はじめに
検索結果の改善を支援するためのツールに Quepid (キューピッド)というものがあります。
QuepidのソースコードはGitHubで公開されており、2019年に初回コミットがあり現在も継続的に改修が行われています(Quepid自体は2014年頃にはあったよう link)
Quepidという存在については数年前から知っていたものの、具体的に何が出来るのか、評価・改善をどう行うのかは分かっていなかったため、今回Quepidについて調査してその内容をまとめます。
もし有用そうであれば、検索結果を今後人手で評価する時に、利用または参考にしたいと思っています。
本記事で分かること
最初にQuepidについての概要について触れた後、ローカル環境でQuepidを起動して最終的に検索結果を評価するところまで試します。
- Quepid概要やコア概念
- ローカル環境でのQuepidの起動方法
- ローカル環境でQuepidとElasticsearchを連携して検索結果を評価する方法
- ケース(Elasticsearchとの連携、評価クエリの追加)作成
- 検索結果の評価
本記事は動作させることを主目的にしているため、検索結果の評価用スコアを出すところまでの流れを主に記述します。
そのため、具体的な改善方法や評価方法に主眼を置いた記述はありません。
Quepid概要
検索エンジンの結果の品質を評価・改善するためのオープンソースのツールです。
検索エンジンとして今回はElasticsearchを用いますが、SolrやOpenSearch、Algoriaなど他エンジンとの連携もサポートしています。
Quepidの特徴としては以下が挙げられます。
| 特徴 | 内容 |
|---|---|
| 検索結果の評価 | 検索クエリに対する結果が適切かどうかを手動で評価する |
| クエリやスコアリングのチューニング | クエリやスコアリングアルゴリズムを調整しながら、検索結果のランキングを改善する |
| 定量評価 | PrecisionやRecall、nDCGなどの評価指標の計算が可能 |
| チームでのコラボレーション | 複数のユーザーが同じチームに参加することで評価を共有出来るため、チーム全体で検索精度の改善が行える |
Quepidのコア概念
Core ConceptsにQuepidで重要な概念(用語として捉えて良さそう)がまとめられていました。
以下に本記事で主に利用する用語を列挙しました。
| 用語 | 定義 |
|---|---|
| Case | 単一検索エンジンにおけるクエリと関連性設定 |
| Query | ケース内のクエリは、キーワードやその他の検索条件とそれに対応する検索結果セットを指す |
| Result | クエリ内の個々の結果ドキュメントを指す。これらが評価されクエリの累積スコアとなる。 |
| Rating | 個々の検索結果の関連性を示すスコア。各評価の解釈はクエリやケースで使用するスコアラーに依存 |
| Scorer | クエリ結果を評価するための指標を指す(e.g. AP, RR, CG, DCG, NDCGなど)。カスタムスコアラーを作成することも可能 |
これらを作成したり操作したりすることで、検索結果のスコアを算出することが出来ます。本記事で評価指標としてnDCGを用いて検索結果のnDCGスコアを算出します。
その他に、本記事ではほとんど登場しないですが、 ブック(プロジェクト管理、複数ケースの一元管理)や チーム(ユーザーグループ) などQuepidで重要となる用語があります。
Quepid起動前の事前準備
ここから実際に手を動かしていきます。
今回QuepidとElasticsearchを連携して結果を評価します。Quepidを起動する前に、Elasticsearchにデータ登録するところまで実施し、検索リクエストを行えるよう事前に準備します。
詳細は割愛しますが、以下の手順で行いました。
- Elasticsearchをローカル環境に起動する
- インデックス
esci-productsを作成する - インデックス
esci-productsに149422件のデータを登録する
- 登録データは、商品検索用データセットesci-dataを利用
- 「localeが"jp"のデータ」かつ「titleとdescriptionが両方とも存在するデータ」に絞って登録
※登録するにあたり search-research を参考にさせて頂きました。
マッピング定義は以下を明示的に定義しています。
{
"mappings": {
"properties": {
"product_id": {
"type": "keyword"
},
"product_title": {
"type": "keyword",
"ignore_above": 256,
"fields": {
"ja": {
"type": "text",
"analyzer": "kuromoji"
},
"en": {
"type": "text",
"analyzer": "standard"
}
}
},
"product_description": {
"type": "keyword",
"ignore_above": 256,
"fields": {
"ja": {
"type": "text",
"analyzer": "kuromoji"
},
"en": {
"type": "text",
"analyzer": "standard"
}
}
},
"product_bullet_point": {
"type": "keyword",
"ignore_above": 256,
"fields": {
"ja": {
"type": "text",
"analyzer": "kuromoji"
},
"en": {
"type": "text",
"analyzer": "standard"
}
}
},
"product_brand": {
"type": "keyword"
},
"product_color": {
"type": "keyword"
},
"product_locale": {
"type": "keyword"
},
"products_dense_vector": {
"type": "dense_vector",
"dims": 512,
"index": true,
"similarity": "cosine"
},
"type": {
"type": "keyword"
},
"image": {
"type": "keyword",
"index": false,
"doc_values": false
}
}
},
"settings": {}
}
ElasticsearchのCORS設定について
Elasticsearch側にCORS設定がないためエラーになるケースがあります。
エラーになった場合は、elasticsearch.ymlに以下を追記して起動し直してください。
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-headers: "X-Requested-With, Content-Type, Content-Length, Authorization"
http.cors.allow-methods: "OPTIONS, HEAD, GET, POST, PUT"
ローカル環境でのQuepidの起動方法
次にQuepidをセットアップしていきます。
Quepid関連のコンテンを立ち上げるために、quepidリポジトリの docker-compose.yml, docker-compose.prod.ymlやInstallation-Guideの情報を参考にしました。
GitHubにあるdocker-compose.ymlを用いてコンテナ起動しようとしましたが、自分の環境では動きませんでした。そのため、ymlファイルを少し修正した以下を用いて起動しました。
services:
app:
container_name: quepid_app
image: o19s/quepid:latest
environment:
- PORT=3000
- RACK_ENV=production
- RAILS_ENV=production
- DATABASE_URL=mysql2://root:password@mysql:3306/quepid
- FORCE_SSL=false
- MAX_THREADS=2
- WEB_CONCURRENCY=2
- SECRET_KEY_BASE=some_value_needed_here
- RAILS_LOG_TO_STDOUT=true
- RAILS_SERVE_STATIC_FILES=true
- EMAIL_MARKETING_MODE=false
- QUEPID_DEFAULT_SCORER=nDCG@10 #デフォルト評価指標用の環境変数
- COMMUNAL_SCORERS_ONLY=false
- QUERY_LIST_SORTABLE=true
ports:
- 3000:3000
links:
- mysql
depends_on:
- mysql
mysql:
container_name: quepid_db
image: mysql:8.3.0
ports:
- 3306:3306
environment:
- MYSQL_ROOT_PASSWORD=password
今回は検索結果を評価するために必要最低限のコンテナのみ(app, MySQL)を起動しています。また、Elasticsearchは別で起動していますが、上記の compose.yml に含めても問題ありません。
上記内容のcompose.ymlファイルを作成後、以下の順にコマンドを実行します。
% docker compose up -d mysql
% docker compose run --rm app bin/rake db:setup ### appコンテナを起動する前にmysqlにデータベースquepidが存在している必要があるため
% docker compose up -d app
コンテナ起動後の構成は以下のようになります。MySQLはQuepid上で追加更新した情報を格納するために利用します。
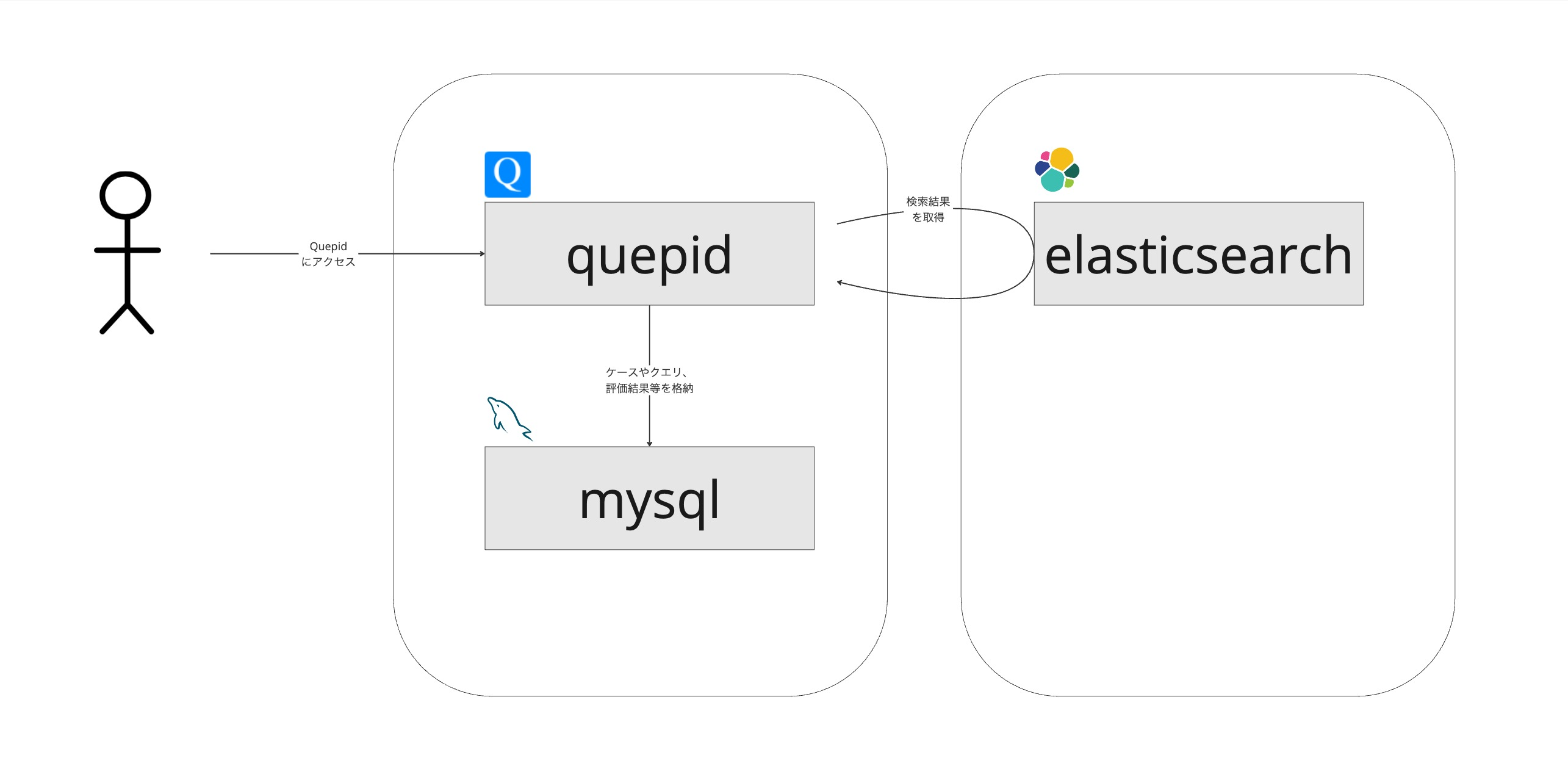
コンテナが全て正常に起動した後 http://localhost:3000 にアクセスすると以下のような画面が表示されます。
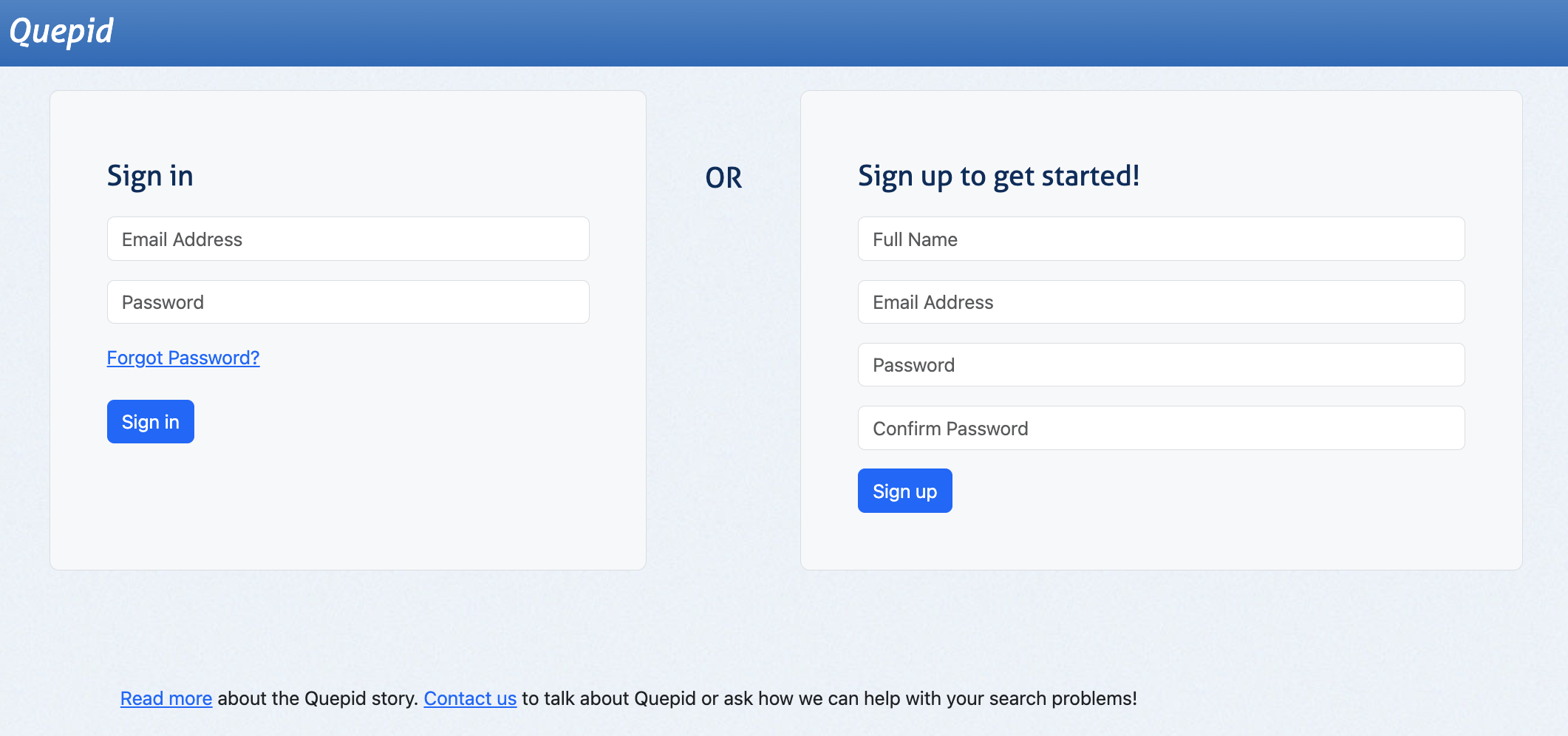
最初にアカウントを作成します。今回の用途はローカル環境用のため、作成できれば問題ないと思います。作成すると以下の画面に遷移します。
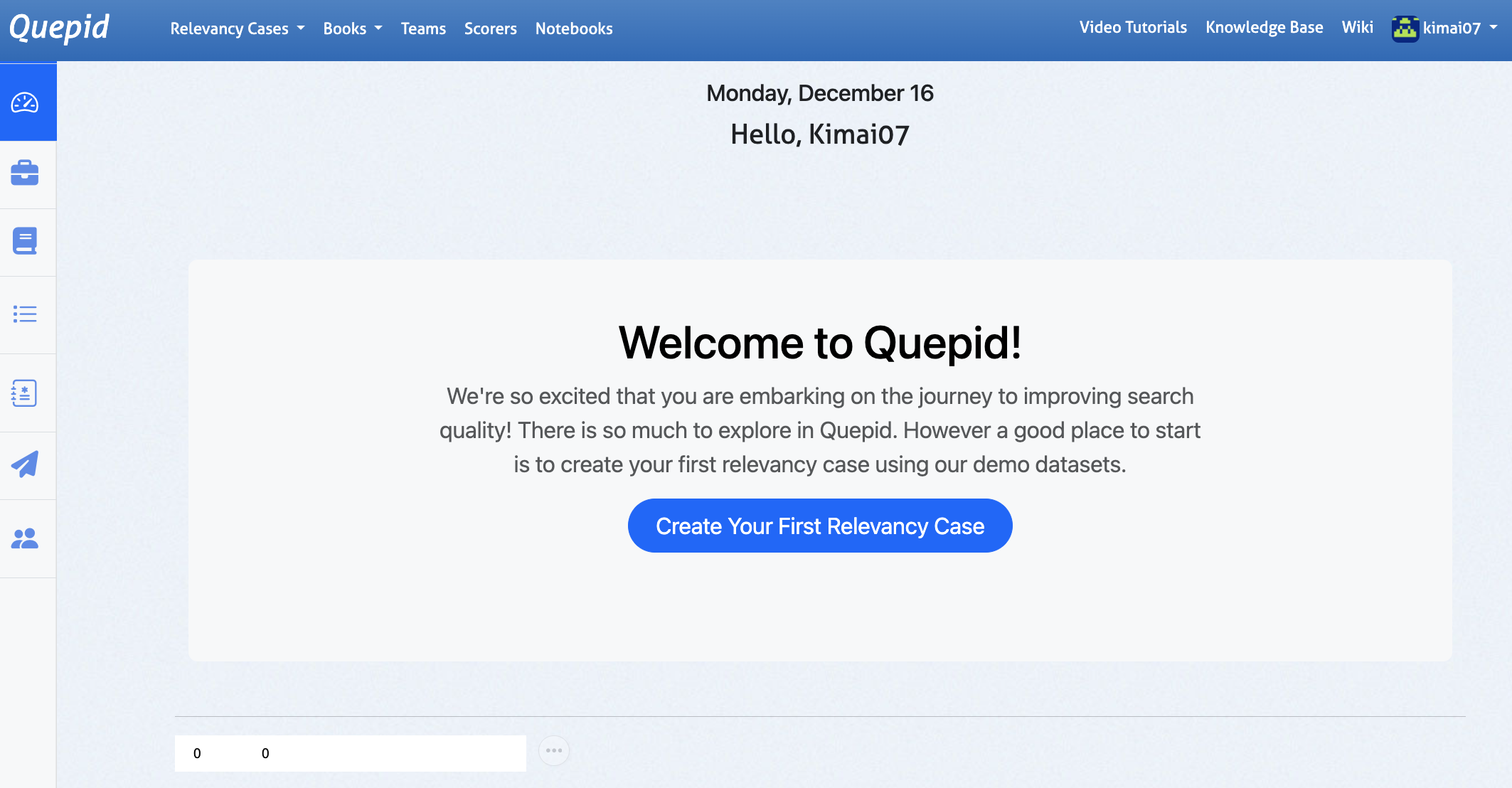
ケース作成
アカウント作成後、ケースを作成します。
ここからようやく検索結果を評価する準備に入っていきます。
手順等は以下リンクによくまとまっていますので参考に。
「Relevancy Case」の作成から以下の順に必要な情報を入力してケースを作成します。
| No | 内容 |
|---|---|
| 1 | ウェルカムのポップアップが表示されるのでContinueをクリック ! 
|
| 2 | ケース名「ESCI Search」を入力してContinueをクリック ! 
|
| 3 | 接続先の検索エンジンを設定します。URL(http://localhost:9200/esci-products/_search)など各種必要な情報を入力してContinueをクリック! 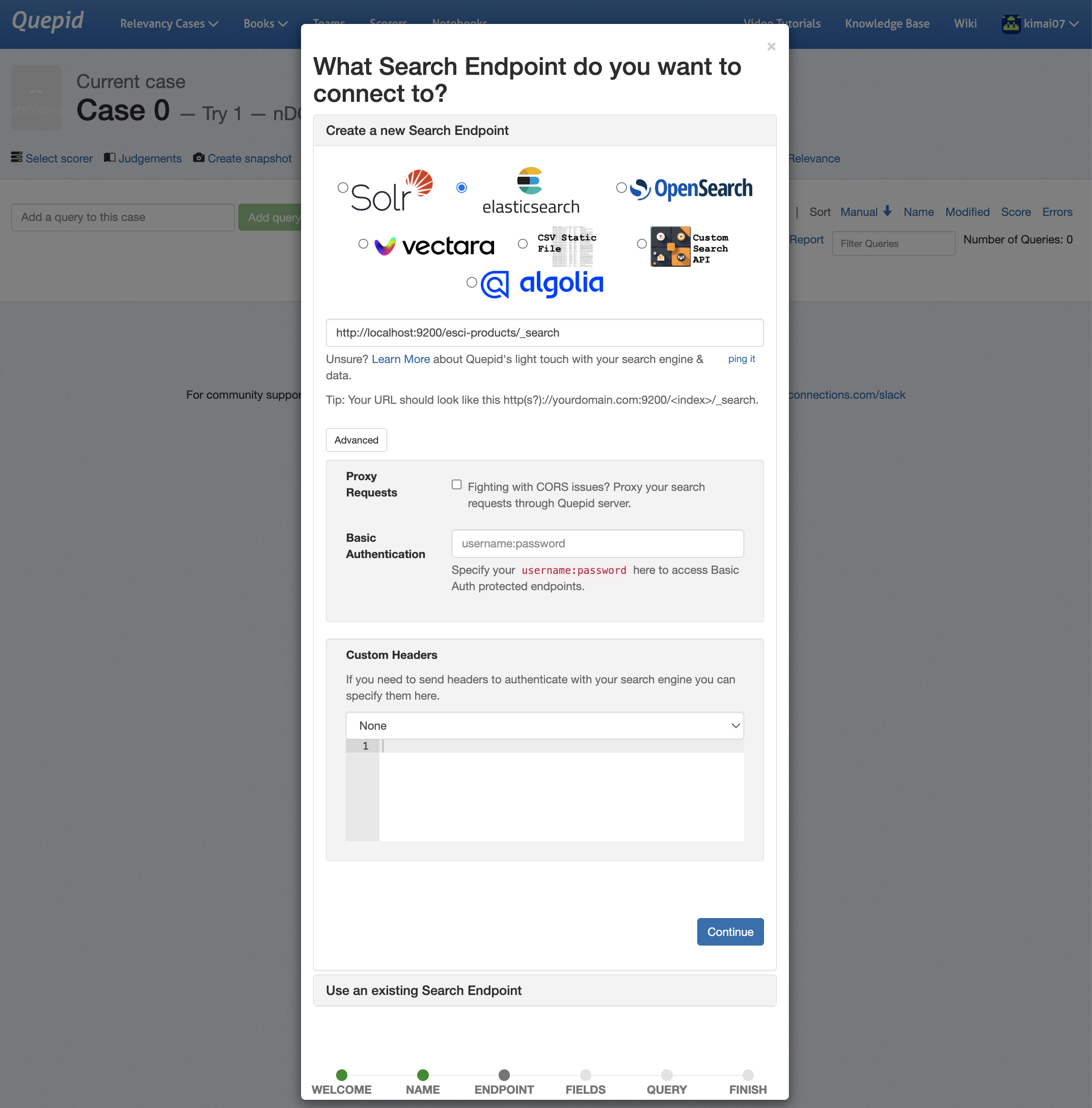
|
| 4 | 結果を評価する時に表示する情報を入力してContinueをクリック。 thumb: や image: で結果に画像を表示することも可能なようです。! 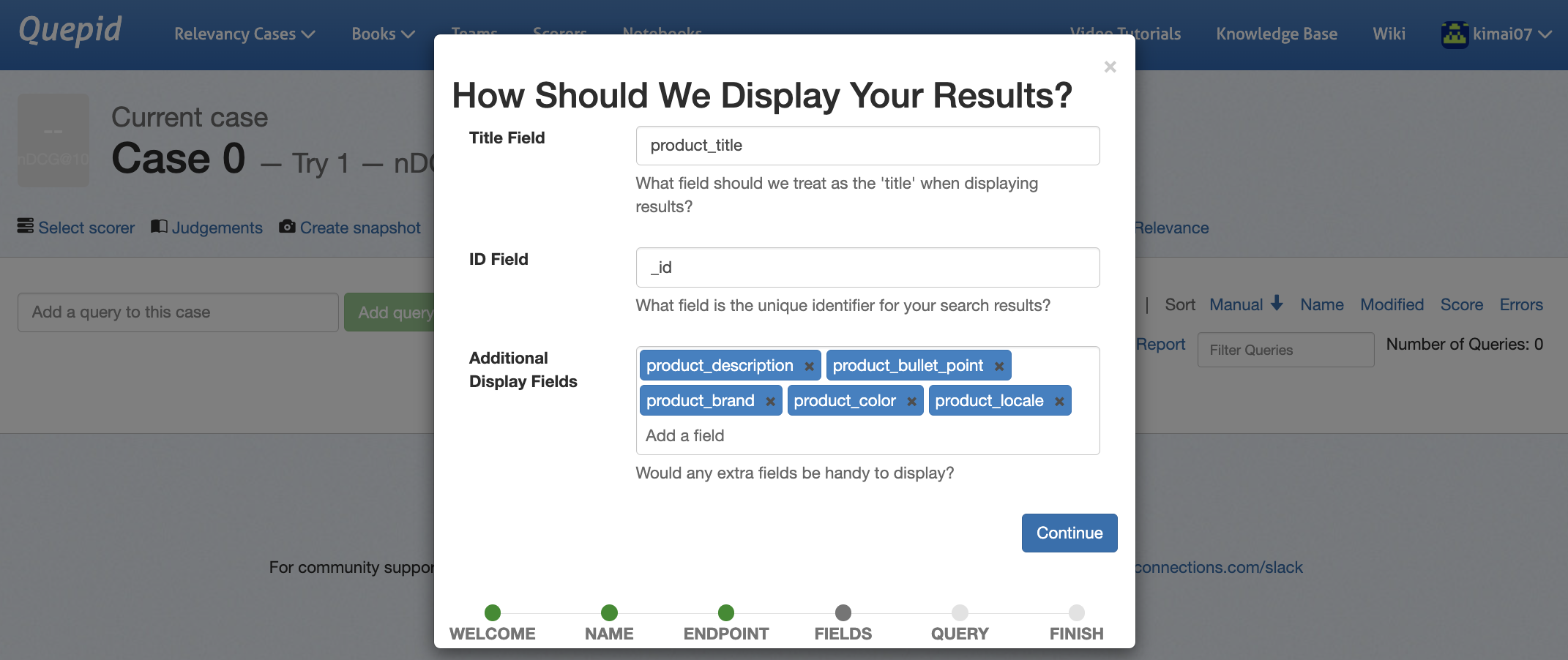
|
| 5 | 評価したいクエリを追加してContinueをクリック ! 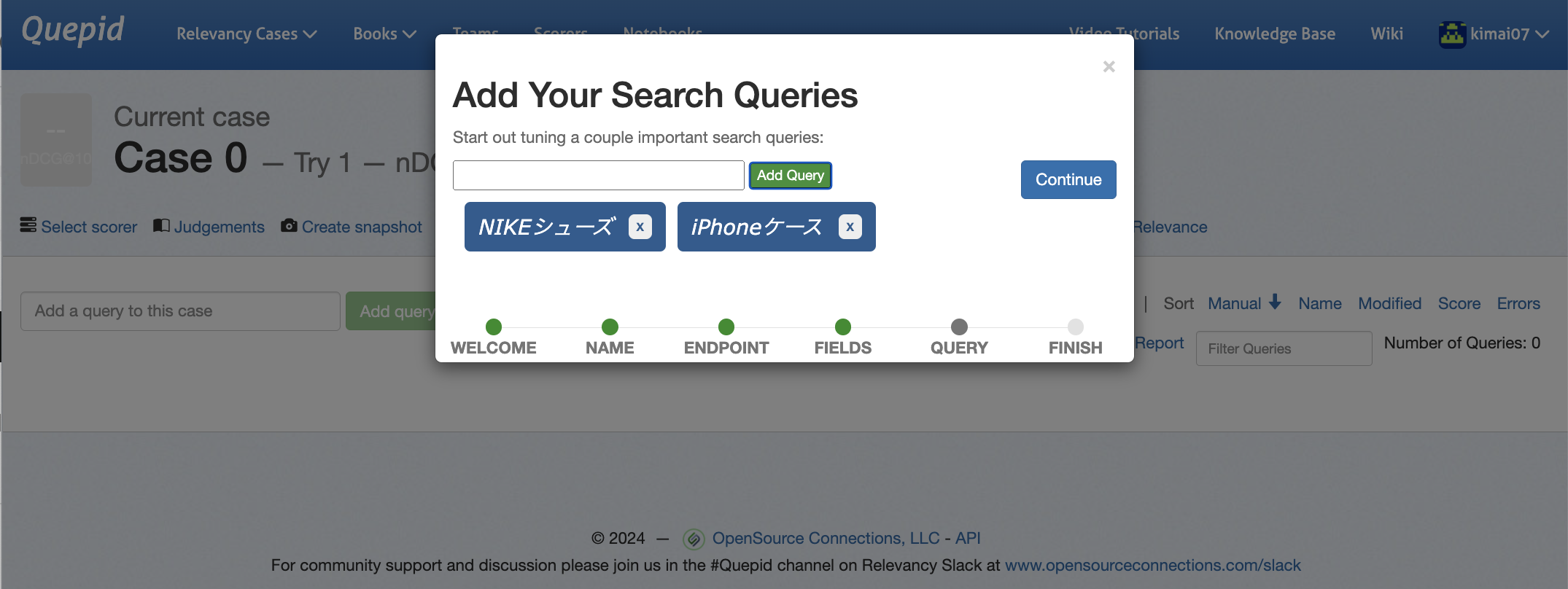
|
| 6 | ケース作成完了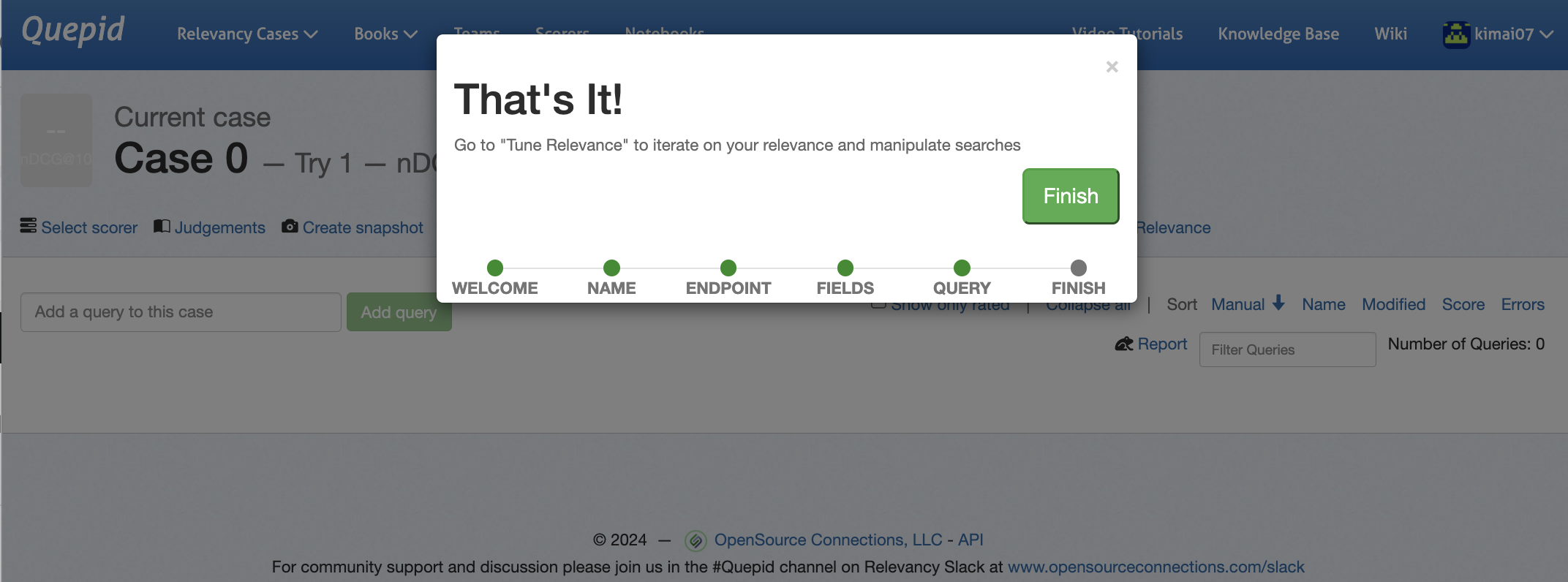
|
元の画面に戻って何度かリロードすると、以下のようなElasticsearchから取得した件数が表示されます。
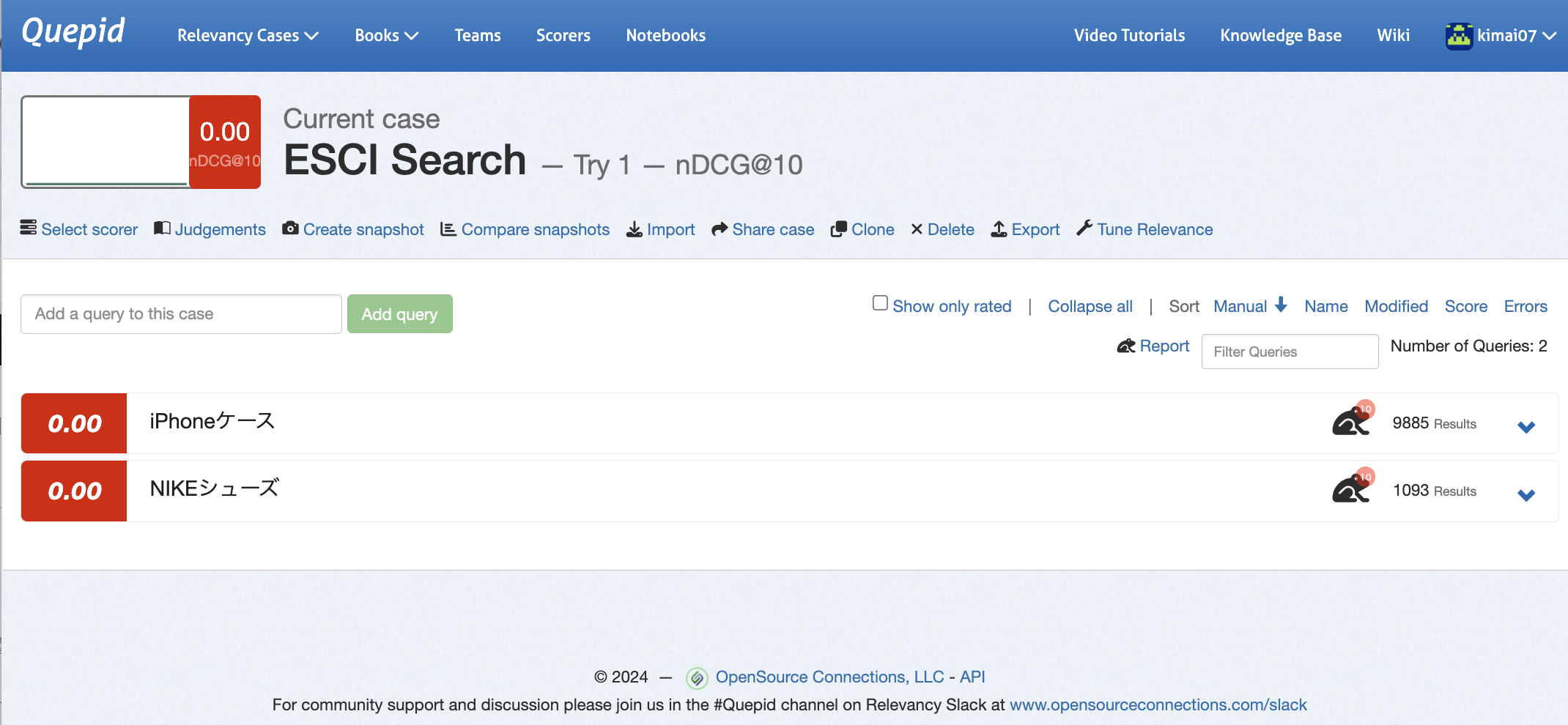
折りたたみ表示を展開するとElasticsearchのレスポンス情報が表示されていたり、今回は評価指標としてnDCGを選択したため、4段階で検索結果アイテムを評価出来ることが分かります。
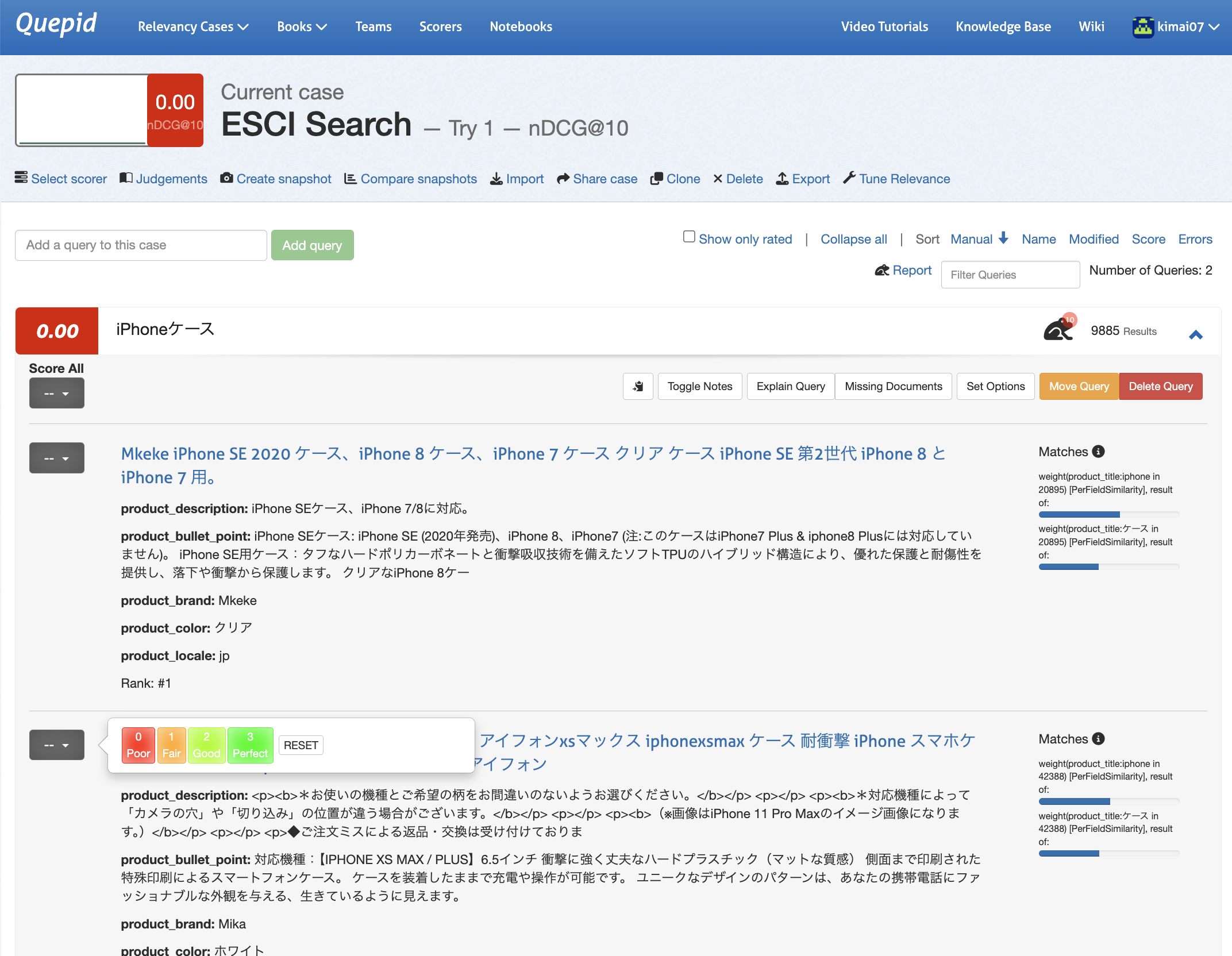
検索結果の評価
「Tune Relevance」というリンクをクリックすると画面の右側に「Query Sandbox」が表示されます。
「Query Sandbox」ではElasticsearchにリクエストするElasticsearchクエリを確認することが出来ます。デフォルトではmulti_matchクエリのtype:best_fieldsで 検索対象がタイトルフィールドのクエリになっているようです。
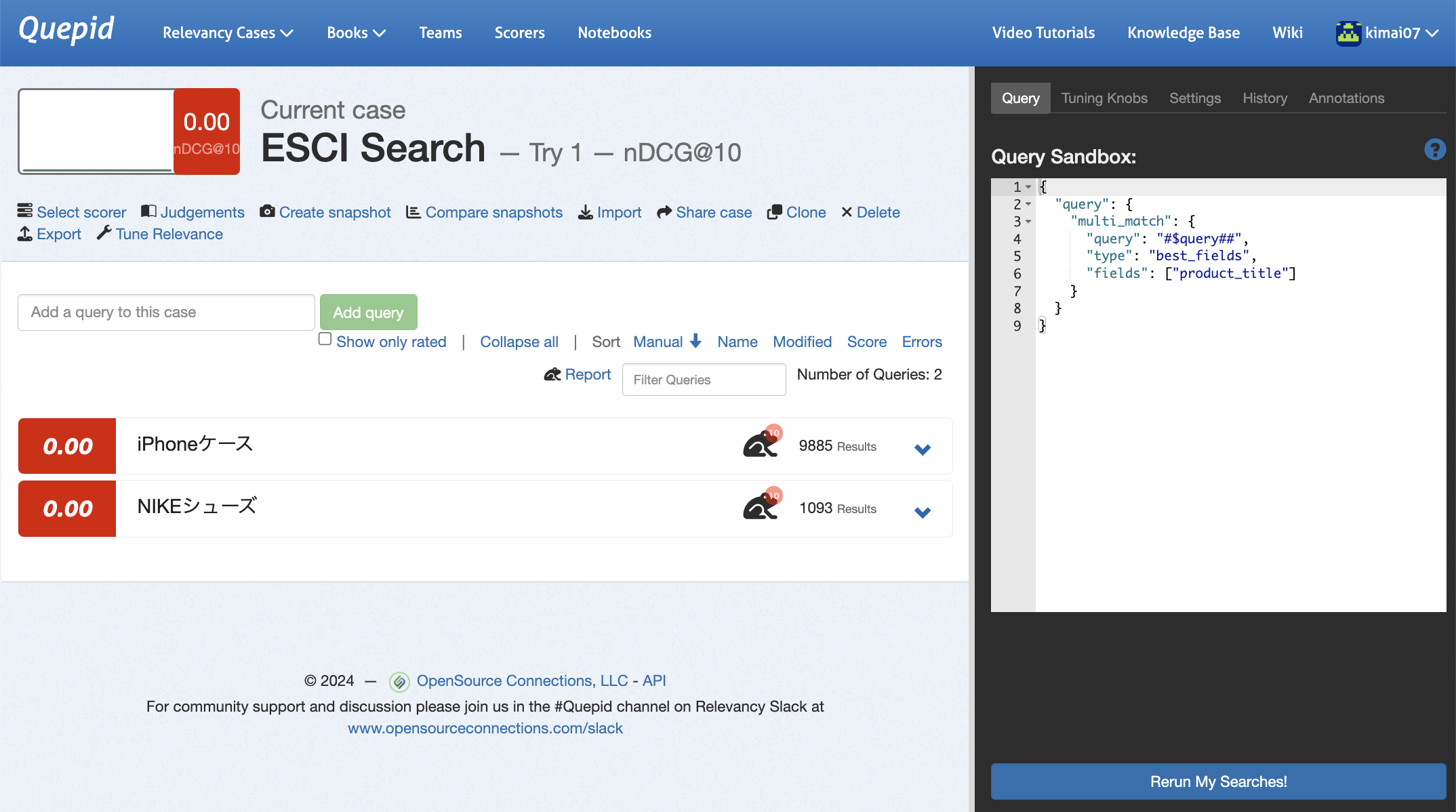
試しにdescriptionも検索対象に加えた後、Rerun My Searches! をクリックして再検索を行ってみました。検索対象のフィールドを増やしたことで、ヒット件数が増えたことを確認しました。
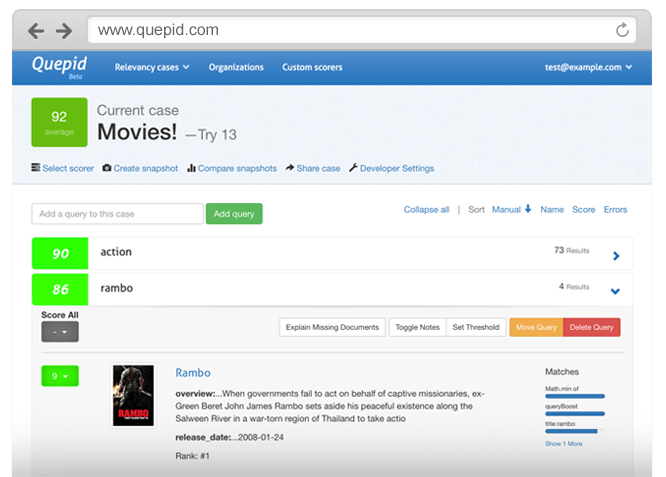
検索結果のTOP10を評価してみます。4段階で良しなに評価してみました。
すると nDCGスコア0.78 が表示されました。
人手での評価がやはりネックですが、検索結果のスコアがすぐに算出・可視化されました。
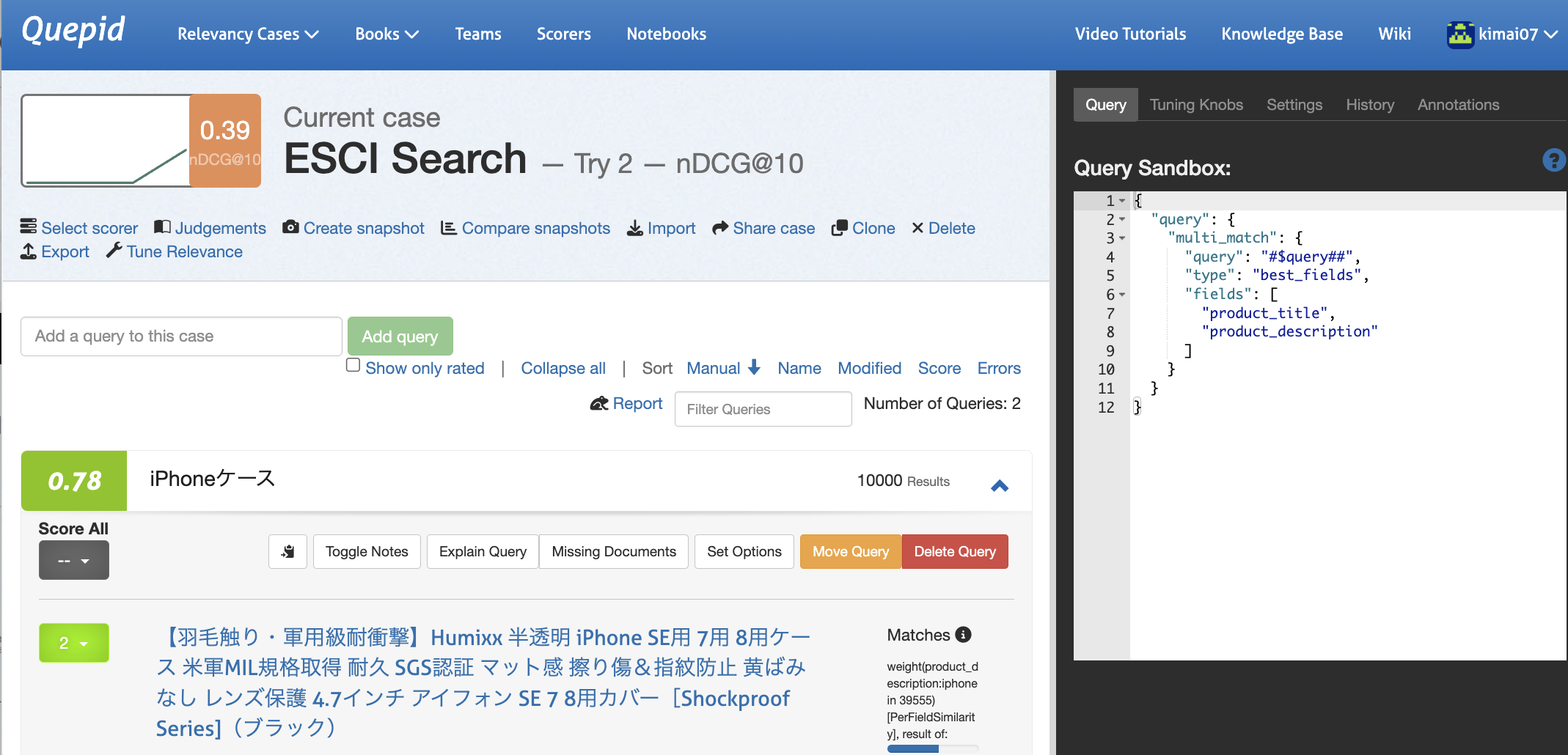
この後、試しにbest_fieldsからmost_fieldsに変更して再検索してみましたが、スコアはすぐには出ませんでした。おそらく検索結果のTOP10が変わってしまい、まだ評価されていない商品(文書)がTOP10に並んでしまったためと思われます。
そのため、お試しで改善を確認するにはなかなか難しいと感じました。もしかしたら、最初は数件のデータで試したほうが良いかもしれません。
<検索チューニングポイント>
チューニングポイントとしては以下が挙げられます。評価した商品(文書)が出てくればこのあたりの検証も行いやすそうです。
- クエリ修正
- ランキングアルゴリズム、スコアリングの調整
- パラメータチューニング(インデックス設定や検索パラメータ調整など)
まとめ
検索結果の改善を支援するツールQuepidについて調査してみました。
評価指標を選択して検索結果を人手で評価してチューニングして再評価するというサイクルを回せそうな可能性を感じましたが、使いこなすにはまだまだ知見が必要だと思いました。
検索結果の個々の商品(文書)を人手で評価する時に、実サービス同等の検索結果UIを表示したいというような要望もありそうですが、カスタマイズ出来るかは分からずとなります。
もっと容易に検索改善を試す方法があるのか、今回使っていない機能にどのようなものがあるのか等については時間がある時に調査したいと思います。