本記事の内容
座標圧縮を題材としたABC213 C問題を解説とは違うアプローチで解いたので共有します。
本記事で解説する問題
問題文

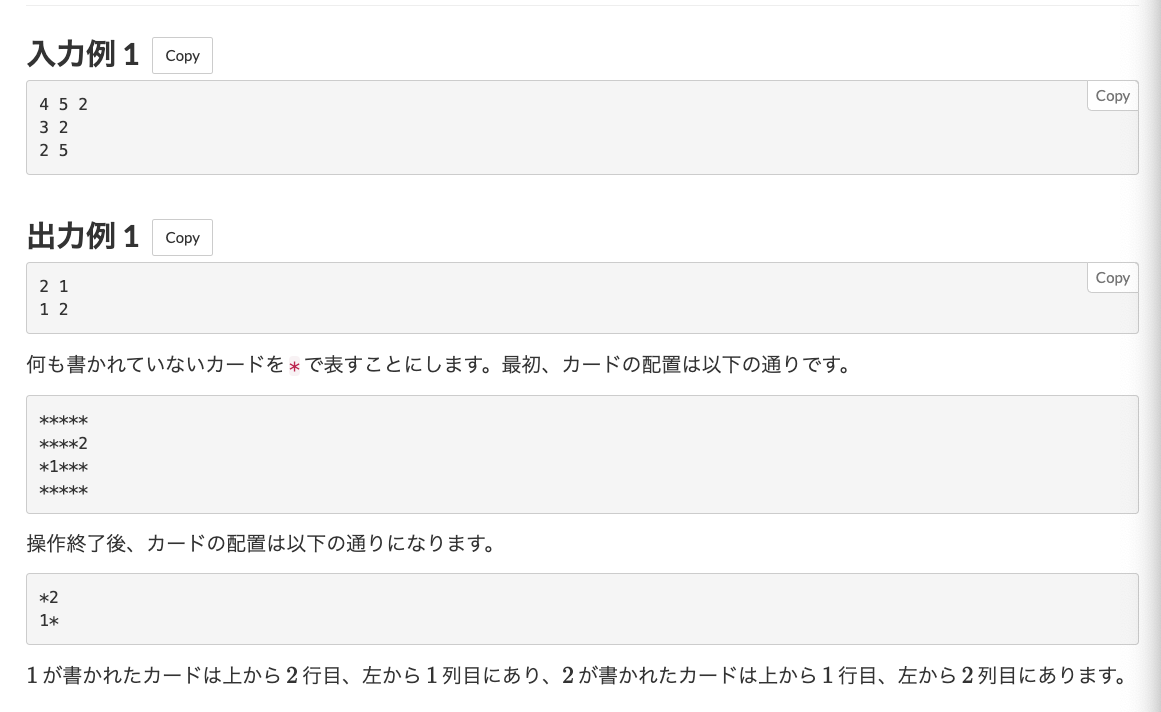
この問題では、サンプルの出力例にある*の行と列を削除して新たな行列を取得する問題です。こちらは座標圧縮という処理と言うみたいです。
筆者の解法
from bisect import bisect_left
h, w, n = map(int, input().split())
ab_n = [list(map(int, input().split())) for _ in range(n)]
rows = [ab_n[i][0] for i in range(n)]
cols = [ab_n[i][1] for i in range(n)]
# その数自身に重複があっても問題ないが、それ以前に重複があるとズレる。 setを用いて重複を削除
r_sort = sorted(set(rows))
c_sort = sorted(set(cols))
for i in range(n):
r_pos = bisect_left(r_sort, ab_n[i][0]) + 1 # 左側のインデックスを返す
c_pos = bisect_left(c_sort, ab_n[i][1]) + 1
print(r_pos, c_pos)
行と列の配列をそれぞれもち、それらを二分探索でインデックスを取得する方法で解きました。この際にsetを使用しないと、前の要素の重複により、ズレてしまうため集合に変換することが重要になります(これを忘れてWAしました。)
pythonのindexは0オリジンなので1を加えれば圧縮した座標を取得することが出来ます。
計算量としては、ソート時にO(NlogN)、座標取得時にO(NlogN)かかっています。全体の計算量はO(NlogN)なので十分早く値を取得することが出来ます。
さいごに
コードの量が増えそうな問題でもシンプルに書けてしまうのがAtCoderあるあるですよね。
解いているときも冷静になってシンプルに書けるようになりたいです。