はじめに
ElasticseachのJava High Level Rest Client(HLRC)がv7.15.0でDeprecatedとなったことに伴い、今後は新Javaクライアントを利用していくことになっていきます。
Javaクライアントがどんなものなのかしっかりと調べたことがなかったので、スライドやドキュメント等を調べて現時点で分かったことについてまとめます。
※クライントに関する公式ドキュメントは以下。
- これまで利用されていたJavaクライアント:Java High Level REST Client ※以降「HLRC」と呼びます
- 今後利用されていくことになる新Javaクライアント:Java Client
調査で参照した資料
- 2022-04 DevoxxFR - The new Elasticsearch Java Client - Google スライド
- Elasticsearch Java API Client | Elastic
- Elasticsearchの新しいJavaクライアント | @johtaniの日記 3rd | @johtani's blog 3rd edition
- ElasticsearchクライアントライブラリとSpecification
今回はGoogleスライド資料と公式ドキュメントの情報をメインに記事をまとめました。
この記事で分かること
新Javaクライアントについて以下を記述していきます。
- 登場した背景
- 特徴やアーキテクチャ
- 使用方法
- HLRCからの移行方法について
これらに関して、詳細まではいかないにしても概要レベルでは知ることが出来るのではと思ってます。
新Javaクライアントが登場した背景
新Javaクライアントについて触れる前に、HLRCに以下のような課題があることが挙げられていました。
- Elasticsearchサーバーコードへの依存があること
- Elasticsearch本体で管理されており、Elasticsearch本体のクラスを利用している
- そのため、Clientで利用しているのは一部のみにも関わらず、多くのDependenciesをpullする必要がある(30MB以上のバイトコード)
- サーバーのコードリファクタリングも行いづらい状況になっている
- 手作業で実装している
- APIと一致していないことがある
- 400エンドポイントのメンテナンスワークが存在
- JSONとアプリケーションオブジェクトのマッピング機能が無い
Architecture of exsisting Java Clients
課題にも挙がっていた通りHLRCはElasticsearchサーバーコードとの依存が存在しています。
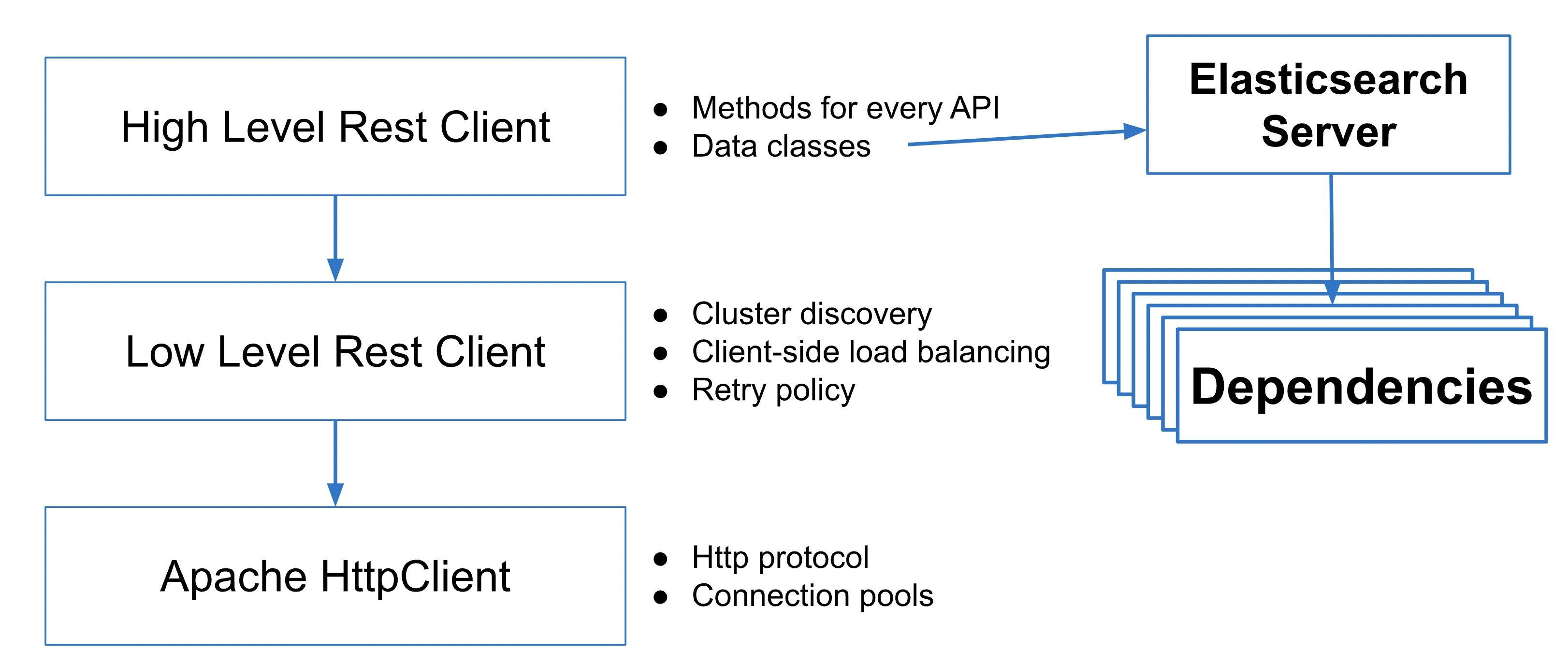
・引用元はこちら
新Javaクライアントについて
これらの課題を解決するために新Javaクライアントが登場しました。
また、もっとモダンにする良い機会ということもあり、クライアントコードの記法にはラムダ式のようなスタイルも採用されました。
以下は主な特徴となります。
- コード自動生成の利用
- API仕様に基づいて生成されるようになる
- 初回クライアントコード生成時、コードの99%が生成出来たとのこと
- もっとモダンなプローチを提供する機会
- fluent functional builder(ラムダ式っぽいスタイル)
- 階層的なDSLがElasticsearchのJSONフォーマットに近い
- JSONとアプリケーションオブジェクト間の自動マッピング
- ただし、Java 8 compatibilityは継続
- その他
- JSON文字列をそのまま使える
- JSON文字列からリクエストオブジェクトを作るためのメソッド
.withJson()が提供されている
- JSON文字列からリクエストオブジェクトを作るためのメソッド
- クライアントライブラリの併用が可能なため、順次移行することが出来る
- JSON文字列をそのまま使える
Architecture of the new Java Client
新Javaクライアントでは、Elasticsearchサーバーコードへの依存がなくなりました。
HTTPクライアントに関しては引き続きLow Level Rest Client(LLRC)を利用します。
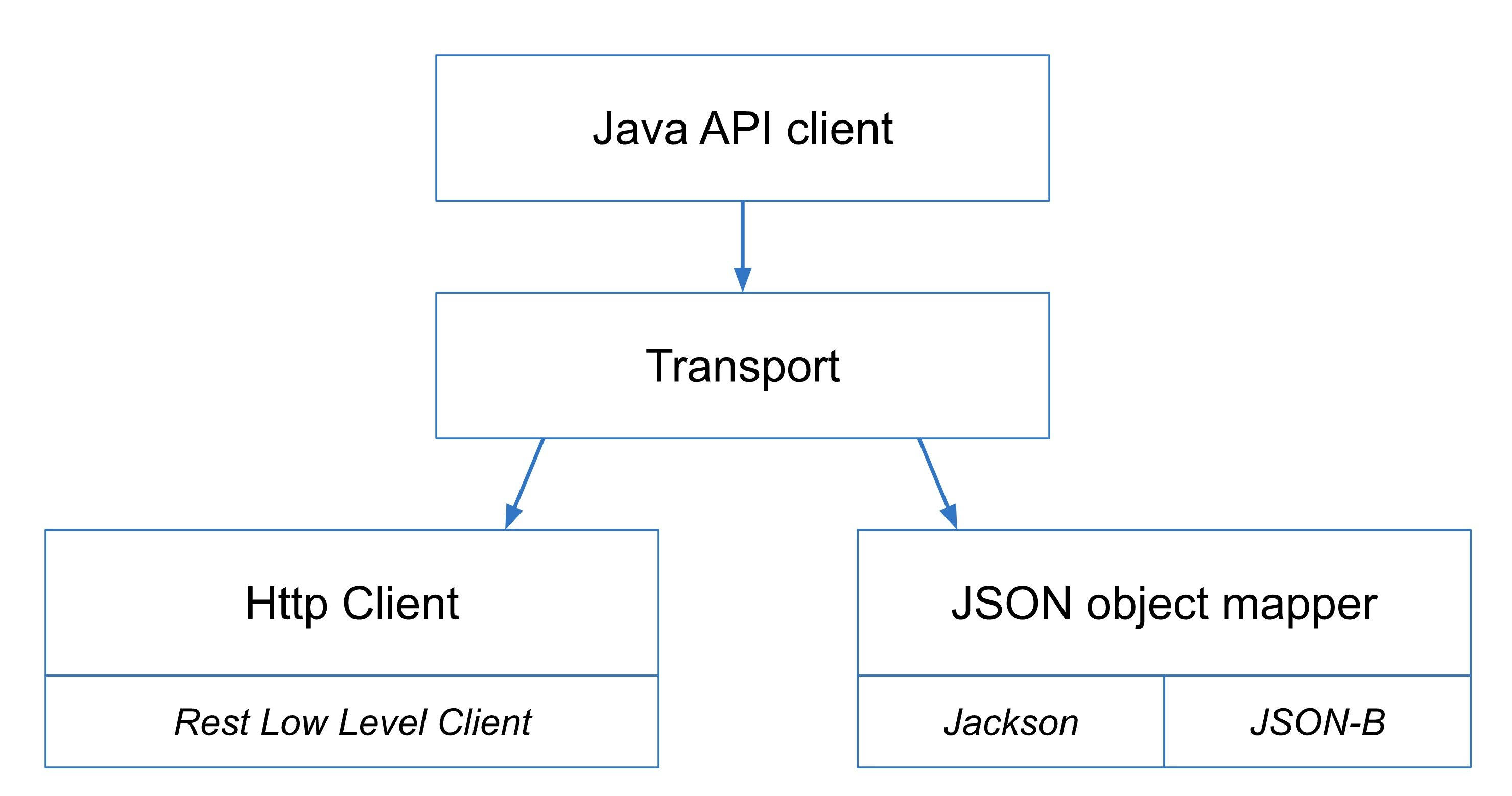
・引用元はこちら
新Javaクライアントの使用方法
新Javaクライアントを実際にどう使うのかについて、スライドや公式ドキュメント記載があったため、その内容を以下に記します。
ここでは、以下の順に記載していきます。
- クライアント生成
- ドキュメントのインデクシング(index)
- ドキュメントのインデクシング(bulk)
- 検索
- アグリゲーション
1. クライアント生成
クライアント生成の実装方法は、アーキテクチャに沿って生成していってますので、上記のアーキテクチャを頭に入れて実装するとスムーズに出来ると思います。
RestClient httpClient =
RestClient.builder(new HttpHost("localhost", 9200)).build(); // HTTP & cluster node discovery layer
JacksonJsonpMapper jsonMapper =
new JacksonJsonpMapper(); // JSON parser and object mapper
ElasticsearchTransport transport =
new RestClientTransport(httpClient, jsonMapper); // Transport: groups JSON and HTTP
ElasticsearchClient client =
new ElasticsearchClient(transport); // Elasticsearch API client
・参考:Connecting | Elasticsearch Java API Client | Elastic
2. ドキュメントのインデクシング(index)
単一ドキュメントをインデクシングする場合は、indexメソッドを用います。
以下のようなQuery DSLのリクエストがあるとします。
PUT /products/_doc/abc
{
"id": "abc",
"name": "Bag",
"price": 42.0
}
このQuery DSLをJavaコードで実装すると以下のようになります。
単一ドキュメントでのインデクシングの場合、classic builderスタイルとfunctional builderスタイルの両方がサポートされています。
(Connectingに記載があるが、ラムダ式っぽく書くbuilderスタイルは「fluent functional builder」と呼ぶよう)
classic builder スタイル (javadoc)
- これまで通りのスタイルで実装することが出来ます。
Product product = new Product("abc", "Bag", 42.0);
IndexRequest<Product> indexRequest = new IndexRequest.Builder<>()
.index("products")
.id("abc")
.document(product) // アプリケーションオブジェクトからJSONにマッピングされる
.build();
client.index(indexRequest);
functional builder スタイル (javadoc)
- ラムダ式っぽく書いた場合、このように実装することが出来ます。これにより、少しシンプルに書くことが出来るようになります。
Product product = new Product("abc", "Bag", 42.0);
client.index(builder -> builder
.index("products")
.id(product.id())
.document(product)
);
- Javadocを確認したところ、indexメソッドの引数は
Function<IndexRequest.Builder<TDocument>,ObjectBuilder<IndexRequest<TDocument>>> fnであった
3. ドキュメントのインデクシング(bulk)
単一ドキュメントではなく、複数のドキュメントをまとめて処理を行いたい場合にbulkメソッドを利用します。
以下のようにbuilderに複数のドキュメントをoperation単位でセットして、最終的にbulkメソッドに指定してリクエストします。
List<Product> ps = List.of(
new Product("abc", "Bag", 42.0),
new Product("bcd", "Bag", 52.0),
new Product("cdf", "Bag", 62.0));
BulkRequest.Builder br = new BulkRequest.Builder();
for (Product p : ps) {
br.operations(op -> op
.index(idx -> idx // operationタイプの指定(index, create, update, deleteのいずれか)
.index("products")
.id(p.name())
.document(p)));
}
BulkRequest br = br.build();
BulkResponse result = client.bulk(br);
もっと詳細が知りたい場合は、公式ドキュメント Bulk: indexing multiple documents に記載がありますので、こちらを参照ください。
4. 検索
検索する場合は、searchメソッドを用います。
以下のようなQuery DSLのリクエストがあるとします。
GET /products/_search
{
"query": {
"term": {
"name": "bag"
}
}
}
このQuery DSLをJavaコードで実装すると以下のようになります。
検索時もインデクシング時同様に、classic builderスタイルとfunctional builderスタイルの両方をサポートしています。
classic builder スタイル (javadoc)
TermQuery query = QueryBuilders.term()
.field("name")
.value("bag")
.build();
SearchRequest request = new SearchRequest.Builder()
.index("products")
.query(query)
.build();
SearchResponse<Product> response =
client.search(
request,
Product.class // JSONからアプリケーションオブジェクトにマッピングされる
);
Product product = response.hits().hits().get(0).source();
functional builder スタイル (javadoc)
SearchResponse<Product> response =
client.search(b -> b
.index("products")
.query(q -> q
.term(t -> t
.field("name")
.value("bag")
)
),
Product.class
);
Product product = response.hits().hits().get(0).source();
functional builder スタイル (splitting complex DSL)
以下のようにquery構築部分を切り出して先に処理を行い、後でsearchメソッドに指定するよう記述することも出来ます。
Query termQuery = QueryBuilders.term(t -> t
.field("name")
.value("bag")
);
SearchResponse<Product> response =
client.search(b -> b
.index("products")
.query(termQuery),
Product.class
);
Product product = response.hits().hits().get(0).source();
withJSON
新JavaクライアントではwithJSONメソッドでJSON文字列を取り込むことが出来ます。
ここでは、Queryオブジェクトを構築する例を挙げたいと思います。
String input = """
{"bool": {"should": [{ "match": { "name": "abc" } },{ "match": { "name": "bcd" } }]}}
""";
Query q = Query.of(b -> b.withJson(new StringReader(input)));
System.out.println(q);
// - Query: {"bool":{"should":[{"match":{"name":{"query":"abc"}}},{"match":{"name":{"query":"bcd"}}}]}}
BoolQuery bq = q.bool();
System.out.println(bq);
// - BoolQuery: {"should":[{"match":{"name":{"query":"abc"}}},{"match":{"name":{"query":"bcd"}}}]}
SearchRequest request = SearchRequest.of(r -> r
.index("products")
.query(q));
response = client.search(request, Product.class);
検索の項目で記載しましたが、インデクシング時など他の機能でも利用可能です。
5. アグリゲーション
アグリゲーションの場合もsearchメソッドを用います。加えてbuilderでaggregationsを用います。
以下のようなQuery DSLのリクエストがあるとします。
GET /products/_search?typed_keys=true
{
"size": 0,
"aggregations": {
"price-histo": {
"histogram": {
"field": "price",
"interval": 50
}
}
}
}
このQuery DSLをJavaコードで実装すると以下のようになります。
アグリゲーションの値設定・取得はコードが膨らむため、最初は難しく感じるところもあるかもしれません。
SearchResponse<Void> response = client
.search(b -> b
.index("products")
.size(0)
.aggregations("price-histo", a -> a
.histogram(h -> h
.field("price") // histogram集計対象を指定
.interval(50)
)
),
Void.class // Void.classを指定すると、レスポンスにドキュメントが含まれない状態となる
);
long firstBucketCount = response.aggregations()
.get("price-histo") // アグリゲーション名の取得
.histogram() // データ範囲内の全てのバケットを取得
.buckets().array() // 配列形式でエンコードされたバケットの取得
.get(0).docCount(); // 対象バケットのドキュメント数の取得
API仕様とコードジェネレータについて
こちらは新Javaクライアントを利用するのであれば知っておくとベターな内容となります。
最初の方でコード自動生成というキーワードが出てきたかと思いますが、新JavaクライアントのコードはAPI仕様をもとにコード生成しています。
API仕様はelasticsearch-specificationという専用リポジトリで仕様管理されています。
コード生成の流れは以下となります。
API仕様(TypeScript) -> モデル(JSON) -> Javaクライアント(Java)
elasticsearch-specificationリポジトリに以下のようなコード生成の全体図があり、こちらを見ると流れがよく分かるかと思います。
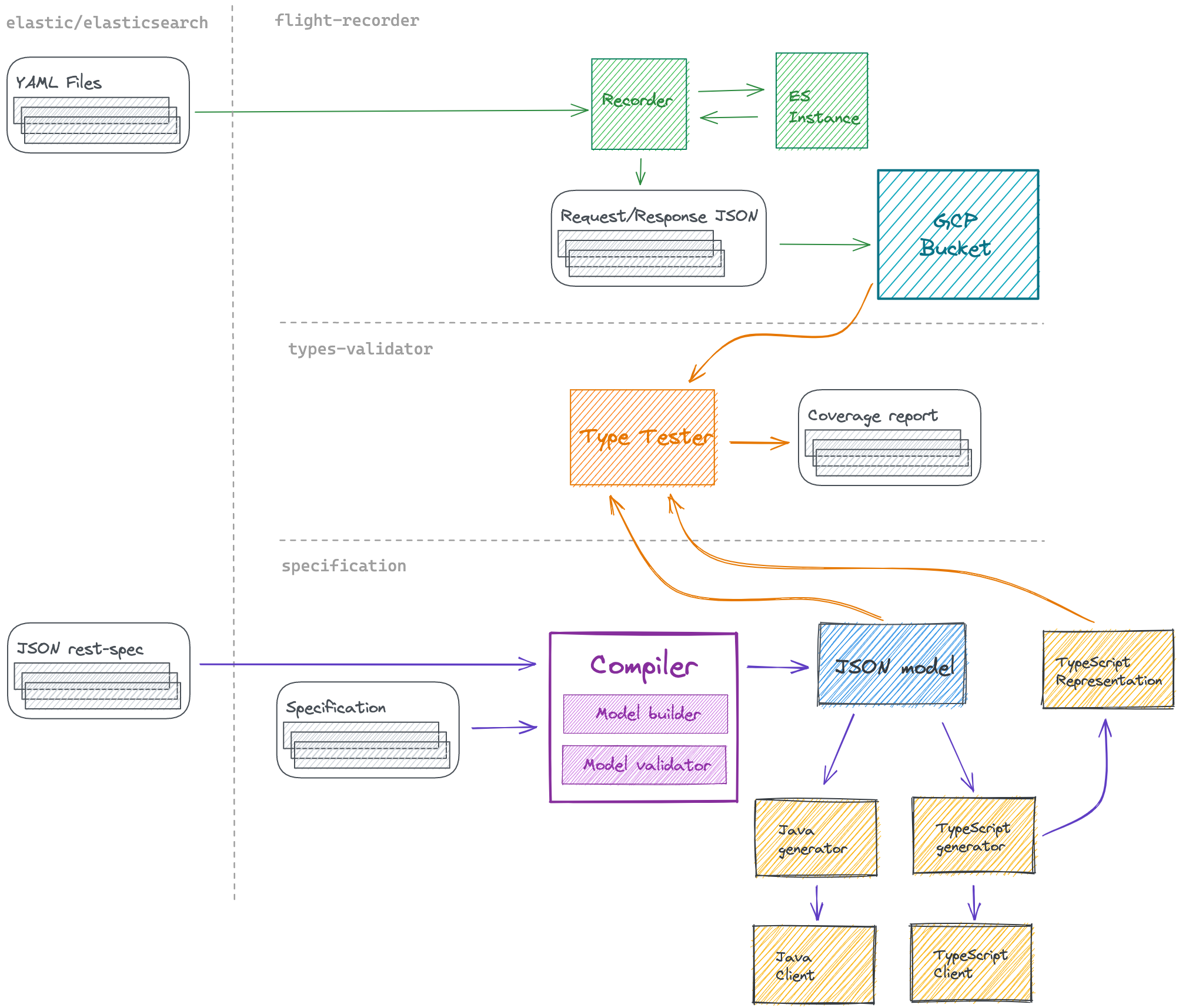
・引用元はこちら
そして、このあたりについては2022/12/14に開催された「第51回Elasticsearch勉強会」で、大谷さんよりLT発表があり、こちらの資料に詳細が記載されていますのでご参照ください。
HLRCからのマイグレーションについて
HLRCからのマイグレーション方法についてですが、公式ドキュメント Migrating from the High Level Rest Client に記載がありました。
このあたりのポイントとしては以下と思っています。
- HLRCと新Javaクライアントの併用が可能
- HLRC7系からElasticsearch8系にリクエストすることが可能
- ただしcompatibility modeにする必要あり。
- HLRCと新Javaクライアントで同じHTTPクライアントを使用することが出来る。
また、おすすめの移行方法として以下が挙げられていました。
- アプリケーションの新機能に対して新Javaクライアントを利用する
- 新Javaクライアントを検索処理など導入しやすい部分に対して書き直して利用する など
さいごに
今回は、Javaクライアントについてしっかりと調査をしましたが、アーキテクチャ図などこれまで調べたことがなかった情報を得ることが出来ました。
新Javaクライアントの書き方についてはまだ慣れていないところもありますが書きやすい印象も受けました。
もしHLRCから新Javaクライアントへ移行することを検討している場合、
移行せずともcompatibility modeを利用することでHLRCからElasticsearch8系にリクエストすることが出来ますので、急ぎで行う必要はないと思っています。
ただし、Elasticsearch8系以降で登場した新機能を利用したくなった場合に利用できない可能性が高いため、出来るタイミングで移行を実施したほうが良いのかなと思いました。
そして、今回の新Javaクライアントの使用方法の説明は「リクエスト構築から検索するまで」だったので、次はレスポンスをどう扱うかについて書ければと思っています。