Splunkといえば、ログをはじめとする各種データをインデックスして検索・分析・可視化するソフトウェアとして有名ですね。
「ログみたいなテキストデータしか扱えないんでしょ?」という声もチラホラ聞こえてきそうですが、いやいやそうではありません。
MySQLのようなRDBMSをデータソースとしてSplunkで分析・可視化することもできるんです。
その方法をまとめてみました。
Splunk DB Connect
DBに入っているデータをSplunkで使うためには Splunk DB Connect というAppを使います。
サポートされているDBは以下
※ DB Connectバージョン3.0.2のものです。最新情報はこちら参照。
- AWS RDS Aurora
- AWS RedShift
- IBM DB2 for Linux
- Informix
- MemSQL
- Microsoft SQL Server
- MySQL
- Oracle Database
- PostgreSQL
- SAP SQL Anywhere (aka Sybase SA)
- Spark SQL
- Sybase ASE
- Sybase IQ
- Teradata
前提条件
JDKが必要です。
Splunkが入っているサーバー・端末にJDKをインストールしましょう。
その他の前提条件はこちら参照
インストール
まずはお手元のSplunkにDB ConnectというAppをインストールします。
- Splunkにログインして [Appの管理] 画面に進む
- [ファイルからAppをインストール] からダウンロードしたファイルをアップロードするか、もしくは、 [他のAppを参照] から
DB Connectを検索してSplunkに直接インストール

- Splunkを再起動
セットアップ
DB Connectの仕組みは下記概念図と考えるとわかりやすいと思います。

- 緑色: Splunkそのもの
- 黄色: DB Connectの機能・仕組み
- 青色: MySQL等RDBMS
今回は図の黄色部分の設定方法を主に解説します。
環境設定
- JAVA_HOMEを設定(DB Connect App > [設定] > [Settings] > [General])
 Windows: `C:\Program Files\Java\jdk1.8.0_121`
OSX: `/Library/Java/JavaVirtualMachines/jdk1.8.0_101.jdk/Contents/Home/jre`
Linux: `/opt/jdk1.8.0_121/jre/`
Windows: `C:\Program Files\Java\jdk1.8.0_121`
OSX: `/Library/Java/JavaVirtualMachines/jdk1.8.0_101.jdk/Contents/Home/jre`
Linux: `/opt/jdk1.8.0_121/jre/`
-
JDBCドライバ配置
MySQL Download Connector/Jをダウンロード、解凍してmysql-connector-java-version-bin.jarファイルを$SPLUNK_HOME/etc/apps/splunk_app_db_connect/driversにコピー
※ $SPLUNK_HOMEはSplunkが使う環境変数です。Linuxの場合、/opt/splunkと読み替えてください。 -
JDBCドライバ読み込み
Splunkで、[設定] > [Settings] > [Drivers] に進んで、右側の[再読込]ボタンをクリック
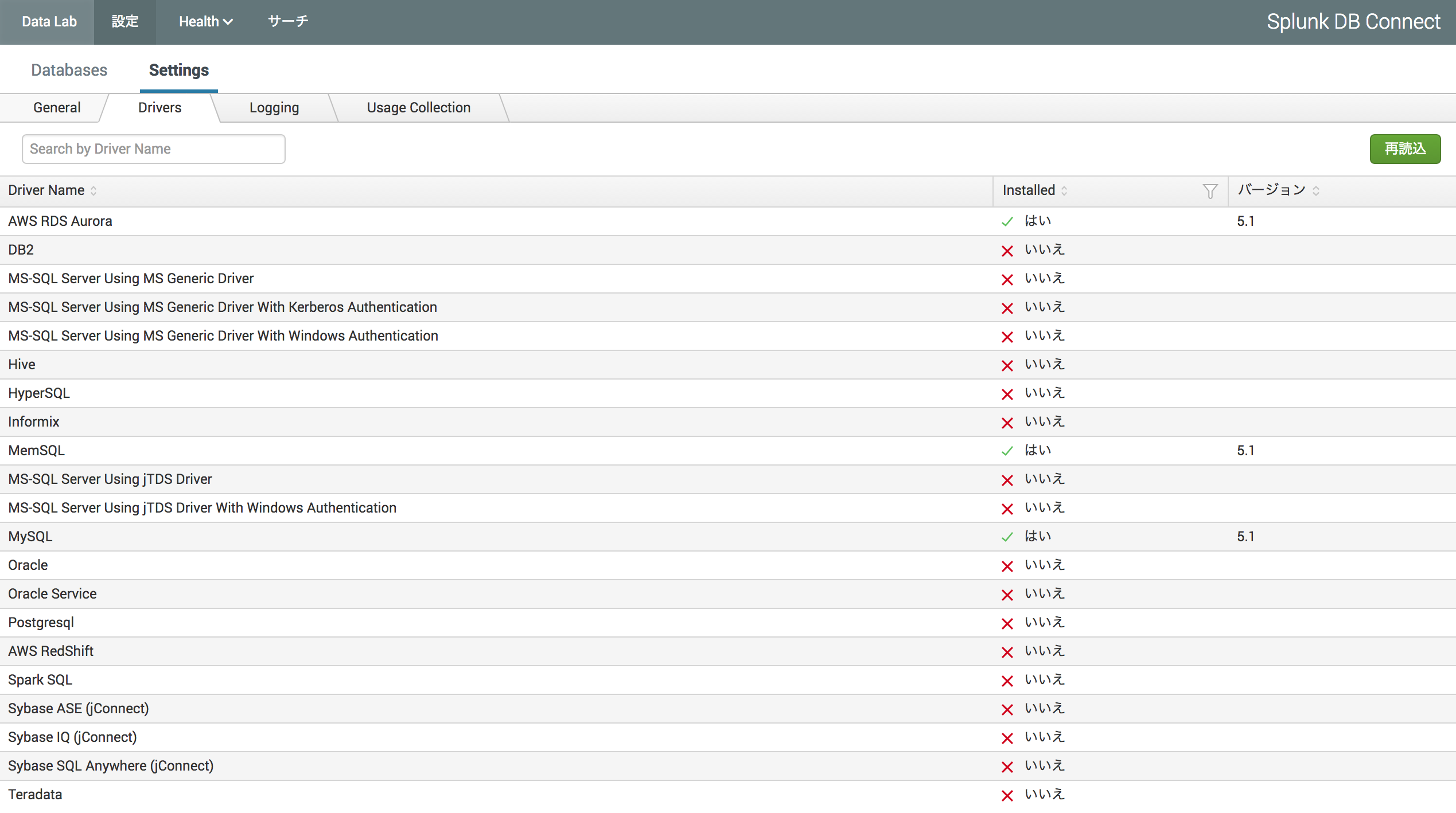 ↑MySQLのドライバが設定されたのがわかりますね
↑MySQLのドライバが設定されたのがわかりますね
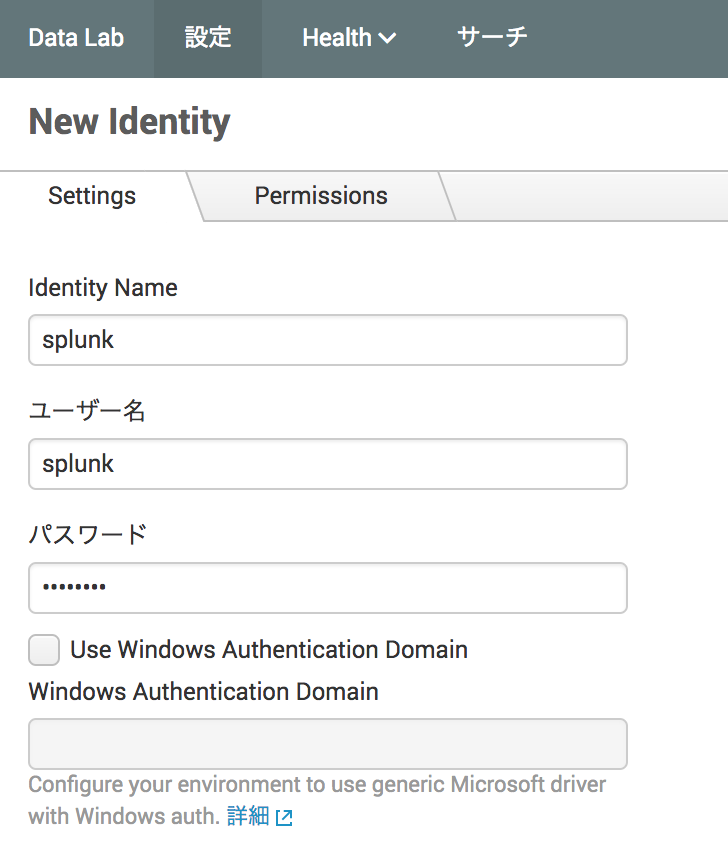
- アイデンティティ作成
DB接続ユーザーのIDとパスワードをSplunkで設定します。
[設定] > [Database] > [Identities] に進んで、右側の[New Identity]ボタンをクリックしてアイデンティティを作成。
私の場合、MySQLにsplunkというユーザーを設定したので、下のように設定しました。
- コネクション作成
SplunkからDBへの接続設定を作成します。
[設定] > [Database] > [Connections] に進んで、右側の[New Connection]ボタンをクリックしてコネクションを作成。
今回は検証環境なので、ローカルのMacにSplunkとMySQLを同居させて、splunktestというデータベースを作成しています。
本来はMySQLとSplunkは別々のサーバーにするべきものなので、必ずしもMySQLサーバーにSplunkをインストールしなければいけないというものではありません、あしからず。
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| splunktest |
+--------------------+
2 rows in set (0.00 sec)
 ↑ `Identyty`は#4で作成したアイデンティティを指定しましょう
↑ `Identyty`は#4で作成したアイデンティティを指定しましょう
データ連携設定
Splunk DB Connectは Input / Output / Lookup の3通りの使い方があります。
InputはDBのデータをSplunkにインデックスします。
Outputは逆にSplunkで検索したデータをDBに書き込みします。
LookupはSplunkに取り込んだログ等に付加情報を与えるものです。(SQLでいうとJOINのイメージです)
今回はInputを紹介します。
Input設定
- Splunk DB Connect > [Data Lab] > [Inputs]
- [New Input]ボタンクリック
今回は以下のように設定しました。
Name Input
名前や説明、コネクションを設定(コネクションは先ほど作成したものを指定しましょう)

Choose and Preview Table: ここ重要
Batch Input か Rising Column を選択します。
Batch Input
毎回同じクエリをデータベースに投げます。したがって、どのレコードまで読み込んだのかを考慮せず全データを毎回取得します。
その場合、Splunkでは前回読み込んだデータを残しつつ、新たに読み込んだデータを追加インデックスします。
毎回テーブルの中身が入れ替わるという場合や1回こっきり読み込む場合には良いでしょう。
Rising Column
どのレコードまで読み込んだかをSplunk側で記録して、次の読み込みタイミングで続きから読み込めるように設定できます。
今回はデータが都度INSERTされるテーブルをインデックスするのでRising Columnを指定します。
ちなみに、テーブル名はsplunk_01で、中身はこんな感じ。
mysql> select * from splunk_01;
+---------------------+-----------+-----------+
| date | column_01 | column_02 |
+---------------------+-----------+-----------+
| 2017-04-03 13:01:38 | abc | 123 |
| 2017-04-03 13:15:52 | def | 456 |
| 2017-04-03 13:16:01 | ghi | 7890 |
| 2017-04-03 15:31:49 | kikeyama | 1234 |
| 2017-04-03 15:42:05 | splunk | 5678 |
| 2017-04-03 16:07:40 | hoge | 1111 |
| 2017-04-03 16:15:21 | melon | 2222 |
| 2017-04-03 16:16:32 | orange | 3333 |
| 2017-04-03 16:16:45 | grape | 4444 |
| 2017-04-03 16:30:37 | suica | 5555 |
+---------------------+-----------+-----------+
10 rows in set (0.00 sec)
Splunkのインデックスではタイムスタンプが重要になるので、dateカラムをつけました。
Splunk設定はコチラ↓

WHERE句の date>? でどこまで読み込んだかのチェックポイントを指定します。
Splunkは $SPLUNK_HOME/var/lib/splunk/modinputs/server/splunk_app_db_connect にチェックポイントを作成します。
この場合、dateカラムの値をチェックポイントとしていますので、そのチェックポイントより大きな値を読み込むようにWHEREで指定しています。
カンの良い方なら気づいたかもしれませんが、タイムスタンプをチェックポイントにするのはオススメできません。
頻繁にINSERTされる場合、レコード書き込みのタイミングとSplunkでの読み込みタイミングしだいでインデックスするデータの重複や漏れが起こり得るからです。
また、NTPによる時刻同期のタイミングしだいでも重複や漏れが起こり得ます。
ということで、オススメはタイムスタンプのレコードではなく、シーケンス番号やトランザクション番号のような、重複せずに昇順降順で表現しやすいユニークな値にすると良いでしょう。
Set Parameters
読み込む行数の制限や実行間隔を設定します。

Splunkでインデックスする際にタイムスタンプ_timeフィールドに入れるべき値はdateカラムと指定しています。
また、今回は1分間隔でSQLを投げてインデックスしています。
メタデータ
ホスト名、ソース、ソースタイプ、インデックスを指定します。Splunkのデータインプットでお馴染みのやつです。

ここまで設定したら [保存] ボタンを押して保存します。
Splunkで検索してみよう
いいですねえ。インデックスされていますねえ。

イベントを開いてみると、テーブルのカラムがそのままフィールドとして設定されていることがわかります。
さらによく見ると、dateカラムの値が_timeフィールドに格納されてますね。

最後に
今回はローカルのMacにSplunkとMySQLを入れて簡易的に設定、動作検証したものとなります。
本番環境で使う際は権限やセキュリティ、パフォーマンスといった観点での注意が必要となります。
詳細な設定方法はSplunk DB Connectのマニュアルをご参照ください。
アプリケーションのトランザクションをDBに格納して保存されている場合、Splunkで詳細に分析・可視化して活用することもできますね。
さらにはログ等他のデータソースと相関検索して分析すればアプリケーション分析やビジネス分析に使えるかもしれません。