はじめに
最近検索エンジンの調査や構築をよくやっています。
今回はAzure Cognitive Searchで日本語全文検索を構築したのでそのときの備忘録。
前提環境
今回は次の環境で開発しています。理由は既にあったから。
- python 3.8.5 (anaconda 3)
Azure Cognitive Searchとは
Azure Cognitive Searchは、Microsoft社が提供するクラウドの検索サービスです。 Azure Cognitive Searchはいわゆる全文検索エンジンの一種で、複数の文書を横断検索するためのシステムです。
目次
1. Azure Cognitive Searchの始め方
Azure Cognitive Searchの料金体系
Azure Cognitive Searchは気軽に始められます。なんとFreeプランあり。素敵。
初期値はStandardで、一般的にはBasicかStandardを選ぶようです。今回はFreeプランです。
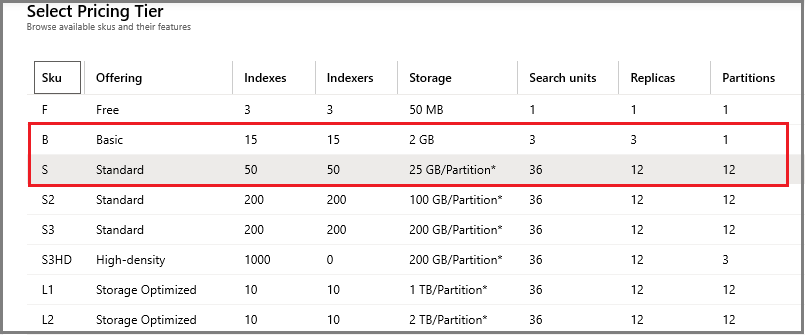
参考. 価格レベルの選択
導入ステップ(簡易)
基本的には次の4ステップからなりますが、今回は②にフォーカスをあてた備忘録です。
① Azure Portalからサービス作る
② 検索インデックスを定義する(←今回の記事)
③ コンテンツをアップロードする
④ 検索クエリ投げてインデックスを検索する
参考. Azure Cognitive Searchとは-ファーストステップ(microsoft.com)
サービスの作成
②の前に①。サービスを作成しておきます。
- いつものAzure PortalからAzure Cognitive Searchを作成。
 |
|---|
- 名前は何でも良いですが、今回は"anlalyzer-test"にしました。
- リージョンは日本っぽいところ。
- そして忘れずにFree(無料)プランにして「確認および作成」押して作成します。
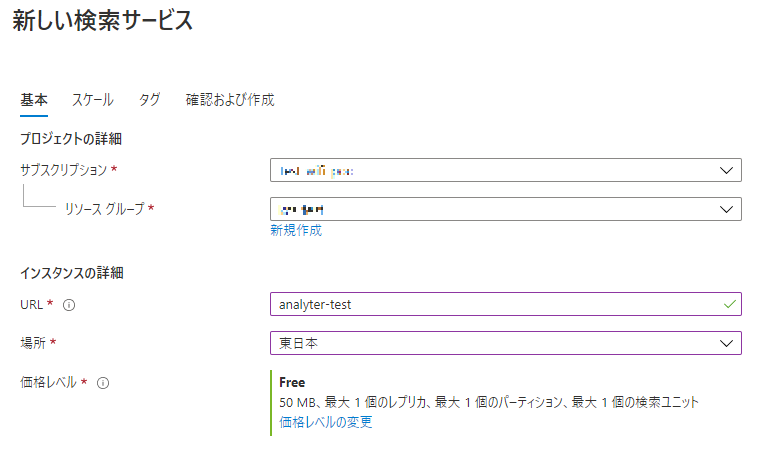 |
|---|
2. インデックススキーマの定義とアナライザー
インデックススキーマとは、インデックスのスキーマのことです(そのまま)。基本的なインデックスはどの全文検索エンジンも「転置インデックス」を基本としています(間違っていたらごめんなさい)。
参考:転置インデックスの説明(gihyo.jp: 検索エンジンは如何にして動くのか-第3回 転置索引とは何か?)
ちなみに、Azureのインデックススキーマは主に、以下の項目定義からなります。
- フィールドコレクション:検索対象のデータ、検索方法、データの解析器、同義語などを設定します。
- サジェスター:このインデックスで検索するためのオートコンプリートデータを定義します。
- スコアリングプロファイル:検索結果の並び替えスコアを定義します。
- アナライザー:主にデータのワード分割処理を定義します(カスタム)。
この中だと「アナライザー」と「スコアリングプロファイル」が検索精度に特に大きな影響を与えます(と思っています)。インデックスを作成するためには、各検索対象データにおいて、索引単位となるワード(トークン)を取り出す必要がありますが、このアナライザーは、そのトークンを取り出す処理方法を指定するものになります。
最も単純なものとして、英語などの文章の場合、スペース区切りで分割する処理があります。
インデックスの定義は、実はAzure Portalから実施するのが可能で、かつ簡単です。ただし同義語設定、サジェスターなどの細かい設定はまだできないようです。そのため今回はpythonからやってみることにします。
なぜpythonかは、私がpython勉強中だから。まずは環境設定。
## Azure 環境設定
service_name = 'mysearch'
index_name = 'test-index'
endpoint = f'https://{service_name}.search.windows.net/'
api_key = <APIキー>
headers = {'Content-Type': 'application/json', 'api-key': api_key}
search_api_version = '?api-version=2020-06-30'
create_url = f'{endpoint}indexes{search_api_version}' #POST
analyze_url = f'{endpoint}indexes/{index_name}/analyze{search_api_version}'
試しに作ってみます。インデックス定義は次の感じ。データや各項目に特に意図はないですが、タイトル(title)と内容(description)を全文検索するイメージです。詳細な検索オプションについては別途参照してください。
| 項目 | データ型 | 返却 | フィルタ | ソート | ファセット | 検索 | アナライザー |
|---|---|---|---|---|---|---|---|
| docID(キー) | Edm.String | True | False | False | False | False | なし |
| category | Edm.String | True | True | False | True | False | なし |
| title | Edm.String | True | False | False | False | True | ja.microsoft |
| description | Edm.String | True | False | False | False | True | ja.microsoft |
インデックス作成コードは次の通り。
# 2020.12.1 時点、python SDKは機能が限定されるため REST APIをそのまま叩きます。
import json
import requests
from pprint import pprint
import settings # 設定値読み込み
index_body = {
{'name': 'docId',
'type': 'Edm.String',
'key': True,
'retrievable': True,
'filterable': False,
'sortable': False,
'facetable': False,
'searchable': False},
{'name': 'category',
'type': 'Edm.String',
'key': False,
'retrievable': True,
'filterable': True,
'sortable': False,
'facetable': True,
'searchable': False},
{'name': 'title',
'type': 'Edm.String',
'key': False,
'retrievable': True,
'filterable': False,
'sortable': False,
'facetable': False,
'searchable': True,
'analyzer': 'ja.microsoft',
'synonym': ''},
{'name': 'issue',
'type': 'Edm.String',
'key': False,
'retrievable': True,
'filterable': False,
'sortable': False,
'facetable': False,
'searchable': True,
'analyzer': 'ja.microsoft',
'synonym': ''},
}
index_schema={
'name': settings.index_name,
'fields': index_body
}
response = requests.post(settings.create_url,
headers=settings.headers,
json=index_schema)
index = response.json()
pprint(index)
3. 日本語のアナライザーと特徴
日本語の文章から名詞や動詞などをトークナイズする場合は形態素解析を行いますが、基本的には、Azure Cognitive Searchの場合は言語アナライザーである「Standard Analyzer ( ja.lucene )」か「Microsoft Analyzer ( ja.microsoft )」のいずれかを使うことになります。
尚、Azureでは次表のアナライザーが指定・構成可能です。特殊アナライザーやカスタムアナライザーは特定のケースをインデックス化する際に指定します。
| トークナイザ | サブカテゴリ | 説明 | 日本語処理 |
|---|---|---|---|
| Standard Lucene Analyzer |
(言語ごと) | 既定値です。みなさんご存知 Apache Lucene が出自の アナライザーです | ◎:日本語用アナライザー有り (ja.lucene) |
| Predefined analyzers | 特殊 | Webページやログファイルからのスクレイピングなど、特定の処理のみが必要なケースで利用します。 例)Asciifolding, Keyword, Pattern, Simple, Stop, Whitespace | △:日本語ベースでないが、処理可能 |
| (同上) | 言語 | 各言語に合わせたMicrosoftお手製の言語アナライザー。うまいこと形態素解析してくれます。 | ◎:日本語用アナライザー有り (ja.microsoft) |
| Custom Analyzers | (ユーザ定義) | 予め定義されたちょっと便利なトークナイザ+フィルターで構成する。トークナイザにはNgram、パス文字列、メールスタイル、redefined Anzlyersも使える。最近日本語の言語アナライザーも使えるようになったようです) | ◯:言語アナライザーもある(いつの間にか!) |
| 参考. Azure Congnitive Searchでのテキスト処理のためのアナライザー |
4. アナライザーを選ぶ。
Predefinedの特殊アナライザーは、特殊なケースがわかりやすいので見るだけでわかると思います。正規表現は自分で作らねばですが。ただ、標準アナライザー、言語アナライザーはドキュメント見ただけだとja.luceneとja.microsoftの違いがよくわからない。
アナライザを動かして感触を得る
AzureはAnalyzerテストができるんですね。イタレリツクセリ。単純なテストコードを以下に。
参考. テキストの分析 (Azure Cognitive Search REST API)
import settings # Azure設定の読み込み
## テスト文字列
analyzing_text = 'すもももももももものうち'
## Microsoft Analyzer
microsoft_analyzer = {
'text': analyzing_text,
'analyzer': 'ja.microsoft'
}
ms_resp = requests.post(settings.analyze_url, headers=settings.headers, json=microsoft_analyzer)
pprint(ms_resp.json())
## Lucene Analyzer
lucene_analyzer = {
'text': analyzing_text,
'analyzer': 'ja.lucene'
}
lucene_resp = requests.post(settings.analyze_url, headers=settings.headers, json=lucene_analyzer)
pprint(lucene_resp.json())
結果はjsonで返却されます。
# 結果はこちら
{'@odata.context':
'https://mysearch.search.windows.net/$metadata#Microsoft.Azure.Search.V2020_06_30.AnalyzeResult',
'tokens': [{'endOffset': 3, 'position': 0, 'startOffset': 0, 'token': 'すもも'},
{'endOffset': 4, 'position': 1, 'startOffset': 3, 'token': 'も'},
{'endOffset': 5, 'position': 2, 'startOffset': 4, 'token': 'も'},
{'endOffset': 6, 'position': 3, 'startOffset': 5, 'token': 'も'},
{'endOffset': 7, 'position': 4, 'startOffset': 6, 'token': 'も'},
{'endOffset': 9, 'position': 5, 'startOffset': 7, 'token': 'もも'},
{'endOffset': 12, 'position': 7, 'startOffset': 10, 'token': 'うち'}]}
{'@odata.context'
'https://mysearch.search.windows.net/$metadata#Microsoft.Azure.Search.V2020_06_30.AnalyzeResult',
'tokens': [{'endOffset': 3, 'position': 0, 'startOffset': 0, 'token': 'すもも'},
{'endOffset': 6, 'position': 2, 'startOffset': 4, 'token': 'もも'},
{'endOffset': 9, 'position': 4, 'startOffset': 7, 'token': 'もも'}]}
簡単な動作確認から見えるのは、
- Microsoftの言語アナライザー(上)は、文法と辞書に基づく古典的な形態素解析ではなさそうです。
噂の深層学習とかBERTとかでしょうか、発展途上のイメージ。品詞フィルタはなさそうなので「も」とか残ってますね。 - Lucene(下)は、名詞をうまく抜き出している。既定のアナライザーなだけはあります。
現状の動作だと、名詞のみを抽出していますので、品詞フィルタとかかかってそうですね。
ですね。
検索したい文書の言いっぷりで見てみる
同じ日本語でも単語だったり言い方だったり、対象とする検索文書によっても選ぶアナライザーは異なってくることが考えられます。ここでは例として川崎市HP「よくある質問(FAQ)」を検索することを考えます。
FAQの問合せ文「小児医療費助成制度の通院医療費の所得制限の限度額について知りたい。」をanalyzerでテストした結果は次の通りです。
# 結果はこちら
{'@odata.context':
'https://kcs-test.search.windows.net/$metadata#Microsoft.Azure.Search.V2020_06_30.AnalyzeResult',
'tokens': [{'endOffset': 2, 'position': 0, 'startOffset': 0, 'token': '小児'},
{'endOffset': 4, 'position': 1, 'startOffset': 2, 'token': '医療'},
{'endOffset': 5, 'position': 2, 'startOffset': 4, 'token': '費'},
{'endOffset': 7, 'position': 3, 'startOffset': 5, 'token': '助成'},
{'endOffset': 9, 'position': 4, 'startOffset': 7, 'token': '制度'},
{'endOffset': 12, 'position': 6, 'startOffset': 10, 'token': '通院'},
{'endOffset': 14, 'position': 7, 'startOffset': 12, 'token': '医療'},
{'endOffset': 15, 'position': 8, 'startOffset': 14, 'token': '費'},
{'endOffset': 18, 'position': 10, 'startOffset': 16, 'token': '所得'},
{'endOffset': 20, 'position': 11, 'startOffset': 18, 'token': '制限'},
{'endOffset': 23, 'position': 13, 'startOffset': 21, 'token': '限度'},
{'endOffset': 24, 'position': 14, 'startOffset': 23, 'token': '額'},
{'endOffset': 27, 'position': 16, 'startOffset': 25, 'token': 'つい'},
{'endOffset': 28, 'position': 17, 'startOffset': 27, 'token': 'て'},
{'endOffset': 30, 'position': 18, 'startOffset': 28, 'token': '知り'},
{'endOffset': 32,
'position': 19,
'startOffset': 30,
'token': 'たい'}]}
{'@odata.context':
'https://kcs-test.search.windows.net/$metadata#Microsoft.Azure.Search.V2020_06_30.AnalyzeResult',
'tokens': [{'endOffset': 2, 'position': 0, 'startOffset': 0, 'token': '小児'},
{'endOffset': 4, 'position': 1, 'startOffset': 2, 'token': '医療'},
{'endOffset': 5, 'position': 2, 'startOffset': 4, 'token': '費'},
{'endOffset': 7, 'position': 3, 'startOffset': 5, 'token': '助成'},
{'endOffset': 9, 'position': 4, 'startOffset': 7, 'token': '制度'},
{'endOffset': 12, 'position': 6, 'startOffset': 10, 'token': '通院'},
{'endOffset': 14, 'position': 7, 'startOffset': 12, 'token': '医療'},
{'endOffset': 15, 'position': 8, 'startOffset': 14, 'token': '費'},
{'endOffset': 18, 'position': 10, 'startOffset': 16, 'token': '所得'},
{'endOffset': 20, 'position': 11, 'startOffset': 18, 'token': '制限'},
{'endOffset': 23, 'position': 13, 'startOffset': 21, 'token': '限度'},
{'endOffset': 24, 'position': 14, 'startOffset': 23, 'token': '額'},
{'endOffset': 30,
'position': 16,
'startOffset': 28,
'token': '知る'}]}
結果としては次の通り。
- Microsoftの言語アナライザー(上)は「つい」「て」といった助詞や「知り」「たい」など動詞の変形が残されています。
- Lucene(下)は、動詞の変形を正規化していますね(知りたい⇒知る)。また「ついて」が除外されています。
検索の視点でアナライザーを評価する
おおよその動作としては示した通りですが、検索の視点でまとめます。
- 両方のアナライザーとも「医療費」が「医療」と「費」に分割されています。「所得制限限度」も同様に分割されています。「所得制限限度」という単語を検索したい場合はダブルクォートでくくるなどの工夫が必要になる。
- Microsoftの方は、抽出する品詞が多い。ただし「の」などのあまりに一般的なものは除外。
変形も対応しているので入力文字列に沿った検索になる。 - Luceneの名詞の抽出はこなれている。動詞を正規化するので時制を無視した検索になる。
Azure Cognitive Searchでは、インデックス化のときと検索のとき、それぞれアナライザを指定できます。しかし上記から、一般的には一緒のものを使った方が良いと思います。
おわりに
各アナライザーは都度進化しており、今回の選び方もあくまで現時点(2020.12.07)の主観的な感想です。検索エンジンの選択では、カタログスペックでは示せない色々があります。検索サービス毎にストレージの速さやインデクサーの有無などの特徴があったりします。個人的には「使ってみなきゃわからない」サービスで、かつ更新頻度が高いサービスであると思っていますので「継続ウォッチ&使ってみる」をしていきたいと思います。
商標など
Microsoft、Microsoft Azureは米国Microsoft Corporationの米国およびその他の国における登録商標または商標です。
Apache、Apache Luceneは、米国および他の国々で登録されたApache Software Foundationの商標です。
記載の会社名、製品名、サービス名等はそれぞれの会社の商標または登録商標です。