでダミーで値を設定。追加された理由は不明だが、読み込み時に勝手に追加されたものを、モデル構築時に除外しなかったためと考えている。
- 23行 x 1499 列のテストデータが入ったcsvファイルを読み込み、予測を行い、結果をファイルに保存するよう変更。なお、最大のポイントは、APIに与える説明変数-値のディクショナリにおいて、キーの順番がダウンロードしたサンプルにおける説明変数の順番に完全に一致している必要があるという点である。
import urllib.request
import json
import os
import ssl
def allowSelfSignedHttps(allowed):
# bypass the server certificate verification on client side
if allowed and not os.environ.get('PYTHONHTTPSVERIFY', '') and getattr(ssl, '_create_unverified_context', None):
ssl._create_default_https_context = ssl._create_unverified_context
allowSelfSignedHttps(True) # this line is needed if you use self-signed certificate in your scoring service.
# Request data goes here
data = {
"data":
[
{
'Column2': "example_value",
'RDkit.MaxEStateIndex': "0",
'RDkit.MinEStateIndex': "0",
'RDkit.MaxAbsEStateIndex': "0",
# 中略
'Mordred.Zagreb2': "0",
'Mordred.mZagreb1': "0",
'Mordred.mZagreb2': "0",
},
],
}
import pandas as pd
df = pd.read_csv("../results/test.csv", index_col=0)
df = df.iloc[:, 1:]
datas = []
for i, (name, item) in enumerate(df.iterrows()):
data_dict = {}
data_dict['Column2'] = "example_value"
for key in data["data"][0].keys():
if key in item:
data_dict[key] = item[key]
datas.append(data_dict)
data_dict_all = {}
data_dict_all["data"] = datas
body = str.encode(json.dumps(data_dict_all))
url = 'XXXX'
api_key = '' # Replace this with the API key for the web service
headers = {'Content-Type':'application/json', 'Authorization':('Bearer '+ api_key)}
req = urllib.request.Request(url, body, headers)
try:
response = urllib.request.urlopen(req)
result = response.read()
results = json.loads(result)
json_dict = json.loads(results)
pd.DataFrame(json_dict["result"]).to_csv("../results/azure_result.csv")
except urllib.error.HTTPError as error:
print("The request failed with status code: " + str(error.code))
print(error.info())
azure_result.csv に予測結果が保存されるため、正解データと比較しR^2を求める。
次はいよいよの結果発表である。
衝撃の結果発表
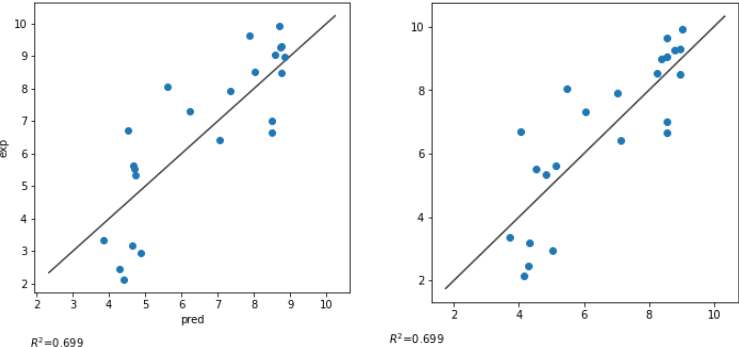
Azuruの外部データに対する精度はR^2: 0.699 となりまさかの引き分けとなりました。
左が手動モデル、右がAzuruモデルの予測実測プロットですが、予測の傾向も似たような傾向になりました
感想
人手でオーソドックスな手順で作ったのに対し、Azuruは何種類ものアルゴリズムによるアンサンブル学習であり、それに引き分けたということで人として一応面目は保たれた。
とはいえ、この難しい小データに対し、アンサンブル学習により高い汎化能力をもつモデルを構築したことは見事である。
より大規模なデータで勝負した場合、負ける可能性が非常に高い。
今後ますますAutoMLは賢くなり、人は追いつけなくなるであろう。。。
ということで今後はモデル構築はAutoMLにまかせ、人は説明性の向上などに注力した方がよいのかもしれない。
おまけ
ちなみに、AzureのLGBMRegressorの精度(最終的にアンサンブルモデルには利用されなかったのだが)はR^2は0.379であり、そのパラメータは以下の通りであった。
{
"min_data_in_leaf": 20
}
こちらで最適化したパラメータは以下であったので、**もう少しパラメータの調整の余地があったのでは?**とコメントしてみる。
{
'n_estimators': 31,
'max_depth': 8,
'num_leaves': 10,
'min_child_weight': 0.7727276588456078,
'subsample': 0.6447022221030615
}