はじめに
こちらは Amazon Bedrock Advent Calendar 2024 の 19 日目の記事です。
皆さん、AWS re:InventのKeynoteはリアルタイム視聴してますか?
当たり前でしょ!という方の中でも過去にアップロードされた数百のre:Inventセッション動画に毎年目を通してるよという方は本当に稀有なのではないでしょうか。
では世界有数のAWS事例の宝庫といっても過言ではないセッション動画に目を通さない理由は何でしょう?英語、動画が長い、そもそも数が多すぎる、etc.理由はいくつも考えられますが、生成AIが世界を変えたと言われる2024年になっても言語やメディアのモダリティーが情報流通の障壁になるなんてもったいないですよね。ということで↓
この記事では、その技術詳細や実装における気付きをまとめました。少しでも生成AI活用を進める方の参考になれば幸いです。
何を作りたいのか
昨今は自動字幕生成や要約記事作成など、生成AIを活用したさまざまな機能が登場しています。ただ、自分が欲しい情報を改めて考えてみると単なる字幕や要約だけでは物足りず、例えばログミーさんが実現しているように、プレゼン資料に描かれた細かい図表やトーク中のニュアンスがしっかり反映された全文記事が欲しいという考えに至りました。
具体的には、動画の文字起こしと英語から日本語への翻訳、それに加えて長い文章を読みやすい段落・見出し構造に整え、適切な箇所に動画から切り出した画像を挿入する、という流れをすべて自動化しようと試みました。そして記事の冒頭に要約を入れることで、要点をざっとつかんだうえで本文を深堀りできる形を目指しています。

最終的な処理の流れ
今回実装した記事自動生成の大まかなフローは以下のようになりました。
- 動画データ と 文字起こし結果 を入力
- 動画を一定秒数ごとに静止画へ切り出し、重要な画像だけを抽出
- プレゼン資料の文字情報などはテキスト抽出し、補助情報として使用する
- 文字起こし結果をベースにしつつ、抽出したテキストで文章を修正・補完
- 日本語に翻訳
- 要約や見出し、章分けなどを施して読みやすい形式に整形
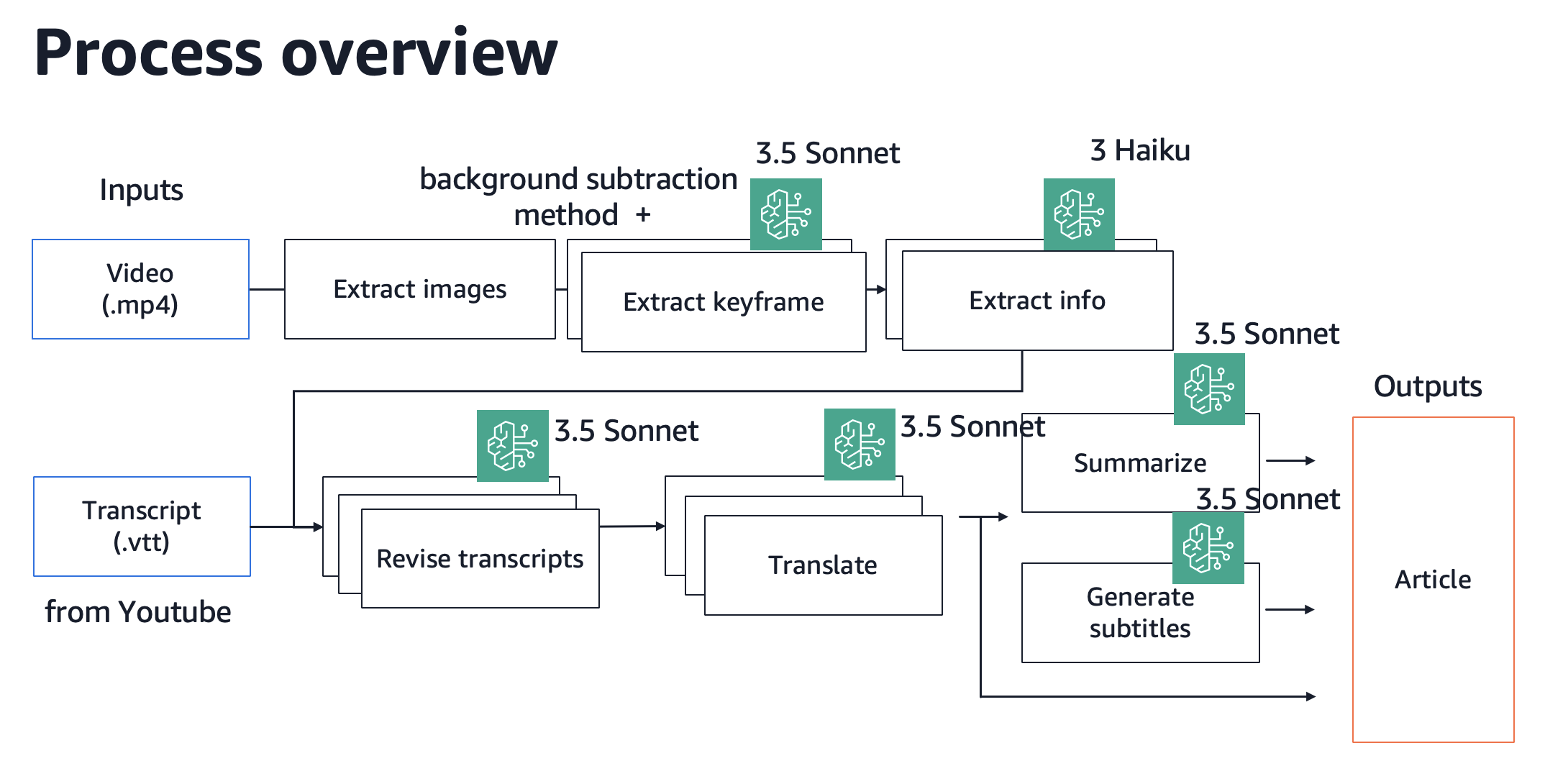
画像や長尺動画を上手く扱う必要もあり、最終的には古典的な画像処理なども組み合わせつつ、LLMに頼るべき部分はサブタスクに細分化した上でLLMを適用する方向に落ち着きました。
実装する中で工夫が必要だった点
精度向上のためのタスク分割
記事化に必要な作業を、すべてを1つのPromptでまとめて解くのはどうしても限界があります。複数の入力の扱い、翻訳、画像挿入、校正、要約、段落分割など、指示が増えれば増えるほどどれか一つがうまくいくと他が崩れやすい状態になり、実際に10以上の指示に厳密に従わせようとするとClaude 3.5 Sonnet v2でも安定しないケースが多々ありました。そんな時に有効だったのがPrompt ChainingやTask Decompositionと呼ばれる考え方です。
例えばAnthropicはPrompt Chainingについて以下のように説明しています。
複雑なタスクを1つのプロンプトで処理しようとすると、Claudeが途中で混乱してしまうことがあります。Chain of Thoughtは優れた手法ですが、タスクに深い思考を必要とする複数の異なるステップがある場合はどうすればよいでしょうか?そこで登場するのがPrompt Chainingです。これは複雑なタスクを、より小さく管理しやすいサブタスクに分解する手法です。
Why chain prompts?
- Accuracy:それぞれのサブタスクにClaudeが完全に集中できるため間違いが減ります
- Clarity:よりシンプルなサブタスクにすることで、指示と出力がより明確になります
- Traceability:Prompt Chainの中の問題を簡単に特定し、修正することができます
また、Amazon Scienceの記事では過度なTask Decompositionの懸念についても言及されています。
タスクの分解と小規模なLLMを使用したエージェント的ワークフローの作成は、より大規模で強力なモデルがしばしば示す新規性や創造性を犠牲にする可能性があります。タスクをサブタスクに「手動で」分解し、特化したモデルに依存することで、全体的なアプローチから生まれる偶発的なつながりや斬新な洞察を捉えることができなくなる可能性があります。
さらに、特定のサブタスクに合わせて複雑なプロンプトを作成するプロセスは、過度に複雑で入り組んだプロンプトを生む可能性があります。これは精度の低下やハルシネーションの増加につながる可能性があります。
まさにこれらの利点と懸念を意識しながらどこでタスクを分割するか、統合するかを調整しました。
- 文章の校正と翻訳は合わせて処理するのが良いのか?
- 特に校正部分のサブタスクが複雑になりがちであったため、更に翻訳まで課すと指示の抜け落ちが多く、分割することに決めた
- 文字起こし結果の校正には、動画から切り出した画像を入力するか、一度画像からテキスト抽出した上で入力するか?
- 今回校正で活用できうる情報はほぼプレゼン資料中のテキストのみであること、画像を複数枚入力すると有意に複雑なタスクでの精度が下がることから、テキストのみを入力することに決めた
処理の並列化と、処理単位間の一貫性の担保
例えばCEO Matt GarmanのKeynoteは2時間45分ほどあり、これを文字に起こすと日本語で7万文字超え。もちろん1回のAPI呼び出しでは処理できないので処理対象を分割して処理することは必須です。基本的にそれらは並列処理できるので速度面でも利点があります。
しかし、文章を分割して処理すると結合する際に不整合が起こる可能性もあります。処理単位の境目で文章が重複する、情報が欠落する、ある処理単位では英語で表現されていたキーワードが次の章では日本語になる、文章のトーンが処理単位ごとに若干違うなど課題も散見されました。
並列処理ではなく直列処理をして前の結果の一部を活用する方法も検討しましたが、処理速度が明らかに伸びるのは試行錯誤の速度に影響しネガティブだったため、独立して並列処理する方向に倒しました。
例えば、最後に処理単位の境目の文章のみを補完する処理を入れる、画像中のテキストから得た全体のキーワードを全ての補完処理時に含める、Promptで極力文体を指示する等の追加の工夫により、全体としては十分読めるレベルになった印象です。
動画から適切なKeyframeを抜き出す
この手の話で難易度が高い処理の一つがこの動画中の適切なKeyframeの抽出です。Video SummarizationにおけるKeyframe選択という文脈では、古典的な手法だと背景差分法やsemanticな特徴量を活用した類似フレームの除去、物体検出やOCRを活用したframeの重要度付け、最近ではDeep Learningベースの重要度のscoringやVLMの活用など様々な手法が提案されています。
今回はプレゼンテーションスライド中のコンテンツを理解した上で判断するという高度な処理が求められたので、最低限背景差分法で重複する画像を除去した後、Claudeを利用したKeyframe抽出を行いました。
以下に実際にKeyframeの条件として指示したPromptの一部を補足します。
- Eliminate images if presentation content (text or visuals on the presentation slides) remains unchanged at all from the previous image. Disregard all other changes, including presenter's dynamic movements, gestures, and expressions changes.
- Images should be eliminated if they lack meaningful presentation content: blank screens, shots showing only the presenter or panelist without any slide content, or any images with significant visual degradation that makes content difficult to comprehend.
このような条件を明記したうえで、CoTを活用しつつKeyframeとして抽出すべき画像のIDを出力させています。Amazon Bedrock上のClaudeは画像を20枚まで含められますが、10枚程度でも精度が悪化し、画像とIDのマッピングを勘違いしたり、条件をSkipし始めたので一回の処理での画像枚数は10枚弱に絞っています。
抜き出した画像を文章中の適切な位置に配置する
こちらも一筋縄で解決しなかった課題です。一見すると、文字起こし結果には動画中の時間が埋め込まれていますし、画像を切り出す際も時間は分かっているので、それらの時間情報を活用すれば解決するように思うのですが、実際は校正や翻訳、段落分けされた後の文章と画像の関係を扱うので悩ましいです。

以下のような手法を試した上で、最終的には3が最も安定して画像を文章中に配置できるという結論に至りました。
- 校正・翻訳後の文章とWebVTTファイルを入力し、各段落の時間をLLMに推定させる
- スライドの内容をから校正・翻訳後の文章に差し込むべき位置を推定させる
- 文字起こし結果自体にKeyframeの情報をimageタグ(< image >Image ID< /image >)で埋め込む。そしてimageタグの位置関係を維持しつつ文章を修正・翻訳するよう指示する
We have Jonathan Kim, < image >40< /image > who is also a Senior Solutions Architect.
結果
re:Invent 2024のセッション動画400個以上をZenn上で公開させていただき、その情報を以下のSpreadsheetにまとめています。
現状の処理では1時間程度の動画を処理するのに、処理時間: 5分、コスト: 100円程掛かっていますが、近年のモデルの進化を見るに調整すれば1-10円でも記事を作成できるでしょう。
精度については実際に記事を読んでいただくのが一番なので、おすすめ記事を載せておきます。
公開から10日で計1万PVぐらいZennの記事を読んでいただいているのですが、SNSでも引用してこのセッションが面白いと言及いただいているのを見ると非常にありがたいです。
現状は個人の環境で処理を回している状況ですが、いずれは類似の仕組みが既存のメディアや記事化専門のサービスに組み込まれ、多くの人が日常で利用するようになるのでしょう。
言語やテキスト・動画・音声といったモダリティを自在に行き来するような、ボーダーレスなメディア体験がここ数年で一層強まるんだろうなという印象を自分も今回の件で強く感じました。
2025年は更に身近に役に立つ活用方法を模索していきたいですね。皆様、良いお年を。
もし既に海外のプレゼン動画などの記事化に取り組まれている企業の方で、この手の技術にご興味ある方がいらっしゃれば、ご一緒できるかもしれないのでぜひご連絡ください!