はじめに: アーキテクチャに関する一般的な原則について
本題に入る前に、「関心の分離」についておさらい。
認識すべきこと:すべてのコードを 1 つの Activity または Fragment に記述するのはよろしくない。
すべてのコードを1つのActivityに記述したときに起こりうるデメリット
①開発コスト高
コード量が肥大化し、他人(未来の自分を含む)が理解しづらくなり、修正も困難に。。。
②メモリ不足
ActivityやFragmentは画面回転したりアプリをバックグラウンドに移したりするだけでLifecycleが終了するため、表示するたびに全ての処理を実行しなければいけなくなる。
高負荷な処理を連続で行うとメモリ不足になってしまうことも。。。
解決策: 関心の分離をする
関心の分離とは主にデータの管理(データの取得・保存)に関して、各クラスの関心を分離させるべきと言う考え方。
要するに、各クラスの役割を定め、自らの役割を全うさせることで効率的で、洗練されたアプリを作成しようということ。
本題:今回はViewModelを補佐するRepositoryの役割について考えてみる
Repositoryの立ち位置を知る(推奨アーキテクチャーより)

画像からRepositoryについてわかること
- 複数のクラスに依存するクラスはリポジトリのみ
- Repositoryは永続データモデルとリモートのデータソースに依存している
- Repositoryに依存されているのはViewModel
Repositoryの主な役割
①データの取得先・取得方法を隠蔽する役割。
Repository内でデータの取得先・取得方法を定義することで、ViewModelからRepositoryを呼び出すときに処理の過程をブラックボックス化する。
②アプリ内で扱いやすいようにデータを整えて提供する役割
データ加工をRepository内で済ませることで、ViewModelからはRepositoryのメソッドを呼び出すだけで済む。
※ データ加工は場合によってViewModelで加工したほうが都合がいいときもある。
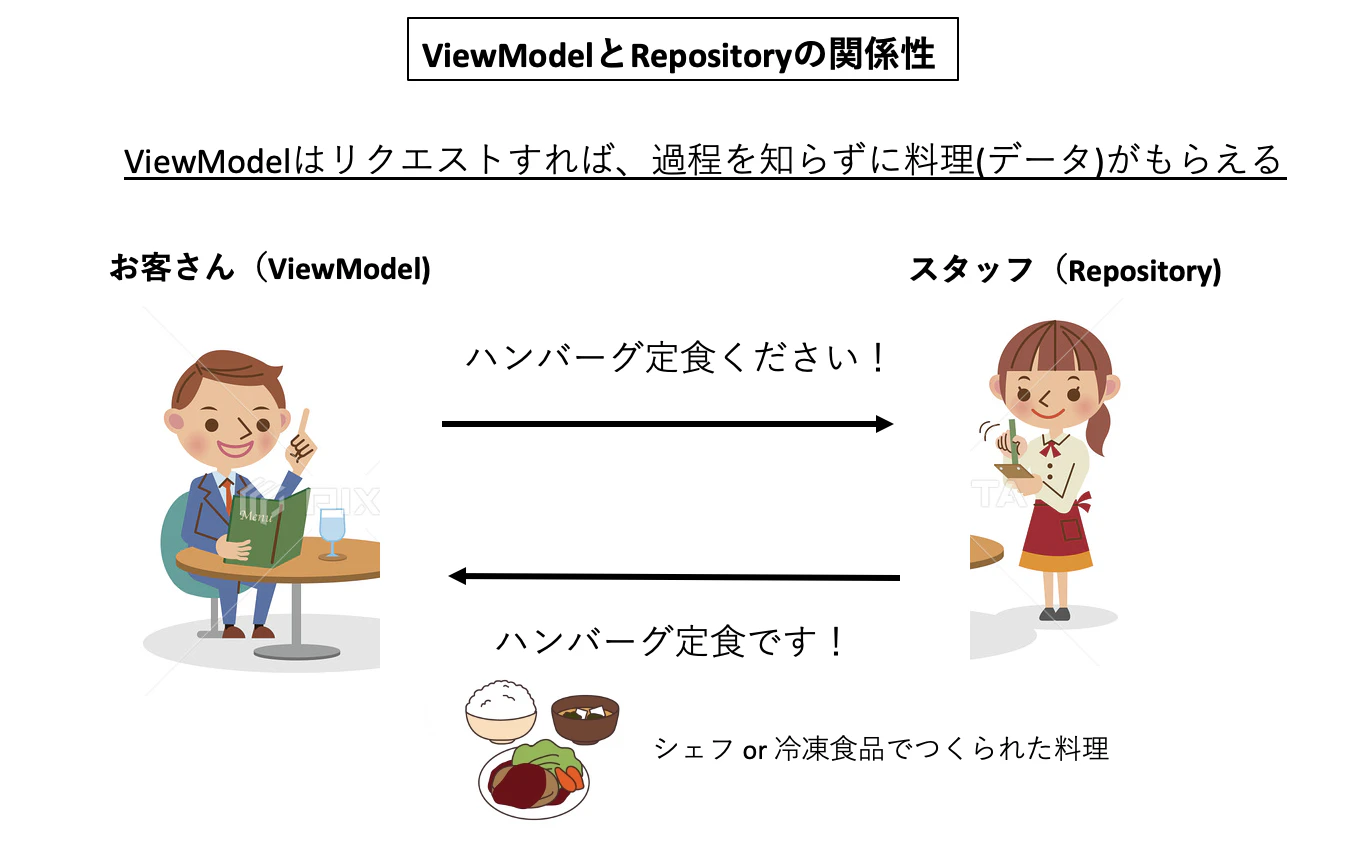
イラストでイメージ解説(レストランのスタッフ)

Repositoryをはさむメリット
メリット① ViewModelで考えるべきことを減らせる
ViewModelは過程を知らずにただ結果(データ)がもらえるようになる = コードをシンプルに保ちやすくなる!
-
ViewModelで考えなくてすむこと
- どこから取得すればいいか
- どうやって取得すればいいか
- キャッシュにデータが残っているか
- データを加工する必要があるのか
-
ViewModelで考えること
- データの取得に時間がかかるかもしれないし、かからないかもしれない
- データの取得は失敗するかもしれない
イラストでイメージ解説(レストランのお客さん)

メリット② データ取得に関する変更がしやすくなる
データ取得に関して変更が必要なコードがRepository配下に限定されるため、ViewModelを変更する必要がなくなる。
データの取得先が変わるパターン例
- 開発当初はAndroid向けにサクッとSQLiteだけでアプリを作ったがアプリがヒットして、iOSやWebにも対応することになった。
→ Firestore等で一部のデータをリアルタイム同期することに決まった。 - データの保存先をローカルのファイルでやっていたが要件が増えたことにより容量オーバーの危機が訪れた。
→ クラウドのRDBMSへ移行することに決まった。
メリット③ テストが書きやすくなる。
Repository配下の部分をモックデータに差し替えやすくなり、テストが書きやすくなる!
[Repositoryを挟まない場合のデメリット]
- データを取得するまでの過程が複雑になればなるほどテストが難しくなる。
- モック化できないため、参照するためにアプリの実装コードを変更しないとテストできない場合がある。
例:クラスにopenをつけたり、メソッドのprivateを外したりする必要が出てくる
最後に
Architectureの話って調べれば調べるほど奥が深いな〜と感じます。
ご指摘やご意見あればぜひ教えていただけると嬉しいです!