1. はじめに
はじめまして、キクタンと申します。今回「ユーザーネーム」と「学びたいアルゴリズム」からAtCoderの問題をレコメンドしてくれるwebアプリを制作しました。
AtCoderユーザーやアルゴリズムを勉強中の人、Webアプリ開発に興味がある人などぜひ見ていって下さい。なお、過去問のネタバレを含みますので一応注意です。
2. アプリ概要
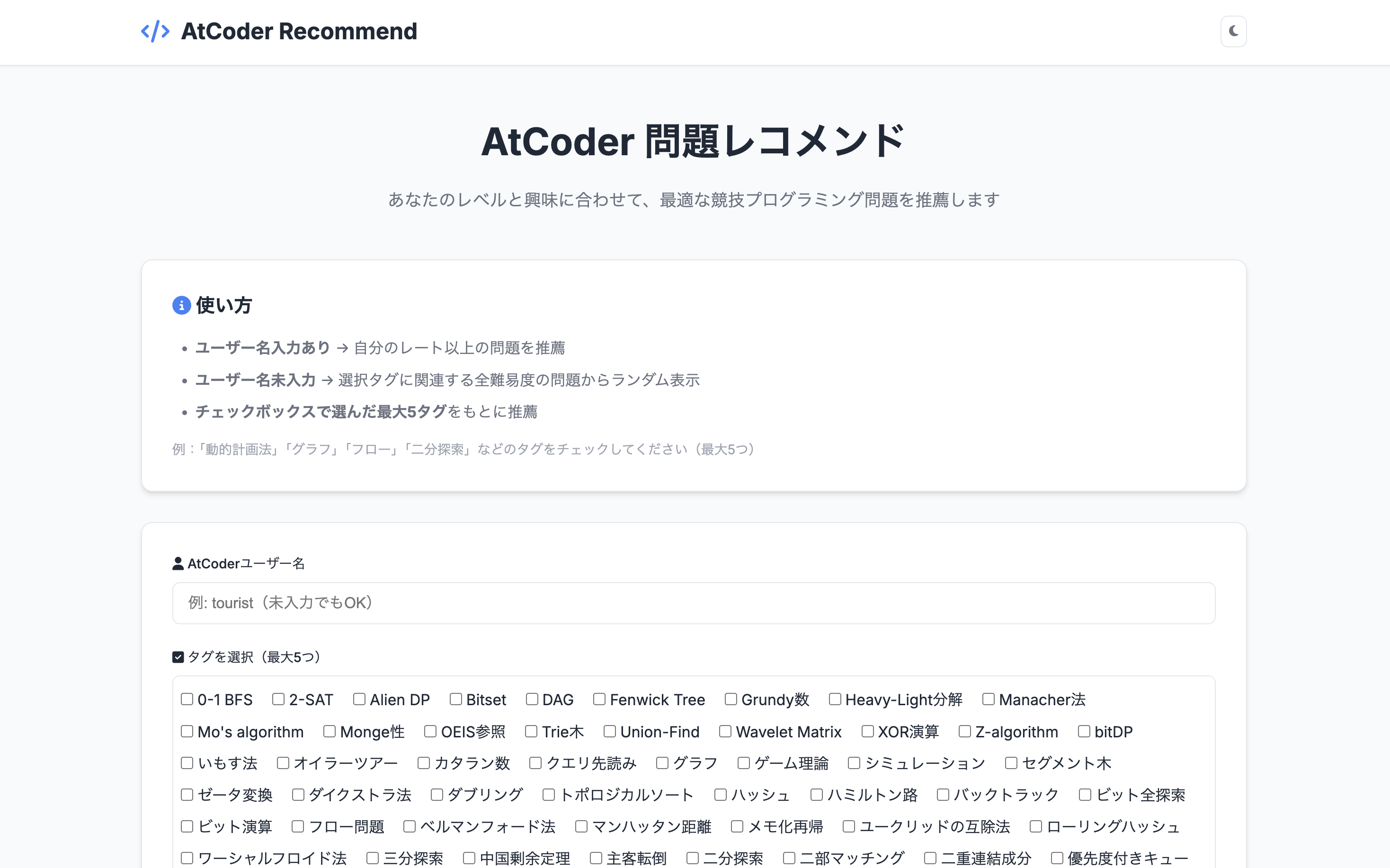
URL: https://problem-recommend-150123537389.asia-northeast1.run.app/
アプリでできること・使い方
- 学びたいアルゴリズムを選択すると、関連した問題がレコメンドされます
- 問題範囲
- ABC175~420、difficulty400以上の問題を網羅
- (difficultyはAtcoder Problemsのものを参照)
- (この範囲設定の理由は後述)
- チェックボックスからアルゴリズムを5つまで選択
- 「問題を探す」ボタンを押すとそのタグの付いた問題が、最大5件出力される
- ユーザーネームを入力すると自身のレートより高い問題のみ
- 未入力の場合は全difficultyから選択
(以下問題表示イメージ)
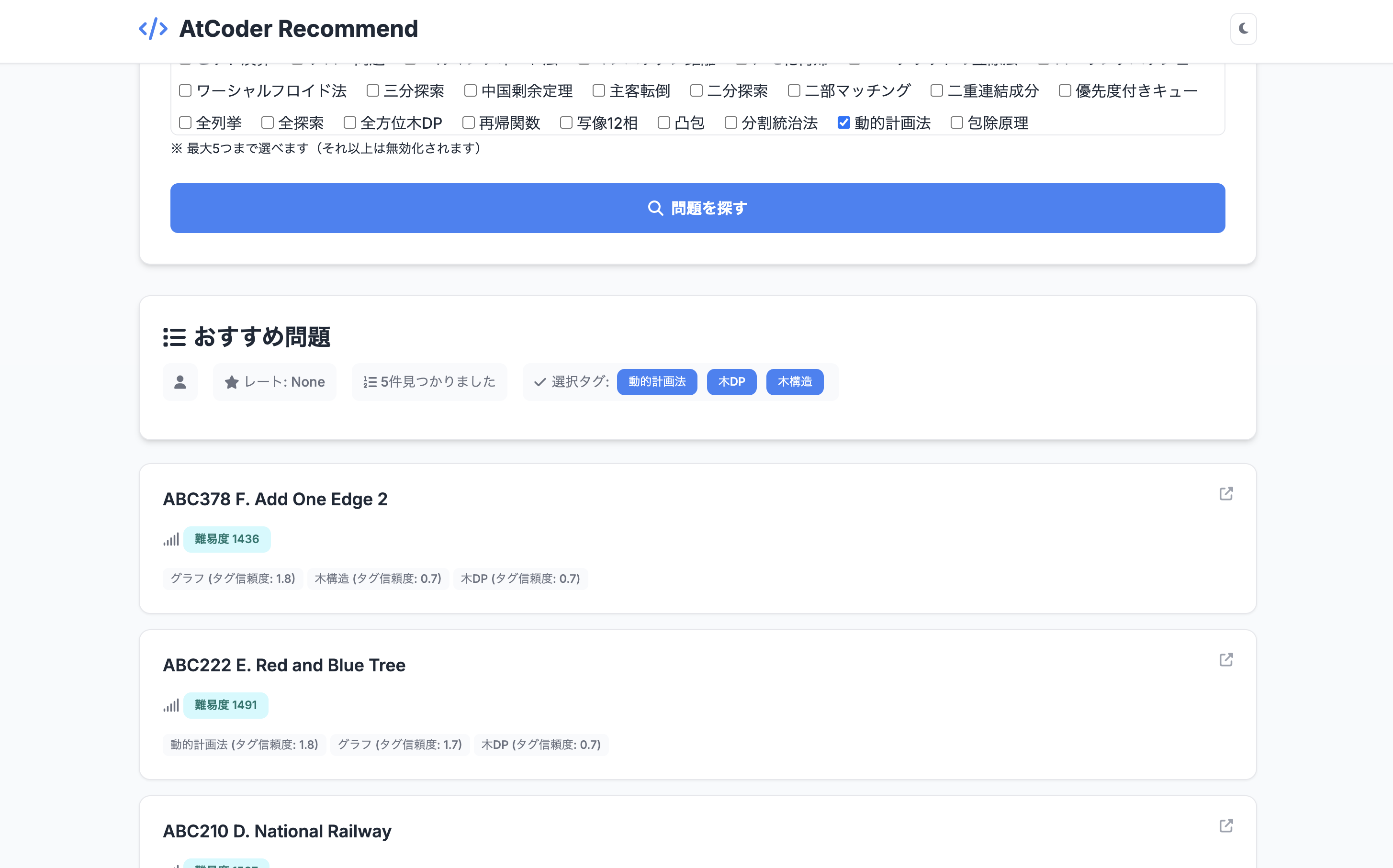
3. 背景
今までにない問題レコメンドアプリ
一連の取り組みの最初の思いつきとしては、「競プロの問題レコメンドアプリを作りたい」でした。競プロの教材はかなり充実していて、「典型90」や「EDPC」をはじめとした公式コンテスト、「Atcoder Problems」や「AtCoder Novisteps」のような有志サイト、さらに問題を集めた個人ブログなど、単純に問題を解いてレートを伸ばすのには十分な情報が集まっていると思います。
一方で「特定のアルゴリズムの問題を解きたい」となった時に、その選択肢はかなり減ると思います。「動的計画法」や「全探索」のような有名アルゴリズムについては問題がまとまっていることも多いですが、例えば「Z-algorithm」「フロー」などの高度典型は問題がまとまってないことも多いです。(脱線しますが、けんちょんさんのブログはすごいと思います)
さらに言うと過去問全体を包括的にまとめているものは、調べたところ1件を除いて存在しないと思います。そこで今回、
- アルゴリズムから問題を検索(提案)する
- 過去問全体を参照する
これらを実現することを目標に、問題レコメンドアプリの制作を考えました。
4. レコメンド機能
使っているもの
詳細は後述しますが、以下の2種類のデータを用意しています。
-
タグ定義ファイル(例: tag_definition.json)
-
問題ごとのタグ付けデータ(例: problems_data.json)
タグ定義ファイル(抜粋)が以下のような形式です。
{
"tags": [
{
"id": "DP",
"name": "動的計画法",
"aliases": ["DP", "動的計画", "Dynamic Programming", "メモ化", "dp"],
"description": "大きな問題を部分問題に分割し、結果をテーブルに記録・再利用する最適化手法。「i番目までで状態jになる最適値/場合の数」を漸化式で求めるのが典型で、ナップサック問題などが代表例。計算量は(状態数)×(遷移)で決まり、bitDPや区間DPといった頻出パターンも存在する。"
},
{
"id": "KDP",
"name": "桁DP",
"aliases": ["桁DP", "桁dp", "digit DP", "digit dp"],
"description": "数値の各桁を状態として持つ動的計画法の特殊形。N桁以下で特定条件を満たす数の個数を数える問題に使用される。桁数×桁×フラグ状態をDPテーブルとし、上からi桁目まで確定した状態を遷移。計算量はO(桁数×10×状態数)で、ABC形式では頻出パターン。"
},
...
]
}
問題へのタグ付けデータ(抜粋)が以下のような形式です。問題一つについて3つのタグを持っています。
"abc175_c": {
"title": "Walking Takahashi",
"problem_url": "https://atcoder.jp/contests/abc175/tasks/abc175_c",
"editorial_url": "https://atcoder.jp/contests/abc175/editorial/52",
"tags": [
"動的計画法",
"中国剰余定理",
"全探索"
],
"tag_ids": [
"DP",
"CRT",
"BRT"
],
"confidence_scores": [
0.765,
0.7200000000000001,
0.6299999999999999
],
...
これらのデータを使って問題レコメンドを行います。
大まかなレコメンドのアルゴリズムと流れ
-
チェックボックスで5件までタグ(学びたいアルゴリズム)を選択
- 選択した順にそれぞれのタグに対して、[1.0, 0.8, 0.6, 0.4, 0.2]の重みをつけておく
- (選択されなかったタグの重みは0.0)
-
全ての問題の関連度(重み)を計算
-
問題の関連度が高いもの上位20個を選出
- ユーザーネーム入力時は、自身のレート未満の問題を除外
-
20個の中からランダムに5個を、difficultyの昇順に表示
5. デプロイ方法
GoogleのCloud Runを使ってデプロイしています。基本無料で運用したかったので、最小インスタンス数0、メモリ上限は512MiBに設定しています。RenderなどのPaaSも使っていましたが、Cloud Runは課金によるメモリ上限の設定などがやりやすく、拡張性が高いと思います。
最初はdockerイメージをアップロードしていましたが、githubのリポジトリをそのまま接続すれば自動でイメージを作ってデプロイできると知ったので、そうしています。便利。
6. 改善点
(現状はできていないことなので結論読む必要はないです)
本来やりたかったこと
今回はチェックボックスでタグを選択する方式にしましたが、本当は
-
ユーザーがアルゴリズム名を入力
-
入力文と類似度の高いタグを自動選出
-
選ばれたタグから問題をレコメンド
という流れにしたかったです。(下図:イメージ)
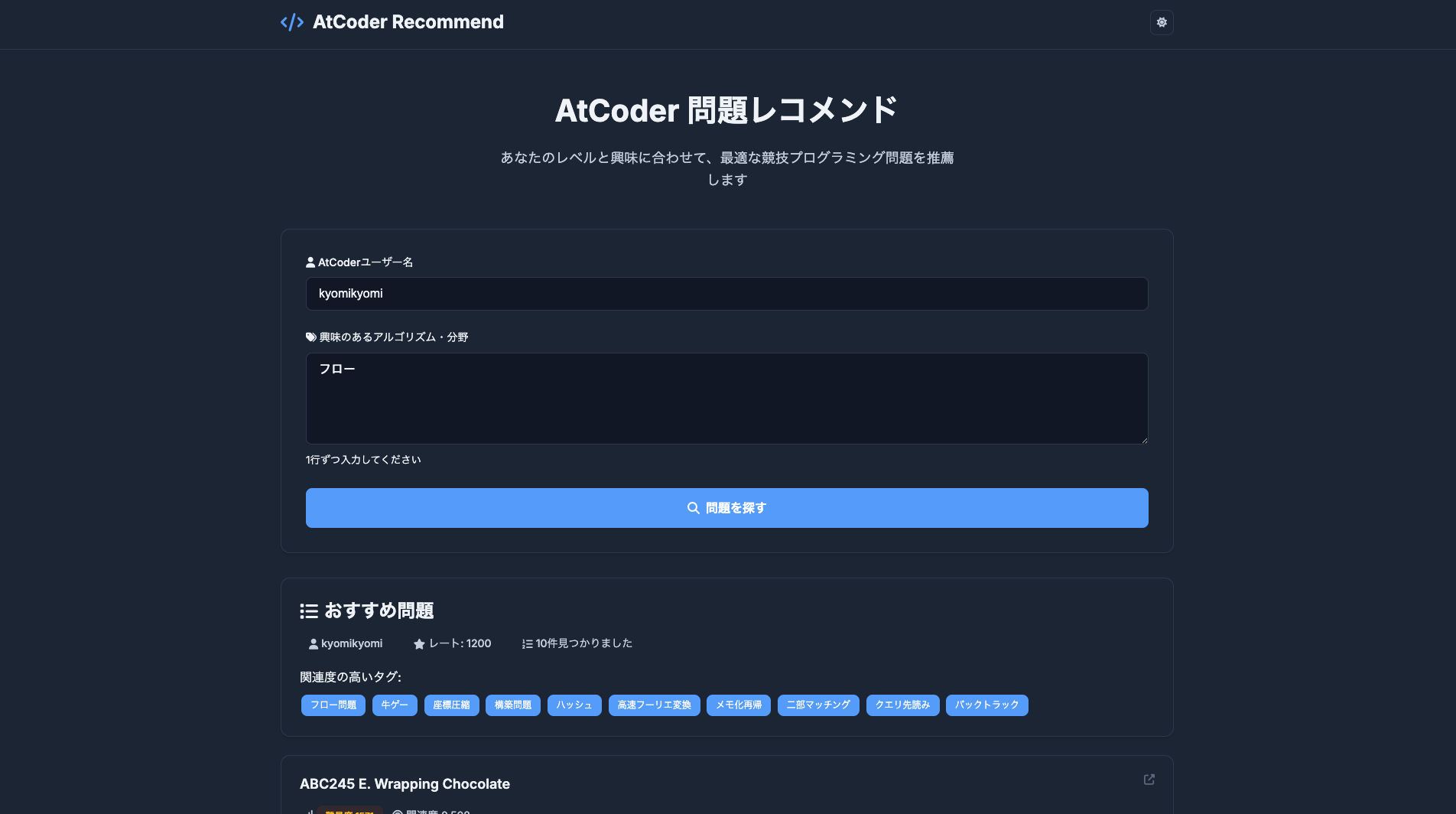
これが実現できると、例えば「動的計画法」と入力すると、関連度の高いタグに「動的計画法」「木DP」「確率・期待値DP」などが自動的に選出されます。また表記揺れに対応できたり、今回チェックボックスに存在しないタグを入力しても似たアルゴリズムを選出できたりなどのメリットがあります。
単語の分散表現の難しさ、精度とメモリのトレードオフ
これを実現するには、単語の分散表現ができればいいです。単語の分散表現とは、単語を例えば300次元のベクトルに変換し、その意味を機械的に扱えるようにしたものです。Word2Vecとか聞いたことあると思います。技術的に不可能ということでは全くなく、例えばSentenceTransformerというライブラリを使うことでタグと入力を埋め込み(ベクトル化)、コサイン類似度を計算して類似度の高いタグを選出できます。実際ローカルだとこの方法で何の問題もなく動きます。
ではなぜこれを実装してないかというと、今回無料でアプリを動かしたいため、でかいライブラリが使えないからです。CloudRunの課金体系は、月ごとのリソース消費量で決まります。まず無料枠が
- CPU - 毎月最初の 180,000 vCPU 秒は無料
- RAM - 毎月最初の 360,000 GiB 秒は無料
- リクエスト - 200 万リクエスト(1 か月あたり)が無料
とあり、これらを使い終わると使用量に応じてかかる金額が増加します(一応クレジットを先払いしてその分から引かれるので、どれだけアクセスが増えても無料に変わりありません)。そのため先述したようにメモリ上限を512MiBに設定しています。
一方でSentenceTransformerはtorchなどに依存しているため、どれだけ小さいモデルでも1.2GBくらいはかかってしまいます。つまりモデルをメモリに乗せた瞬間アウトなわけです。


(↑ 人生で初めて他人に自作アプリを見せた時の反応がこれ)
ローカルとクラウドの環境の違いを実感しました。
他にも分散表現方法はもちろんあります。例えばFastTextという方法があり、これも学習済みモデルをダウンロードして用いるのですが、語彙を制限してメモリを削減できるのが強みです。例えば日本語の学習済みモデルをこのサイトなどからダウンロードすると、そのままだと8GBくらいですが、語彙を30万くらいに絞ると100MBくらいまで減ります。
これでアプリは動くようになるのですが、やはり精度が低いです。競プロやアルゴリズムの語彙は多少特殊だったり、カタカナや英語、数字が入り混じっていることが原因にあると思います。例えば「二分探索」を入力すると、「二部マッチング」「2-SAT」などが選出されます。「二」に反応しすぎていて、単語の意味を正確に捉えられていないとわかります。他にもあらゆる入力に対し「中国剰余定理」タグが反応するようになるなど不具合が多かったです。
他にも編集距離を考えるとか、タグのエイリアスを頑張って準備するとか考えましたが、競プロの語彙的に難しく、何より1つの入力から関連した複数のタグを自動的に選出するのは難しいと思い、そもそもテキスト入力からではなくユーザーにタグを選択させる方式をとりました。
ほぼフロントだけで動作するので、結果として非常に軽量かつ高速になりましたが、ユーザー的にはタグを見つけにくかったり、複数回クリックする煩わしさが生まれてしまったりという使いにくさが出てしまったと思います。難しいですね。
7. おわりに
学びたいアルゴリズムからAtcoderの過去問をレコメンドするアプリを制作しました。現状学びたいアルゴリズムから、過去問を網羅的に見て問題を提案するアプリやサービスは少ないと思い、今回の取り組みに挑戦しました。結果として不満は残りつつも、一定の価値は示せたと思います。もっといいものを作りうることも確かだと思うので、興味ある人はぜひ挑戦してみて欲しいです。
実を言うと、このアプリ自体はおまけみたいなもので、本質は「タグ付けデータの作成」にあります。一度に全てを説明すると記事が長くなりすぎるので、レコメンドアプリ部分でこの記事を区切り、タグデータ生成に関しては次の記事で説明したいと思います。「後述します」と言っていた部分も次の記事で説明します。
では次の記事の、「AIと自然言語処理を使ってAtcoderの問題のタグ付けをしました」でお会いしましょう。ここまで読んでいただきありがとうございました。