このページは?
最近、新入社員の人たちが基本情報の勉強をしていたので、自分でもパラパラと基本情報の本を読んでみたのですが、初学者にこの説明をしても難しすぎるのでは??と感じたため厳密ではないと怒られるかもしれませんが自分なりの理解を説明してみようと思いました。
本記事で扱う範囲としては「第三正規形」までを考えています。
正規化とは?
端的に言えば「カラム(列)やテーブルを分割することでデータの不整合を防ぐための設計方法」だと思えば良いです!
正規化の種類
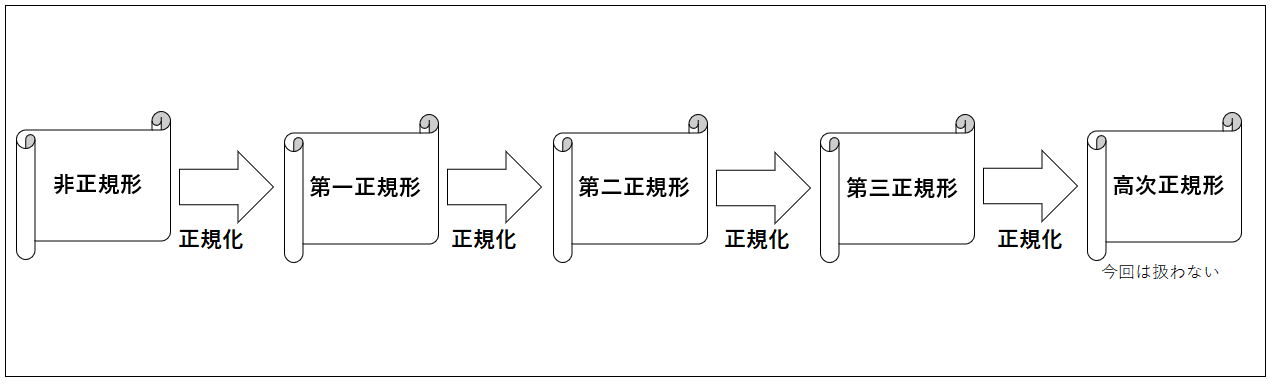
第一正規形
非正規系について
まずは非正規形がどんなものかという点について説明します。
非正規形はフィールド(エクセルでいうところのセル)が結合されていたり一つのフィールドの中に複数の情報が入っています。
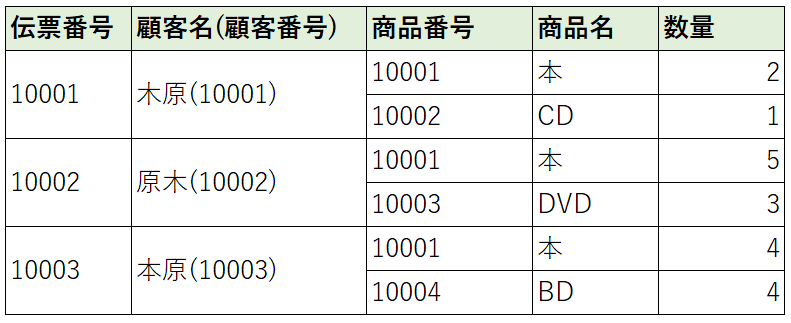
非正規形から第一正規形にするときのポイント
フィールドの結合をなくすこと
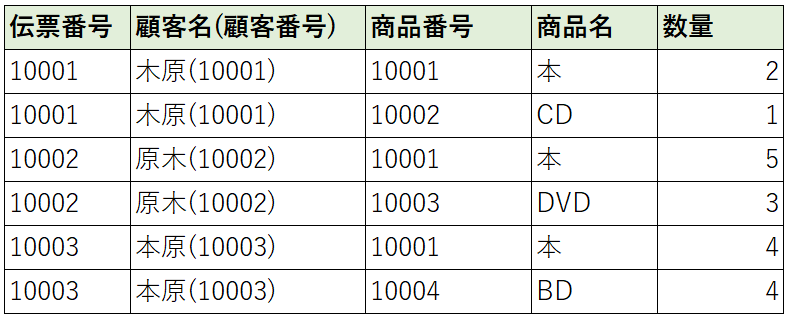
フィールド内に複数の情報が含まれなくすること
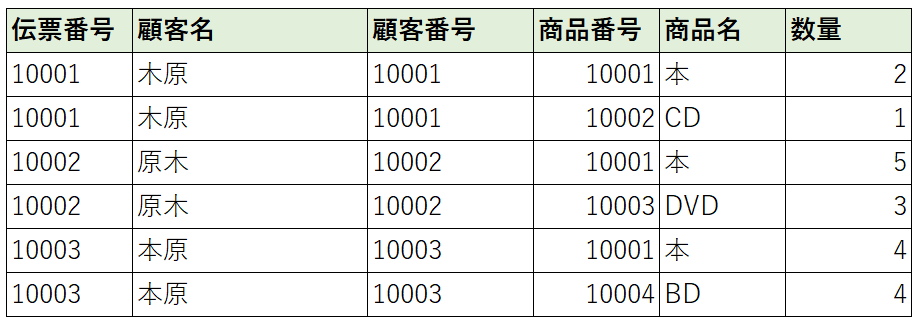
第一正規形のまとめ
第一正規形はシンプルな表として各フィールド内に複数の情報を持たない状態なります。
第二正規形と第三正規形に入る前に
なぜ候補キーを学ぶ必要があるか
第二正規形と第三正規形に入る前に1つ押さえておきたいことがあります。それは「候補キー」についてです。
なぜ第二正規形と第三正規形を学ぶ前に「候補キー」について理解しておく必要があるかといえば第二正規形と第三正規形の行う操作にはほとんど差がないのですが、違いとなるのがこの「候補キー」だからです。
候補キーについて
端的に言えば「レコード(行)を特定するために必要なフィールドの組のうち組の数が最小のもの」です。
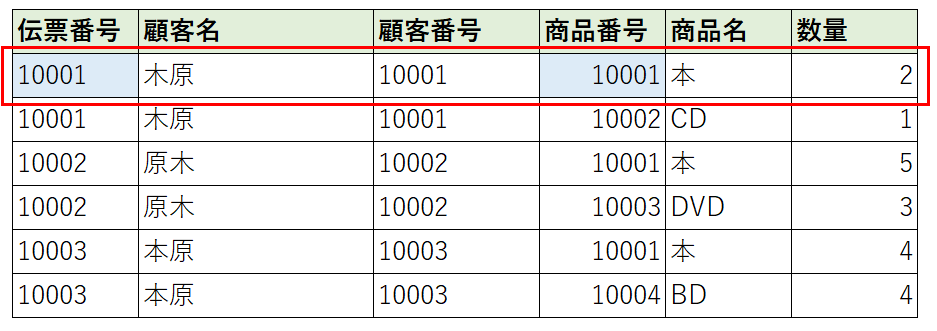
第一正規形の例で具体的に説明します。
このテーブルを見ると「伝票番号」と「商品番号」が分かれば対象のレコード(行)がどれなのか?ということが分かると思います。また、補足ですが、候補キーは一つとは限りません。
今回の場合も「伝票番号」と「商品名」でもレコード(行)を特定することができます。
第二正規形
第二正規形にするための前提条件
そもそも第二正規形にするためには正規化する対象が「第一正規形」である必要があります。
第一正規形から第二正規形にするときのポイント
候補キーと非候補キー(どの候補キーにも含まれないフィールド)に分ける
・候補キー
{伝票番号, 商品番号} or {伝票番号, 商品名}
・非候補キー
顧客名、顧客番号、数量
候補キーを分解した時に非候補キーを特定できるかを考える
{伝票番号}から{数量}が特定できるか?
伝票番号と数量は関係がないので特定できません。
{商品番号}から{数量}が特定できるか?
商品番号と数量は関係がないので特定できません。
{伝票番号}から{顧客番号, 顧客名}が特定できるか?
伝票番号に対して顧客は1人しかいないので特定できます。
{商品番号}から{顧客番号, 顧客名}が特定できるか?
商品番号と顧客は関係がないので特定できません。
特定できた組み合わせを別テーブルとして分解する
・伝票テーブル
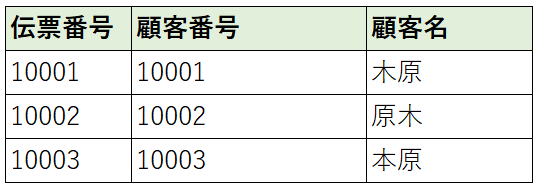
・伝票明細テーブル
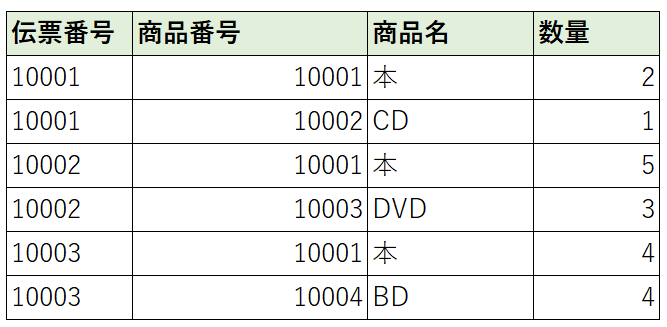
第二正規形のまとめ
第二正規形になると少なくとも候補キーから特定できるような情報が同一レコード内にはない状態になります。
第三正規形
第三正規形にするための前提条件
第三正規形にするためには正規化する対象が「第二正規形」である必要があります。
第二正規形から第三正規形にするときのポイント
非候補キーの中から他の非候補キーを特定できるかを考える
伝票テーブルは{顧客番号}が決まっていれば{顧客名}も決まります。
特定できた組み合わせを別テーブルに分解する
・伝票テーブル
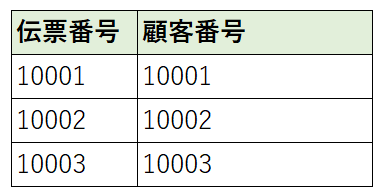
・顧客テーブル
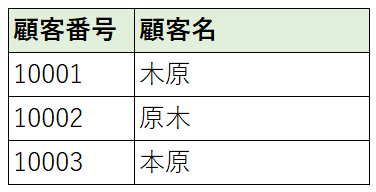
第三正規形のまとめ
第三正規形になると非候補キーの中からも特定できるような情報が同一レコード内にない状態になります。
ところでなんで正規化するの?
正規化を行わない場合は登録、更新、削除のタイミングでデータの不整合を起こす場合があります。
登録時に起きるデータ不整合
下記のケースで新しく顧客のデータを登録したい場合に伝票が必要になってしまいます。
顧客データを伝票に限らずに管理したいと考えたときに正規化を行っていないときに実現できなくなります。
更新時に起こるデータ不整合
下記のケースで1行目の顧客名を「木原」から「木原木」等に変更した場合に2行目の「木原」も「木原木」に変更する必要がありますが、これが漏れてしまうとデータ間で矛盾が起きることがあります。
削除時に起こるデータ不整合
下記のケースで最終行のデータを削除してしまうと「BD」の商品名と商品番号がどこにも管理されなくなってしまいます。
あえて正規化しない!!
正規化を行うとテーブルを結合をする必要があるので、処理速度はどうしても落ちてしまいます。
そのため、あえて正規化を行わないと考えることもあります。
特にどのようなケースで正規化を行わないと判断するかについて少し説明します。
データの更新を行わない場合
正規化の目的を考えるとデータの更新を行わないようなテーブルに対しては正規化を行わなくても良いかなと考えて処理速度を重視してあえて正規化を行わないことがあります。
履歴を管理したい場合
下記のケースで顧客名が何かの原因で変わった場合も伝票を発行した時の名前を残したいというケースで必要以上に正規化してしまうとその情報を残すことができなくなってしまいます。
高速化を求める場合
正規化をすると処理速度が遅くなってしまうので高速化を求めるケースではあえて正規化を行わないと考えることもあります。
終わりに
今回は正規化を説明するにあたり集合論的な話をバッサリと落としています。
そのため、第二正規形と第三正規形については厳密には正しくない気がしています。
ただし、フィールドから他のフィールドを特定できるか?って考えることであったり関係を考えているフィールドが候補キーであるか非候補キーであるかを意識することが正規化を理解するにあたって重要だと考えており、初学者はまずはここから押さえてから集合論を学んだほうが良いのではないか?と考えるためです。
思っていたよりも内容が複雑になってしまったので、この記事も理解しづらいかもしれないのですが、それでも誰かの助けになればよいなと思います。