はじめに
はじめまして。Qiita初投稿。エンジニア職を目指しAidemyで勉強中です。
初めてのAIアプリを作ってみての自分なりの経験をまとめます。先に結果を言いますと非常にできの悪いアプリになったため、温かい目で感想、アドバイスなどあればよろしくお願いします。
概要
何のアプリを作ろうか何も考えてなく、ぼーっと空を見ていてふと雲の画像識別を作ろうと考えました。
まず雲の種類は10種類あるので、それぞれの画像がどの雲に該当するかを判断するモデルを作る。
流れ
- まずは雲の写真を収集(1種類100枚前後)
- 写真からそれぞれの種類の雲を分類
- 機械学習で雲の種類を学習させたモデルを作成
- 結果と反省。モデルの精度向上を目指して
- まとめ
言語はPython、環境はGoogle Colaboratoryを使用しました。
1. まずは雲の写真を収集(1種類100枚前後)
10種類の雲は「"巻積雲","巻層雲","巻雲","高積雲","高層雲","乱層雲","積乱雲","積雲","層積雲","層雲"」という風に分かれています。
 "巻積雲"
"巻積雲"
 "巻層雲"
"巻層雲"

"巻雲"

"高積雲"
 "高層雲"
"高層雲"

"乱層雲"

"積乱雲"
 "積雲"
"積雲"

"層積雲"
 "層雲"
"層雲"
画像を集める際にicrawlerという便利なPythonのパッケージを使いました。
icrawlerとはGoogle、Bing、Baidu、Flickrなどの画像検索サービスから画像をダウンロードしてくれる便利なPythonのパッケージです
使い方は下記のサイトを参考にしました。
https://atmarkit.itmedia.co.jp/ait/articles/2010/28/news018.html
10種類の雲をそれぞれスクレイピングしフォルダに格納しました。
2. 写真からそれぞれの種類の雲を分類
画像を集めたものをチェックします。まず関係ない画像やイラストもとってきてたのでそれ削除し、スクレイピングしたものと違う雲の画像も多かったので正しいフォルダに画像を写す。
また、1つの画像に複数の種類の雲が写っていた場合は特定の種類の雲のみ切り取る。
ほぼ全ての画像に複数の種類の雲が写っていたので、この作業だけでも一苦労でした。
3. 機械学習で雲の種類を学習させたモデルを作成
インターネットから取得した画像は、cv2を用いて50×50にリサイズしてます。
まず最初にvgg16モデルを使えば、それなりの精度のものが作れると思いモデルの作成を始めました。
VGG16というのは,「ImageNet」と呼ばれる大規模画像データセットで学習された16層からなるCNNモデルです。ここに全結合層を再度学習させてみました。
転移学習のコード
input_tensor = Input(shape=(50, 50, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.3))
top_model.add(Dense(128, activation='relu'))
top_model.add(Dropout(0.3))
top_model.add(Dense(10, activation='softmax'))
model = Model(vgg16.input, top_model(vgg16.output))
for layer in model.layers[:15]:
layer.trainable = False
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.8),
metrics=['accuracy'])
しかし正答率が10%強にしかならず、層を増やしてもあまり変わらず、転移学習を使わずにやってみると
こちらではおおよそ30%の正答率になったのでこちらでモデルを作ることにしました。
転移学習を使わない場合
model = Sequential()
model.add(Conv2D(filters=32, kernel_size=(2, 2), input_shape=(50, 50, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(225))
model.add(Activation('relu'))
model.add(Dense(110))
model.add(Dropout(0.3))
model.add(Dense(255))
model.add(Activation('relu'))
model.add(Dense(110))
model.add(Dense(10))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='adadelta',
metrics=['accuracy'])
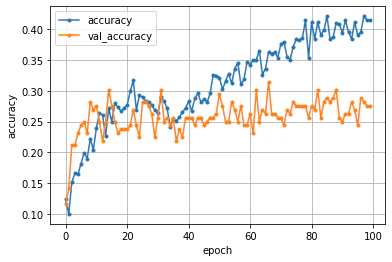
訓練データは40回あたりから右肩上がりだが、検証データに対してはずっと横ばい。
4. 反省、モデルの精度向上を目指して
機械学習では、データ集めや前処理が大切と言われている通り、作業の中でいちばん時間を割くことになりました。特に雲の場合1枚1枚千差万別で1枚の画像の中に複数の雲が混じっていることなど当たり前で、あまり良く撮れてない画像などもあり、目で見てもどの種類か判別に苦労しました。また色や形など(半透明やしろ〜黒に近いグレー)で見分けるにしても、朝方や夕方、日が落ちる直前などの画像は見た目でもほぼ判別不可能だったので学習する画像から排除したりして正答率が若干上がりました。
こちらのサイトでもわかるように変種や部分的な特徴もだいぶ被っているので振り分けるのに苦労しました。
http://www1.linkclub.or.jp/~kinoko/AboutCloud.html
例えば、「積雲」の一種の雄大積雲と、無毛の「積乱雲」(いわゆる雷雲)の違いは雷があるかどうかだけなので画像で判別しようがないと思い、雄大積雲は積乱雲の方に入れました(一般の人にはどちらも入道雲と呼ばれている)。その他も少しの大きさの違いや厚み、雲の高さなどで分かれるのでかなり大変でした。
改良点ばかりなので、まず考えられるのは
・画像を増やす(集めたり、左右反転、水平移動、高いところの雲は回転させてもいいかも)
・空は「高層、中層、低層」に分かれているのでそれぞれの層別にモデルを作る。
・他の転移学習も試してみる。
など
まとめ
自分がこの数カ月で学んだことはわずかだと思います。
これからの課題は山ほどありますが、とりあえず何かを作って行ったり、実践することが上達の近道だと思いますので、色々なアプリを作ったり、kaggleやsignateへの挑戦、数学的・統計的な知識などを積極的に学んでいこうと思います。
長く内容も薄いものになりましたが、ここまで読んでくださりありがとうございました。